

A Study of the CHN Intelligent Bone Age Assessment Method with Reference to Atlas Developmental Indications
-
摘要: 骨龄(BA)是评估儿童生长发育是否正常的重要指标之一。中国人手腕骨发育标准-CHN计分法是目前中国儿童生长发育中骨龄评估(BAA)最常用的方法之一。但是在CHN计分法中,某些参照骨图谱的发育指征跨度较大,导致专家依据个人经验主观判断它的发育分期而影响评估准确度。在利用深度学习对该类图谱的发育分期进行评估时,会导致它的评估结果产生随机性。该文基于专家评估过的2万余张儿童手腕部X线片,在CHN计分法的基础上,在相邻发育分期间隔跨度较大的参照骨标准图谱之间勾绘新的成熟度指征,产生细化图谱,并利用层次分析法为其分配对应的成熟度得分,提高骨龄评价的准确率。该文在AlexNet网络的基础上融合Harris特征和卷积注意力模块,对各参照骨的发育分期进行评估。在自制的年龄分布为5-11岁的数据集上,采用优化后的CHN法得到的骨龄在容忍度为0.5岁和1岁时的准确率分别达到了94.6%和99.13%。实验结果表明所提方法可以更加精细地分辨儿童手腕骨发育程度,大幅提高骨龄评估的准确率,辅助临床应用。Abstract: Bone Age (BA) is one of the most important indicators in evaluating children's growth. The Bone Age Assessment (BAA) based on Chinese wrist bone development standard-CHN (CHN) scoring method is widely used in the evaluation of children's growth and development and height prediction. However, the adjacent developmental levels of some reference bones last longer, leading to the subjective judgment of developmental levels by experts based on personal experience, which affects the accuracy of predictions. When deep learning is used to evaluate the developmental levels of these atlases, the prediction results will be random. In this paper, based on more than 20000 X-ray images evaluated by experts, a new mature indicator with a large interval with a large interval is drawn to generate exquisite atlas to perform some reference bones. Additionally, the corresponding maturity score is determined by analyzing the level structure process to maximize the impact of error -level prediction on BAA. Combining Harris features and convolutional blocks of the convolutional neural network of the attention module is designed to evaluate automatically the level of bone maturity. In addition, an annotated database with an age distribution of 5-11 years is built to train and evaluate the method. The accuracy of predictions obtained by adding a new standard atlas to the CHN method reaches 94.6% and 99.13% when the tolerance is 0.5 years and 1 year, respectively. The experimental results show that the method proposed in this paper can distinguish the development degree of reference bones more precisely, and improve greatly the accuracy of BAA, proving the potential for practical clinical application.
-
表 1 近节指骨Ⅴ各发育分期等级数量分布表
发育分期等级 多位专家意见是否
全部一致图片数量 在该分期图像中的
占比(%)3 一致 431 38.14 不一致 699 61.86 4 一致 830 59 不一致 577 41  下载: 导出CSV
下载: 导出CSV
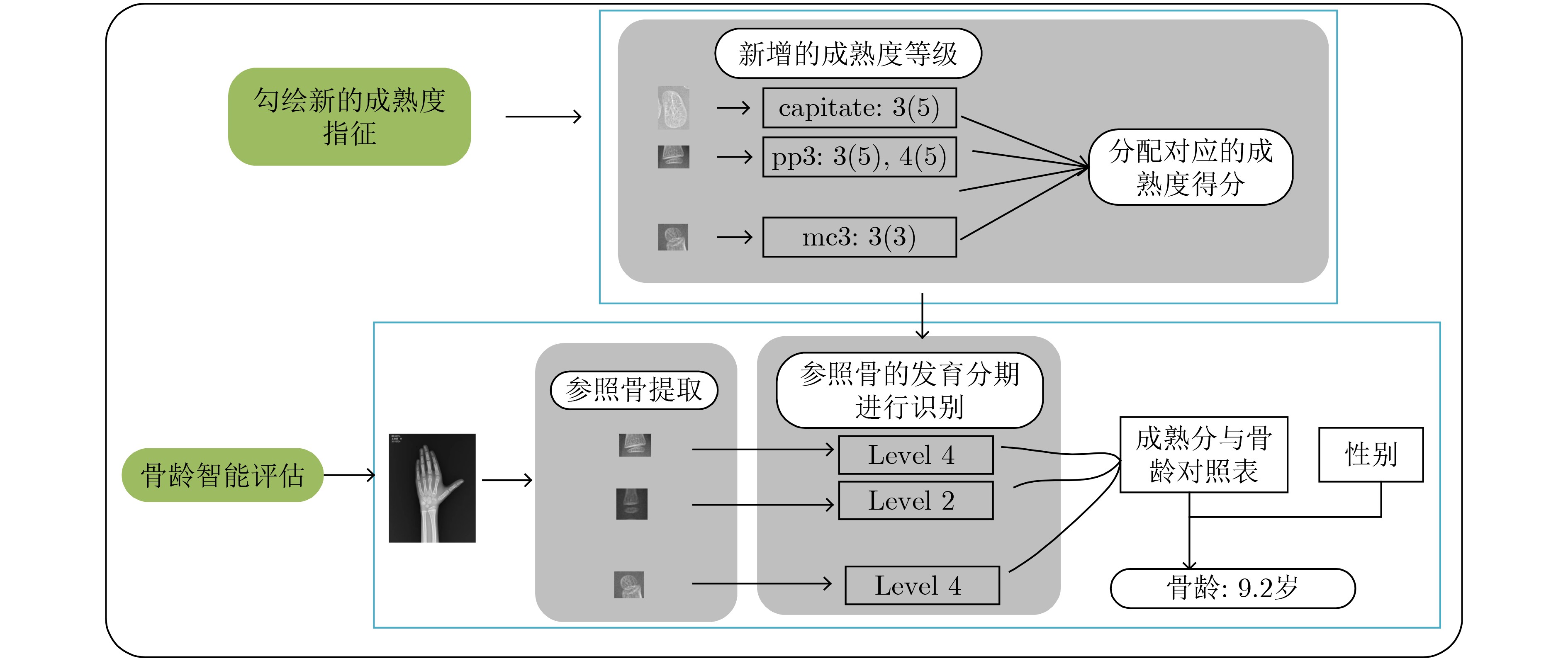
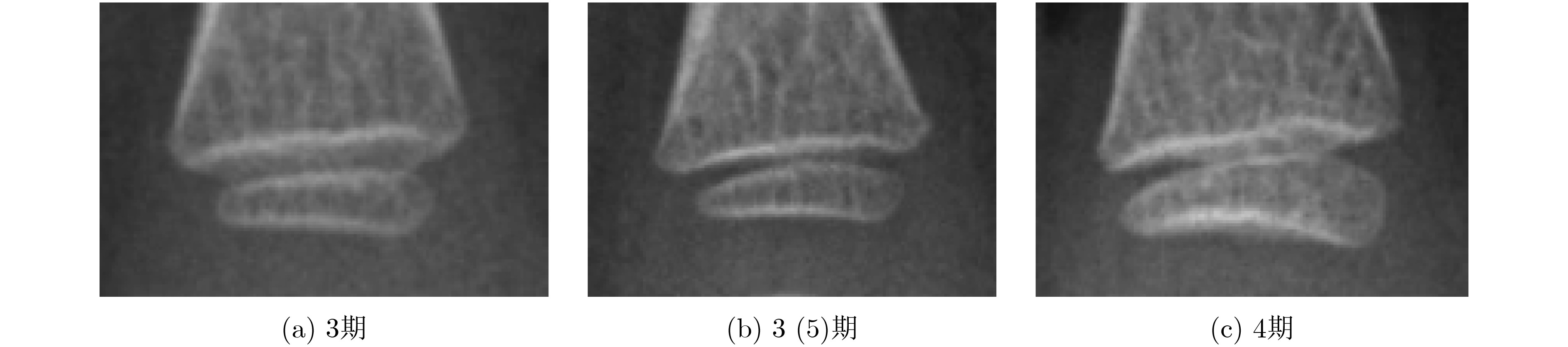
表 3 近节指骨Ⅴ的成熟度等级以及发育指征和其对应成熟度得分
发育分期 Level3 Level3(5) Level4 对应标准图谱 


对应发育指征 骨骺最大横径≥干骺端的一半 骨骺近侧缘有凹起的趋势,开始出现致密白线 骨骺近侧缘凹,明显致密 对应得分(男) 34 40 45 对应得分(女) 43 48 53
下载: 导出CSV
表 5 14块参照骨的发育分期分类准确率(%)
mp3 mp5 pp5 pp3 pp1 dp1 dp3 dp5 Capitate Hamate Radius mc1 mc3 mc5 准确率 89.00 96.70 88.60 86.00 97.87 85.30 98.02 96.42 83.66 93.10 83.72 97.43 91.60 92.38
下载: 导出CSV
表 6 不同年龄组在不同性能指标下的准确率(%)
年龄(岁) Label1 label2 ±0.5岁 ±1岁 ±0.5岁 ±1岁 5-6 86.88 99.17 86.58 96.76 6-7 85.78 98.95 84.03 94.18 7-8 86.36 98.73 83.45 97.82 8-9 80.70 97.69 81.38 94.02 9-10 89.92 98.32 88.24 97.70 10-11 88.79 97.43 88.48 98.87
下载: 导出CSV
表 7 分别采用CHN法和Re_CHN法得到的骨龄评估准确率(%)
标准 BAA方法 ± 0.5岁 ±1岁 label1 Re_CHN 87.93 98.67 CHN 78.27 97.54 label2 Re_CHN 85.62 96.20 CHN 72.78 95.81 label1 or label2 Re_CHN 94.60 99.13 CHN 85.18 98.50
下载: 导出CSV
-
[1] 潘复平, 张国栋. 骨龄与青春期发育关系的追踪观察[J]. 中华预防医学杂志, 1985, 19(2): 79–82.PAN Fuping and ZHANG Guodong. Follow-up observation on the relationship between bone age and puberty development[J]. Chinese Journal of Preventive Medicine, 1985, 19(2): 79–82. [2] 邵伟东, 金春华, 潘慧, 等. 中国儿童手腕部骨龄评测标准CHN法与参考图谱[M]. 北京: 中国协和医科大学出版社, 2018: 15–20.SHAO Weidong, JIN Chunhua, PAN Hui, et al. Chinese Children's Wrist Bone Age Evaluation Standard[M]. Beijing: Peking Union Medical College Press, 2018: 15–20. [3] 张烨城. 骨龄在体育教学及训练中的应用[J]. 青少年体育, 2018(9): 58–59. doi: 10.3969/j.issn.2095-4581.2018.09.037ZHANG Yecheng. Application of bone age in physical education teaching and training[J]. Youth Sport, 2018(9): 58–59. doi: 10.3969/j.issn.2095-4581.2018.09.037 [4] 沈勋章. 手腕部骨龄鉴定方法的研究进展[J]. 中国医药科学, 2011, 1(12): 9–12.SHEN Xunzhang. Identification of wrist skeletal age of the research progress[J]. China Medicine and Pharmacy, 2011, 1(12): 9–12. [5] SPAMPINATO C, PALAZZO S, GIORDANO D, et al. Deep learning for automated skeletal bone age assessment in X-ray images[J]. Medical Image Analysis, 2017, 36: 41–51. doi: 10.1016/j.media.2016.10.010 [6] GREULICH W W and IDELL PYLE S. Radiographic atlas of skeletal development of the hand and wrist[J]. The American Journal of the Medical Sciences, 1959, 238(3): 393. [7] TANNER J M and WHITEHOUSE R H. Clinical longitudinal standards for height, weight, height velocity, weight velocity, and stages of puberty[J]. Archives of Disease in Childhood, 1976, 51(3): 170–179. doi: 10.1136/adc.51.3.170 [8] 叶义言. 新版骨龄评分法概述[J]. 中华儿科杂志, 2004, 42(1): 30–32. doi: 10.3760/j.issn:0578-1310.2004.01.009YE Yiyan. Overview of new version of bone age scoring method[J]. Chinese Journal of Pediatrics, 2004, 42(1): 30–32. doi: 10.3760/j.issn:0578-1310.2004.01.009 [9] 张绍岩, 花纪青, 刘丽娟, 等. 中国人手腕骨发育标准—中华05. III. 中国儿童骨发育的长期趋势[J]. 中国运动医学杂志, 2007, 26(2): 149–153. doi: 10.16038/j.1000-6710.2007.02.004ZHANG Shaoyan, HUA Jiqing, LIU Lijuan, et al. The standards of skeletal maturity of hand and wrist for Chinese-China 05. III. The secular trend of skeletal development in Chinese children[J]. Chinese Journal of Sports Medicine, 2007, 26(2): 149–153. doi: 10.16038/j.1000-6710.2007.02.004 [10] 张绍岩, 杨士增, 邵伟东, 等. 中国人手腕骨发育标准—CHN法[J]. 体育科学, 1993, 13(6): 33–39.ZHANG Shaoyan, YANG Shizeng, SHAO Weidong, et al. The standards of skeletal development of hand and wrist for Chinese-CHN method[J]. China Sports Science, 1993, 13(6): 33–39. [11] THODBERG H H, KREIBORG S, JUUL A, et al. The BoneXpert method for automated determination of skeletal maturity[J]. IEEE Transactions on Medical Imaging, 2009, 28(1): 52–66. doi: 10.1109/tmi.2008.926067 [12] LEE H, TAJMIR S, LEE J, et al. Fully automated deep learning system for bone age assessment[J]. Journal of Digital Imaging, 2017, 30(4): 427–441. doi: 10.1007/s10278-017-9955-8 [13] OQUAB M, BOTTOU L, LAPTEV I, et al. Learning and transferring mid-level image representations using convolutional neural networks[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1717–1724. [14] REN Xuhua, LI Tingting, YANG Xiujun, et al. Regression convolutional neural network for automated pediatric bone age assessment from hand radiograph[J]. IEEE Journal of Biomedical and Health Informatics, 2019, 23(5): 2030–2038. doi: 10.1109/jbhi.2018.2876916 [15] HAN Yaxin and WANG Guangbin. Skeletal bone age prediction based on a deep residual network with spatial transformer[J]. Computer Methods and Programs in Biomedicine, 2020, 197: 105754. doi: 10.1016/j.cmpb.2020.105754 [16] LIU Bo, ZHANG Yu, CHU Meicheng, et al. Bone age assessment based on rank-monotonicity enhanced ranking CNN[J]. IEEE Access, 2019, 7: 120976–120983. doi: 10.1109/access.2019.2937341 [17] SON S J, SONG Y, KIM N, et al. TW3-based fully automated bone age assessment system using deep neural networks[J]. IEEE Access, 2019, 7: 33346–33358. doi: 10.1109/access.2019.2903131 [18] 刘宗才, 吴锦华, 王荣品, 等. 深度学习骨龄评测系统对贵州省儿童及青少年骨龄测评的准确性[J]. 中国医学影像技术, 2019, 35(12): 1799–1803. doi: 10.13929/j.1003-3289.201907037LIU Zongcai, WU Jinhua, WANG Rongpin, et al. Accuracy of deep learning based bone age assessment system of children and adolescents in Guizhou[J]. Chinese Journal of Medical Imaging Technology, 2019, 35(12): 1799–1803. doi: 10.13929/j.1003-3289.201907037 [19] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/tpami.2016.2577031 [20] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386 [21] LIU Jun, WANG Guang, DUAN Lingyu, et al. Skeleton-based human action recognition with global context-aware attention LSTM networks[J]. IEEE Transactions on Image Processing, 2018, 27(4): 1586–1599. doi: 10.1109/tip.2017.2785279 [22] WANG Jinrui, LI Shunming, AN Zenghui, et al. Batch-normalized deep neural networks for achieving fast intelligent fault diagnosis of machines[J]. Neurocomputing, 2019, 329: 53–65. doi: 10.1016/j.neucom.2018.10.049 [23] DAHL G E, SAINATH T N, and HINTON G E. Improving deep neural networks for LVCSR using rectified linear units and dropout[C]. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, Canada, 2013: 8609–8613. [24] KO B, KIM H G, OH K J, et al. Controlled dropout: A different approach to using dropout on deep neural network[C]. 2017 IEEE International Conference on Big Data and Smart Computing, Jeju, Korea (South), 2017: 358–362. [25] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. [26] HU Jie, SHEN Li, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011–2023. doi: 10.1109/TPAMI.2019.2913372 [27] WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11531–11539. [28] LIU Haomiao, WANG Ruiping, SHAN Shiguang, et al. Deep supervised hashing for fast image retrieval[J]. International Journal of Computer Vision, 2019, 127(9): 1217–1234. doi: 10.1007/s11263-019-01174-4 [29] WU E, KONG Bin, WANG Xin, et al. Residual attention based network for hand bone age assessment[C]. 2019 IEEE 16th International Symposium on Biomedical Imaging, Venice, Italy, 2018: 1158–1161. -

 下载:
下载:





图(5) / 表(8)
计量
- 文章访问数: 1588
- HTML全文浏览量: 1345
- PDF下载量: 84
- 被引次数: 0
