

Hierarchical State Regularization Variational AutoEncoder Based on Memristor Recurrent Neural Network
-
摘要: 变分自编码器(VAE)作为一个功能强大的文本生成模型受到越来越多的关注。然而,变分自编码器在优化过程中容易出现后验崩溃,即忽略潜在变量,退化为一个自编码器。针对这个问题,该文提出一种新的变分自编码器模型,通过层次化编码和状态正则方法,可以有效缓解后验崩溃,且相较于基线模型具有更优的文本生成质量。在此基础上,基于纳米级忆阻器,将提出的变分自编码器模型与忆阻循环神经网络(RNN)结合,设计一种基于忆阻循环神经网络的硬件实现方案,即层次化变分自编码忆组神经网络(HVAE-MNN),探讨模型的硬件加速。计算机仿真实验和结果分析验证了该文模型的有效性与优越性。Abstract: As a powerful text generation model, the Variational AutoEncoder(VAE) has attracted more and more attention. However, in the process of optimization, the variational auto-encoder tends to ignore the potential variables and degenerates into an auto-encoder, called a posteriori collapse. A new variational auto-encoder model is proposed in this paper, called Hierarchical Status Regularisation Variational AutoEncoder (HSR-VAE), which can effectively alleviate the problem of posterior collapse through hierarchical coding and state regularization and has better model performance than the baseline model. On this basis, based on the nanometer memristor, the model is combined with the memristor Recurrent Neural Network (RNN). A hardware implementation scheme based on a memristor recurrent neural network is proposed to realize the hardware acceleration of the model, which called Hierarchical Variational AutoEncoder Memristor Neural Networks (HVAE-MHN). Computer simulation experiments and result analysis verify the validity and superiority of the proposed model.
-
Key words:
- Variational AutoEncoder(VAE) /
- Memristor /
- Memristor recurrent network /
- Text generation
-
表 1 数据集
数据集 训练集 验证集 测试集 词表(k) PTB 42068 3370 3761 9.95 Yelp 100000 10000 10000 19.76 Yahoo 100000 10000 10000 19.73 Dailydialog 11118 1000 1000 22  下载: 导出CSV
下载: 导出CSV
表 2 语言模型实验对比
模型 PTB Yahoo NLL↓ PPL↓ KL NLL↓ PPL↓ KL VAE-LSTM 101.2 101.4 0.0 328.6 61.2 0.0 SA-VAE 101.0 100.7 1.3 327.2 60.2 5.2 Cyc-VAE 102.8 109.0 1.4 330.6 65.3 2.1 Lag_VAE 100.9 99.8 7.2 326.7 59.8 5.7 BN-VAE 100.2 96.9 7.2 327.4 60.2 8.8 Sri-VAE 101.2 94.2 10.1 327.3 57.0 16.1 TWR-VAE 86.6 40.9 5.0 317.3 50.2 3.3 本文 79.4 30.2 9.1 290.7 35.8 8.7
下载: 导出CSV
表 3 语言模型生成文本示例
模型 原始文本 生成文本 TWR-VAE (1) it 's totally different
(2) sec proposals may n
(3) the test may come today(1) it 's very ok
(2) terms officials may n
(3) the naczelnik may be本文 (1) merrill lynch ready assets trust
(2) all that now has changed
(3) now it 's happening again(1) merrill lynch ready assets trust
(2) what that now has changed
(3) now it 's quite again
下载: 导出CSV
表 4 消融研究实验对比
模型 Yelp Yahoo NLL↓ PPL↓ MI↑ KL NLL↓ PPL↓ MI↑ KL TWR-VAE_RNN 395.4 56.4 3.9 0.5 363.0 88.2 4.1 0.6 TWR-VAE_GRU 360.9 39.7 4.2 3.3 336.9 63.9 4.2 3.7 TWR-VAE_ LSTM 344.3 33.5 4.1 3.1 317.3 50.2 4.1 3.3 本文 RNN + RNN 400.9 57.3 2.6 1.3 366.3 90.8 3.2 2.4 RNN + LSTM 340.3 31.3 3.7 5.1 303.2 41.7 3.3 6.0 RNN + GRU 358.6 37.4 3.6 3.1 326.5 56.2 4.9 3.9 LSTM + RNN 349.7 34.2 3.3 6.3 310.8 46.7 3.4 6.7 LSTM + LSTM 340.4 31.1 3.7 10.2 310.4 45.6 3.5 8.8 LSTM + GRU 341.5 31.4 3.3 7.0 295.7 38.1 3.5 7.9 GRU + RNN 349.8 34.2 4.6 10.6 320.8 52.8 4.8 11.2 GRU + LSTM 342.5 31.7 3.4 10.7 293.7 37.1 3.5 11.1 GRU + GRU 336.6 29.9 3.5 7.3 290.7 35.8 3.4 8.7
下载: 导出CSV
表 5 对话响应生成任务实验对比
模型 BLEU BOW Intra-dist Inter-dist R↑ P↑ F1↑ A↑ E↑ G↑ dist-1↑ dist-2↑ dist-1↑ dist-2↑ SeqGAN 0.270 0.270 0.270 0.918 0.495 0.774 0.747 0.806 0.075 0.081 VHRED 0.271 0.260 0.265 0.892 0.507 0.786 0.633 0.771 0.071 0.089 VHCR 0.289 0.266 0.277 0.925 0.525 0.798 0.768 0.814 0.105 0.129 CVAE 0.265 0.222 0.242 0.923 0.543 0.811 0.938 0.973 0.177 0.222 WAE 0.341 0.278 0.306 0.948 0.578 0.846 0.830 0.940 0.327 0.583 iVAE 0.355 0.239 0.285 0.951 0.609 0.872 0.897 0.975 0.501 0.868 TWR-VAE 0.407 0.281 0.333 0.952 0.603 0.865 0.921 0.990 0.497 0.817 本文 0.377 0.268 0.313 0.919 0.583 0.859 0.977 0.969 0.701 0.915
下载: 导出CSV
表 6 对话响应生成文本示例
TWR-VAE 本文 对话1 问题: come in, come in, what can i do for you ?期望响应: professor donald, are you giving your advanced geology course again next semester? (1) i would like to have a look at your computer.
(2) hello, i'd like to buy a ticket to shanghai.
(3) hello, i'm looking for a job.(1) who have been working.
(2) and a lot of coffee.
(3) some advice of humor.对话2 问题: does the bathroom have a bath or a shower? 期望响应: all our bathrooms have full size <unk> with a shower attachment. (1) yes, sir. everything is available. and we will charge it.
(2) perhaps i can use a credit card to the bank. what would you like?
(3) sure. does that mean will be there in your room?(1) sure, we have two. the room is <unk> and <unk>. it's $ 60 for a while.
(2) that's a reserved room, but it has a maximum account with us today.
(3) yes, that is the fee.
下载: 导出CSV
-
[1] KINGMA D P and WELLING M. Auto-encoding variational bayes[C]. The 2nd International Conference on Learning Representations, Banff, Canada, 2014. [2] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139–144. doi: 10.1145/3422622 [3] VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[J]. arXiv: 1807.03748, 2018. [4] RAZAVI A, VAN DEN OORD A, and VINYALS O. Generating diverse high-fidelity images with VQ-VAE-2[C]. The 33rd Conference on Neural Information Processing Systems, Vancouver, Canada, 2019. [5] LI Xiao, LIN Chenghua, LI Ruizhe, et al. Latent space factorisation and manipulation via matrix subspace projection[C/OL]. The 37th International Conference on Machine Learning, 2020. [6] LI Ruizhe, LI Xiao, LIN Chenghua, et al. A stable variational autoencoder for text modelling[C]. The 12th International Conference on Natural Language Generation, Tokyo, Japan, 2019. [7] FANG Le, LI Chunyuan, GAO Jianfeng, et al. Implicit deep latent variable models for text generation[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 2019. [8] GU Xiaodong, CHO K, HA J W, et al. DialogWAE: Multimodal response generation with conditional wasserstein auto-encoder[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019. [9] JOHN V, MOU Lili, BAHULEYAN H, et al. Disentangled representation learning for non-parallel text style transfer[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019. [10] BOWMAN S R, VILNIS L, VINYALS O, et al. Generating sentences from a continuous space[C]. The 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 2016: 10–21. [11] YANG Zichao, HU Zhiting, SALAKHUTDINOV R, et al. Improved variational autoencoders for text modeling using dilated convolutions[C]. The 34th International Conference on Machine Learning, Sydney, Australia, 2017: 3881–3890. [12] XU Jiacheng and DURRETT G. Spherical latent spaces for stable variational autoencoders[C]. The 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2018: 4503–4513. [13] SHEN Dinghan, CELIKYILMAZ A, ZHANG Yizhe, et al. Towards generating long and coherent text with multi-level latent variable models[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 2079–2089. [14] HAO Fu, LI Chunyuan, LIU Xiaodong, et al. Cyclical annealing schedule: A simple approach to mitigating KL vanishing[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019: 240–250. [15] HE Junxian, SPOKOYNY D, NEUBIG G, et al. Lagging inference networks and posterior collapse in variational autoencoders[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019. [16] ZHU Qile, BI Wei, LIU Xiaojiang, et al. A batch normalized inference network keeps the KL vanishing away[C/OL]. The 58th Annual Meeting of the Association for Computational Linguistics, 2020: 2636–2649. [17] LI Ruizhe, LI Xiao, CHEN Guanyi, et al. Improving variational autoencoder for text modelling with timestep-wise regularisation[C]. The 28th International Conference on Computational Linguistics, Barcelona, Spain, 2020: 2381–2397. [18] PANG Bo, NIJKAMP E, HAN Tian, et al. Generative text modeling through short run inference[C/OL]. The 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021: 1156–1165. [19] SILVA F, SANZ M, SEIXAS J, et al. Perceptrons from memristors[J]. Neural Networks, 2020, 122: 273–278. doi: 10.1016/j.neunet.2019.10.013 [20] LIU Jiaqi, LI Zhenghao, TANG Yongliang, et al. 3D Convolutional Neural Network based on memristor for video recognition[J]. Pattern Recognition Letters, 2020, 130: 116–124. doi: 10.1016/j.patrec.2018.12.005 [21] WEN Shiping, WEI Huaqiang, YANG Yin, et al. Memristive LSTM network for sentiment analysis[J]. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2021, 51(3): 1794–1804. doi: 10.1109/TSMC.2019.2906098 [22] ADAM K, SMAGULOVA K, and JAMES A P. Memristive LSTM network hardware architecture for time-series predictive modeling problems[C]. 2018 IEEE Asia Pacific Conference on Circuits and Systems, Chengdu, China, 2018: 459–462. [23] GOKMEN T, RASCH M J, and HAENSCH W. Training LSTM networks with resistive cross-point devices[J]. Frontiers in Neuroscience, 2018, 12: 745. doi: 10.3389/fnins.2018.00745 [24] LI Can, WANG Zhongrui, RAO Mingyi, et al. Long short-term memory networks in memristor crossbar arrays[J]. Nature Machine Intelligence, 2019, 1(1): 49–57. doi: 10.1038/s42256-018-0001-4 [25] LIU Xiaoyang, ZENG Zhigang, and WUNSCH II D C. Memristor-based LSTM network with in situ training and its applications[J]. Neural Networks, 2020, 131: 300–311. doi: 10.1016/j.neunet.2020.07.035 [26] PARK Y, CHO J, and KIM G. A hierarchical latent structure for variational conversation modeling[C]. 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, USA, 2018: 1792–1801. [27] CHUA L. Memristor-the missing circuit element[J]. IEEE Transactions on Circuit Theory, 1971, 18(5): 507–519. doi: 10.1109/TCT.1971.1083337 [28] STRUKOV D B, SNIDER G S, STEWART D R, et al. The missing memristor found[J]. Nature, 2008, 453(7191): 80–83. doi: 10.1038/nature06932 [29] KIM Y, WISEMAN S, MILLER A C, et al. Semi-amortized variational autoencoders[C]. The 35 th International Conference on Machine Learning, Stockholm, Sweden, 2018: 2678–2687. [30] ZHAO Tiancheng, ZHAO Ran, and ESKENAZI M. Learning discourse-level diversity for neural dialog models using conditional variational autoencoders[C]. The 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 2017: 654–664. [31] LI Yanran, SU Hui, SHEN Xiaoyu, et al. DailyDialog: A manually labelled multi-turn dialogue dataset[C]. The Eighth International Joint Conference on Natural Language Processing, Taipei, China, 2017: 986–995. [32] KHEMAKHEM I, KINGMA D P, MONTI R P, et al. Variational autoencoders and nonlinear ICA: A unifying framework[C]. The Twenty Third International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 2020. [33] SERBAN I V, SORDONI A, LOWE R, et al. A hierarchical latent variable encoder-decoder model for generating dialogues[C]. The 31st AAAI Conference on Artificial Intelligence, San Francisco, USA, 2017. [34] YU Lantao, ZHANG Weinan, WANG Jun, et al. SeqGAN: Sequence generative adversarial nets with policy gradient[C]. The Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, USA, 2017: 2852–2858. -


 下载:
下载:
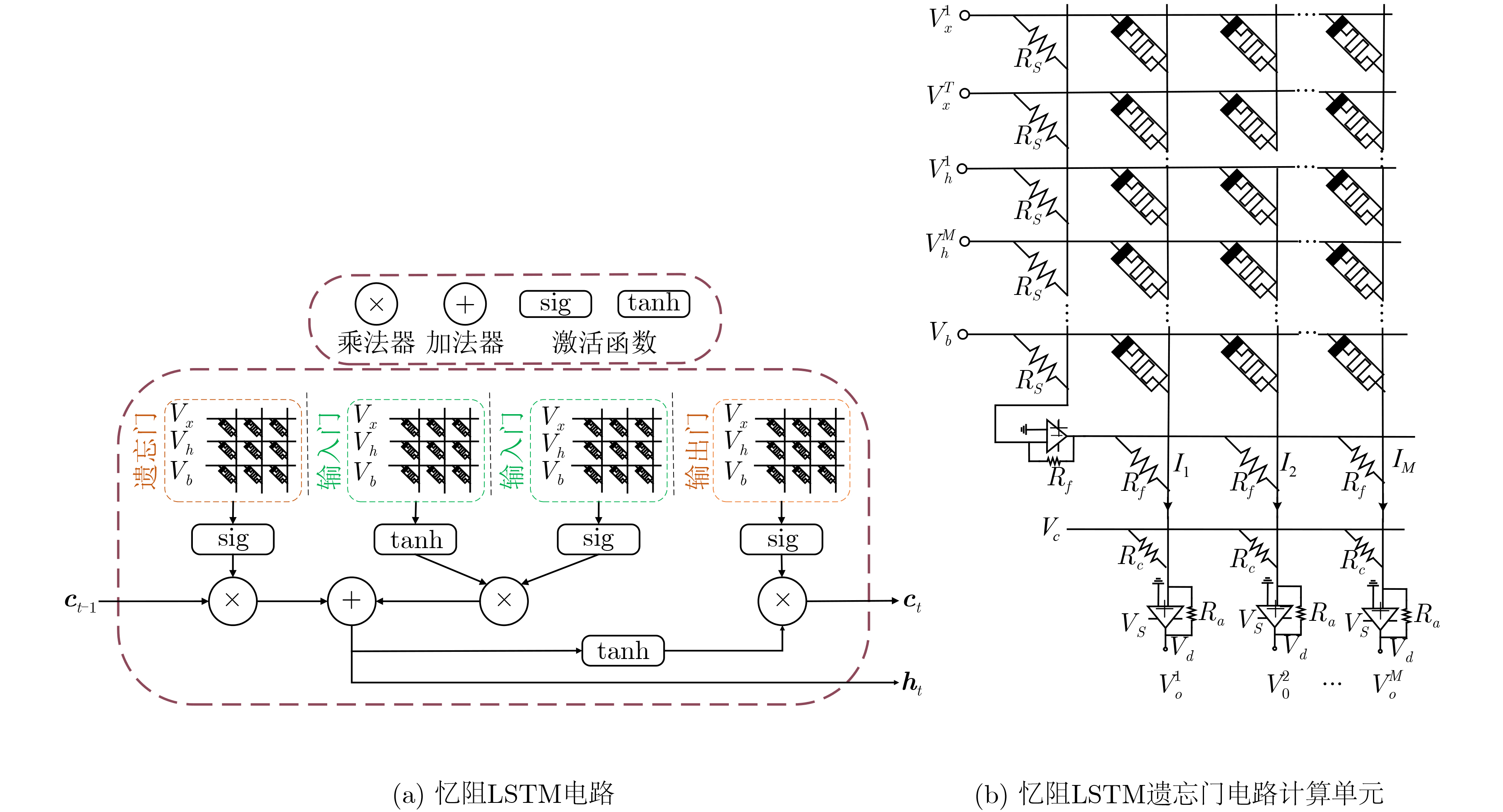


图(2) / 表(6)
计量
- 文章访问数: 1159
- HTML全文浏览量: 887
- PDF下载量: 146
- 被引次数: 0
