

Weapon-Target Assignment Optimization Based on Multi-attribute Decision-making and Deep Q-Network for Missile Defense System
-
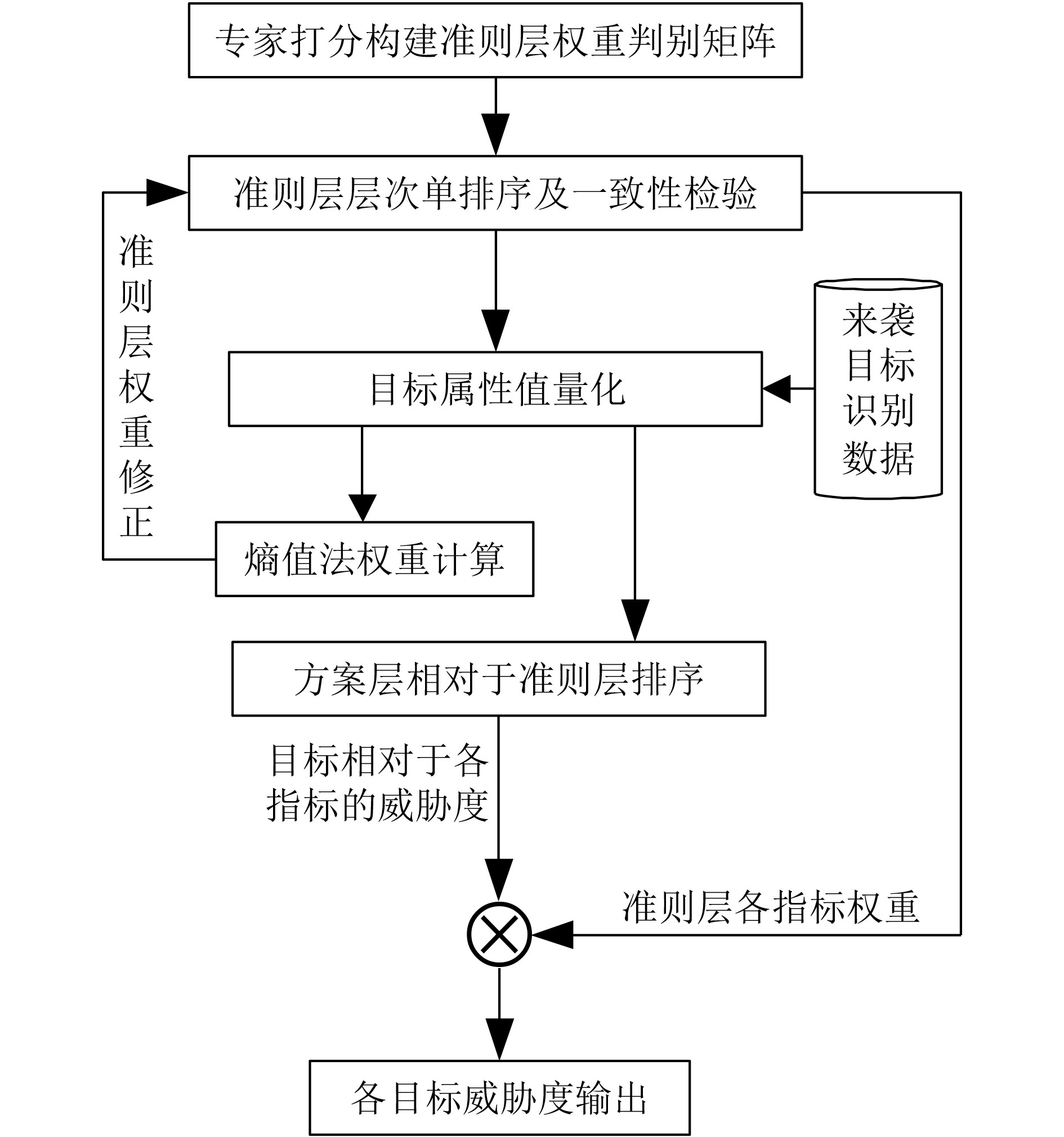
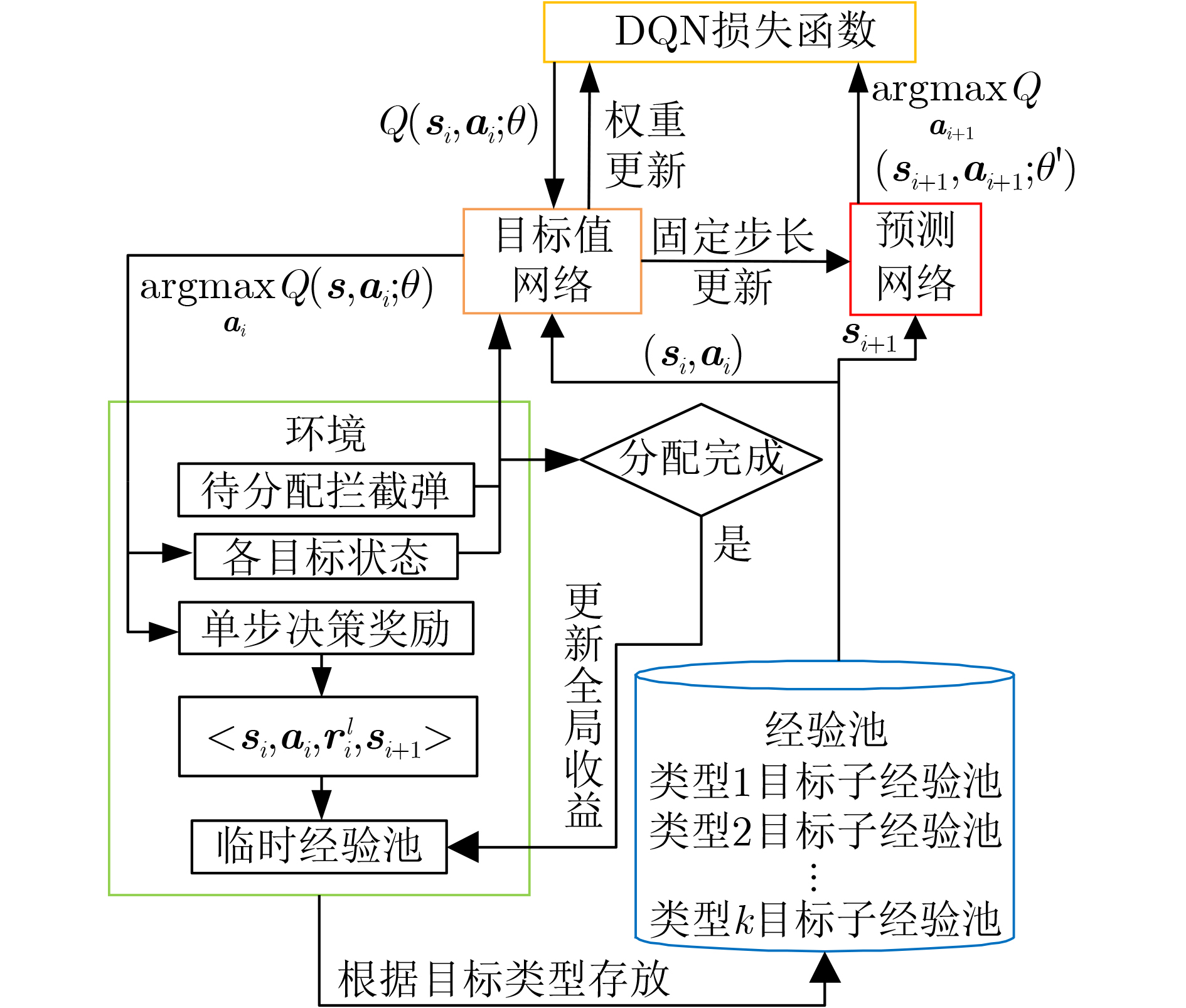
摘要: 针对中大规模武器-目标分配(WTA)决策空间复杂度高、求解效率低的问题,该文提出一种基于多属性决策和深度Q网络(DQN)的WTA优化方法。建立基于层次分析法(AHP)的导弹威胁评估模型,引入熵值法表征目标属性差异,提升威胁评估客观性。根据最大毁伤概率准则,建立基于DQN的WTA分段决策模型,引入经验池均匀采样策略,确保各类目标分配经验的等概率抽取;设计综合局部和全局收益的奖励函数,兼顾DQN火力分配模型的训练效率和决策准确性。仿真结果表明,相较于传统启发式方法,该方法具备在线快速求解大规模WTA问题的优势,且对于WTA场景要素变化具有较好的鲁棒性。Abstract: In a large-scale Weapon-Target Assignment (WTA) problem, the explored solution space becomes enormous due to the curse of dimensionality, and it causes low-efficiency in searching optimization solution. For solving this problem effectively, a WTA optimization approach based on multi-attribute decision-making and Deep Q-Network (DQN) is proposed. Firstly, a threat-assessment model for attacking missiles is built based on the approach of Analytic Hierarchy Process (AHP). Meanwhile, an entropy method, used for evaluating the differences of target attributes, is introduced, to increase objective in computing threat-assessment results. Then, an assignment criterion of maximum intercept probability is designed based on assess results, and a multi-steps WTA decision model is built in DQN frame. A uniform experience sampling strategy is designed, making sure that each target type of assignment experience has the same probability to be selected. Furthermore, for balancing the DQN convergence speed and global optimum, a reward function that combines local and global rewards is designed. Lastly, simulation results shows that the proposed WTA approach has the advantage in solving large-scale WTA problem fast and effectively, compared with the general heuristic approach. Also, it presents the robust performance for WTA scenario elements variation.
-
表 1 目标属性值
编号 攻击地
重要度剩余飞行
时间(s)最大高度
(km)关机点
速度(km/s)RCS
(m2)1 4 220 260 2.3 0.007 2 9 250 225 2.1 0.005 3 4 530 630 4.2 0.012 4 2 550 680 4.8 0.013 5 6 240 235 2.2 0.010 6 2 610 710 5.1 0.015 7 1 1200 1600 6.8 0.017 8 0 1120 1450 6.6 0.016 9 2 1400 75 7.4 0.006 10 3 1500 78 7.1 0.007  下载: 导出CSV
下载: 导出CSV
表 2 传统和改进AHP方法的评估指标权重计算结果对比
攻击地
重要度剩余飞行
时间(s)最大高度
(km)关机点
速度(km/s)RCS
(m2)传统AHP 0.34 0.27 0.08 0.12 0.19 改进AHP 0.44 0.17 0.16 0.13 0.10
下载: 导出CSV
表 3 改进AHP与传统AHP法的目标威胁度评估结果
编号 8 7 9 4 6 改进AHP法 0.125 0.119 0.111 0.107 0.106 传统AHP法 0.115 0.110 0.104 0.107 0.106 编号 10 3 1 5 2 改进AHP法 0.104 0.095 0.091 0.078 0.060 传统AHP法 0.099 0.097 0.097 0.088 0.075
下载: 导出CSV
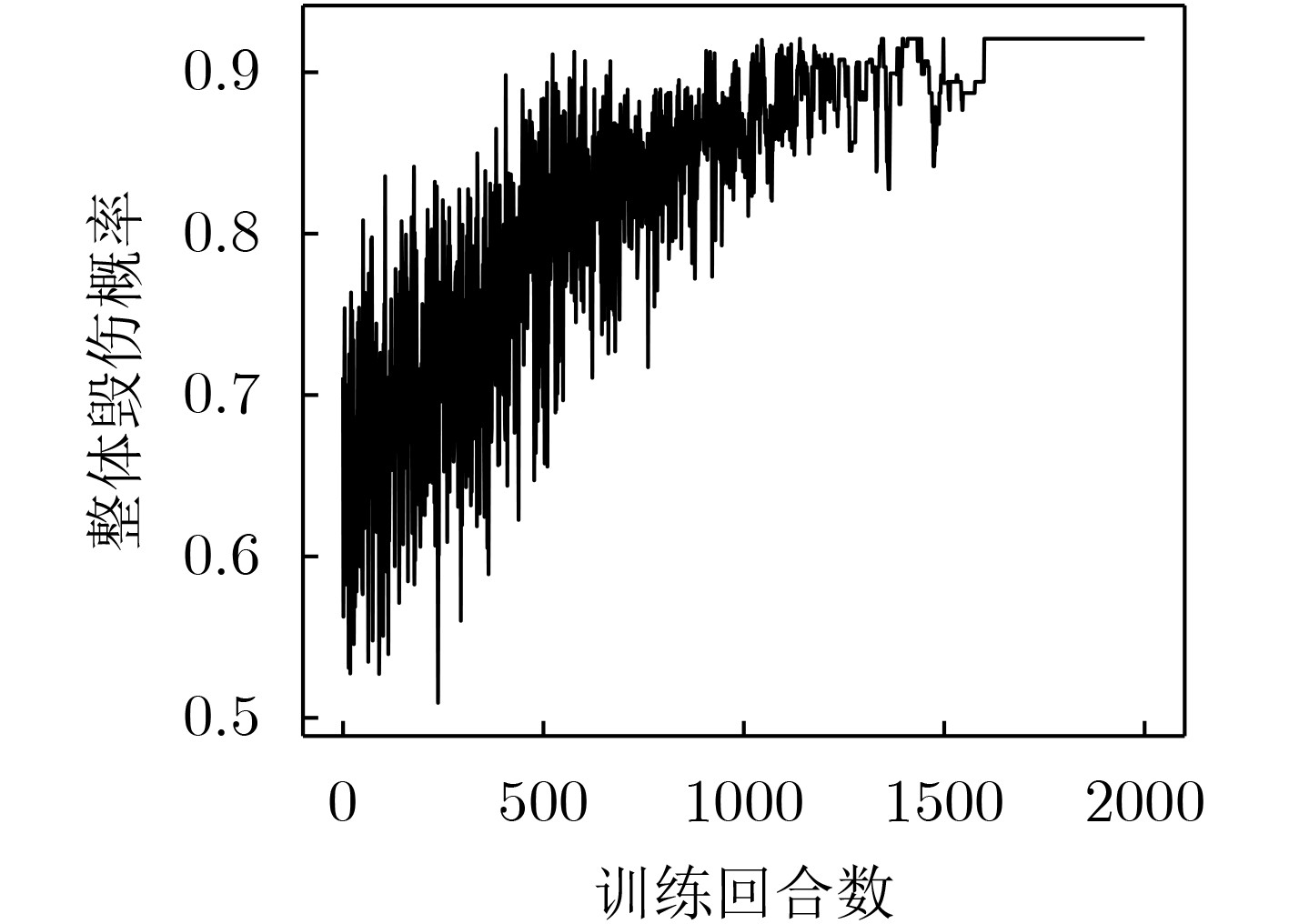
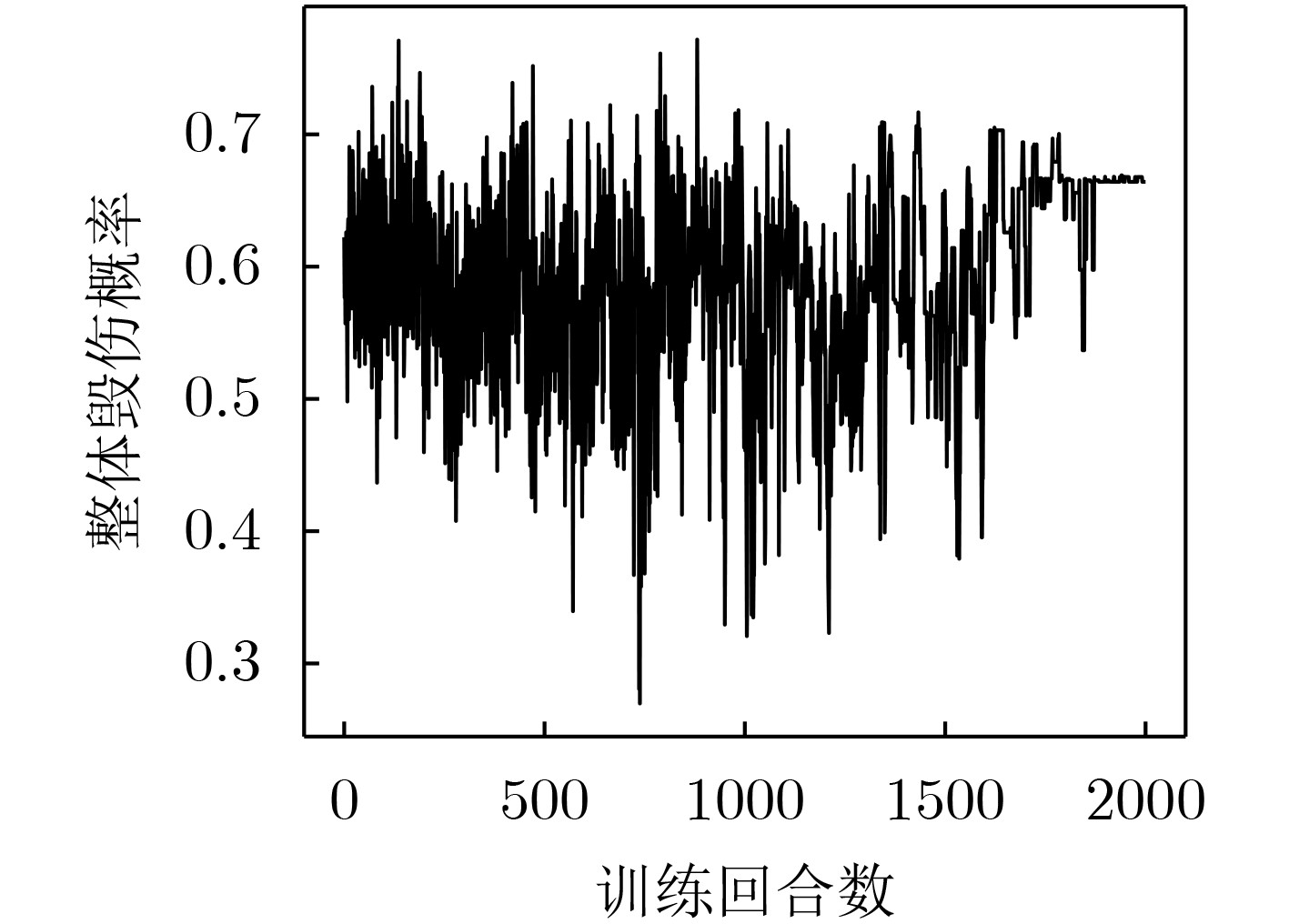
表 5 3种场景测试结果
指标 测试用例编号 分配方案求解方法 DQN PSO 随机法 整体毁伤概率 #1 0.921 0.982 0.620 #2 0.918 0.907 0.590 #3 0.856 0.758 0.540 运行时间(s) #1 0.050 22.001 0.001 #2 0.170 62.021 0.003 #3 0.220 137.000 0.019
下载: 导出CSV
-
[1] KLINE A, AHNER D, and HILL R. The weapon-target assignment problem[J]. Computers & Operations Research, 2019, 105: 226–236. doi: 10.1016/j.cor.2018.10.015 [2] YUE Jiao and ZHANG Ke. Vulnerability Threat assessment based on AHP and fuzzy comprehensive evaluation[C]. 2014 IEEE Seventh International Symposium on Computational Intelligence and Design, Hangzhou, China, 2014: 513–516. [3] 杨罗章, 胡生亮, 冯士民. 基于Entropy-TOPSIS方法的目标威胁动态评估与仿真[J]. 兵工自动化, 2020, 39(3): 53–56,60. doi: 10.7690/bgzdh.2020.03.012YANG Luozhang, HU Shengliang, and FENG Shimin. Dynamic evaluation and simulation of targets threat based on entropy and TOPSIS method[J]. Ordnance Industry Automation, 2020, 39(3): 53–56,60. doi: 10.7690/bgzdh.2020.03.012 [4] 陈龙, 马亚平. 基于分层贝叶斯网络的航母编队对潜威胁评估[J]. 系统仿真学报, 2017, 29(9): 2206–2212,2220. doi: 10.16182/j.issn1004731x.joss.201709044CHEN Long and MA Yaping. Threat assessment of aircraft carrier formation based on hierarchical Bayesian network[J]. Journal of System Simulation, 2017, 29(9): 2206–2212,2220. doi: 10.16182/j.issn1004731x.joss.201709044 [5] 杨爱武, 李战武, 徐安, 等. 基于RS-CRITIC的空战目标威胁评估[J]. 北京航空航天大学学报, 2020, 46(12): 2357–2365. doi: 10.13700/j.bh.1001-5965.2019.0638YANG Aiwu, LI Zhanwu, XU An, et al. Threat assessment of air combat target based on RS-CRITIC[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(12): 2357–2365. doi: 10.13700/j.bh.1001-5965.2019.0638 [6] LLOYD S P and WITSENHAUSE H S. Weapon allocation is NP-Complete[C]. The IEEE Summer Simulation Conference, Reno, USA, 1986: 1054–1058. [7] 王邑, 孙金标, 肖明清, 等. 基于类型2区间模糊K近邻分类器的动态武器目标分配方法研究[J]. 系统工程与电子技术, 2016, 38(6): 1314–1319. doi: 10.3969/j.issn.1001-506X.2016.06.15WANG Yi, SUN Jinbiao, XIAO Mingqing, et al. Research of dynamic weapon-target assignment problem based on type-2 interval fuzzy K-nearest neighbors classifier[J]. Systems Engineering and Electronics, 2016, 38(6): 1314–1319. doi: 10.3969/j.issn.1001-506X.2016.06.15 [8] 王净, 战凯, 晏峰. 基于动态规划算法的舰空导弹火力分配模型研究[J]. 舰船电子工程, 2011, 31(2): 24–26. doi: 10.3969/j.issn.1627-9730.2011.02.007WANG Jing, ZHAN Kai, and YAN Feng. Ship-to-air missile firepower-distributing model study based on dynamic programming algorithm[J]. Ship Electronic Engineering, 2011, 31(2): 24–26. doi: 10.3969/j.issn.1627-9730.2011.02.007 [9] 丁立超, 黄枫, 潘伟. 基于改进混沌遗传算法的炮兵火力分配方法[J]. 系统仿真技术, 2021, 17(1): 12–16. doi: 10.16812/j.cnki.cn31-1945.2021.01.003DING Lichao, HUANG Feng, and PAN Wei. Artillery fire allocation method based on improved chaotic genetic algorithm[J]. System Simulation Technology, 2021, 17(1): 12–16. doi: 10.16812/j.cnki.cn31-1945.2021.01.003 [10] 李俨, 董玉娜. 基于SA-DPSO混合优化算法的协同空战火力分配[J]. 航空学报, 2010, 31(3): 626–631.LI Yan and DONG Yu’na. Weapon-target assignment based on simulated annealing and discrete particle swarm optimization in cooperative air combat[J]. Acta Aeronautica et Astronautica Sinica, 2010, 31(3): 626–631. [11] SILVER D, SCHRITTWIESER J, SIMONYAN K, et al. Mastering the game of Go without human knowledge[J]. Nature, 2017, 550(7676): 354–359. doi: 10.1038/nature24270 [12] ZHU Yuke, MOTTAGHI R, KOLVE E, et al. Target-driven visual navigation in indoor scenes using deep reinforcement learning[C]. 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 2017: 3357–3364. [13] 施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610–1623. doi: 10.16383/j.aas.c201059SHI Wei, FENG Yanghe, CHENG Guangquan, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning[J]. Acta Automatica Sinica, 2021, 47(7): 1610–1623. doi: 10.16383/j.aas.c201059 [14] 阎栋, 苏航, 朱军. 基于DQN的反舰导弹火力分配方法研究[J]. 导航定位与授时, 2019, 6(5): 18–24. doi: 10.19306/j.cnki.2095-8110.2019.05.003YAN Dong, SU Hang, and ZHU Jun. Research on fire distribution method of anti-ship missile based on DQN[J]. Navigation Positioning and Timing, 2019, 6(5): 18–24. doi: 10.19306/j.cnki.2095-8110.2019.05.003 [15] ZHU Yuxin, TIAN Dazuo, and YAN Feng. Effectiveness of entropy weight method in decision-making[J]. Mathematical Problems in Engineering, 2020, 2020: 3564835. doi: 10.1155/2020/3564835 [16] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. doi: 10.1038/nature14236 -

 下载:
下载:

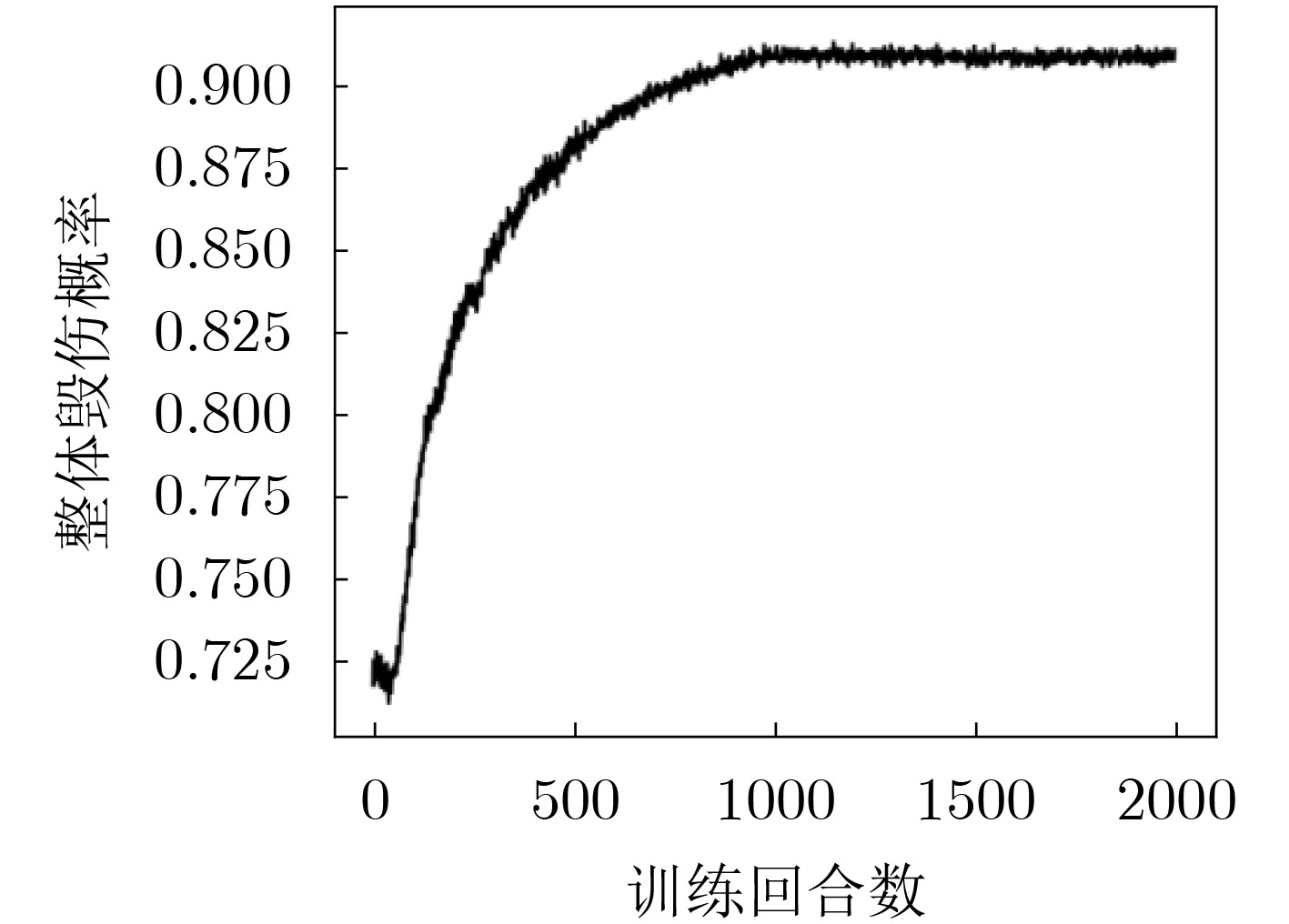


图(6) / 表(5)
计量
- 文章访问数: 2567
- HTML全文浏览量: 1313
- PDF下载量: 191
- 被引次数: 0
