

Cross-modal Video Moment Retrieval Based on Enhancing Significant Features
-
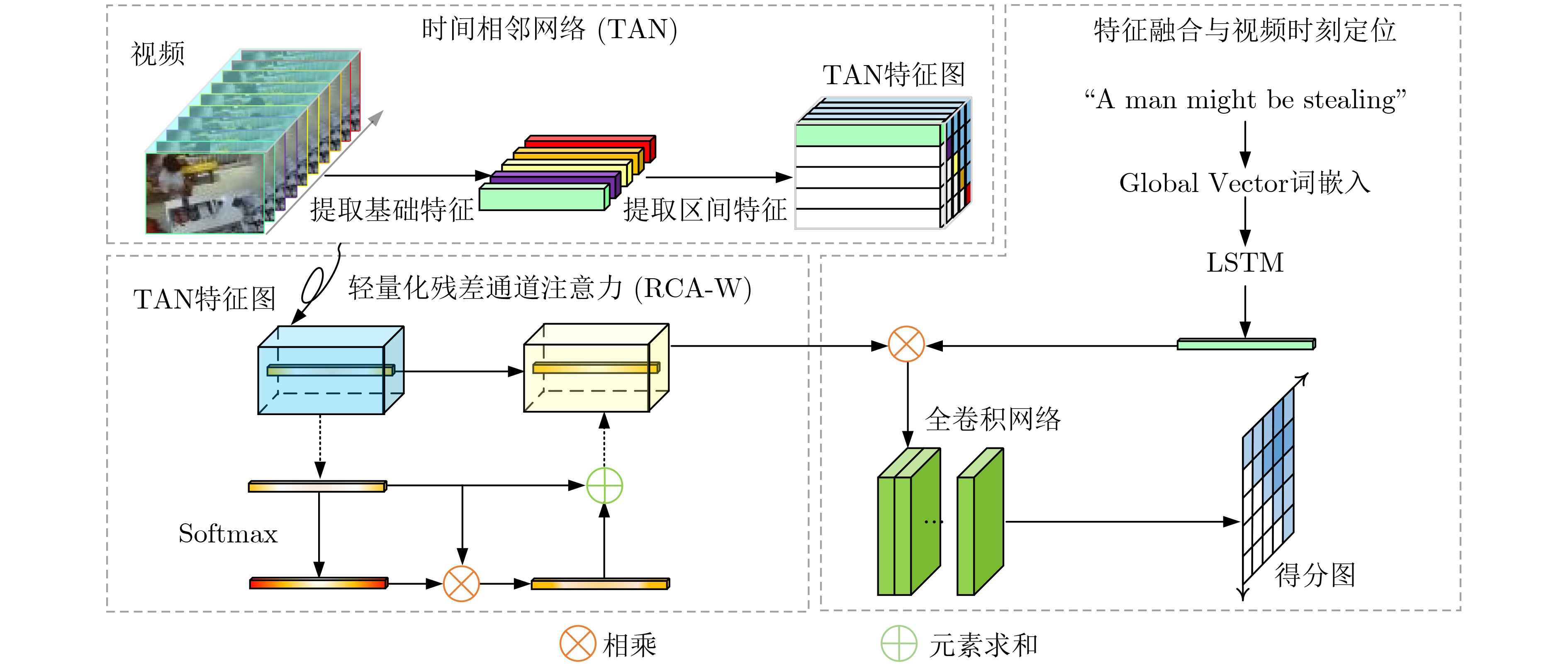
摘要: 随着视频获取设备和技术的不断发展,视频数量增长快速,在海量视频中精准查找目标视频片段是具有挑战的任务。跨模态视频片段检索旨在根据输入一段查询文本,模型能够从视频库中找出符合描述的视频片段。现有的研究工作多是关注文本与候选视频片段的匹配,忽略了视频上下文的“语境”信息,在视频理解时,存在对特征关系表达不足的问题。针对此,该文提出一种基于显著特征增强的跨模态视频片段检索方法,通过构建时间相邻网络学习视频的上下文信息,然后使用轻量化残差通道注意力突出视频片段的显著特征,提升神经网络对视频语义的理解能力。在公开的数据集TACoS和ActivityNet Captions的实验结果表明,该文所提方法能更好地完成视频片段检索任务,比主流的基于匹配的方法和基于视频-文本特征关系的方法取得了更好的表现。Abstract: With the continuous development of video acquisition equipment and technology, the number of videos has grown rapidly. It is a challenging task in video retrieval to find target video moments accurately in massive videos. Cross-modal video moment retrieval is to find a moment matching the query from the video database. Existing works focus mostly on matching the text with the moment, while ignoring the context content in the adjacent moment. As a result, there exists the problem of insufficient expression of feature relation. In this paper, a novel moment retrieval network is proposed, which highlights the significant features through residual channel attention. At the same time, a temporal adjacent network is designed to capture the context information of the adjacent moment. Experimental results show that the proposed method achieves better performance than the mainstream candidate matching based and video-text features relation based methods.
-
表 1 SFEN在TACoS数据集上的召回率
方法 Rank@1 Rank@5 IoU=0.1 IoU=0.3 IoU=0.5 IoU=0.1 IoU=0.3 IoU=0.5 LTAN[3] 20.4 15.4 9.9 45.6 31.2 20.1 CTRL[1] 24.3 18.3 13.3 48.7 36.7 25.4 ACL[2] 31.6 24.2 20.0 57.9 42.2 30.7 ABLR[8] 34.7 19.5 9.4 – – – DORi[11] – 31.8 28.7 – – – ACRN[5] 24.2 19.5 14.6 47.4 35.0 24.9 CMHN[30] – 31.0 26.2 – 46.0 36.7 QSPN[12] 25.3 20.2 15.2 53.2 36.7 25.3 IIN-C3D[6] – 31.5 29.3 – 52.7 46.1 ExCL[9] – 45.5 28.0 – – – 2D-TAN[4] 47.6 37.3 25.3 70.3 57.8 45.0 本文SFEN 56.2 47.3 36.1 79.8 69.5 58.1  下载: 导出CSV
下载: 导出CSV
表 2 SFEN在ActivityNet Captions数据集上的召回率
方法 Rank@1 Rank@5 IoU=0.3 IoU=0.5 IoU=0.7 IoU=0.3 IoU=0.5 IoU=0.7 DORi[11] 57.9 41.3 26.4 – – – CTRL[1] 47.4 29.0 10.3 75.3 59.2 37.5 ACRN[5] 49.7 31.7 11.3 76.5 60.3 38.6 MABAN[10] – 42.4 24.3 – – – CMHN[30] 62.5 43.5 24.0 85.4 73.4 53.2 QSPN[12] 52.1 33.3 13.4 77.7 62.4 40.8 TripNet[7] 48.4 32.2 13.9 – – – ExCL[9] 63.0 43.6 23.6 – – – 2D-TAN[4] 59.5 44.5 26.5 85.5 77.1 62.0 本文SFEN 59.9 45.6 28.7 85.5 77.3 63.0
下载: 导出CSV
表 3 SFEN的消融实验结果
TACoS数据集(Rank@1) ActivityNet Captions数据集(Rank@1) CIoU RCA-W $ \mathcal{R} $ IoU=0.1 IoU=0.3 IoU=0.5 IoU=0.7 IoU=0.1 IoU=0.3 IoU=0.5 IoU=0.7 √ √ √ 56.2 47.3 36.1 20.3 77.1 59.9 45.6 28.7 √ √ × 55.2 44.1 33.6 20.0 76.8 56.5 41.0 27.1 √ × √ 53.9 44.0 33.2 18.1 76.4 58.4 44.2 28.4 × √ √ 55.9 45.7 34.1 17.7 77.4 58.7 44.1 26.3
下载: 导出CSV
表 4 SFEN的时间复杂度和计算量
模块 时间复杂度 计算量(G) 时间相邻网络 $ O({K^2} \times {C_{{\text{in}}}} \times {C_{{\text{out}}}} \times N) $ 4.27 轻量化残差通道注意力 $ O({C_{{\text{in}}}} \times N) $ 0.02 特征融合与视频时刻定位 $ O(Z \times {K^2} \times {C_{{\text{in}}}} \times {C_{{\text{out}}}} \times N) $ 270.66
下载: 导出CSV
表 5 SFEN使用不同的注意力模型在TACoS数据集上的对比结果
方法 Rank@1 Rank@5 推理时间(s) 模型大小(M) 计算量(G) IoU=0.1 IoU=0.3 IoU=0.5 IoU=0.1 IoU=0.3 IoU=0.5 baseline[4] 47.6 36.1 25.3 70.3 57.8 45.0 0.151 731.0 F=274.93 Non-local[21] 52.5 41.1 28.9 75.2 61.5 48.7 0.178 735.3 F+8.54 SE[17] 49.2 37.5 25.4 76.2 63.3 50.1 0.550 737.4 F+4.27 RCA[19] 53.2 43.3 32.6 77.6 63.7 52.6 0.565 734.3 F+8.55 ECA[20] 53.5 42.4 30.4 74.9 63.6 50.3 0.452 731.1 F+0.05 本文RCA-W 56.2 47.3 36.1 79.8 69.5 58.1 0.153 731.1 F+0.02
下载: 导出CSV
-
[1] GAO Jiyang, SUN Chen, YANG Zhenheng, et al. TALL: Temporal activity localization via language query[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5277–5285. [2] GE Runzhou, GAO Jiyang, CHEN Kan, et al. MAC: Mining activity concepts for language-based temporal localization[C]. 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2019: 245–253. [3] LIU Meng, WANG Xiang, NIE Liqiang, et al. Cross-modal moment localization in videos[C]. The 26th ACM International Conference on Multimedia, Seoul, Korea, 2018: 843–851. [4] ZHANG Songyang, PENG Houwen, FU Jianlong, et al. Learning 2D temporal adjacent networks for moment localization with natural language[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12870–12877. [5] LIU Meng, WANG Xiang, NIE Liqiang, et al. Attentive moment retrieval in videos[C]. The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, USA, 2018: 15–24. [6] NING Ke, XIE Lingxi, LIU Jianzhuang, et al. Interaction-integrated network for natural language moment localization[J]. IEEE Transactions on Image Processing, 2021, 30: 2538–2548. doi: 10.1109/TIP.2021.3052086 [7] HAHN M, KADAV A, REHG J M, et al. Tripping through time: Efficient localization of activities in videos[C]. The 31st British Machine Vision Conference, Manchester, UK, 2020. [8] YUAN Yitian, MEI Tao, and ZHU Wenwu. To find where you talk: Temporal sentence localization in video with attention based location regression[C]. The 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 9159–9166. [9] GHOSH S, AGARWAL A, PAREKH Z, et al. ExCL: Extractive clip localization using natural language descriptions[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019: 1984–1990. [10] SUN Xiaoyang, WANG Hanli, and HE Bin. MABAN: Multi-agent boundary-aware network for natural language moment retrieval[J]. IEEE Transactions on Image Processing, 2021, 30: 5589–5599. doi: 10.1109/TIP.2021.3086591 [11] RODRIGUEZ-OPAZO C, MARRESE-TAYLOR E, FERNANDO B, et al. DORi: Discovering object relationships for moment localization of a natural language query in a video[C]. 2021 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2021. [12] XU Huijuan, HE Kun, PLUMMER B A, et al. Multilevel language and vision integration for text-to-clip retrieval[C]. The 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 9062–9069. [13] TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4489–4497. [14] HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735 [15] CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation[C]. 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1724–1734. [16] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [17] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. [18] WOO S, PARK J, LEE J, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. [19] ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 294–310. [20] WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020. [21] WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803. [22] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [23] ZHENG Zhaohui, WANG Ping, LIU Wei, et al. Distance-IoU Loss: Faster and better learning for bounding box regression[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12993–13000. [24] ZHENG Zhaohui, WANG Ping, REN Dongwei, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics, 2022, 52(8): 8574–8586. [25] REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 658–666. [26] REGNERI M, ROHRBACH M, WETZEL D, et al. Grounding action descriptions in videos[J]. Transactions of the Association for Computational Linguistics, 2013, 1: 25–36. doi: 10.1162/tacl_a_00207 [27] KRISHNA R, HATA K, REN F, et al. Dense-captioning events in videos[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 706–715. [28] ROHRBACH M, REGNERI M, ANDRILUKA M, et al. Script data for attribute-based recognition of composite activities[C]. The 12th European Conference on Computer Vision, Florence, Italy, 2012: 144–157. [29] ZHANG Da, DAI Xiyang, WANG Xin, et al. MAN: Moment alignment network for natural language moment retrieval via iterative graph adjustment[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019. [30] PENNINGTON J, SOCHER R, and MANNING C. GloVe: Global vectors for word representation[C]. 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1532–1543. [31] HU Yupeng, LIU Meng, SUN Xiaobin, et al. Video moment localization via deep cross-modal hashing[J]. IEEE Transactions on Image Processing, 2021, 30: 4667–4677. doi: 10.1109/TIP.2021.3073867 -

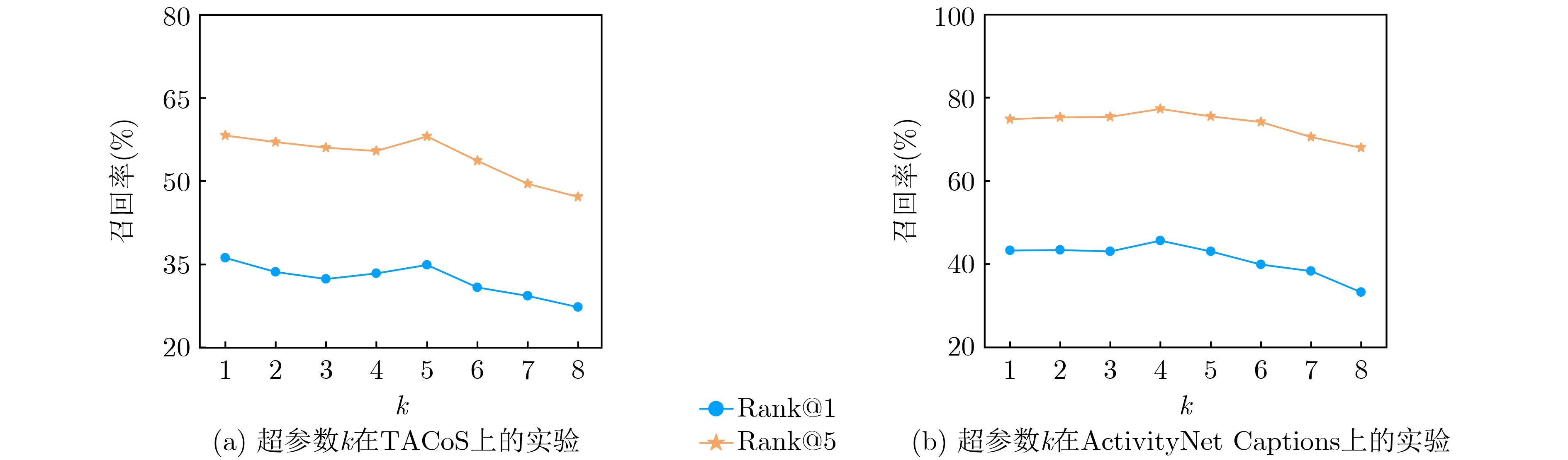
 下载:
下载:





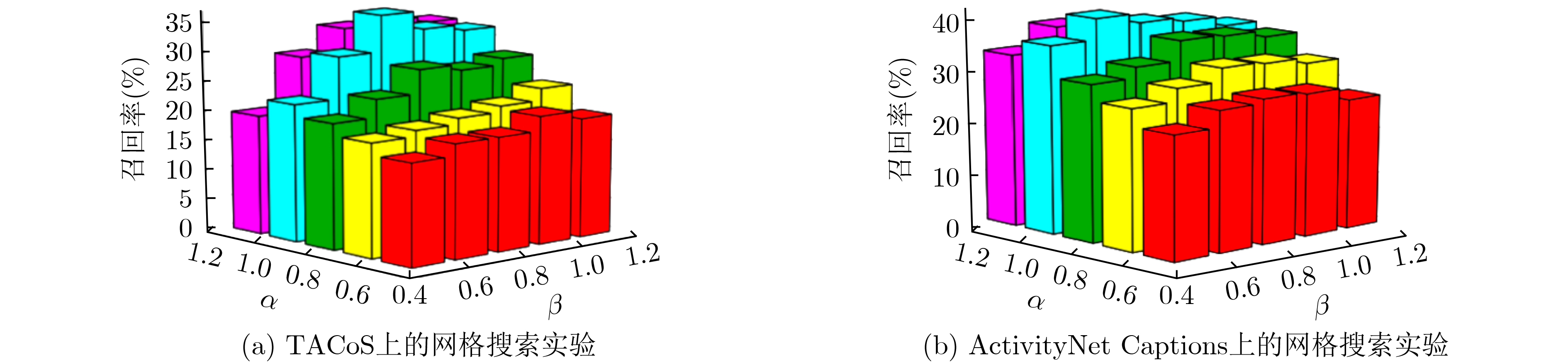





图(8) / 表(5)
计量
- 文章访问数: 1254
- HTML全文浏览量: 856
- PDF下载量: 119
- 被引次数: 0
