

6D Pose Estimation Network in Complex Point Cloud Scenes
-
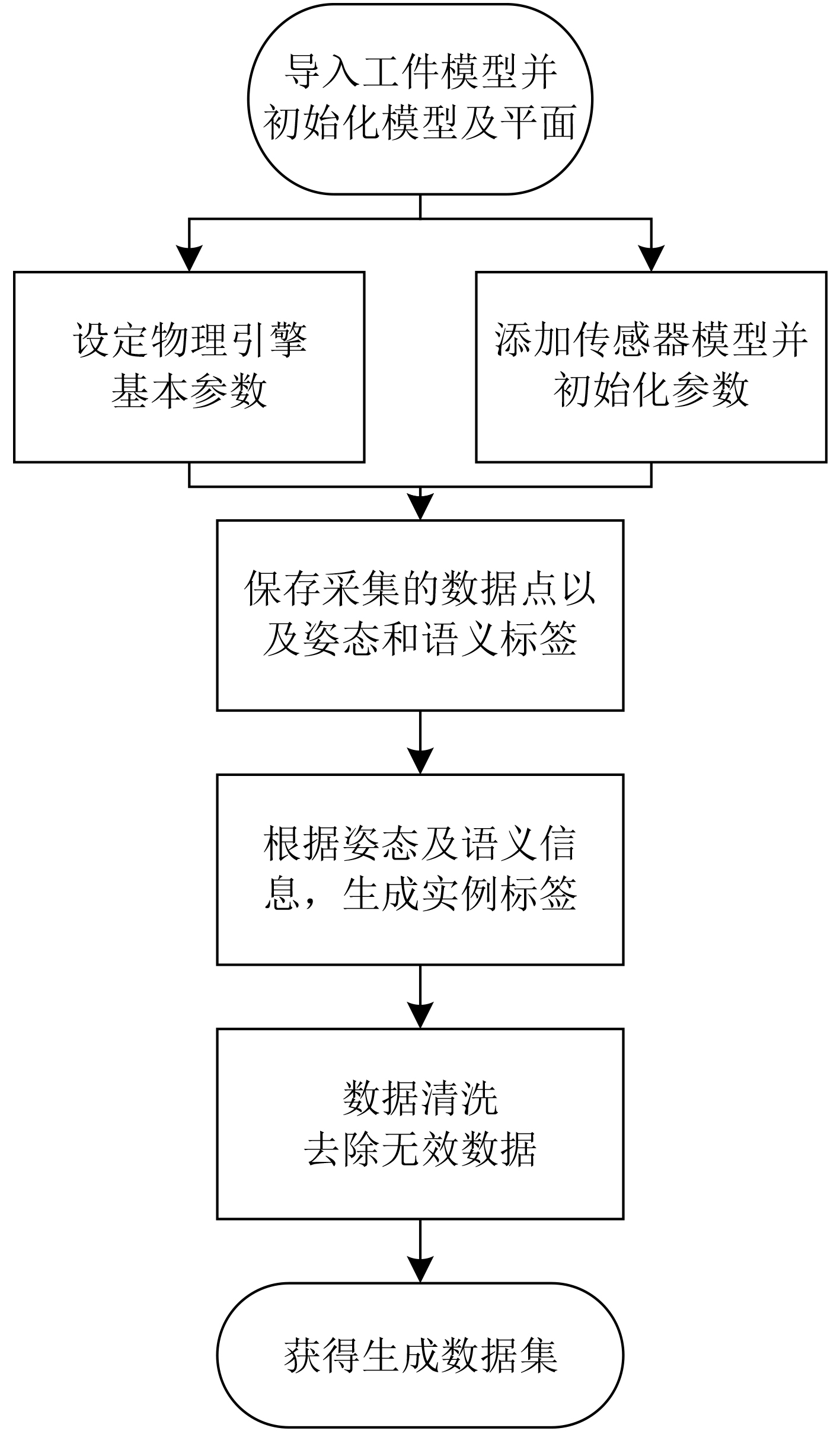
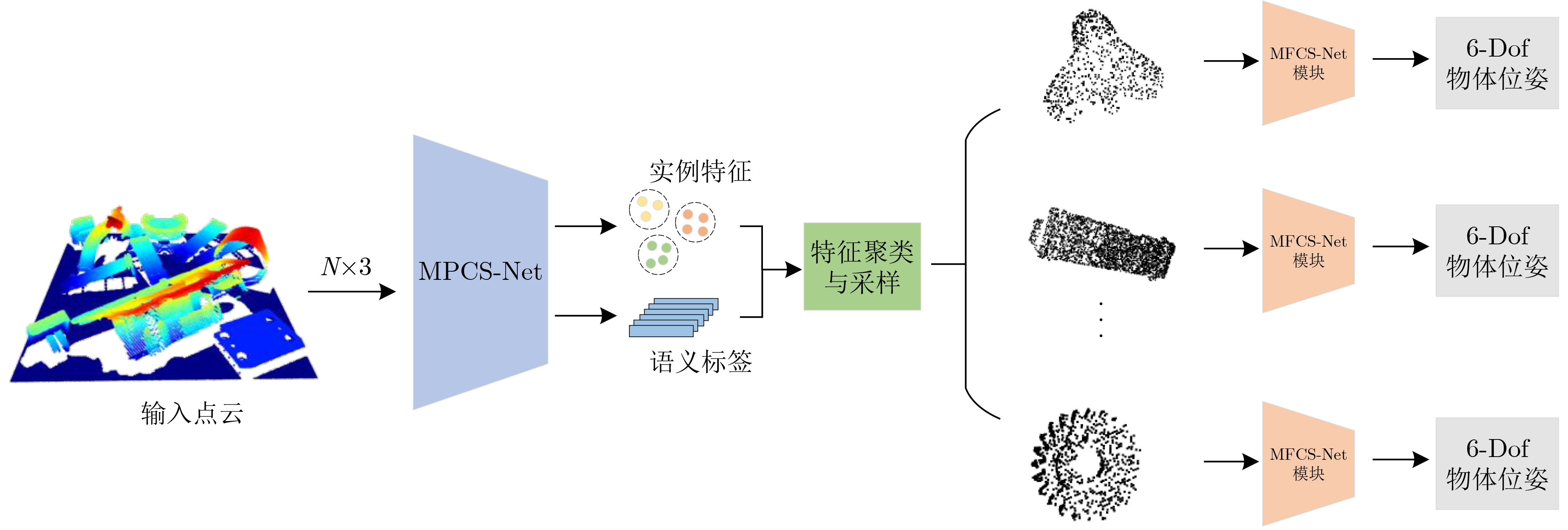
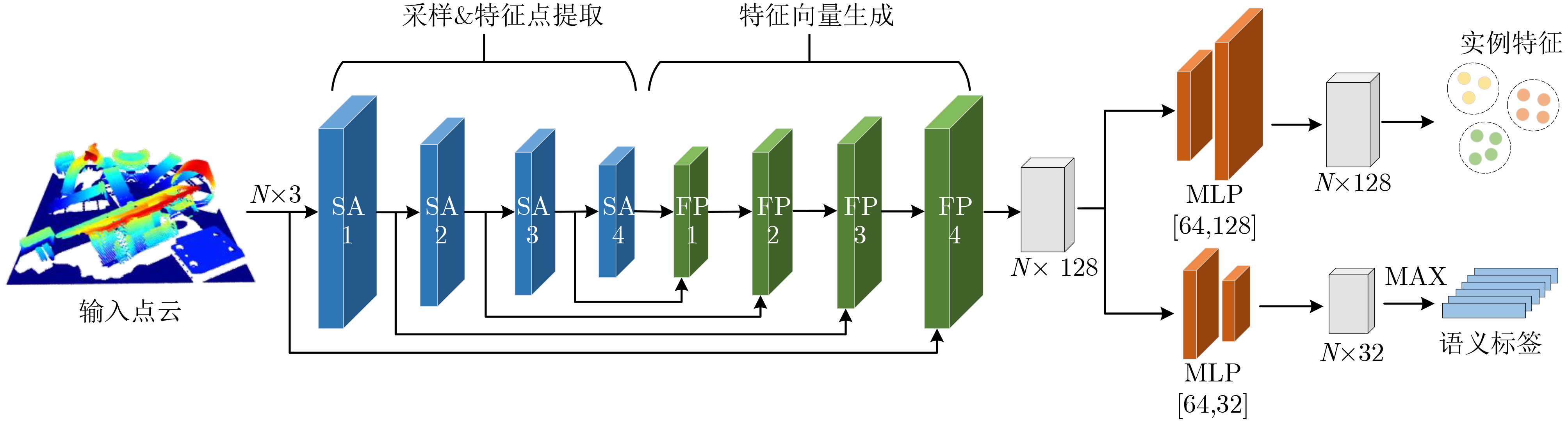
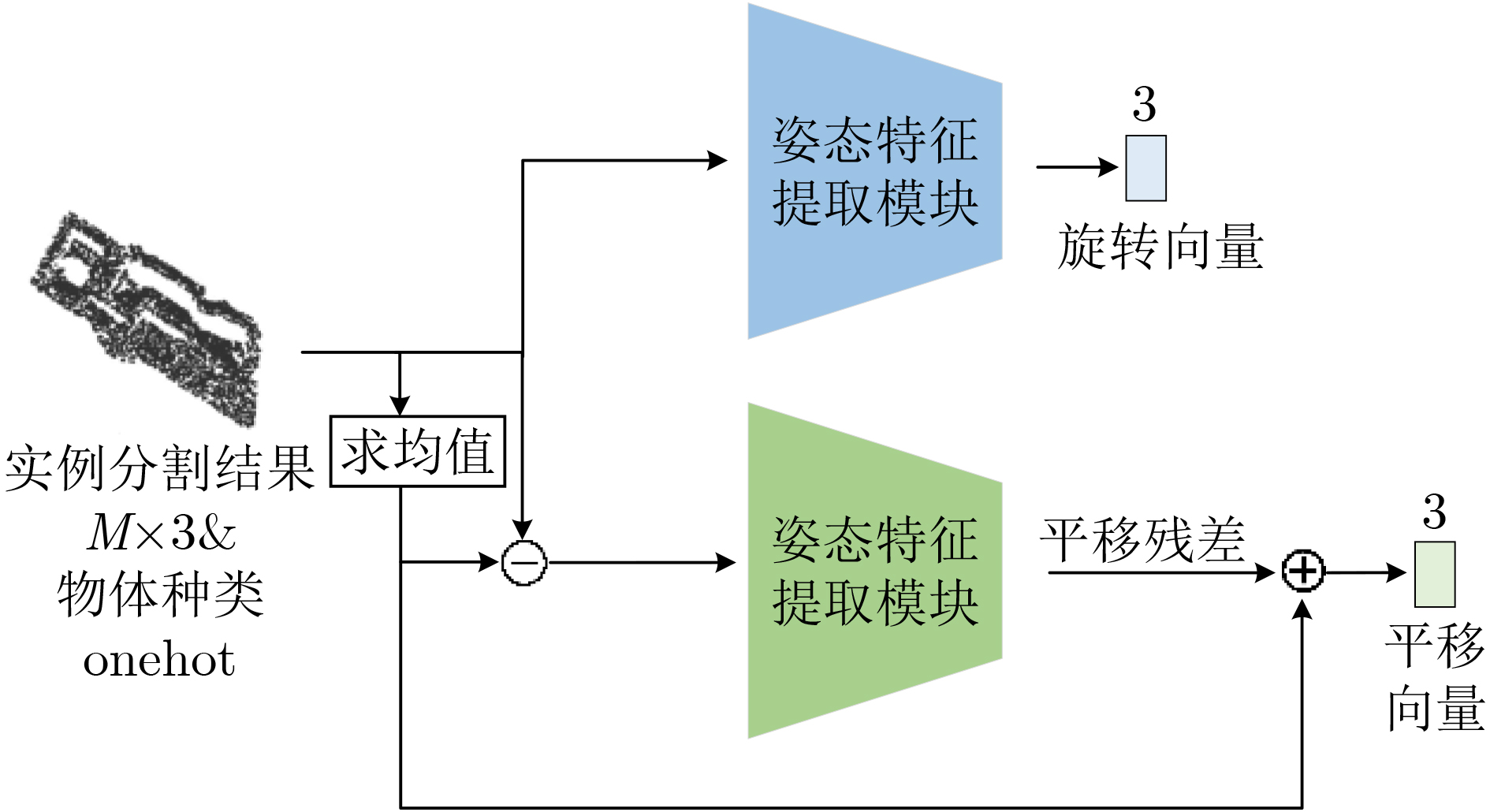
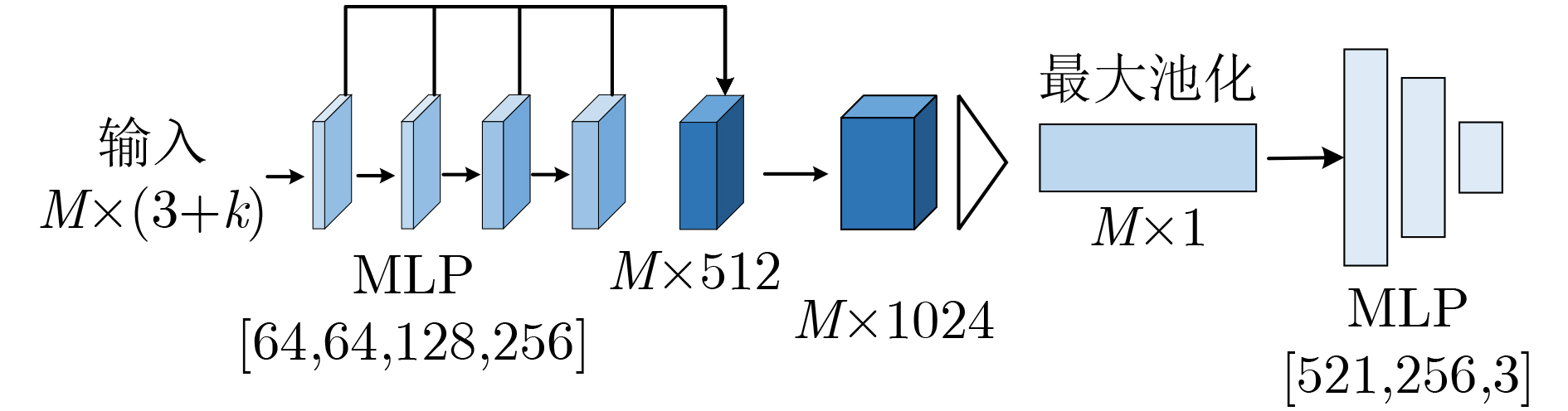
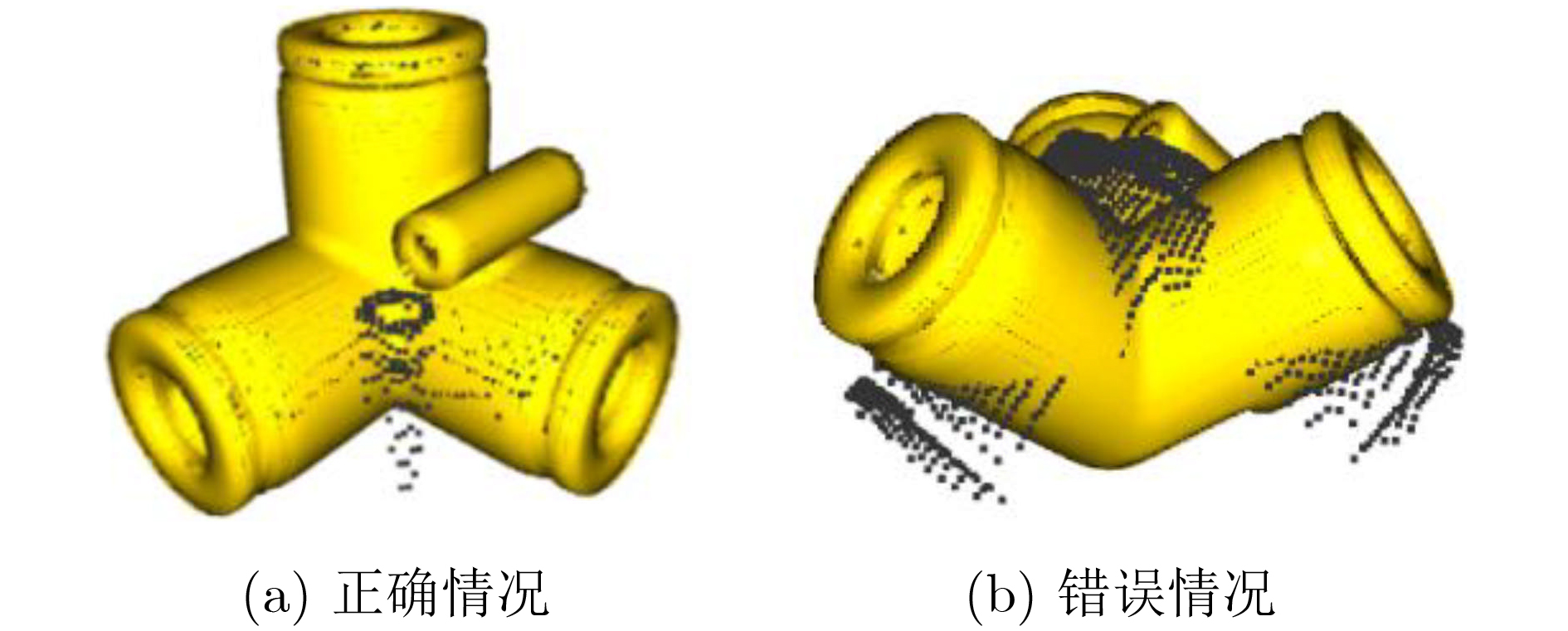
摘要: 针对工业上常见的弱纹理、散乱摆放复杂场景下点云目标机器人抓取问题,该文提出一种6D位姿估计深度学习网络。首先,模拟复杂场景下点云目标多姿态随机摆放的物理环境,生成带真实标签的数据集;进而,设计了6D位姿估计深度学习网络模型,提出多尺度点云分割网络(MPCS-Net),直接在完整几何点云上进行点云实例分割,解决了对RGB信息和点云分割预处理的依赖问题。然后,提出多层特征姿态估计网(MFPE-Net),有效地解决了对称物体的位姿估计问题。最后,实验结果和分析证实了,相比于传统的点云配准方法和现有的切分点云的深度学习位姿估计方法,所提方法取得了更高的准确率和更稳定性能,并且在估计对称物体位姿时有较强的鲁棒性。Abstract: Focusing on the robot grasping problem of point cloud targets in complex scenes with weak texture and scattered placement, a 6D pose estimation deep learning network is proposed. First, the complex scenes of the physical environment are simulated, where point cloud targets are randomly placed in multiple poses to generate a dataset with real labels; Further, a 6D pose estimation deep learning network model is designed, and a Multiscale Point Cloud Segmentation Net (MPCS-Net) is proposed to segment point cloud instances directly on the complete geometric point cloud, solving the dependence on RGB information and point cloud segmentation pre-processing. Then, the Multilayer Feature Pose Estimation Net (MFPE-Net) is proposed, which addresses effectively the pose estimation problem of symmetrical objects. Finally, the experimental results and analysis confirm that, compared with the traditional point cloud registration methods and the existing deep learning pose estimation methods of the segmented point cloud, the proposed method achieves higher accuracy and more stable performance. The preferable robustness in estimating the pose of symmetrical objects also proves its efficacy.
-
Key words:
- Point clouds /
- Deep learning /
- Pose estimation
-
表 1 训练基本配置表
配置项目 项目值 配置项目 项目值 数据集总量 10000个 平均点距(水平) 1 mm 单场景物体数 4~7个 优化器 SGD 训练集数量 9000个 训练迭代次数 500 测试集数量 1000个 BatchSize 16 初始学习率 0.01 学习率衰减步数 50  下载: 导出CSV
下载: 导出CSV
表 2 语义分割精度(%)和平均时间(s)
方法 精度(%) 平均时间(s) 物体A 物体B 物体C 物体D 物体E 物体F 物体G PointNet++ 82.93 0.286 86.74 80.23 83.33 78.53 83.51 85.74 88.73 MT-PNet 89.79 0.305 89.74 87.97 84.69 92.42 88.05 87.21 95.50 MV-CRF 91.03 2.973 91.27 92.03 89.65 89.02 92.78 89.95 94.47 本文 99.02 0.324 98.79 99.28 98.99 98.93 98.61 98.97 99.67
下载: 导出CSV
表 3 实例分割精度(%)和平均时间(s)
方法 精度(%) 平均时间(s) 物体A 物体B 物体C 物体D 物体E 物体F 物体G MT-PNet 80.84 4.973 78.87 75.55 83.48 86.99 75.06 87.85 84.25 MV-CRF 84.45 8.934 83.03 80.21 85.77 88.96 80.57 89.11 89.48 本文 94.35 5.312 92.74 96.85 93.53 95.06 94.67 93.83 93.51
下载: 导出CSV
表 4 不同实例聚类方法精度(%)
方法 精度(%) 物体A 物体B 物体C 物体D 物体E 物体F 物体G HAC 72.05 54.87 83.68 72.08 75.06 78.84 67.19 79.48 DBSCAN 89.75 83.51 92.06 94.05 80.83 85.47 92.59 90.64 MeanShift 94.35 92.74 96.85 93.53 95.06 94.67 93.83 93.51
下载: 导出CSV
表 5 姿态估计精度(%)
FPFH+ICP PPF+ICP CloudPose+ICP 本文+ICP AD AD-S AD AD-S AD AD-S AD AD-S 物体A 88.13 99.88 97.72 99.77 88.53 97.21 98.32 100 物体B 77.86 96.47 71.67 72.07 85.82 93.66 96.30 97.68 物体C 61.02 96.36 93.17 99.80 71.86 96.73 96.51 98.91 物体D 87.83 97.23 98.04 98.54 97.53 98.36 97.85 99.25 物体E 3.72 94.82 10.89 99.02 12.54 96.73 12.24 99.08 物体F 48.17 97.80 42.44 99.21 53.36 92.63 49.56 98.91 物体G 28.04 96.54 23.82 96.76 32.02 91.36 17.07 97.25
下载: 导出CSV
-
[1] ASTANIN S, ANTONELLI D, CHIABERT P, et al. Reflective workpiece detection and localization for flexible robotic cells[J]. Robotics and Computer-Integrated Manufacturing, 2017, 44: 190–198. doi: 10.1016/j.rcim.2016.09.001 [2] RUSU R B, BLODOW N, and BEETZ M. Fast point feature histograms (FPFH) for 3D registration[C]. 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 2009: 3212–3217. [3] SALTI S, TOMBARI F, and DI STEFANO L. SHOT: Unique signatures of histograms for surface and texture description[J]. Computer Vision and Image Understanding, 2014, 125(8): 251–264. doi: 10.1016/j.cviu.2014.04.011 [4] DROST B, ULRICH M, NAVAB N, et al. Model globally, match locally: Efficient and robust 3D object recognition[C]. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, USA, 2010: 998–1005. [5] BIRDAL T and ILIC S. Point pair features based object detection and pose estimation revisited[C]. 2015 International Conference on 3D Vision, Lyon, France, 2015: 527–535. [6] TANG Keke, SONG Peng, and CHEN Xiaoping. 3D object recognition in cluttered scenes with robust shape description and correspondence selection[J]. IEEE Access, 2017, 5: 1833–1845. doi: 10.1109/ACCESS.2017.2658681 [7] HOLZ D, NIEUWENHUISEN M, DROESCHEL D, et al. Active Recognition and Manipulation for Mobile Robot Bin Picking[M]. RÖHRBEIN F, VEIGA G, NATALE C. Gearing Up and Accelerating Cross‐Fertilization Between Academic and Industrial Robotics Research in Europe. Cham: Springer, 2014: 133–153. [8] WU Chenghei, JIANG S Y, and SONG Kaitai. CAD-based pose estimation for random bin-picking of multiple objects using a RGB-D camera[C]. 2015 15th International Conference on Control, Automation and Systems (ICCAS), Busan, Korea (South), 2015: 1645–1649. [9] 高雪梅. 面向自动化装配的零件识别与抓取方位规划[D]. [硕士论文], 哈尔滨工业大学, 2018.GAO Xuemei. Research on Objects Recognition and Grasping Position Planning for Robot Automatic Assemblysensing [D]. [Master dissertation], Harbin Institute of Technology, 2018. [10] LYU Yecheng, HUANG Xinming, and ZHANG Ziming. Learning to segment 3D point clouds in 2D image space[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 12255–12264. [11] ZHOU Yin and TUZEL O. VoxelNet: End-to-end learning for point cloud based 3D object detection[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4490–4499. [12] QI C R, LIU Wei, WU Chenxia, et al. Frustum pointnets for 3D object detection from RGB-D data[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 918–927. [13] PHAM Q H, NGUYEN T, HUA B S, et al. JSIS3D: Joint semantic-instance segmentation of 3D point clouds with multi-task pointwise networks and multi-value conditional random fields[C].The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 8819–8828. [14] QI C R, SU Hao, MO Kaichun, et al. PointNet: Deep learning on point sets for 3D classification and segmentation[C]. Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 77–85. [15] GAO Ge, LAURI M, WANG Yulong, et al. 6D object pose regression via supervised learning on point clouds[C]. 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 2020: 3643–3649. [16] DU Guoguang, WANG Kai, LIAN Shiguo, et al. Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: A review[J]. Artificial Intelligence Review, 2021, 54(3): 1677–1734. doi: 10.1007/s10462-020-09888-5 [17] GSCHWANDTNER M, KWITT R, UHL A, et al. BlenSor: Blender sensor simulation toolbox[C]. International Symposium on Visual Computing, Las Vegas, USA, 2011: 199–208. [18] LU Qingkai, CHENNA K, SUNDARALINGAM B, et al. Planning Multi-fingered Grasps as Probabilistic Inference in a Learned Deep Network[M]. AMATO N, HAGER, G, THOMAS S, et al. Robotics Research. Cham: Springer, 2020: 455–472. [19] DE BRABANDERE B, NEVEN D, and VAN GOOL L. Semantic instance segmentation with a discriminative loss function[J]. arXiv preprint arXiv: 1708.02551, 2017. [20] KUHN H W. The Hungarian method for the assignment problem[J]. Naval Research Logistics, 2005, 52(1): 7–21. doi: 10.1002/nav.20053 [21] LIU Liyuan, JIANG Haoming, HE Pengcheng, et al. On the variance of the adaptive learning rate and beyond[J]. arXiv preprint arXiv: 1908.03265v1, 2019. [22] GAO Ge, LAURI M, ZHANG Jianwei, et al. Occlusion Resistant Object Rotation Regression from Point Cloud Segments[M]. LEAL-TAIXÉ L and ROTH S. European Conference on Computer Vision. Cham: Springer, 2018: 716–729. [23] HINTERSTOISSER S, LEPETIT V, ILIC S, et al. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes[C]. 11th Asian Conference on Computer Vision, Berlin, Germany, 2012: 548–562. -


 下载:
下载:








图(13) / 表(6)
计量
- 文章访问数: 2236
- HTML全文浏览量: 2447
- PDF下载量: 214
- 被引次数: 0
