

Single Image Dehazing Method Based on Multi-scale Features Combined with Detail Recovery
-
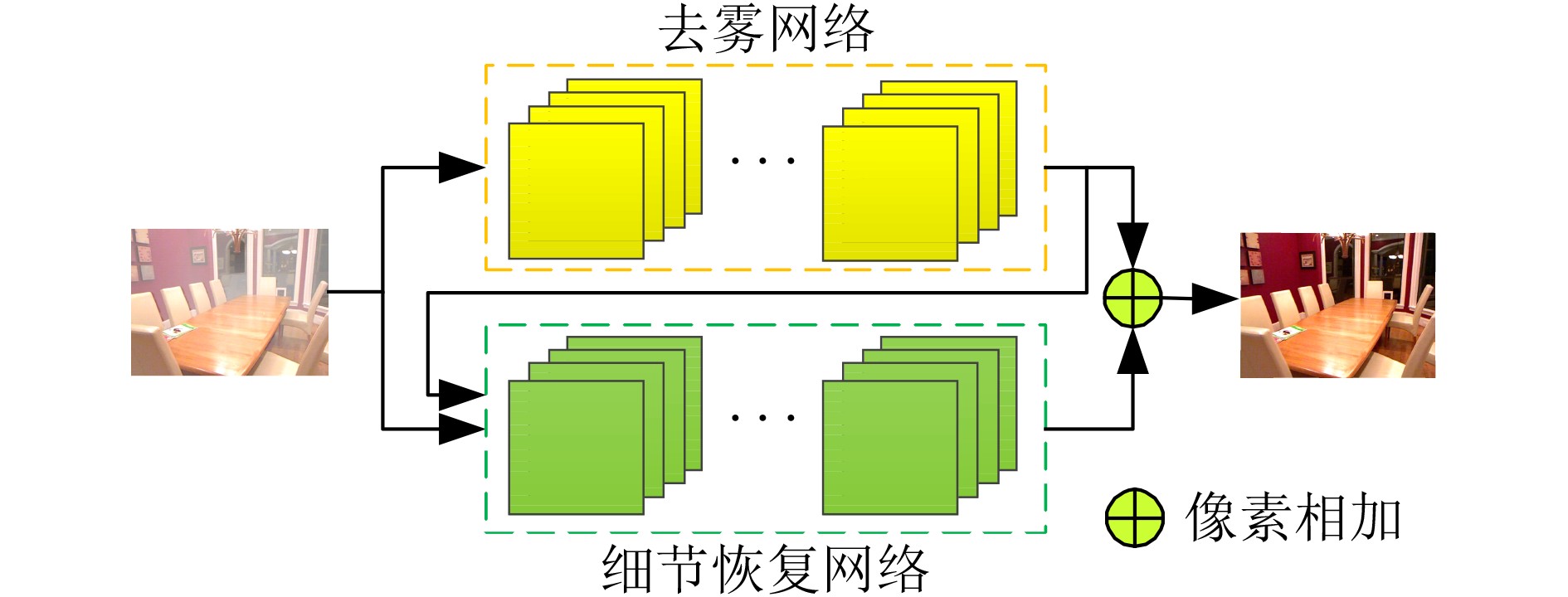
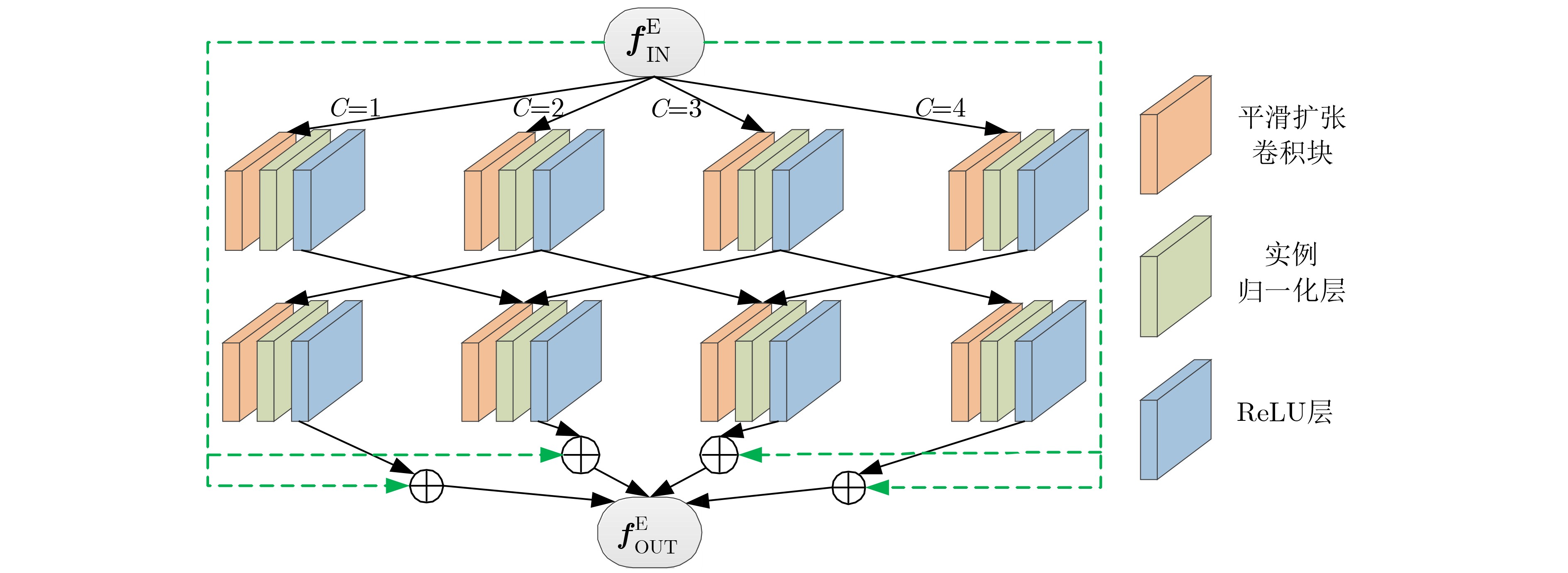
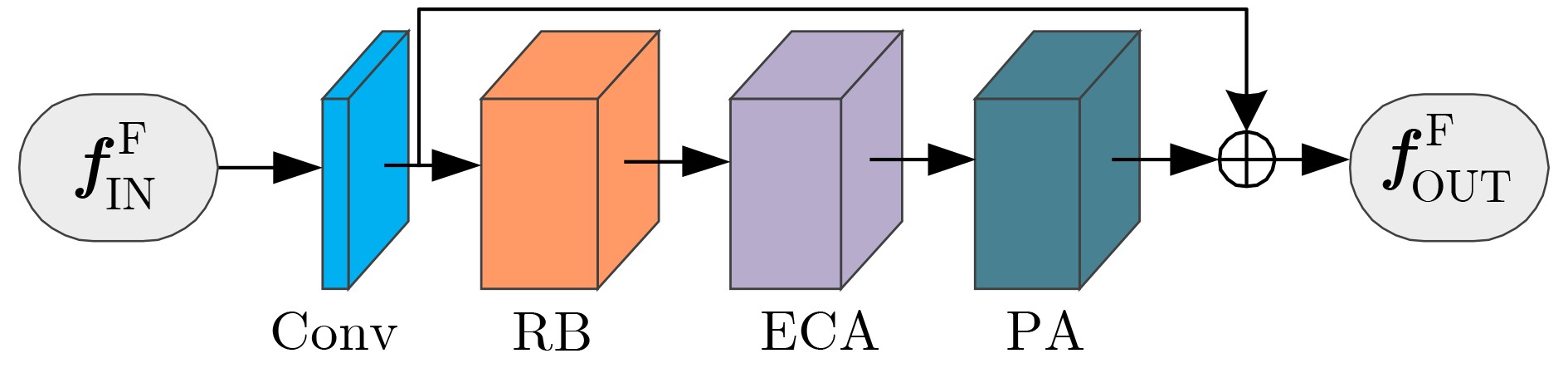
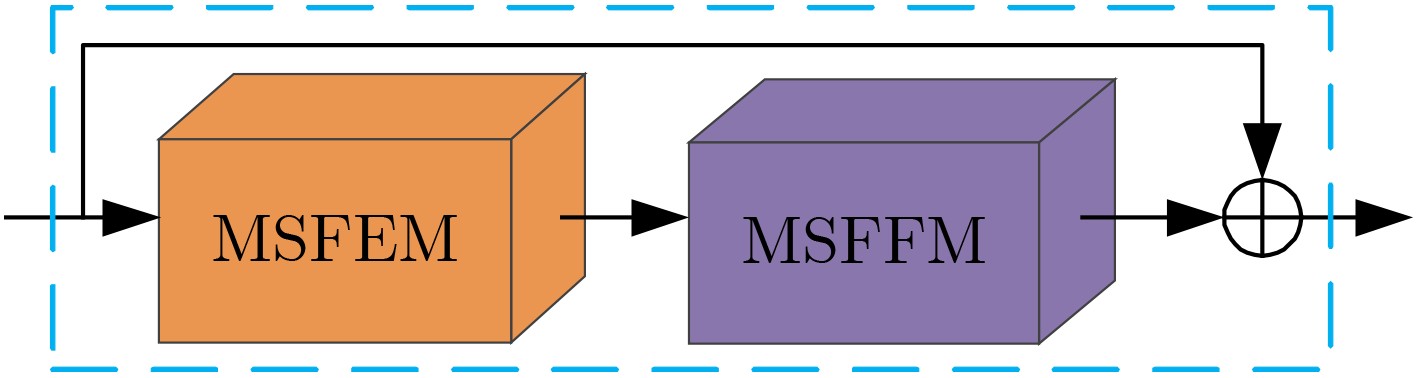
摘要: 为提高单幅图像去雾方法的准确性及其去雾结果的细节可见性,该文提出一种基于多尺度特征结合细节恢复的单幅图像去雾方法。首先,根据雾在图像中的分布特性及成像原理,设计多尺度特征提取模块及多尺度特征融合模块,从而有效提取有雾图像中与雾相关的多尺度特征并进行非线性加权融合。其次,构造基于所设计多尺度特征提取模块和多尺度特征融合模块的端到端去雾网络,并利用该网络获得初步去雾结果。再次,构造基于图像分块的细节恢复网络以提取细节信息。最后,将细节恢复网络提取出的细节信息与去雾网络得到的初步去雾结果融合得到最终清晰的去雾图像,实现对去雾后图像视觉效果的增强。实验结果表明,与已有代表性的图像去雾方法相比,所提方法能够对合成图像及真实图像中的雾进行有效去除,且去雾结果细节信息保留完整。Abstract: In order to improve the accuracy of the single image dehazing method and the detail visibility of its dehazing results, a single image dehazing method based on multi-scale features combined with detail recovery is proposed. Firstly, according to the distribution characteristics and imaging principles of haze in images, the multi-scale feature extraction module and the multi-scale feature fusion module are designed to extract effectively the haze-related multi-scale features in the hazy image and perform nonlinear weighted fusion. Secondly, the end-to-end dehazing network based on the designed multi-scale feature extraction module and multi-scale feature fusion module are constructed, and the preliminary dehazing results are obtained by using this network. Then, a detail recovery network based on image blocking is constructed to extract detail information. Finally, the detail information extracted from the detail recovery network is fused with the preliminary dehazing results obtained from the dehazing network to obtain the final clear dehazed image, which can enhance the visual effect of the dehazing images. The experimental results show that compared with the existing representative image dehazing methods, the proposed method can effectively remove the haze in the synthetic images and the real-world images, and the detailed information of the dehazing results is kept.
-
Key words:
- Image dehazing /
- Detail recover /
- Multi-scale features /
- Non-linear weighted fusion
-
表 1 不同配置消融实验的PSNR和SSIM指标对比
数据集 MSFEM MSFEM+MSFFM MSFEM+MSFFM+细节恢复网络 PSNR$ \uparrow $ SSIM$ \uparrow $ PSNR$ \uparrow $ SSIM$ \uparrow $ PSNR$ \uparrow $ SSIM$ \uparrow $ SOTS(Indoor) 33.06 0.977 33.52 0.979 35.16 0.988 SOTS(Outdoor) 29.11 0.966 32.64 0.979 33.78 0.985 Middlebury 16.53 0.840 16.61 0.843 17.48 0.864  下载: 导出CSV
下载: 导出CSV
表 2 各算法的PSNR和SSIM指标对比
数据集 客观指标 DCP[9] DeHazeNet[13] AOD-Net[14] GridDehazeNet[16] FFA-Net[18] MSBDN[25] 所提方法 SOTS(Indoor) PSNR$ \uparrow $ 16.61 19.82 20.51 32.16 36.39 32.51 35.16 SSIM$ \uparrow $ 0.855 0.821 0.816 0.984 0.989 0.977 0.988 SOTS(Outdoor) PSNR$ \uparrow $ 19.14 24.75 24.14 30.86 33.57 33.64 33.78 SSIM$ \uparrow $ 0.861 0.927 0.920 0.982 0.984 0.982 0.985 Middlebury PSNR$ \uparrow $ 11.94 – 13.94 16.94 13.76 17.34 17.48 SSIM$ \uparrow $ 0.762 – 0.743 0.856 0.698 0.862 0.864 I-HAZE PSNR$ \uparrow $ 11.99 14.58 15.34 16.53 15.26 23.93 20.73 SSIM$ \uparrow $ 0.528 0.688 0.704 0.768 0.696 0.891 0.813 O-HAZE PSNR$ \uparrow $ 13.27 15.77 16.45 16.75 21.36 24.36 25.80 SSIM$ \uparrow $ 0.576 0.697 0.684 0.766 0.869 0.749 0.875
下载: 导出CSV
-
[1] 姚婷婷, 梁越, 柳晓鸣, 等. 基于雾线先验的时空关联约束视频去雾算法[J]. 电子与信息学报, 2020, 42(11): 2796–2804. doi: 10.11999/JEIT190403YAO Tingting, LIANG Yue, LIU Xiaoming, et al. Video dehazing algorithm via haze-line prior with spatiotemporal correlation constraint[J]. Journal of Electronics &Information Technology, 2020, 42(11): 2796–2804. doi: 10.11999/JEIT190403 [2] 谭建豪, 殷旺, 刘力铭, 等. 引入全局上下文特征模块的DenseNet孪生网络目标跟踪[J]. 电子与信息学报, 2021, 43(1): 179–186. doi: 10.11999/JEIT190788TAN Jianhao, YIN Wang, LIU Liming, et al. DenseNet-siamese network with global context feature module for object tracking[J]. Journal of Electronics &Information Technology, 2021, 43(1): 179–186. doi: 10.11999/JEIT190788 [3] 余淼, 胡占义. 高阶马尔科夫随机场及其在场景理解中的应用[J]. 自动化学报, 2015, 41(7): 1213–1234. doi: 10.16383/j.aas.2015.c140684YU Miao and HU Zhanyi. Higher-order markov random fields and their applications in scene understanding[J]. Acta Automatica Sinica, 2015, 41(7): 1213–1234. doi: 10.16383/j.aas.2015.c140684 [4] STARK J A. Adaptive image contrast enhancement using generalizations of histogram equalization[J]. IEEE Transactions on Image Processing, 2000, 9(5): 889–896. doi: 10.1109/83.841534 [5] JIANG B, WOODELL G A, and JOBSON D J. Novel multi-scale retinex with color restoration on graphics processing unit[J]. Journal of Real-Time Image Processing, 2015, 10(2): 239–253. doi: 10.1007/s11554-014-0399-9 [6] SEOW M J and ASARI V K. Ratio rule and homomorphic filter for enhancement of digital colour image[J]. Neurocomputing, 2006, 69(7/9): 954–958. doi: 10.1016/j.neucom.2005.07.003 [7] DAUBECHIES I. The wavelet transform, time-frequency localization and signal analysis[J]. IEEE Transactions on Information Theory, 1990, 36(5): 961–1005. doi: 10.1109/18.57199 [8] FATTAL R. Single image dehazing[J]. ACM Transactions on Graphics, 2008, 27(3): 1–9. doi: 10.1145/1360612.1360671 [9] HE Kaiming, SUN Jian, and TANG Xiaoou. Single image haze removal using dark channel prior[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(12): 2341–2353. doi: 10.1109/TPAMI.2010.168, [10] 杨燕, 王志伟. 基于均值不等关系优化的自适应图像去雾算法[J]. 电子与信息学报, 2020, 42(3): 755–763. doi: 10.11999/JEIT190368YANG Yan and WANG Zhiwei. Adaptive image dehazing algorithm based on mean unequal relation optimization[J]. Journal of Electronics &Information Technology, 2020, 42(3): 755–763. doi: 10.11999/JEIT190368 [11] WANG Jinbao, HE Ning, ZHANG Lulu, et al. Single image dehazing with a physical model and dark channel prior[J]. Neurocomputing, 2015, 149: 718–728. doi: 10.1016/j.neucom.2014.08.005 [12] ZHU Qingsong, MAI Jiaming, and SHAO Ling. A fast single image haze removal algorithm using color attenuation prior[J]. IEEE Transactions on Image Processing, 2015, 24(11): 3522–3533. doi: 10.1109/TIP.2015.2446191 [13] CAI Bolun, XU Xiangmin, JIA Kui, et al. DehazeNet: An end-to-end system for single image haze removal[J]. IEEE Transactions on Image Processing, 2016, 25(11): 5187–5198. doi: 10.1109/TIP.2016.2598681 [14] LI Boyi, PENG Xiulian, WANG Zhangyang, et al. AOD-Net: All-in-one dehazing network[C]. IEEE International Conference on Computer Vision, Venice, Italy, 2017: 4780–4788. [15] QU Yanyun, CHEN Yizi, HUANG Jingying, et al. Enhanced pix2pix dehazing network[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 8160–8168. [16] LIU Xiaohong, MA Yongrui, SHI Zhihao, et al. GridDehazeNet: Attention-based multi-scale network for image dehazing[C]. IEEE International Conference on Computer Vision, Seoul, Korea (South), 2019: 7314–7323. [17] DAS S D and DUTTA S. Fast deep multi-patch hierarchical network for nonhomogeneous image dehazing[C]. IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2020: 1994–2001. [18] QIN Xu, WANG Zhilin, BAI Yuanchao, et al. FFA-Net: Feature fusion attention network for single image dehazing[C]. 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 11908–11915. [19] WANG Zhengyang and JI Shuiwang. Smoothed dilated convolutions for improved dense Prediction[C]. 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, United Kingdom, 2018: 2486–2495. [20] WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11531–11539. [21] LI Boyi, REN Wenqi, FU Dengpan, et al. Benchmarking single-image dehazing and beyond[J]. IEEE Transactions on Image Processing, 2019, 28(1): 492–505. doi: 10.1109/TIP.2018.2867951 [22] SCHARSTEIN D, HIRSCHMÜLLER H, KITAJIMA Y, et al. High-resolution stereo datasets with subpixel-accurate ground truth[C]. 36th German Conference on Pattern Recognition, Münster, Germany, 2014: 31–42. [23] ANCUTI C, ANCUTI C O, TIMOFTE R, et al. I-HAZE: A dehazing benchmark with real hazy and haze-free indoor images[C]. Advanced Concepts for Intelligent Vision Systems, 19th International Conference, ACIVS 2018, Poitiers, France, 2018: 620–631. [24] ANCUTI C O, ANCUTI C, TIMOFTE R, et al. O-HAZE: A dehazing benchmark with real hazy and haze-free outdoor images[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, USA, 2018: 867–875. [25] DONG Hang, PAN Jinshan, XIANG Lei, et al. Multi-scale boosted dehazing network with dense feature fusion[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 2154–2164. -

 下载:
下载:







图(9) / 表(3)
计量
- 文章访问数: 1563
- HTML全文浏览量: 1120
- PDF下载量: 206
- 被引次数: 0
