

Real-time Detection of Hiding Contraband in Human Body During the Security Check Based on Lightweight U-Net with Deep Learning
-
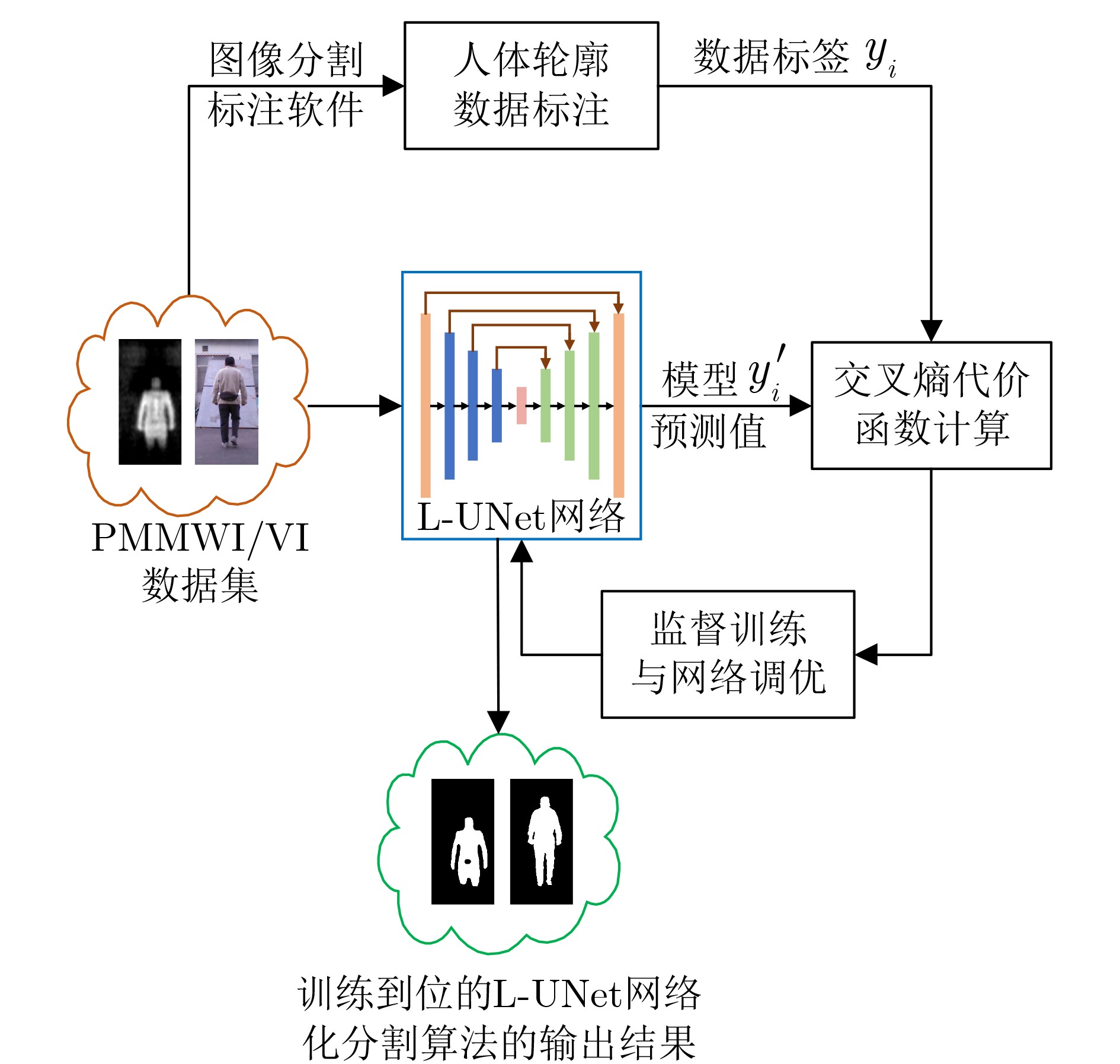
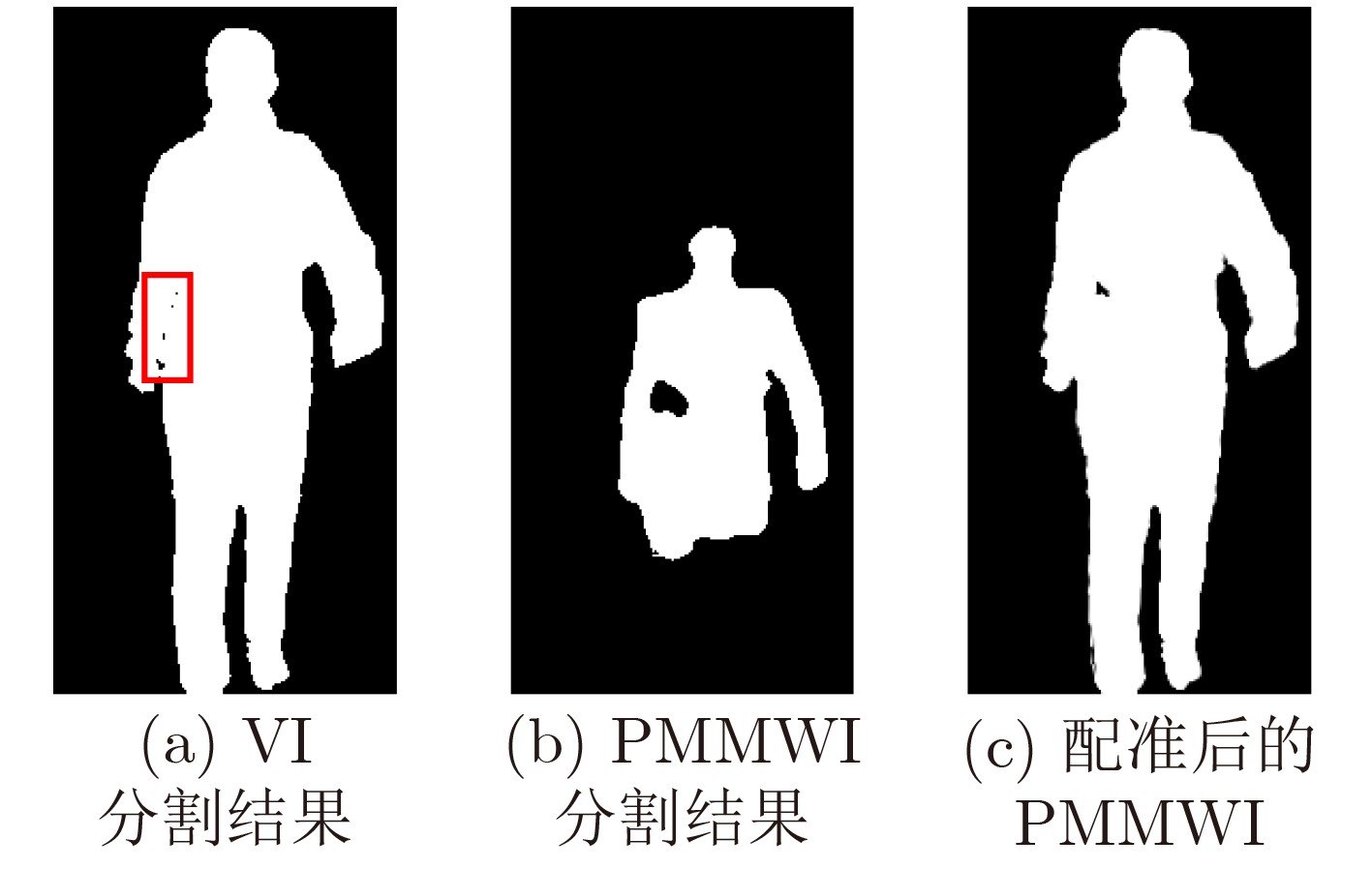
摘要: 在高端智能安检系统研发中,如何使受检者在无接触正常行进过程中,对其实施人体是否携带隐匿违禁物的快速高效检测是具有挑战性的关键性技术。被动毫米波成像以其安全无害、穿透性强等突出优势而成为安检成像的热门选项。该文利用被动毫米波成像和可见光成像的优势互补,通过轻量级U-Net的深度学习,研究提出人体安检隐匿违禁物的高性能实时检测算法。首先构建和训练轻量级U-Net分割网络,进行被动毫米波图像(PMMWI)和可见光图像(VI)中人体轮廓的快速分割,实现人体与背景的有效分离,以获取疑似隐匿违禁物的轮廓信息。进而,以轻量级U-Net为工具,通过基于相似性测度的无监督学习方法进行被动毫米波人体轮廓图像与可见光人体轮廓图像的配准,以滤除虚警目标,并在可见光图像中进行疑似目标定位,得到单帧图像的检测结果。最后,通过序列多帧图像之检测结果的综合集成与推断,给出最终检测结果。通过在专门构建的数据集上的实验结果表明,该文所提方法的F1指标达到92.3%,展现出良好的性能优势。Abstract: In the research and development of high-end intelligent security check system, it is a challenging key technology how to make the detection of whether the human body is carrying hiding contraband quickly and efficiently in the normal process of non-contact travel. Passive millimeter wave imaging has become a popular option for security imaging due to its outstanding advantages such as safety, harmlessness and strong penetration. In this paper, the complementary advantages of passive millimeter wave imaging and visible imaging are employed, and a high-performance detection algorithm for hiding contraband in human body based on the lightweight U-Net is proposed. A lightweight U-Net is first constructed and trained to realize the rapid segmentation of the human contour in Passive MilliMeter Wave Image (PMMWI) and Visible Image (VI). In this way, the information of human contour and hiding contraband can be extracted. Then, human contour registration on PMMWI/VI is realized by the unsupervised learning method based on the similarity measure with the lightweight U-Net. After filtering the false alarm target, the position of the hiding contraband is marked in VI and the detection result on single frame image can be obtained. In the end, the final detection result is given through the comprehensive integration and inference of the detection results of sequence multi-frame images. Experimental results on a specially constructed dataset show that the proposed method reaches 92.3% of F1 evaluation index, thus demonstrates its performance advantages.
-
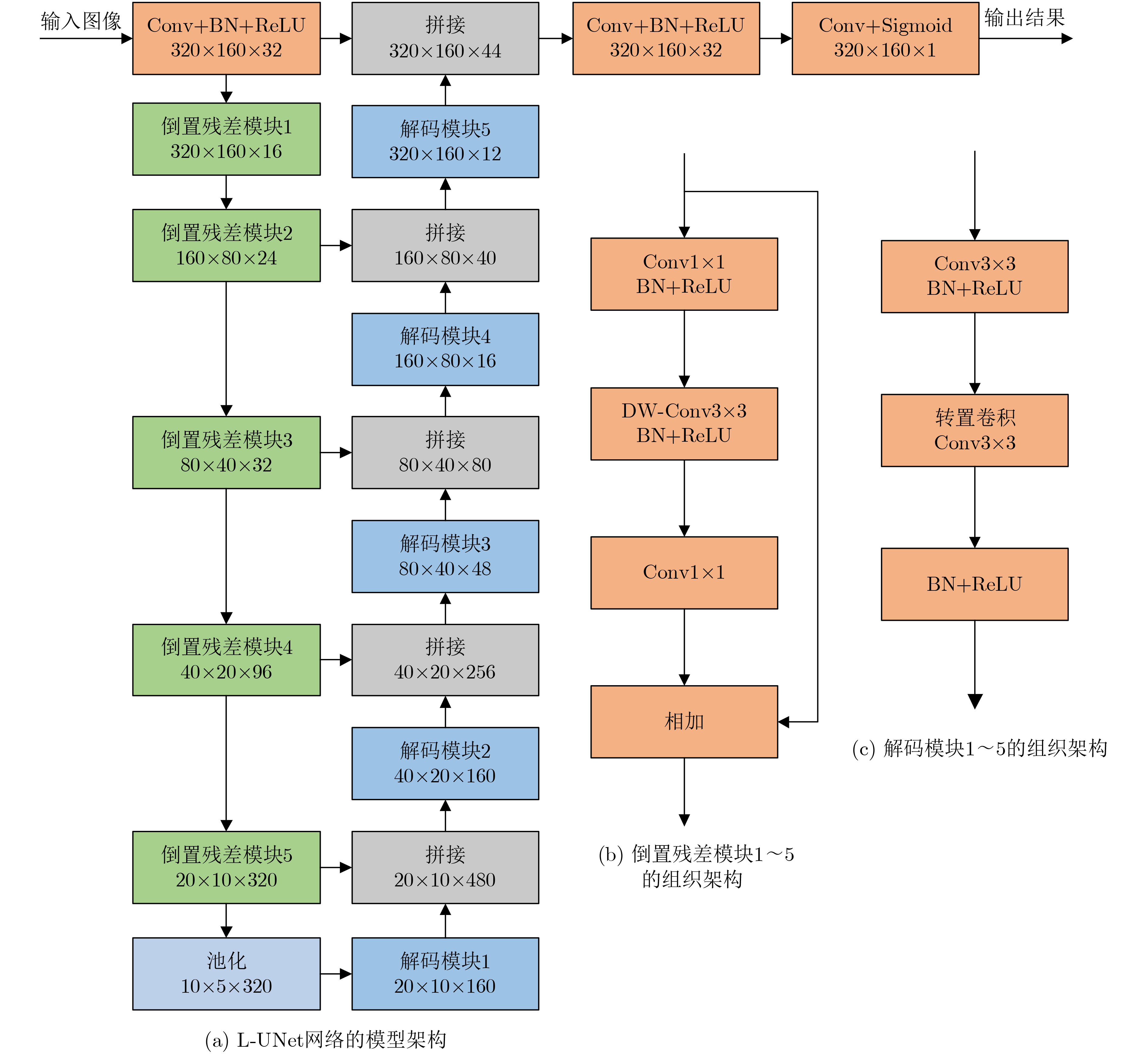
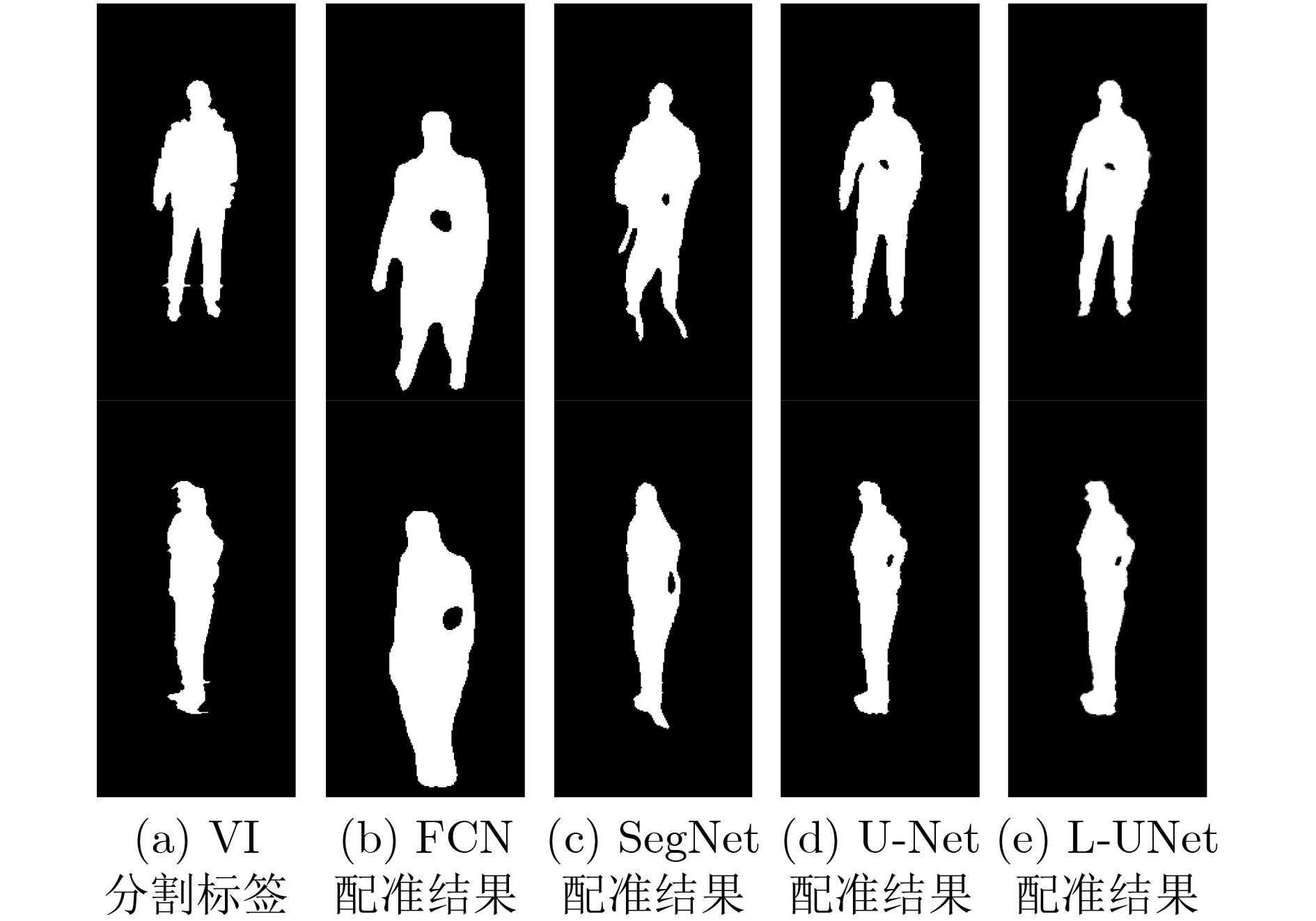
表 1 基于轻量级U-Net深度学习的人体安检隐匿物检测算法
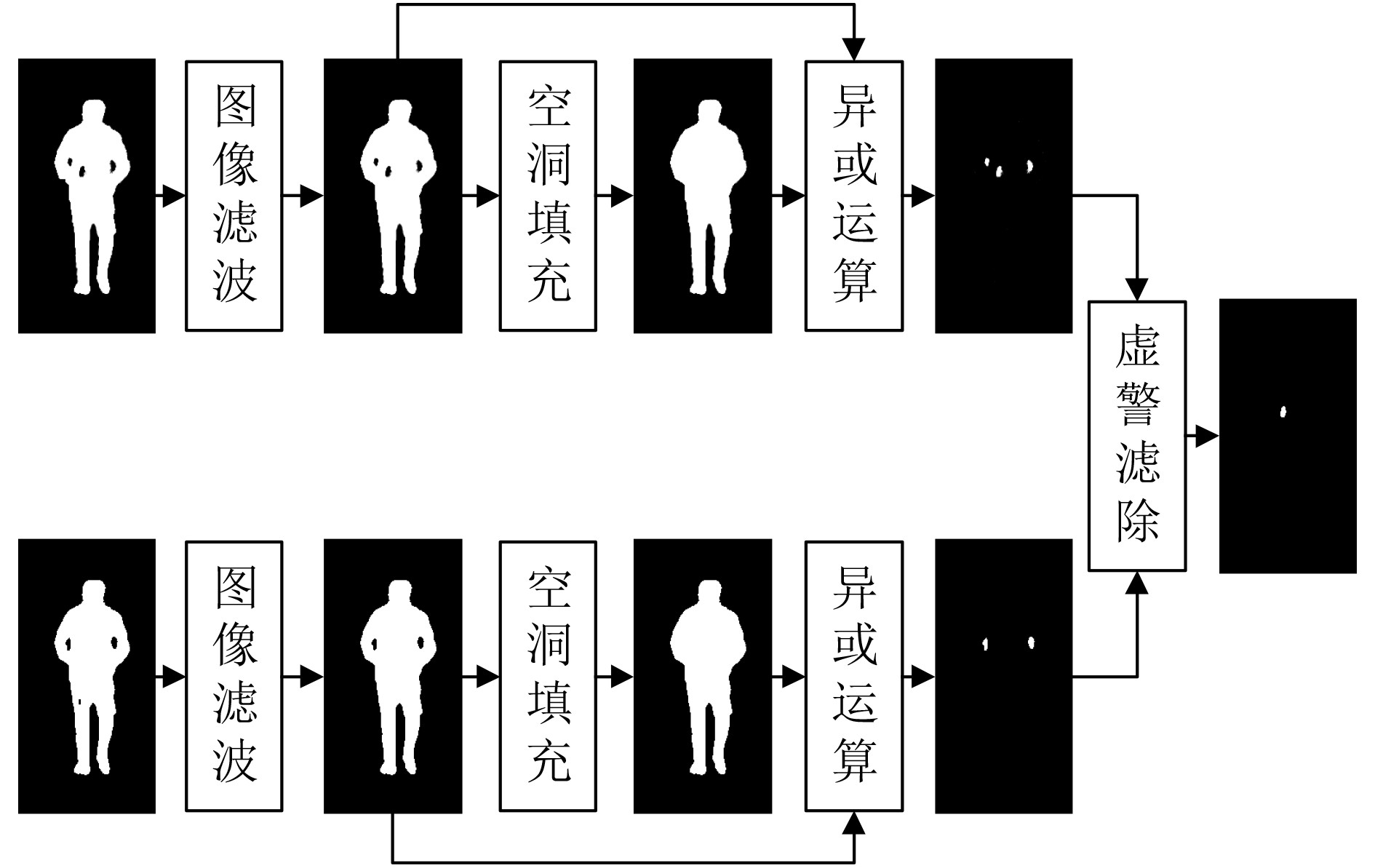
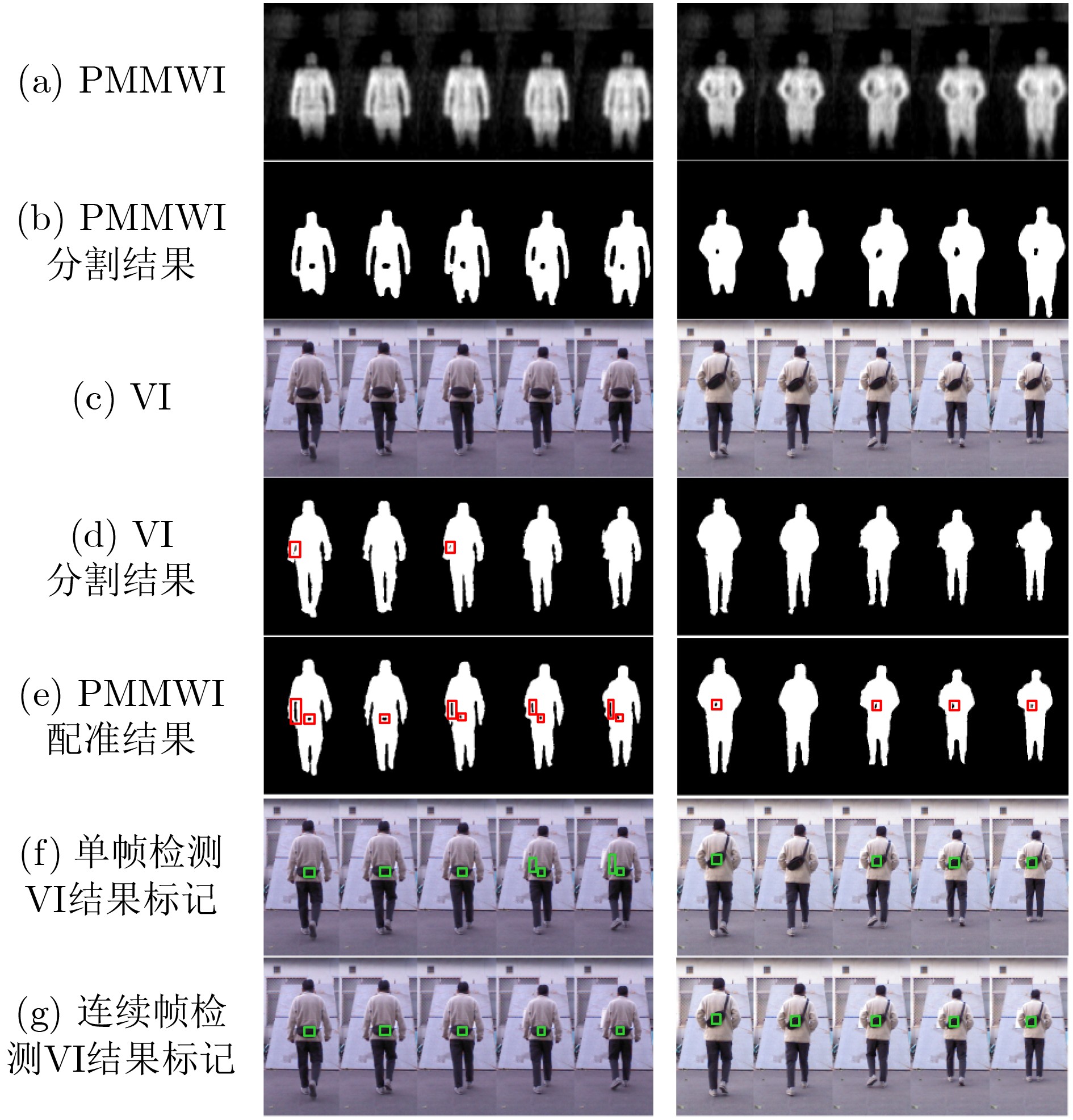
输入: 被动毫米波图像序列${\boldsymbol{P}} = \{ {p^1},{p^2}, \cdots ,{p^n}\} $,可见光图像序列${\boldsymbol{V}} = \{ {v^1},{v^2}, \cdots ,{v^n}\} $,检测结果表决的序列门限数$n$。 输出: 带有检测结果标记的VI序列${\boldsymbol{R}}$。 初始化: 矩阵${ {\boldsymbol{I} }_{320 \times 160} } = { {\textit{0}}}$ 步骤1 根据3.3节中训练方法,获取人体轮廓分割的L-UNet模型${M_1}$。 步骤2 根据4.4节中训练方法,获取人体轮廓配准的L-UNet模型${M_2}$。 步骤3 For $i = 1$ to $n$ 步骤4 将${p^i}$和${v^i}$输入${M_1}$获得人体轮廓分割图像$p_s^i$和$v_s^i$。 步骤5 将$p_s^i$和$v_s^i$输入${M_2}$获得配准后的PMMWI图像$p_r^i$。 步骤6 依据5.2节中方法进行虚警滤除并获得隐匿物目标,同时将隐匿物区域像素值置1,其余置0,得到隐匿物目标二值图${o^i}$。 步骤7 将${o^i}$与${\boldsymbol{I}}$逐像素相加:${\boldsymbol{I}} = {\boldsymbol{I}} + {o^i}$。 步骤8 If $i{\text{ }}\% {\text{ }}5 = = 0$ 步骤9 将${\boldsymbol{I}}$中像素值大于等于$n$的区域在${v^i}$中进行标记得到${r^i}$。 步骤10 将${\boldsymbol{I}}$像素值全部置0。 步骤11 End If 步骤12 End For 步骤13 输出带有隐匿物检测结果标记的VI序列${\boldsymbol{R}} = \{ {r^1},{r^2}, \cdots ,{r^n}\} $。  下载: 导出CSV
下载: 导出CSV
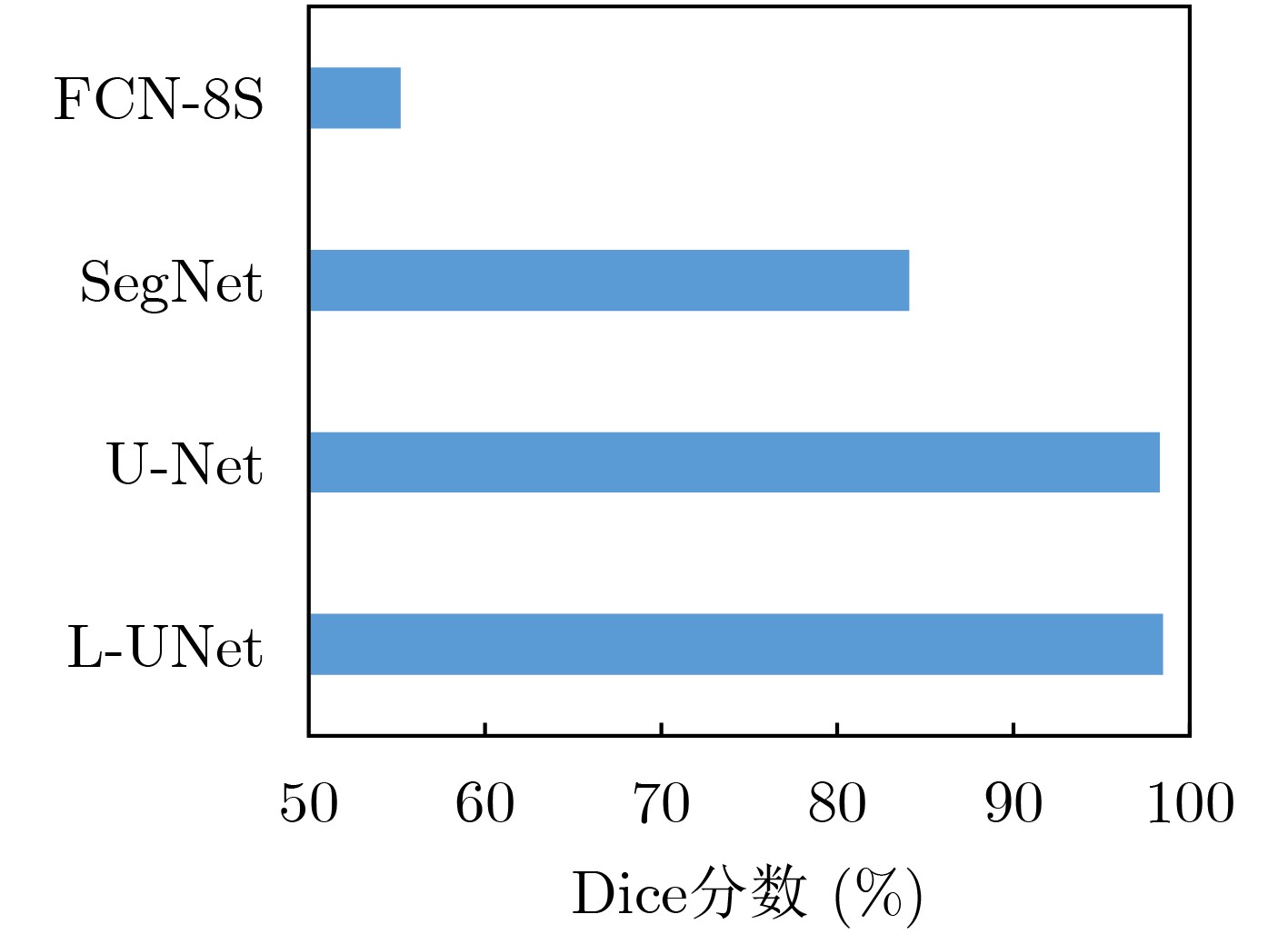
表 4 单帧图像隐匿物检测与连续帧检测性能对比(%)
性能指标 检测方式 单帧图像
检测连续帧检测
n=2连续帧检测
n=3连续帧检测
n=4P 78.7 72.2 92.3 100.0 R 90.8 100.0 92.3 69.2 F1 84.3 83.9 92.3 81.8
下载: 导出CSV
表 5 YOLO v3单帧图像隐匿物检测性能(%)
性能指标 针对不同被测图像类的测试方式 所有实采图像 实采图像中含隐匿物
的图像P 100.0 87.0 R 30.8 90.9 F1 47.1 88.9
下载: 导出CSV
-
[1] 冯辉, 涂昊, 高炳西, 等. 被动毫米波太赫兹人体成像关键技术进展[J]. 激光与红外, 2020, 50(11): 1395–1401. doi: 10.3969/j.issn.1001-5078.2020.11.018FENG Hui, TU Hao, GAO Bingxi, et al. Progress on key technologies of passive millimeter wave and terahertz imaging for human body screening[J]. Laser &Infrared, 2020, 50(11): 1395–1401. doi: 10.3969/j.issn.1001-5078.2020.11.018 [2] SANDLER M, HOWARD A, ZHU Menglong, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, America, 2018: 4510–4520. [3] LÓPEZ-TAPIA S, MOLINA R, and DE LA BLANCA N P. Using machine learning to detect and localize concealed objects in passive millimeter-wave images[J]. Engineering Applications of Artificial Intelligence, 2018, 67: 81–90. doi: 10.1016/j.engappai.2017.09.005 [4] LÓPEZ-TAPIA S, MOLINA R, and DE LA BLANCA N P. Deep CNNs for object detection using passive millimeter sensors[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(9): 2580–2589. doi: 10.1109/TCSVT.2017.2774927 [5] PANG Lei, LIU Hui, CHEN Yang, et al. Real-time concealed object detection from passive millimeter wave images based on the YOLOv3 algorithm[J]. Sensors, 2020, 20(6): 1678. doi: 10.3390/s20061678 [6] LONG J, SHELHAMER E, and DARRELL T. Fully convolutional networks for semantic segmentation[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, America, 2015: 3431–3440. [7] RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. [8] 罗会兰, 卢飞, 孔繁胜. 基于区域与深度残差网络的图像语义分割[J]. 电子与信息学报, 2019, 41(11): 2777–2786. doi: 10.11999/JEIT190056LUO Huilan, LU Fei, and KONG Fansheng. Image semantic segmentation based on region and deep residual network[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2777–2786. doi: 10.11999/JEIT190056 [9] ZHU Lanyun, JI Deyi, ZHU Shiping, et al. Learning statistical texture for semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, America, 2021: 12532–12541, [10] FU Yabo, LEI Yang, WANG Tonghe, et al. Deep learning in medical image registration: A review[J]. Physics in Medicine & Biology, 2020, 65(20): 20TR01. doi: 10.1088/1361-6560/ab843e [11] CAO Xiaohuan, YANG Jianhua, ZHANG Jun, et al. Deformable image registration using a cue-aware deep regression network[J]. IEEE Transactions on Biomedical Engineering, 2018, 65(9): 1900–1911. doi: 10.1109/TBME.2018.2822826 [12] MOK T C W and CHUNG A C S. Fast symmetric diffeomorphic image registration with convolutional neural networks[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, America, 2020: 4643–4652. [13] KIM B, KIM D H, PARK S H, et al. CycleMorph: Cycle consistent unsupervised deformable image registration[J]. Medical Image Analysis, 2021, 71: 102036. doi: 10.1016/j.media.2021.102036 [14] BALAKRISHNAN G, ZHAO A, SABUNCU M R, et al. VoxelMorph: A learning framework for deformable medical image registration[J]. IEEE Transactions on Medical Imaging, 2019, 38(8): 1788–1800. doi: 10.1109/TMI.2019.2897538 [15] MA Yingjun, NIU Dongmei, ZHANG Jinshuo, et al. Unsupervised deformable image registration network for 3D medical images[J]. Applied Intelligence, 2022, 52(1): 766–779. doi: 10.1007/s10489-021-02196-7 [16] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. https://arxiv.org/abs/1704.04861, 2017. [17] HE Kaiming, ZHANG Xingyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. IEEE conference on computer vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [18] BREHERET A. Pixel annotation tool[EB/OL]. https://github.com/abreheret/PixelAnnotationTool, 2017. [19] SOKOOTI H, DE VOS B, BERENDSEN F, et al. Nonrigid image registration using multi-scale 3D convolutional neural networks[C]. 20th International Conference on Medical Image Computing and Computer Assisted Intervention, Quebec City, Canada, 2017: 232–239. [20] JADERBERG M, SIMONYAN K, ZISSERMAN A, et al. Spatial transformer networks[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 2017–2025. doi: 10.5555/2969442.2969465. [21] BADRINARAYANAN V, KENDALL A, and CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481–2495. doi: 10.1109/TPAMI.2016.2644615 [22] DICE L R. Measures of the amount of ecologic association between species[J]. Ecology, 1945, 26(3): 297–302. doi: 10.2307/1932409 -

 下载:
下载:














图(17) / 表(5)
计量
- 文章访问数: 1246
- HTML全文浏览量: 1153
- PDF下载量: 170
- 被引次数: 0
