

Underwater Optical Image Interested Object Detection Model Based on Improved SSD
-
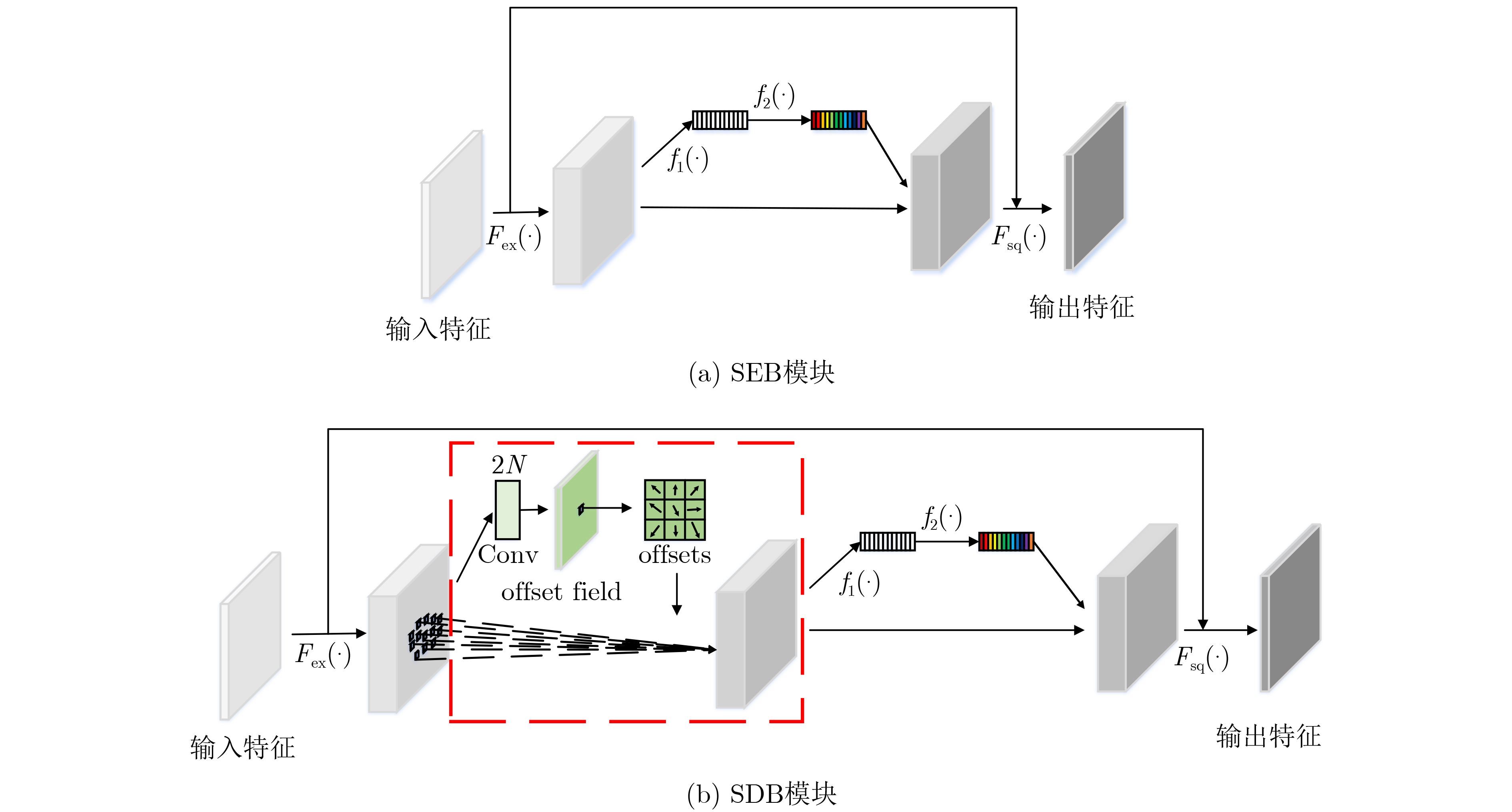
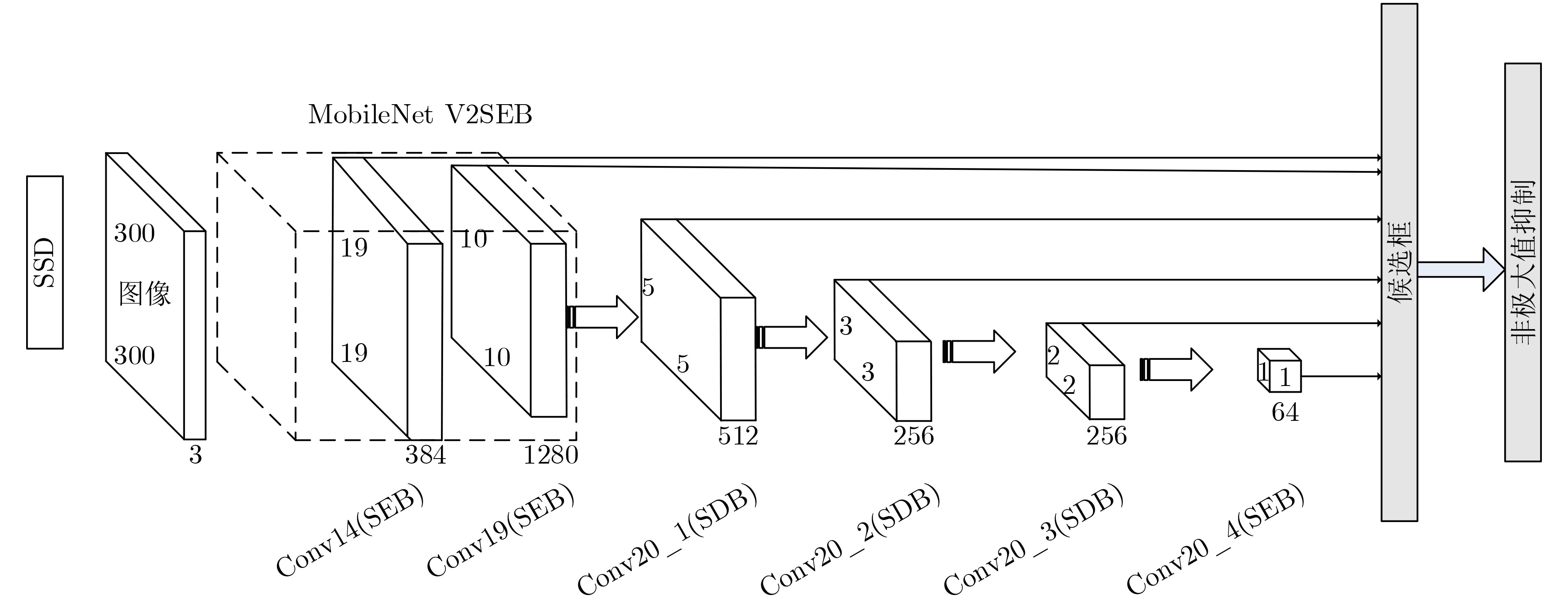
摘要: 针对轻量化目标模型SSD-MV2对水下光学图像感兴趣目标检测精度低的问题,该文提出一种通道可选择的轻量化特征提取模块(SEB)和一种卷积核可变形、通道可选择的特征提取模块(SDB)。与此同时,利用SEB模块和SDB模块分别重新设计了SSD-MV2的基础网络和附加特征提取网络,记作SSD-MV2SDB,并为其选择了合理的基础网络扩张系数和附加特征提取网络SDB模块数量。在水下图像感兴趣目标检测数据集UOI-DET上,SSD-MV2SDB比SSD-MV2检测精度提高3.04%。实验结果表明,SSD-MV2SDB适用于水下图像感兴趣目标检测任务。
-
关键词:
- 水下光学图像感兴趣目标检测 /
- SSD /
- MobileNet V2 /
- 可变形卷积 /
- 通道可选择
Abstract: In order to solve the problem of low detection accuracy of SSD-MV2, a Selective and Efficient Block (SEB) and a Selective and Deformable Block (SDB) are proposed. At the same time, the basic network and additional feature extraction network of SSD-MV2 are redesigned by using SEB and SDB, which is named SSD-MV2SDB, and a set of reasonable expansion coefficient of basic network and number of SDB in additional feature extraction network are selected for SSD-MV2SDB. On UOI-DET, mAP of SSD-MV2SDB is 3.04% higher than that of SSD-MV2. The experimental results show that SSD-MV2SDB is suitable for underwater optical image interested object detection task. -
表 2 目标检测模型性能比较
模型 基础网络 附加特征提取网络 检测精度(%) 参数大小(MB) 检测时间(ms) SSD-MV2 IRB IRB 94.24 10.2 7.20 SSD-MV2SEB SEB SEB 95.09 11.0 10.01 SSD-MV2IRBD SEB IRBD 95.97 14.8 13.52 SSD-MV2SDB SEB SDB 97.28 14.9 13.86  下载: 导出CSV
下载: 导出CSV
表 3 基础网络扩张系数对SSD-MV2SDB性能的影响
扩张系数 检测精度(%) 参数大小(MB) 检测时间(ms) 2 95.03 12.1 13.66 4 97.28 14.9 13.86 6 97.33 17.7 13.90 8 97.76 20.4 14.12
下载: 导出CSV
表 4 附加特征提取网络SDB模块数量对SSD-MV2SDB性能的影响
模块数量 检测精度(%) 参数大小(MB) 检测时间(ms) 0 95.09 11.0 10.01 1 96.08 13.5 11.11 2 97.09 14.2 12.53 3 97.28 14.9 13.86
下载: 导出CSV
-
[1] YEH C H, LIN Chuhan, KANG Liwei, et al. Lightweight deep neural network for joint learning of underwater object detection and color conversion[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 6: 1–15. doi: 10.1109/TNNLS.2021.3072414 [2] HMUE P M and PUMRIN S. Image enhancement and quality assessment methods in turbid water: A review article[C]. IEEE International Conference on Consumer Electronics, Bangkok, Thailand, 2019: 59–63. [3] CHEN Bin, LI Rong, BAI Wanjian, et al. Research on recognition method of optical detection image of underwater robot for submarine cable[C]. 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 2019: 1973–1976. [4] LECUN Y, BENGIO Y, and HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436–444. doi: 10.1038/nature14539 [5] ZHANG J X, YORDANOV B, GAUNT A, et al. A deep learning model for predicting next-generation sequencing depth from DNA sequence[J]. Nature Communications, 2021, 12: 4387. doi: 10.1038/s41467-021-24497-8 [6] WANG Shiqiang. Efficient deep learning[J]. Nature Computational Science, 2021, 1(3): 181–182. doi: 10.1038/s43588-021-00042-x [7] LAGEMANN C, LAGEMANN K, MUKHERJEE S, et al. Deep recurrent optical flow learning for particle image velocimetry data[J]. Nature Machine Intelligence, 2021, 3(7): 641–651. doi: 10.1038/s42256-021-00369-0 [8] LI Sichun, JIN Xin, YAO Sibing, et al. Underwater small target recognition based on convolutional neural network[C]. Global Oceans 2020: Singapore – U. S. Gulf Coast, Biloxi, USA, 2020: 1–7. [9] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. [10] GIRSHICK R. Fast R-CNN[C]. IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2015: 1440–1448. [11] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [12] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 779–788. [13] SRITHAR S, PRIYADHARSINI M, SHARMILA F M, et al. Yolov3 Supervised machine learning framework for real-time object detection and localization[J]. Journal of Physics:Conference Series, 2021, 1916: 012032. doi: 10.1088/1742-6596/1916/1/012032 [14] IANDOLA F N, MOSKEWICZ N W, ASHRAF K, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size[EB/OL]. https://arxiv.org/abs/1602.07360v1, 2016. [15] SZEGEDY C, LIU Wei, JIA Yangqing, et al. . Going deeper with convolutions[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. [16] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. https://arxiv.org/abs/1704.04861, 2017. [17] SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4510–4520. [18] HU Jie, SHEN Li, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011–2023. doi: 10.1109/TPAMI.2019.2913372 [19] DAI Jifeng, QI Haozhi, XIONG Yuwen, et al. Deformable convolutional networks[C]. IEEE International Conference on Computer Vision, Venice, Italy, 2017: 764–773. -

 下载:
下载:



图(3) / 表(4)
计量
- 文章访问数: 1475
- HTML全文浏览量: 945
- PDF下载量: 191
- 被引次数: 0
