

Human Posture Recognition Based on Multi-dimensional Information Feature Fusion of Frequency Modulated Continuous Wave Radar
-
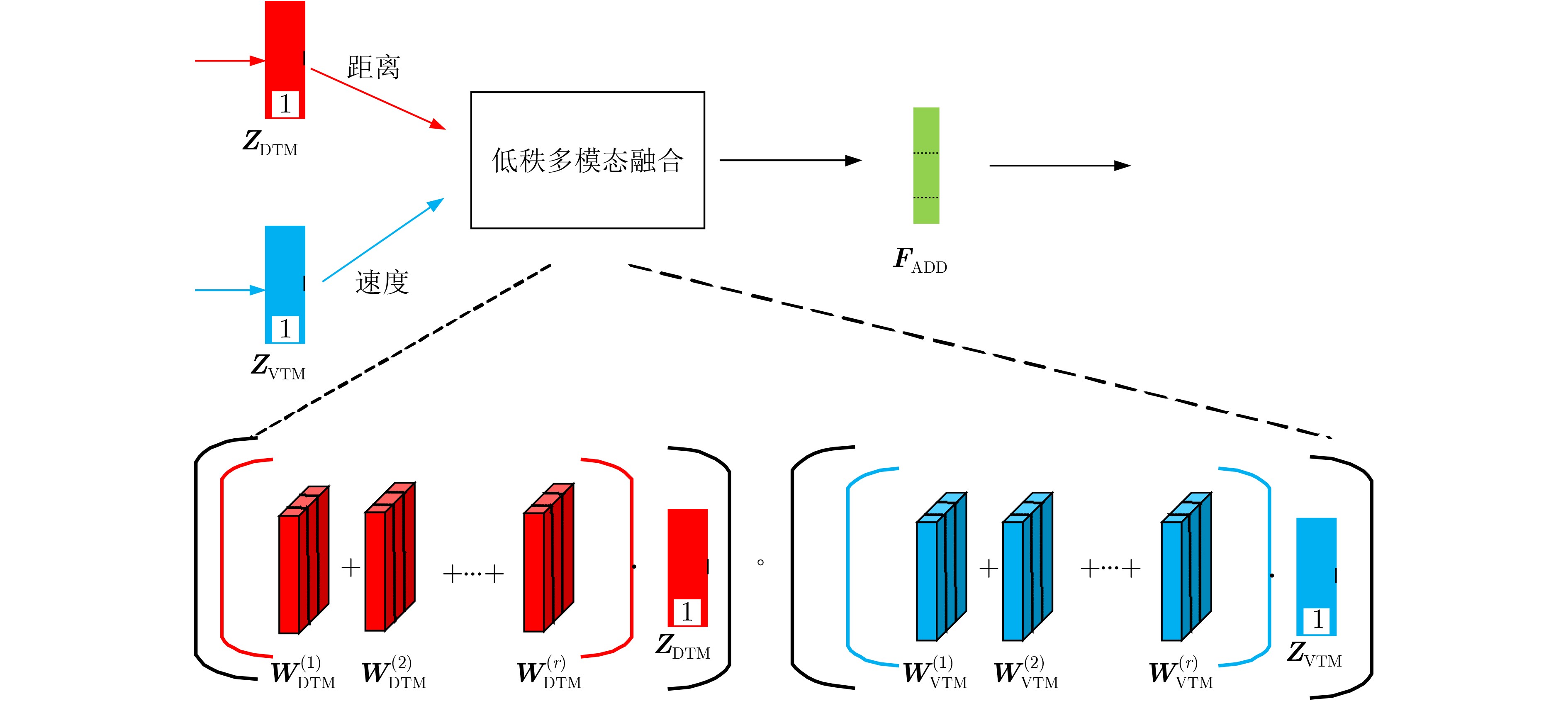
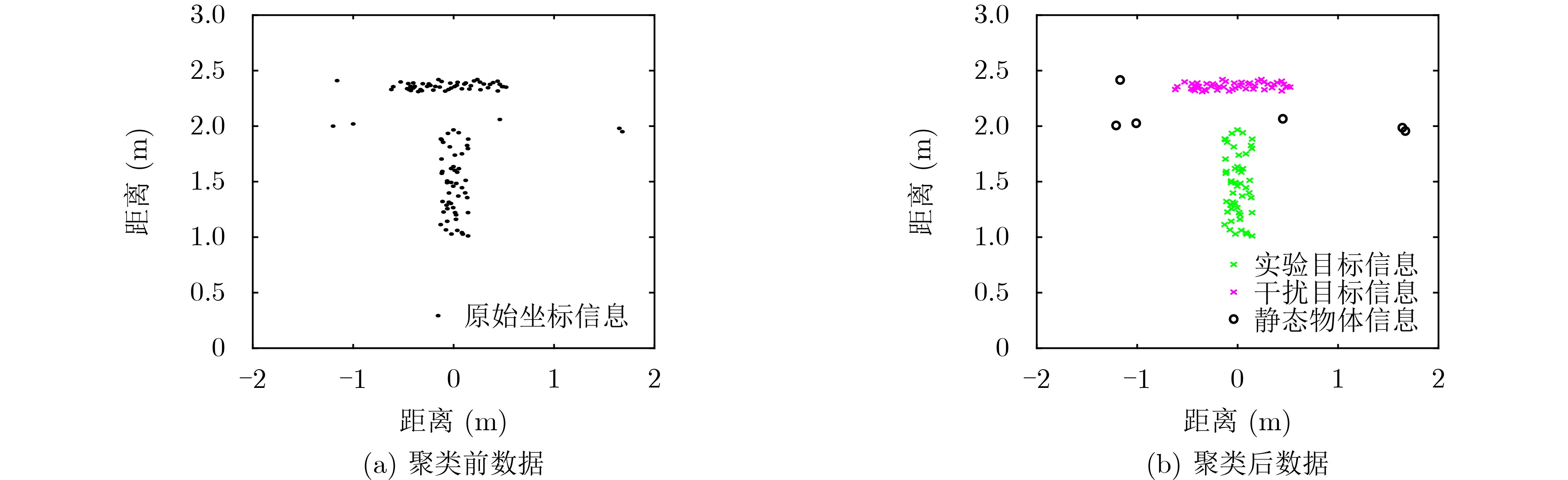
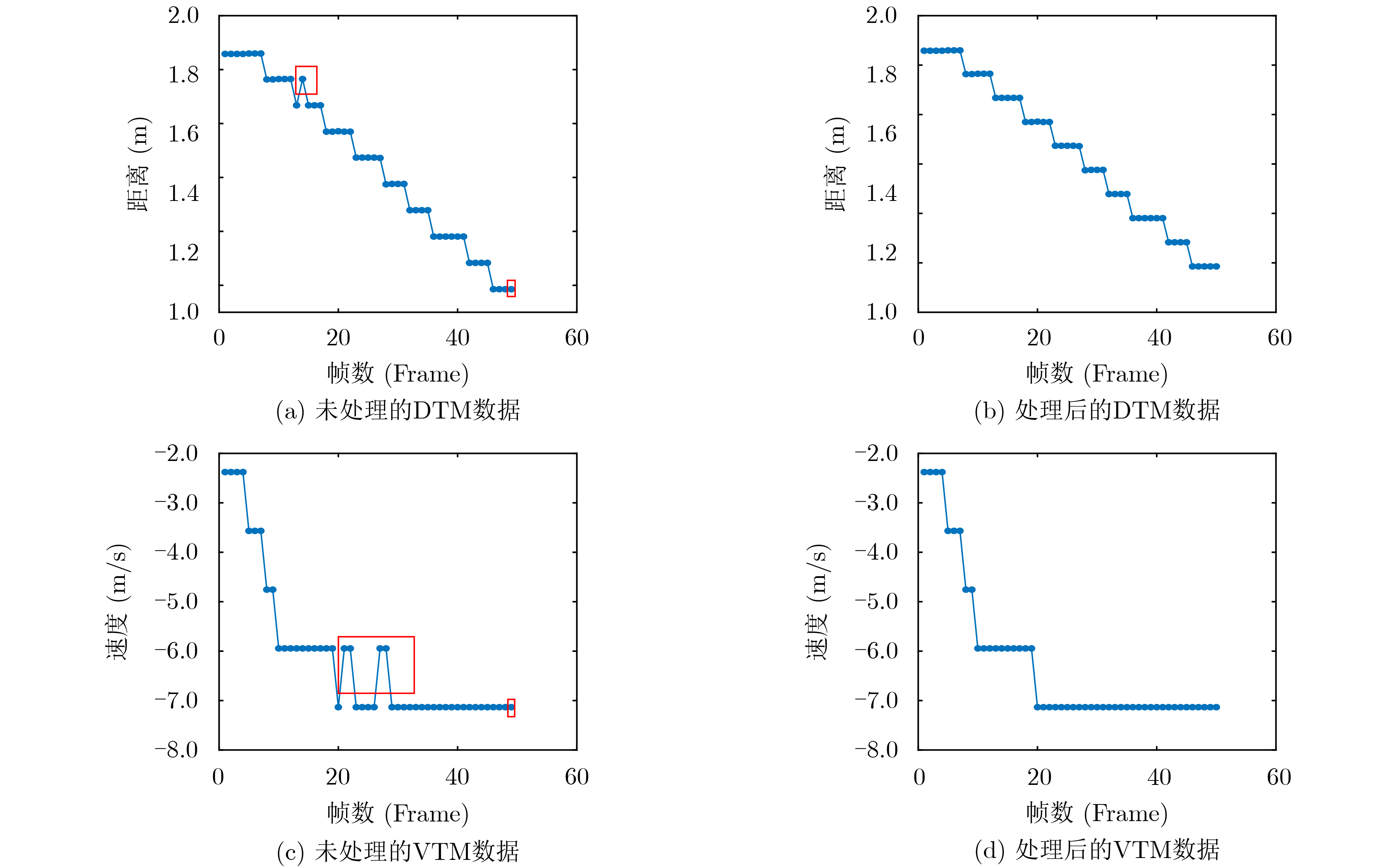
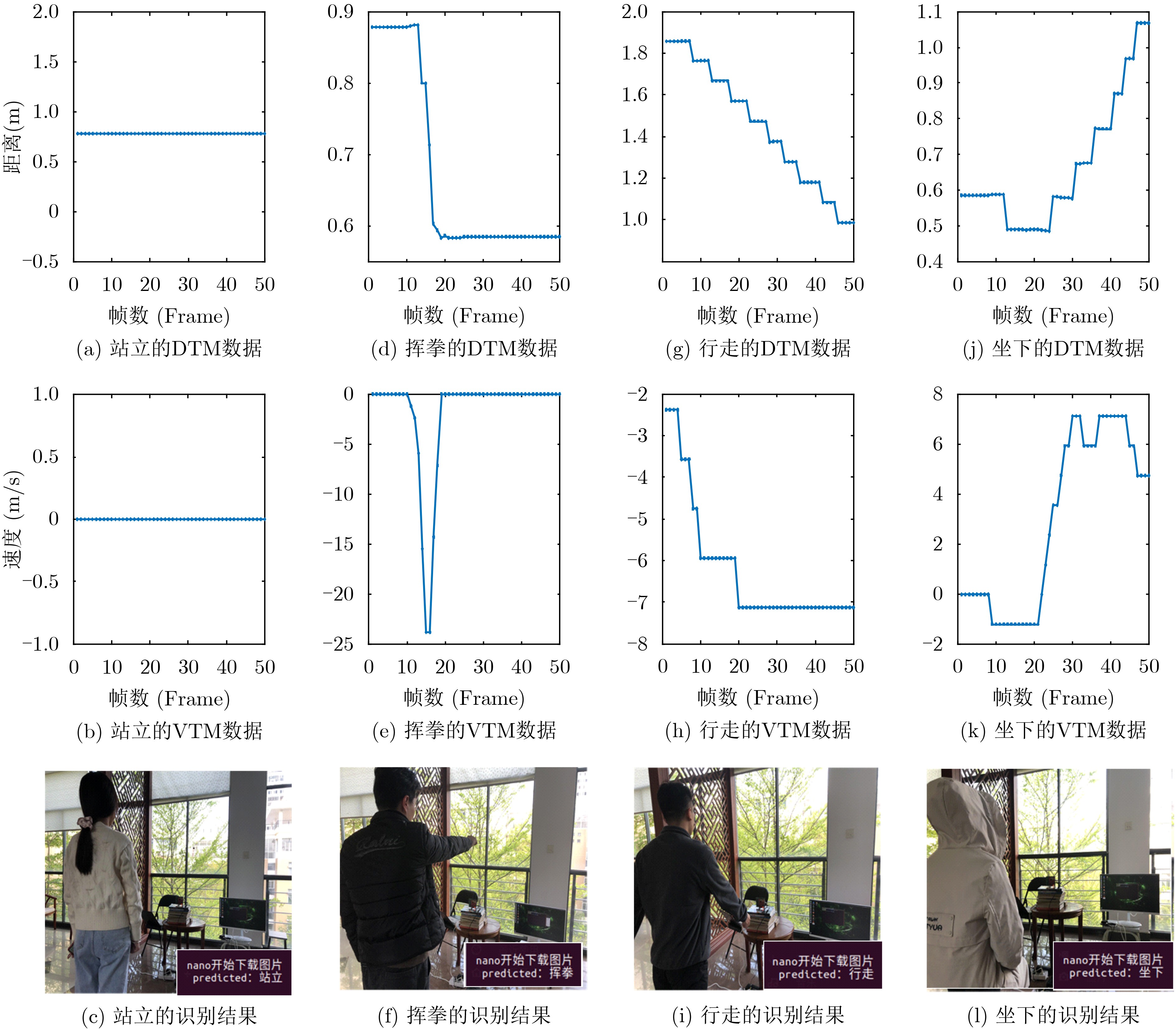
摘要: 为实现在复杂多样的环境下人体姿势的识别,该文提出一种基于调频连续波(FMCW)雷达的多维信息特征融合的人体姿势识别方法。该方法通过对FMCW雷达原始信号进行3维快速傅里叶变换得到目标距离、速度和角度的多维信息,在采用具有噪声的基于密度的聚类算法(DBSCAN)和 Hampel滤波算法解决运动范围内动态或静态目标的噪声干扰后使用卷积神经网络对多维信息进行特征提取,然后利用低秩多模态融合网络(LMF)充分融合多维信息的特征,并通过域鉴别器进一步获得与环境无关的特征,最终使用活动识别器获得姿势识别结果。为了实用性,在边缘计算平台上搭载预先设计的算法和训练好的网络模型进行实验验证。实验结果表明,在复杂的环境下该方法的识别精度可达到91.5%。Abstract: In order to realize the recognition of human posture in complex and diverse environments, a method based on Frequency Modulated Continuous Wave (FMCW) radar signal is proposed. This method obtains multi-dimensional information of distance, speed and angle by performing 3D fast Fourier transform on the original signal of FMCW radar. After using the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm and the Hampel filter algorithm to solve the noise interference of dynamic or static targets in the range of motion, the convolutional neural network is used to extract the features of multi-dimensional information. Then Low-rank Multimodal Fusion network (LMF) is used to fully fuse the features of multi-dimensional information. Finally, the domain discriminator further obtains domain-independent features, and the activity recognizer obtains the result of gesture recognition. The pre-designed algorithm and the trained network model are carried out on the edge computing platform for experimental verification. Experimental results show that the recognition accuracy of this method can reach 91.5% in complex environments.
-
表 3 DV-EI-Net多参数网络目标域分类精度(%)
模型 VTM+DTM 基于串联特征融合方式(无域鉴别器) 85.0 基于LMF融合方式(无域鉴别器) 86.5 基于串联特征融合方式(有域鉴别器) 87.5 基于LMF融合方式(有域鉴别器) 91.5  下载: 导出CSV
下载: 导出CSV
-
[1] 杨丽梅, 李致豪. 面向人机交互的手势识别系统设计[J]. 工业控制计算机, 2020, 33(3): 18–20,22. doi: 10.3969/j.issn.1001-182X.2020.03.007YANG Limei and LI Zhihao. Design of gesture recognition system towards human computer interaction[J]. Industrial Control Computer, 2020, 33(3): 18–20,22. doi: 10.3969/j.issn.1001-182X.2020.03.007 [2] AGGARWAL J K and XIA Lu. Human activity recognition from 3D data: A review[J]. Pattern Recognition Letters, 2014, 48: 70–80. doi: 10.1016/j.patrec.2014.04.011 [3] TRAN D, WANG Heng, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6450–6459. [4] 熊昕, 郑杨娇子, 张上. 基于长短时记忆网络及变体的跌倒检测和人体行为识别系统[J]. 信息通信, 2020(2): 65–67. doi: 10.3969/j.issn.1673-1131.2020.02.027XIONG Xin, ZHENG Yangjiaozi, and ZHANG Shang. Fall detection and human behavior recognition system based on long and short time memory networks and variants[J]. Information &Communications, 2020(2): 65–67. doi: 10.3969/j.issn.1673-1131.2020.02.027 [5] SABOKROU M, POURREZA M, FAYYAZ M, et al. AVID: Adversarial visual irregularity detection[C]. 14th Asian Conference on Computer Vision, Perth, Australia, 2019: 488–505. [6] 刘天亮, 谯庆伟, 万俊伟, 等. 融合空间-时间双网络流和视觉注意的人体行为识别[J]. 电子与信息学报, 2018, 40(10): 2395–2401. doi: 10.11999/JEIT171116LIU Tianliang, QIAO Qingwei, WAN Junwei, et al. Human action recognition via Spatio-temporal dual network flow and visual attention fusion[J]. Journal of Electronics &Information Technology, 2018, 40(10): 2395–2401. doi: 10.11999/JEIT171116 [7] WANG Jie, ZHANG Xiao, GAO Qinhua, et al. Device-free wireless localization and activity recognition: A deep learning approach[J]. IEEE Transactions on Vehicular Technology, 2017, 66(7): 6258–6267. doi: 10.1109/TVT.2016.2635161 [8] XU Shengzhi, KOOIJ B J, and YAROVOY A. Joint Doppler and DOA estimation using (Ultra-)Wideband FMCW signals[J]. Signal Processing, 2020, 168: 107259. doi: 10.1016/j.sigpro.2019.107259 [9] LEE J, HWANG S, YOU S, et al. Joint angle, velocity, and range estimation using 2D MUSIC and successive interference cancellation in FMCW MIMO radar system[J]. IEICE Transactions on Communications, 2020, E103.B(3): 283–290. doi: 10.1587/transcom.2018EBP3330 [10] 王勇, 吴金君, 田增山, 等. 基于FMCW雷达的多维参数手势识别算法[J]. 电子与信息学报, 2019, 41(4): 822–829. doi: 10.11999/JEIT180485WANG Yong, WU Jinjun, TIAN Zengshan, et al. Gesture recognition with multi-dimensional parameter using FMCW radar[J]. Journal of Electronics &Information Technology, 2019, 41(4): 822–829. doi: 10.11999/JEIT180485 [11] ZHAO Yinan, ZHANG Zihao, and ZHANG Zhaolin. Multi-angle data cube action recognition based on millimeter wave radar[C]. 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 2020: 749–753. [12] ZHAO Mingmin, LI Tianhong, ABU ALSHEIKH M, et al. Through-wall human pose estimation using radio signals[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7356–7365. [13] 刘皓, 郭立, 易波, 等. 基于3D骨架和MCRF模型的行为识别[J]. 中国科学技术大学学报, 2014, 44(4): 285–291. doi: 10.3969/j.issn.0253-2778.2014.04.005LIU Hao, GUO Li, YI Bo, et al. Human activity recognition based on 3D skeletons and MCRF model[J]. Journal of University of Science and Technology of China, 2014, 44(4): 285–291. doi: 10.3969/j.issn.0253-2778.2014.04.005 [14] ATREY P K, HOSSAIN M A, EL SADDIK A, et al. Multimodal fusion for multimedia analysis: A survey[J]. Multimedia Systems, 2010, 16(6): 345–379. doi: 10.1007/s00530-010-0182-0 [15] MORENCY L P, MIHALCEA R, and DOSHI P. Towards multimodal sentiment analysis: Harvesting opinions from the web[C]. The 13th International Conference on Multimodal Interfaces, Alicante, Spain, 2011: 169–176. [16] XUE Hongfei, JIANG Wenjun, MIAO Chenglin, et al. DeepFusion: A deep learning framework for the fusion of heterogeneous sensory data[C]. The Twentieth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Catania, Italy, 2019: 151–160. [17] ZADEH A, CHEN Minghai, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[C]. The 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017: 1114–1125. [18] LIU Zhun, SHEN Ying, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2247–2256. [19] GANIN Y and LEMPITSKY V. Unsupervised domain adaptation by backpropagation[C]. The 32nd International Conference on Machine Learning, Lille, France, 2015: 1180–1189. [20] SCITOVSKI R, MAJSTOROVIĆ S, and SABO K. A combination of RANSAC and DBSCAN methods for solving the multiple geometrical object detection problem[J]. Journal of Global Optimization, 2021, 79(3): 669–686. doi: 10.1007/s10898-020-00950-8 [21] DEKKER B, JACOBS S, KOSSEN A S, et al. Gesture recognition with a low power FMCW radar and a deep convolutional neural network[C]. 2017 European Radar Conference (EURAD), Nuremberg, Germany, 2017: 163–166. [22] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2014. -


 下载:
下载:



图(6) / 表(4)
计量
- 文章访问数: 1814
- HTML全文浏览量: 1159
- PDF下载量: 188
- 被引次数: 0
