

Monaural Speech Enhancement Based on Attention-Gate Dilated Convolution Network
-
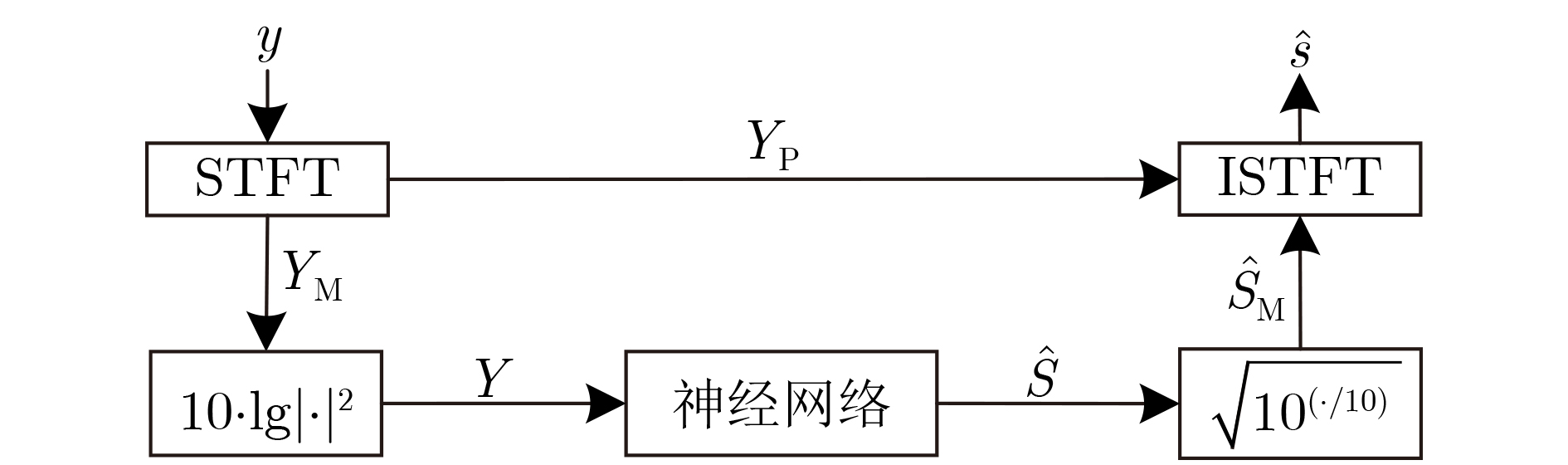
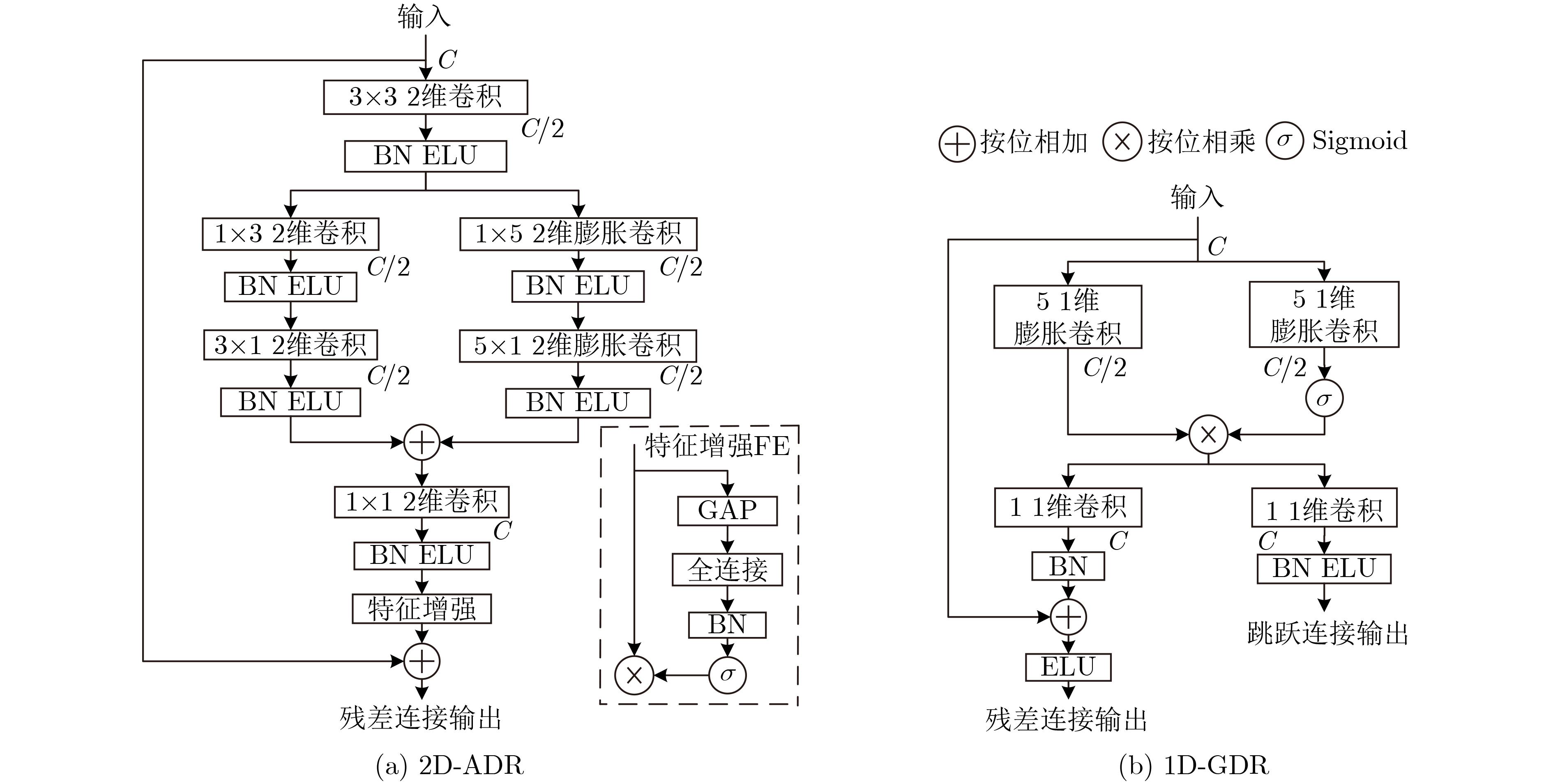
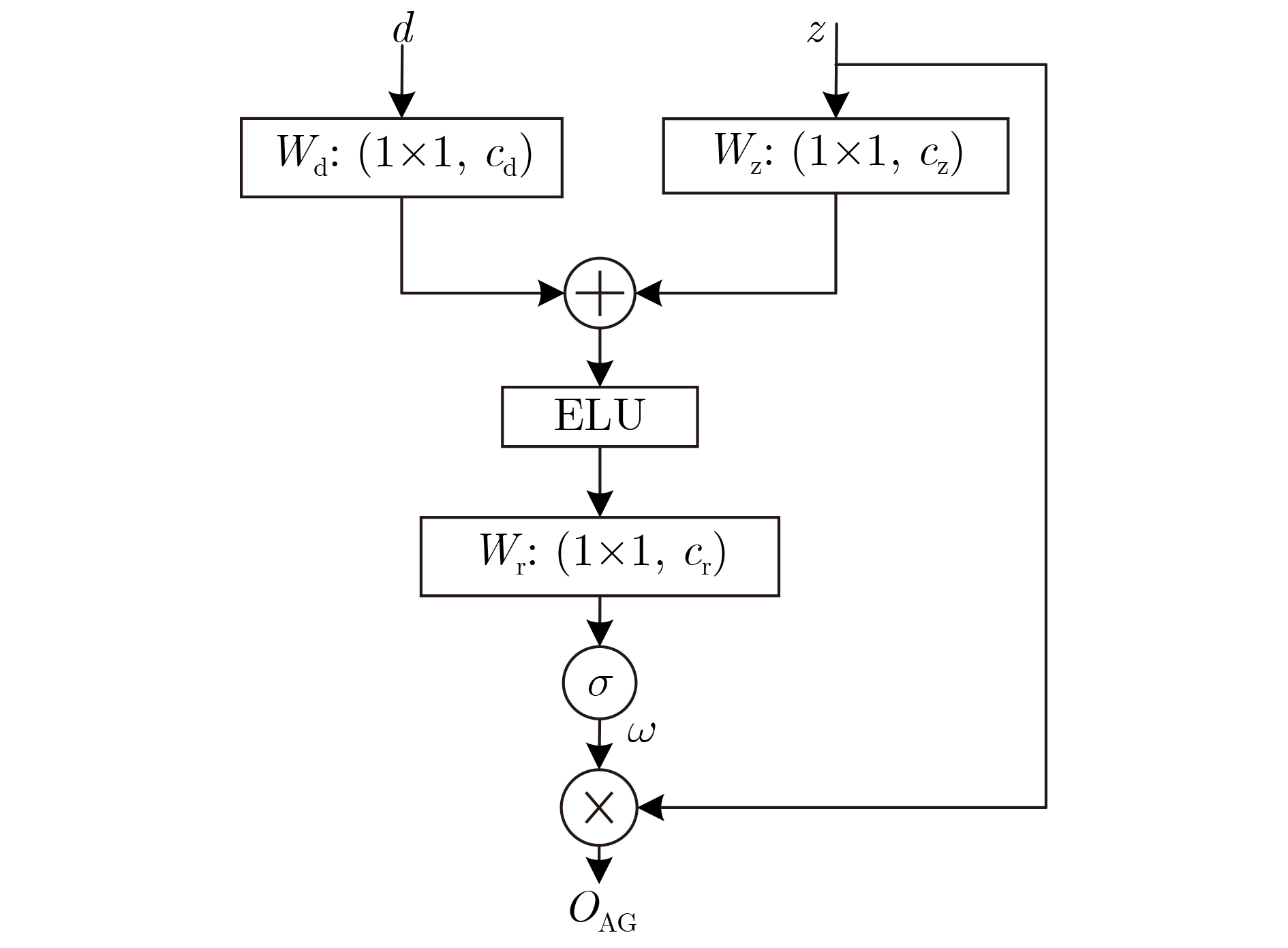
摘要: 在有监督语音增强任务中,上下文信息对目标语音的估计产生重要影响,为了获取更加丰富的语音全局相关特征,该文以尽可能小的参数为前提,设计了一种新型卷积网络来进行语音增强。所提网络包含编码层、传输层与解码层3个部分:编解码部分提出一种2维非对称膨胀残差(2D-ADR)模块,其能明显减小训练参数并扩大感受野,提升网络对上下文信息的获取能力;传输层提出一种1维门控膨胀残差(1D-GDR)模块,该模块结合膨胀卷积、残差学习与门控机制,能够选择性传递特征并获取更多时序相关信息,同时采用密集跳跃连接的方式对8个1D-GDR模块进行堆叠,以增强层间信息流动并提供更多梯度传播方式;最后,对相应编解码层进行跳跃连接并引入注意力机制,以使解码过程获得更加鲁棒的底层特征。实验部分,使用了不同的参数设置以及对比方法来验证网络的有效性与鲁棒性,通过在28种噪声环境下训练及测试,相比于其他方法,该文方法以1.25×106的参数取得了更优的客观和主观指标,具备较强的增强效果与泛化能力。Abstract: In supervised speech enhancement, contextual information has an important influence on the estimation of target speech. In order to obtain richer global related features of speech, a new convolution network for speech enhancement on the premise of the smallest possible parameters is designed in this paper. The proposed network contains three parts: encode layer, transfer layer and decode layer. The encode and decode part propose a Two-Dimensional Asymmetric Dilated Residual (2D-ADR) module, which can significantly reduce training parameters and expand the receptive field, and improve the model’s ability to obtain contextual information. The transfer layer proposes a One-Dimensional Gating Dilated Residual (1D-GDR) module, which combines dilated convolution, residual learning and gating mechanism to transfer selectively features and obtain more time-related information. Moreover, the eight 1D-GDR modules are stacked by a dense skip-connection way to enhance the information flow between layers and provide more gradient propagation path. Finally, the corresponding encode and decode layer is connected by skip-connection and attention mechanism is introduced to make the decoding process obtain more robust underlying features. In the experimental part, different parameter settings and comparison methods are used to verify the effectiveness and robustness of the network. By training and testing under 28 kinds of noise, compared with other methods, the proposed method has achieved better objective and subjective metrics with 1.25 million parameters, and has better enhancement effect and generalization ability.
-
Key words:
- Speech enhancement /
- Dilated convolution /
- Residual learning /
- Gate mechanism /
- Attention mechanism
-
表 1 网络参数
层 模块 参数 输入维度 输出维度 1 Conv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {2,2} \right),{\text{ }}c = 16 $ $ 128 \times 128 \times 1 $ $ 64 \times 64 \times 16 $ 2 2D-ADR $ d = 1 $ $ 64 \times 64 \times 16 $ $ 64 \times 64 \times 16 $ 3 Conv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {2,2} \right),{\text{ }}c = 32 $ $ 64 \times 64 \times 16 $ $ 32 \times 32 \times 32 $ 4 2D-ADR $ d = 2 $ $ 32 \times 32 \times 32 $ $ 32 \times 32 \times 32 $ 5 Conv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {1,2} \right),{\text{ }}c = 64 $ $ 32 \times 32 \times 32 $ $ 32 \times 16 \times 64 $ 6 2D-ADR $ d = 4 $ $ 32 \times 16 \times 64 $ $ 32 \times 16 \times 64 $ 7 Conv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {1,2} \right),{\text{ }}c = 64 $ $ 32 \times 16 \times 64 $ $ 32 \times 8 \times 64 $ 8 Reshape - $ 32 \times 8 \times 64 $ $ 32 \times 512 $ 9 DCGDR $ c1 = 128,{\text{ }}c2 = 512 $
d=(1, 2, 5, 9, 2, 5, 9, 17)$ 32 \times 512 $ $ 32 \times 512 $ 10 Reshape - $ 32 \times 512 $ $ 32 \times 8 \times 64 $ 11 Deconv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {1,2} \right),{\text{ }}c = 64 $ $ 32 \times 8 \times \left( {64 + 64} \right) $ $ 32 \times 16 \times 64 $ 12 2D-ADR $ d = 1 $ $ 32 \times 16 \times 64 $ $ 32 \times 16 \times 64 $ 13 Deconv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {1,2} \right),{\text{ }}c = 32 $ $ 32 \times 16 \times \left( {64 + 64} \right) $ $ 32 \times 32 \times 32 $ 14 2D-ADR $ d = 2 $ $ 32 \times 32 \times 32 $ $ 32 \times 32 \times 32 $ 15 Deconv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {2,2} \right),{\text{ }}c = 16 $ $ 32 \times 32 \times \left( {32 + 32} \right) $ $ 64 \times 64 \times 16 $ 16 2D-ADR $ d = 4 $ $ 64 \times 64 \times 16 $ $ 64 \times 64 \times 16 $ 17 Deconv2d $ k = \left( {3,3} \right),{\text{ }}s = \left( {2,2} \right),{\text{ }}c = 1 $ $ 64 \times 64 \times \left( {16 + 16} \right) $ $ 128 \times 128 \times 1 $ 18 Deconv2d $ k = \left( {1,1} \right),{\text{ }}s = \left( {1,1} \right),{\text{ }}c = 1 $ $ 128 \times 128 \times 1 $ $ 128 \times 128 \times 1 $  下载: 导出CSV
下载: 导出CSV
表 2 噪声类型
类型 噪声 训练噪声 Babble, Factory1, Volvo, White, F16, Pink, Tank, Machinegun, Office, Street, Restaurant, Bell, Alarm, Destroyer, Hfchannel, Alarm, Traffic, Animal, Wind, Cry, Shower, Laugh 测试噪声(匹配噪声) Babble, Factory1, Volvo, White, F16, Hfchannel, Street, Restaurant 测试噪声(不匹配噪声) Factory2, Buccaneer1, Engine , Leopard, Destroyer, Crowd
下载: 导出CSV
表 3 网络取不同膨胀率对增强语音的PESQ和STOI(%)影响
膨胀率
(编解码层)膨胀率
(传输层)PESQ STOI (%) 1,2,5 1,2,4,8,1,2,4,8 2.697 84.34 1,2,5 1,2,5,9,1,2,5,9 2.722 84.68 1,2,4 1,2,4,8,1,2,5,9 2.708 84.45 1,2,4 1,2,5,9,2,5,9,17 2.769 84.90
下载: 导出CSV
表 4 AG的数量对增强语音PESQ和STOI(%)影响
AG数量 PESQ STOI (%) 参数量 (M) 0 2.688 84.05 1.226 1 2.711 84.36 1.233 2 2.753 84.80 1.246 3 2.764 84.90 1.249 4 2.769 84.90 1.250
下载: 导出CSV
表 5 匹配噪声下各方法的平均STOI(%)和PESQ
PESQ STOI(%) –5 0 5 10 均值 –5 0 5 10 均值 含噪语音 1.389 1.595 1.856 2.183 1.756 58.21 65.71 72.63 78.42 68.74 谱减法 1.478 1.682 2.158 2.331 1.912 61.58 70.47 75.28 82.43 72.44 RCED 1.875 2.272 2.601 2.815 2.391 71.34 79.91 83.62 86.13 80.25 CRN 2.184 2.525 2.731 2.907 2.587 72.47 82.06 85.68 88.87 82.27 BiLSTM 2.123 2.507 2.765 2.957 2.588 72.85 82.81 86.53 89.62 82.95 GRN 2.201 2.618 2.877 3.023 2.680 74.12 84.03 87.91 90.03 84.02 AU-net 2.286 2.589 2.854 3.105 2.709 76.08 84.32 87.46 90.52 84.60 NAAGN 2.324 2.687 2.856 3.208 2.769 76.92 84.21 87.95 90.89 84.99 本文 2.365 2.714 3.002 3.254 2.834 76.58 84.79 89.13 92.12 85.66
下载: 导出CSV
表 6 不匹配噪声下各方法的平均STOI(%)和PESQ
PESQ STOI(%) –5 0 5 10 均值 –5 0 5 10 均值 含噪语音 1.402 1.674 1.927 2.238 1.810 57.74 65.70 73.02 78.33 68.70 谱减法 1.511 1.721 2.149 2.374 1.939 62.16 68.79 76.02 82.58 72.39 RCED 1.823 2.181 2.495 2.696 2.299 68.87 76.97 82.18 85.22 78.31 CRN 1.915 2.401 2.592 2.768 2.419 70.73 78.01 84.13 86.45 79.83 BiLSTM 1.893 2.387 2.625 2.794 2.425 70.98 79.49 84.62 88.21 80.83 GRN 2.043 2.486 2.725 2.891 2.536 72.97 82.62 86.34 88.97 82.73 AU-net 2.121 2.495 2.731 2.942 2.572 73.66 83.05 86.08 89.22 83.00 NAAGN 2.134 2.486 2.802 2.955 2.594 73.99 83.18 86.47 89.15 83.20 本文 2.224 2.621 2.865 3.108 2.705 74.37 83.55 87.58 91.05 84.14
下载: 导出CSV
表 7 各方法的CSIG, CBAK和COVL得分
对比方法 含噪语音 谱减法 RCED CRN BiLSTM GRN AU-net NAAGN 本文 CSIG 2.98 3.27 2.74 3.15 3.24 3.49 3.69 3.76 4.13 CBAK 1.63 2.11 2.66 2.75 2.83 3.00 3.22 3.10 3.49 COVL 1.85 2.15 2.45 2.82 2.80 3.15 3.21 3.29 3.38
下载: 导出CSV
-
[1] YELWANDE A, KANSAL S, and DIXIT A. Adaptive wiener filter for speech enhancement[C]. International Conference on Information, Communication, Instrumentation and Control, Indore, India, 2017: 1–4. [2] MIYAZAKI R, SARUWATARI H, INOUE T, et al. Musical-noise-free speech enhancement based on optimized iterative spectral subtraction[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(7): 2080–2094. doi: 10.1109/TASL.2012.2196513 [3] HENDRIKS R C, HEUSDENS R, and JENSEN J. An MMSE estimator for speech enhancement under a combined stochastic–deterministic speech model[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(2): 406–415. doi: 10.1109/TASL.2006.881666 [4] XU Yong, DU Jun, DAI Lirong, et al. An experimental study on speech enhancement based on deep neural networks[J]. IEEE Signal Processing Letters, 2014, 21(1): 65–68. doi: 10.1109/LSP.2013.2291240 [5] WANG Qing, DU Jun, DAI Lirong, et al. Joint noise and mask aware training for DNN-based speech enhancement with SUB-band features[C]. 2017 Hands-free Speech Communications and Microphone Arrays, San Francisco, USA, 2017: 101–105. [6] SALEEM N, KHATTAK M I, AL-HASAN M, et al. On learning spectral masking for single channel speech enhancement using feedforward and recurrent neural networks[J]. IEEE Access, 2020, 8: 160581–160595. doi: 10.1109/ACCESS.2020.3021061 [7] GERS F A, SCHMIDHUBER J, and CUMMINS F. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451–2471. doi: 10.1162/089976600300015015 [8] LI Xiaoqi, LI Yaxing, DONG Yuanjie, et al. Bidirectional LSTM network with ordered neurons for speech enhancement[C]. Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 2020: 2702–2706. [9] YOUSEFI M and HANSEN J H L. Block-based high performance CNN architectures for frame-level overlapping speech detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 28–40. doi: 10.1109/TASLP.2020.3036237 [10] CHOI H, PARK S, PARK J, et al. Multi-speaker emotional acoustic modeling for CNN-based speech synthesis[C]. 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 2019: 6950–6954. [11] PARK S R and LEE J W. A fully convolutional neural network for speech enhancement[C]. Proceedings of the Interspeech 2017, Stockholm, Sweden, 2017: 1993–1997. [12] TAN Ke and WANG Deliang. A convolutional recurrent neural network for real-time speech enhancement[C]. Proceedings of the Interspeech 2018, Hyderabad, India, 2018: 3229–3233. [13] TAN Ke, CHEN Jitong, and WANG Deliang. Gated residual networks with dilated convolutions for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(1): 189–198. doi: 10.1109/TASLP.2018.2876171 [14] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [15] RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. [16] DENG Feng, JIANG Tao, WANG Xiaorui, et al. NAAGN: Noise-aware attention-gated network for speech enhancement[C]. Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 2020: 2457–2461. [17] OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention U-Net: Learning where to look for the pancreas[J]. arXiv: 1804.03999, 2018. [18] WANG Yu, ZHOU Quan, LIU Jie, et al. Lednet: A lightweight encoder-decoder network for real-time semantic segmentation[C]. 2019 IEEE International Conference on Image Processing, Taipei, China, 2019: 1860–1864. [19] HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2261–2269. [20] SUBAKAN C, RAVANELLI M, CORNELL S, et al. Attention is all you need in speech separation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 21–25. [21] DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks[C]. Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 2017: 933–941. [22] HU Jie, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011–2023. doi: 10.1109/TPAMI.2019.2913372 [23] KANEKO T, KAMEOKA H, TANAKA K, et al. Cyclegan-VC2: Improved cyclegan-based non-parallel voice conversion[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 2019: 6820–6824. [24] GAROFOLO J S, LAMEL L F, FISHER W M, et al. Darpa Timit acoustic-phonetic continuous speech corpus CD-ROM {TIMIT}[R]. NIST Interagency/Internal Report (NISTIR)-4930, 1993. [25] ITU-T. P. 862 Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs[S]. International Telecommunications Union (ITU-T) Recommendation, 2001: 862. [26] TAAL C H, HENDRIKS R C, HEUSDENS R, et al. An algorithm for intelligibility prediction of time–frequency weighted noisy speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(7): 2125–2136. doi: 10.1109/TASL.2011.2114881 -

 下载:
下载:







图(9) / 表(7)
计量
- 文章访问数: 1353
- HTML全文浏览量: 1277
- PDF下载量: 122
- 被引次数: 0
