

Traffic Classification Method Based on Dynamic Balance Adaptive Transfer Learning
-
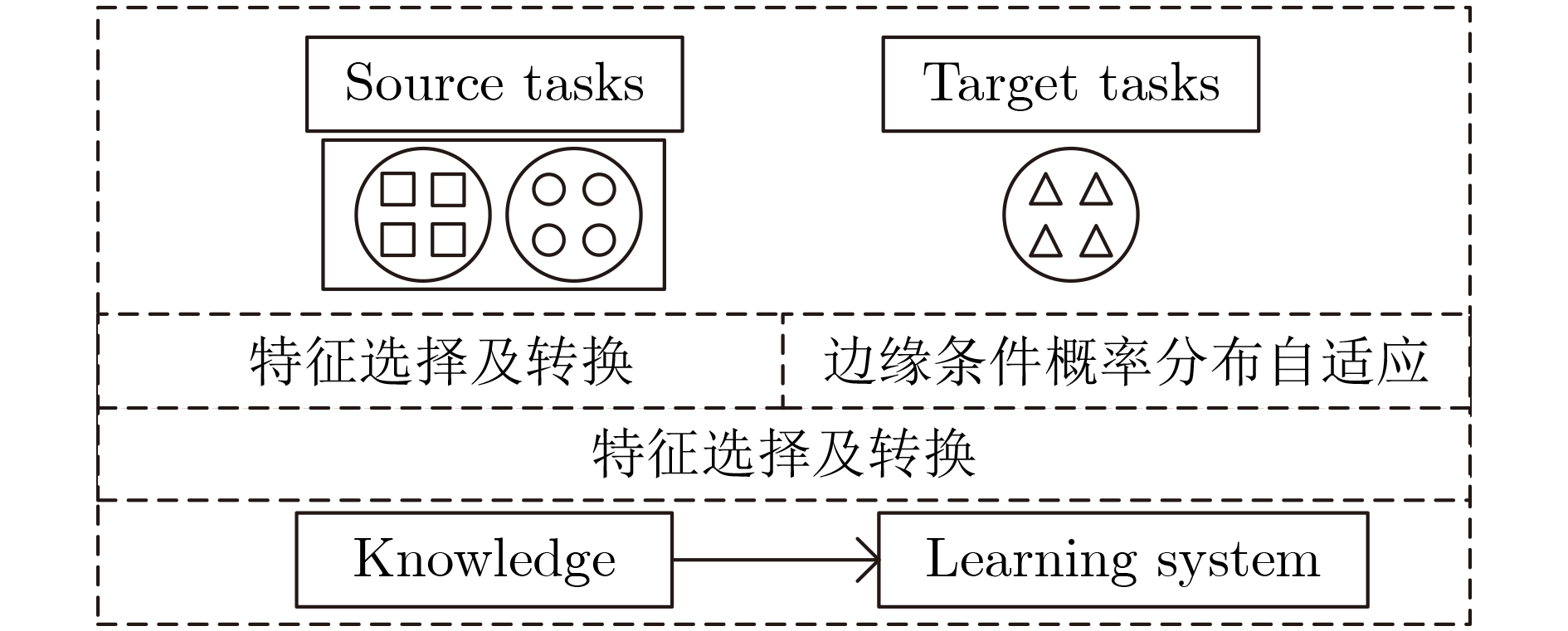
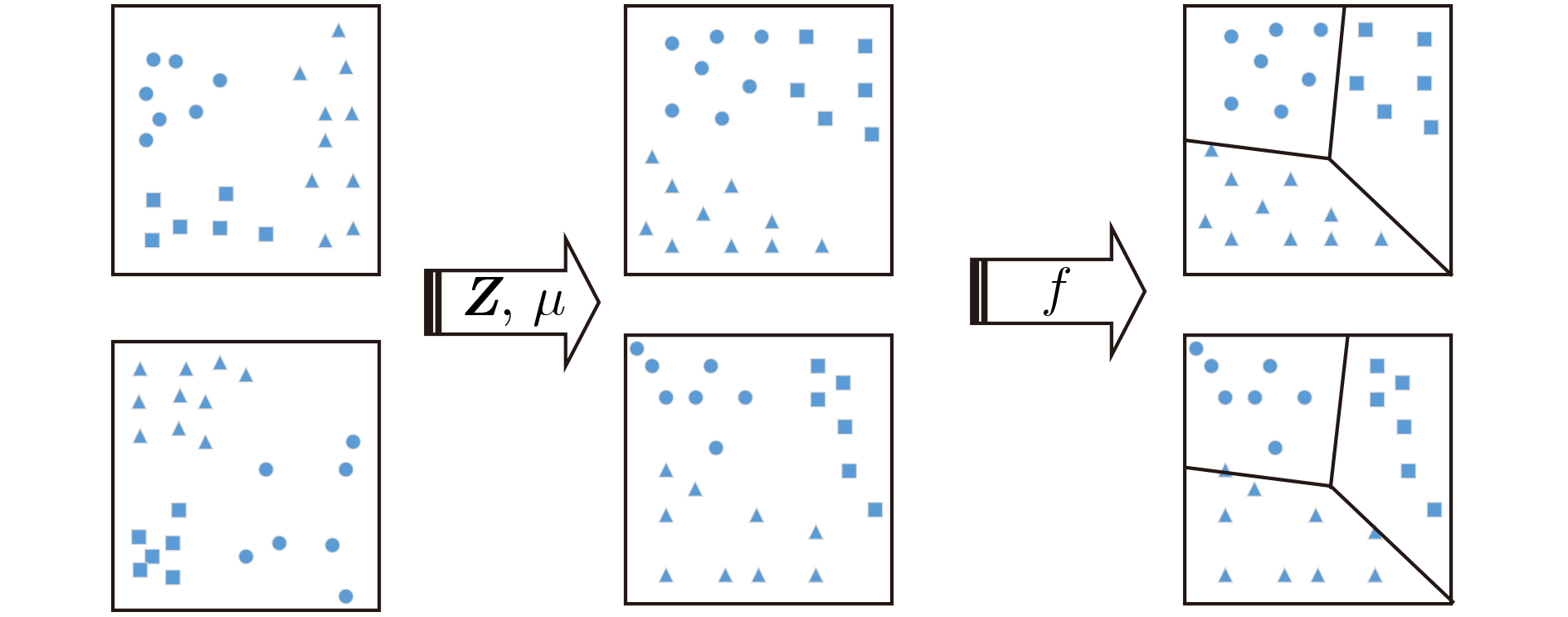
摘要: 针对应用流量识别性能和准确率降低等问题,该文提出一种动态平衡自适应迁移学习的流量分类算法。首先将迁移学习引入到应用流量识别中,通过将源领域和目标领域的样本特征映射到高维特征空间中,使得源领域和目标领域的边缘分布与条件分布距离尽量小,提出使用概率模型来判断和计算域之间的边缘分布与条件分布的区别,利用概率模型对分类类别确认度的大小,定量来计算平衡因子
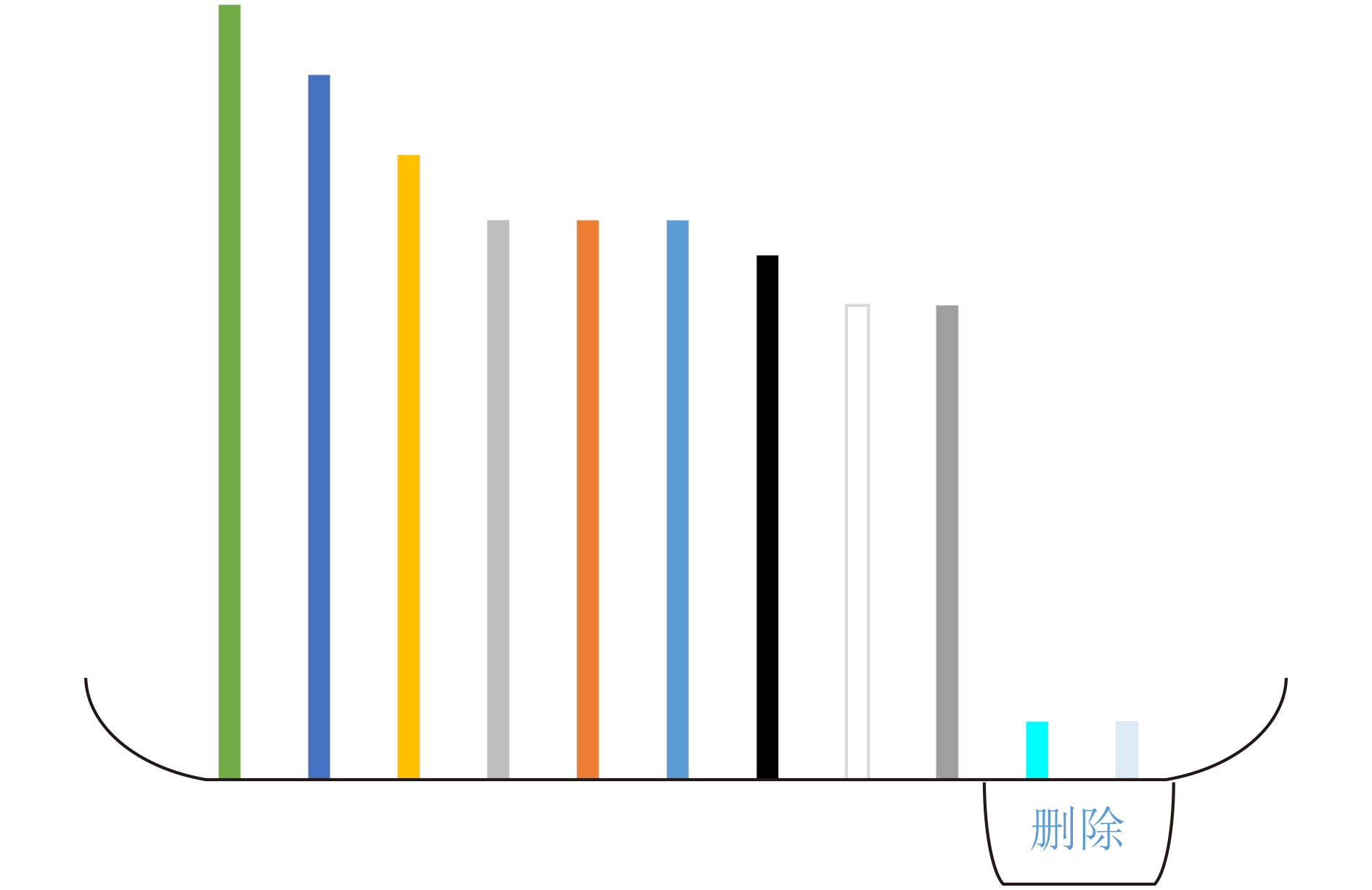
$ \mu $ ,解决DDA中只考虑到分类错误率,没有考虑到确认度的问题。然后引入断崖式下跌策略动态确定特征主元的数量,将进行转换后的特征使用基础分类器进行训练,通过不断的迭代训练,将最终得到的分类器应用到最新的移动终端应用识别上,比传统机器学习方法的准确率平均提高了7%左右。最后针对特征维度较高的问题,引入逆向特征自删除策略,结合推土机距离(EMD),使用信息增益权重推土机相关系数,提出了针对应用流量识别的特征选择算法,解决了部分特征对模型的分类无法起到任何的帮助,仅仅导致模型的训练时间增加,甚至由于无关特征的存在导致模型的性能和准确率降低等问题,将经过选择处理的特征集作为迁移学习的训练输入数据,使得迁移算法的时间缩短大约80%。Abstract: In this paper, an improved and adaptive transfer learning algorithm is proposed for mobile application traffic recognition filed, which maps the sample features of source domain and target domain into high-dimensional feature space to minimize the marginal distribution and conditional distribution distances of the domains. A probabilistic model is presented to judge and calculate the difference between marginal distribution and conditional distribution between the domains. It can determine the degree of classification category and calculate quantitively the balance factor$ \mu $ , which solves effectively the problem that DDA only considers classification error rate and ignores the degree of confirmation. Besides, the cliff-type down strategy is introduced to determine dynamically the number of feature principal. Compared with the traditional machine learning method, the proposed algorithm improves the accuracy by about 7%. Moreover, a feature selection algorithm for application traffic recognition is proposed to solve the problem of high feature dimension, where the reverse feature self-deleting strategy combined with the Earth Mover’s Distance (EMD) and used the correlation coefficient of the bulldozer to weight the information gain is introduced. It solves the problems that increasing the training time of model due to invalid features and decreasing the model performance and accuracy caused by irrelevant features. Simulation result shows that when the training input data for transfer learning uses the feature set processed by the proposed algorithm, the time of the transfer algorithm can be shortened by about 80%.-
Key words:
- Transfer learning /
- Application recognition /
- Feature extraction /
- Cross-domain
-
表 1 有标签的半监督平衡分配适应算法
输入:源数据 $ {\boldsymbol{X}}_{s} $,目标数据$ {\boldsymbol{X}}_{t} $,源数据标签$ {Y}_{s} $和目标数据标
签$ {Y}_{t} $,迭代次数 T。输出:分类器 $ f $ Begin: (1) 选择概率模型$ {\mu }_{0}=\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{r}\mathrm{t}\mathrm{M}\mathrm{u}({\boldsymbol{X}}_{s},{\boldsymbol{X}}_{t}) $ (2) $ \mathrm{v}\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{c}\mathrm{k}({\boldsymbol{X}}_{s},{\boldsymbol{X}}_{t}) $, create H (3) for i=0 to T do: (4) updata $ {\boldsymbol{M}}_{0} $ (5) for j=0 to C do: (6) if c not in Y_tar_predic (7) continue (8) if c in Y_tar_predic (9) compute $ {\boldsymbol{M}}_{c} $, updata $ \boldsymbol{M} $ (10) if Y tar_predic is not None (11) updata $ \mu $ (12) else (13) updata $ \mu $ (14) values, vector := eig(dot(K,M,K.T), dot(K,H,K.T)) (15) use (23) select $ {\mathrm{v}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{o}\mathrm{r}}_{\mathrm{p}\mathrm{o}\mathrm{r}\mathrm{t}} $ (16) classifier.fit($ {X}_{\mathrm{t}\mathrm{r}\mathrm{a}\mathrm{i}\mathrm{n}},{Y}_{\mathrm{t}\mathrm{r}\mathrm{a}\mathrm{i}\mathrm{n}} $) (17) $\widehat{{y} }=\mathrm{p}\mathrm{r}\mathrm{e}\mathrm{d}\mathrm{i}\mathrm{c}\mathrm{t}\left({X}_{ {\mathrm{t} }_{\mathrm{n}\mathrm{e}\mathrm{w} } }\right)$ (18) updata W (19)return classifier: $ f $ End  下载: 导出CSV
下载: 导出CSV
表 2 添加20%目标领域样本半监督学习结果(%)
类别 传统算法 迁移学习算法 k-NN PCA SVM GFK TCA JDA BDA SMTADA C→A 23.7 39.5 53.1 46.0 45.6 43.1 44.9 64.9 C→W 25.8 34.6 41.7 37.0 39.3 39.9 38.6 66.1 C→D 25.5 44.6 47.8 40.8 45.9 49.0 47.8 59.2 A→C 26.0 39.0 41.7 40.7 42.0 40.9 40.9 60.7 A→W 29.8 35.9 31.9 37.0 40.0 38.0 39.3 52.9 A→D 25.5 33.8 44.6 40.1 35.7 42.0 43.3 60.5 W→C 19.9 28.2 28.2 24.8 31.5 33.0 28.9 58.0 W→A 23.0 29.1 27.6 27.6 30.5 29.8 33.0 66.7 W→D 59.2 89.2 78.3 85.4 86.0 89.2 91.7 90.4 D→C 26.3 29.7 26.4 29.3 33.0 31.2 32.5 59.9 D→A 28.5 33.2 26.2 28.7 32.8 33.4 33.1 71.3 D→W 63.4 86.1 52.5 80.3 87.5 89.2 91.9 85.1 平均 31.4 43.6 41.6 43.1 45.8 46.6 47.2 67.1
下载: 导出CSV
表 3 应用流量实验对比结果(%)
流量类别 传统学习算法 迁移学习算法 RandomForest k-NN GaussianNB BDA SMTADA 1→12 90.6 90.4 84.3 87.1 97.2 2→12 91.8 91.9 83.8 87.6 97.9 3→12 90.8 91.4 85.8 88.2 97.5 4→12 91.8 90.0 84.6 87.4 97.3 5→12 92.0 90.4 84.1 91.5 98.0 6→12 91.4 89.7 85.4 87.8 98.2 7→12 89.7 92.0 86.5 91.3 97.1 8→12 92.8 91.5 86.8 88.6 96.6 9→12 91.9 89.6 84.8 88.1 96.8 10→12 90.2 92.6 86.3 81.9 98.1 平均 91.3 90.95 85.24 87.95 97.47
下载: 导出CSV
表 4 所选特征的部分含义
序号 简称 全称 109 idletime_max_b a 服务端到客户端时连续数据包之间的最大空闲时间 119 RTT_avg_b a 服务端到客户端的RTT平均值 123 RTT_from_3WHS_b a 服务端到客户端TCP 3次握手所计算RTT时间 126 RTT_full_sz_min_a b 客户端到服务端最小RTT样例 223 FFT_all 所有包的IAT傅里叶变换(频率6) 110 Throughput_a b 客户端到服务端的平均吞吐量 1 Client Port 客户端服务端口号 243 FFT_b a 服务端到客户端分组IAT反正切傅里叶变换(频率6) 106 data_xmit_a b 客户端到服务端总数据传输时间 221 FFT_all 所有包的IAT傅里叶变换(频率4) 114 RTT_min_a b 客户端到服务端的最小RTT样例 241 FFT_b a 服务端到客户端分组IAT反正切傅里叶变换(频率4) … … …
下载: 导出CSV
表 5 逆向选择策略所选特征实验结果(%)
流量类别 传统学习算法 迁移学习算法 RandomForest k-NN GaussianNB BDA SMTADA SMTADA(P) 1→12 90.6 90.4 84.3 95.3 97.0 97.2 2→12 91.8 91.9 83.8 94.7 96.1 97.9 3→12 90.8 91.4 85.8 93.9 95.9 97.5 4→12 91.8 90.0 84.6 95.8 96.6 97.3 5→12 92.0 90.4 84.1 94.4 95.4 98.0 6→12 91.4 89.7 85.4 94.1 97.2 98.2 7→12 89.7 92.0 86.5 92.7 96.4 97.1 8→12 92.8 91.5 86.8 93.6 96.2 96.6 9→12 91.9 89.6 84.8 91.8 95.5 96.8 10→12 90.2 92.6 86.3 95.1 97.2 98.1 平均 91.3 90.95 85.24 94.14 96.35 97.47
下载: 导出CSV
-
[1] 邹腾宽, 汪钰颖, 吴承荣. 网络背景流量的分类与识别研究综述[J]. 计算机应用, 2019, 39(3): 802–811. doi: 10.11772/j.issn.1001-9081.2018071552ZOU Tengkuan, WANG Yuying, and WU Chengrong. Review of network background traffic classification and identification[J]. Journal of Computer Applications, 2019, 39(3): 802–811. doi: 10.11772/j.issn.1001-9081.2018071552 [2] SUN Guanglu, LIANG Lili, CHEN Teng, et al. Network traffic classification based on transfer learning[J]. Computers & Electrical Engineering, 2018, 69: 920–927. doi: 10.1016/j.compeleceng.2018.03.005 [3] 李猛, 李艳玲, 林民. 命名实体识别的迁移学习研究综述[J]. 计算机科学与探索, 2020, 15(2): 206–218. doi: 10.3778/j.issn.1673-9418.2003049LI Meng, LI Yanling, and LIN Min. Review of transfer learning for named entity recognition[J]. Journal of Frontiers of Computer Science and Technology, 2020, 15(2): 206–218. doi: 10.3778/j.issn.1673-9418.2003049 [4] WANG Jindong. Concise handbook of transfer learning[EB/OL].https://www.sohu.com/a/420774574_114877. [5] 李号号. 基于实例的迁移学习技术研究及应用[D]. [硕士论文], 武汉大学, 2018.LI Haohao. Research and application of instance-based transfer learning[D]. [Master dissertation], Wuhan University, 2018. [6] PAN S J, TSANG I W, KWOK J T, et al. Domain adaptation via transfer component analysis[J]. IEEE Transactions on Neural Networks, 2011, 22(2): 199–210. doi: 10.1109/TNN.2010.2091281 [7] 季鼎承, 蒋亦樟, 王士同. 基于域与样例平衡的多源迁移学习方法[J]. 电子学报, 2019, 47(3): 692–699.JI Dingcheng, JIANG Yizhang, and WANG Shitong. Multi-source transfer learning method by balancing both the domains and instances[J]. Acta Electronica Sinica, 2019, 47(3): 692–699. [8] YAO Yi and DORETTO G. Boosting for transfer learning with multiple sources[C]. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, USA, 2010: 1855–1862. [9] 唐诗淇, 文益民, 秦一休. 一种基于局部分类精度的多源在线迁移学习算法[J]. 软件学报, 2017, 28(11): 2940–2960. doi: 10.13328/j.cnki.jos.005352TANG Shiqi, WEN Yimin, and QIN Yixiu. Online transfer learning from multiple sources based on local classification accuracy[J]. Journal of Software, 2017, 28(11): 2940–2960. doi: 10.13328/j.cnki.jos.005352 [10] 张博, 史忠植, 赵晓非, 等. 一种基于跨领域典型相关性分析的迁移学习方法[J]. 计算机学报, 2015, 38(7): 1326–1336. doi: 10.11897/SP.J.1016.2015.01326ZHANG Bo, SHI Zhongzhi, ZHAO Xiaofei, et al. A transfer learning based on canonical correlation analysis across different domains[J]. Chinese Journal of Computers, 2015, 38(7): 1326–1336. doi: 10.11897/SP.J.1016.2015.01326 [11] 张宁. 基于决策树分类器的迁移学习研究[D]. [硕士论文], 西安电子科技大学, 2014.ZHANG Ning. Research on transfer learning based on decision tree classifier[D]. [Master dissertation], Xidian University, 2014. [12] 洪佳明, 印鉴, 黄云, 等. TrSVM: 一种基于领域相似性的迁移学习算法[J]. 计算机研究与发展, 2011, 48(10): 1823–1830.HONG Jiaming, YIN Jian, HUANG Yun, et al. TrSVM: A transfer learning algorithm using domain similarity[J]. Journal of Computer Research and Development, 2011, 48(10): 1823–1830. [13] FADDOUL J B and CHIDLOVSKII B. Learning multiple tasks with boosted decision trees[P]. US, 8694444, 2014. [14] WAN Zitong, YANG Rui, HUANG Mengjie, et al. A review on transfer learning in EEG signal analysis[J]. Neurocomputing, 2021, 421: 1–14. doi: 10.1016/j.neucom.2020.09.017 [15] TAN Ben, ZHANG Yu, PAN S, et al. Distant domain transfer learning[C]. The Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, USA, 2017: 2604–2610. [16] CHIANG K J, WEI Chunshu, NAKANISHI M, et al. Boosting template-based SSVEP decoding by cross-domain transfer learning[J]. Journal of Neural Engineering, 2021, 18(1): 016002. doi: 10.1088/1741-2552/abcb6e [17] NIU Shuteng, HU Yihao, WANG Jian, et al. Feature-based distant domain transfer learning[C]. 2020 IEEE International Conference on Big Data (Big Data), Atlanta, USA, 2020: 5164–5171. [18] DUAN Lixin, XU Dong, and TSANG I W H. Domain adaptation from multiple sources: A domain-dependent regularization approach[J]. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(3): 504–518. doi: 10.1109/TNNLS.2011.2178556 [19] WANG Jindong, CHEN Yiqiang, FENG Wenjie, et al. Transfer learning with dynamic distribution adaptation[J]. ACM Transactions on Intelligent Systems and Technology, 2020, 11(1): 6. doi: 10.1145/3360309 [20] JIANG R, PACCHIANO A, STEPLETON T, et al. Wasserstein fair classification[C]. The Thirty-Fifth Conference on Uncertainty in Artificial Intelligence, Tel Aviv, Israel, 2019: 862–872. [21] PRONZATO L. Performance analysis of greedy algorithms for minimising a maximum mean discrepancy[J]. arXiv preprint arXiv: 2101.07564, 2021. [22] 张东光. 统计学[M]. 2版. 北京: 科学出版社, 2020: 161–169.ZHANG Dongguang. Statistics[M]. 2nd ed. Beijing: China Science Press, 2020: 161–169. [23] MOORE A W and ZUEV D. Internet traffic classification using bayesian analysis techniques[J]. ACM SIGMETRICS Performance Evaluation Review, 2005, 33(1): 50–60. doi: 10.1145/1071690.1064220 -





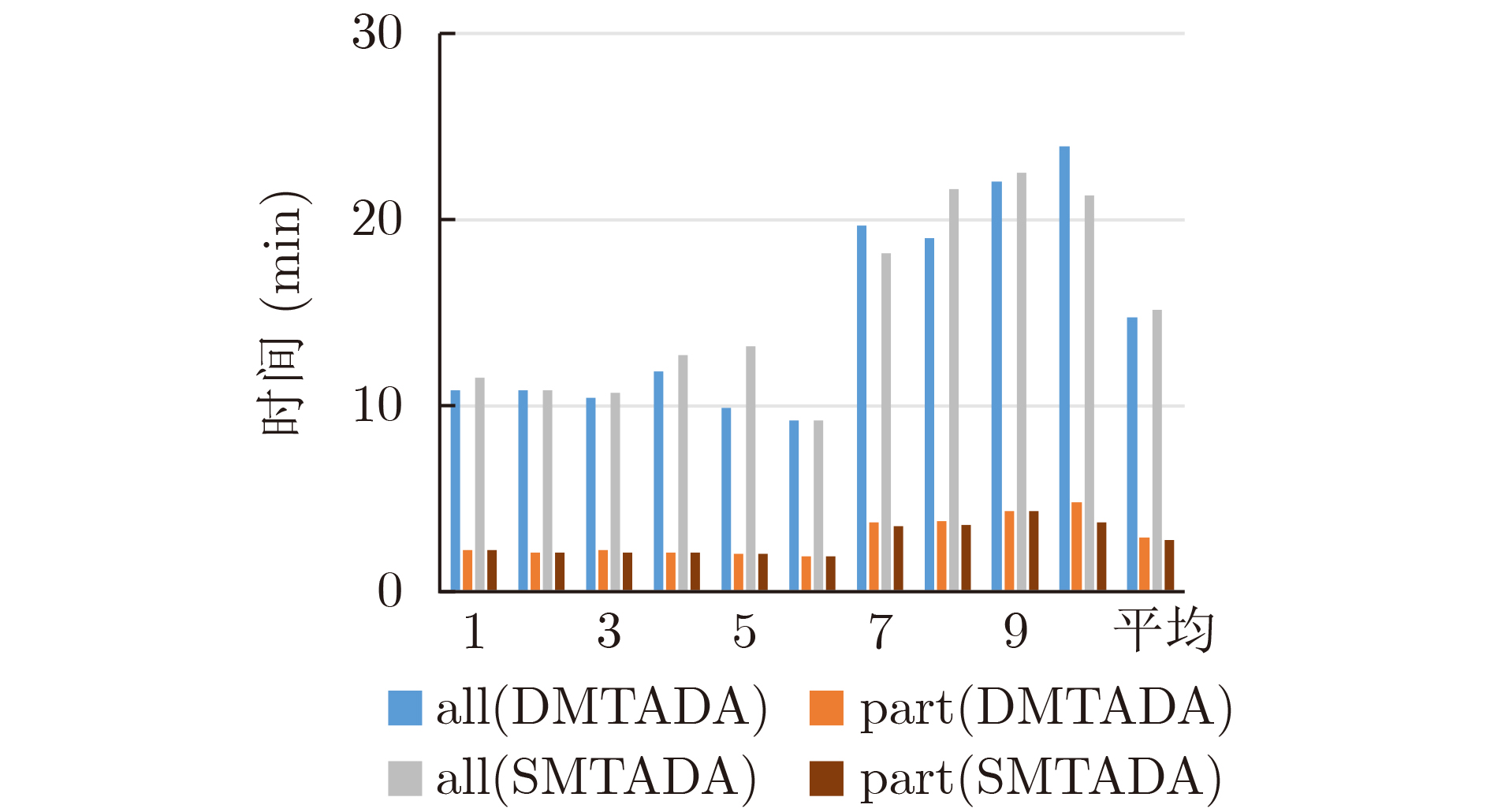


图(7) / 表(5)
计量
- 文章访问数: 1410
- HTML全文浏览量: 1016
- PDF下载量: 107
- 被引次数: 0
 下载:
下载:
