

Linear Coprime Sensor Location Arrays: Mutual Coupling Effect and Angle Estimation
-
摘要: 该文研究了阵元位置互质的线性阵列(CLA)的互耦分析和角度估计问题。首先,给出了阵元位置互质的线性阵列的定义,证明了其导向矢量是不模糊的。随后,利用高阶累积量,建立了阵列输出信号的3阶张量模型,并通过张量分解得到导向矢量的估计。最后,利用得到的导向矢量估计,推导了一种无模糊的信号角度估计的方法。CLA可将相邻阵元间的间距设计远大于半波长,因此可显著降低阵列互耦效应。通过阻抗匹配互耦模型比较了CLA和常用典型阵列结构的互耦与角度估计性能,表明了CLA的有效性。Abstract: This paper investigates the problems of mutual coupling analysis and angle estimation for linear Coprime sensor Linear Arrays (CLA). Firstly, the CLA is defined. It is proved that the steering vector CLA is unambiguous. Afterwards, based on high-order cumulants, a third-order tensor model of the array output is established. Array steering vectors are subsequently estimated via tensor decomposition. Finally, unambiguous direction estimates are derived from the estimated steering vectors. The sensor spacings of the CLA can be designed as much greater than a half-wavelength, thereby significantly reducing array mutual coupling effect. Using impedance matching mutual coupling model, the mutual coupling effect and angle estimation performance are compared with the existing well-known array configurations to show the effectiveness of the CLA.
-
Key words:
- Non-uniform linear arrays /
- Coprime /
- Angle estimation /
- Arrays mutual coupling
-
[1] HERO A, MESSER H, GOLDBERG J, et al. Highlights of statistical signal and array processing[J]. IEEE Signal Processing Magazine, 1998, 15(5): 21–64. doi: 10.1109/79.708539 [2] 张小飞, 陈华伟, 仇小锋, 等. 阵列信号处理及MATLAB实现[M]. 北京: 电子工业出版社, 2015: 87–145. [3] 张小飞, 李建峰, 徐大专. 传感器阵列信源定位[M]. 北京: 电子工业出版社, 2018: 36–112. [4] PAL P and VAIDYANATHAN P P. Nested arrays: A novel approach to array processing with enhanced degrees of freedom[J]. IEEE Transactions on Signal Processing, 2010, 58(8): 4167–4181. doi: 10.1109/TSP.2010.2049264 [5] HAN Keyong and NEHORAI A. Wideband Gaussian source processing using a linear nested array[J]. IEEE Signal Processing Letters, 2013, 20(11): 1110–1113. doi: 10.1109/LSP.2013.2281514 [6] HAN Keyong and NEHORAI A. Nested array processing for distributed sources[J]. IEEE Signal Processing Letters, 2014, 21(9): 1111–1114. doi: 10.1109/LSP.2014.2325000 [7] HAN Keyong and NEHORAI A. Nested vector-sensor array processing via tensor modeling[J]. IEEE Transactions on Signal Processing, 2014, 62(10): 2542–2553. doi: 10.1109/TSP.2014.2314437 [8] HE Jin, ZHANG Zenghui, SHU Ting, et al. Direction finding of multiple partially polarized signals with a nested cross-diople array[J]. IEEE Antennas and Wireless Propagation Letters, 2017, 16: 1679–1682. doi: 10.1109/LAWP.2017.2665591 [9] ZHENG Zhi, FU Mingcheng, WANG Wenqin, et al. Localization of mixed near-field and far-field sources using symmetric double-nested arrays[J]. IEEE Transactions on Antennas and Propagation, 2019, 67(11): 7059–7070. doi: 10.1109/TAP.2019.2925199 [10] ZHANG Xiaofei, WANG Yunfei, and ZHENG Wang. Direction of arrival estimation of non-circular signals using modified nested array[C]. 2020 IEEE 11th Sensor Array and Multichannel Signal Processing Workshop (SAM), Hangzhou, China, 2020: 1–5. [11] 李建峰, 蒋德富, 沈明威. 基于平行嵌套阵互协方差的二维波达角联合估计算法[J]. 电子与信息学报, 2017, 39(3): 670–676. doi: 10.11999/JEIT160488LI Jianfeng, JIANG Defu, and SHEN Mingwei. Joint two-dimensional direction of arrival estimation based on cross covariance matrix of parallel nested array[J]. Journal of Electronics and Information Technology, 2017, 39(3): 670–676. doi: 10.11999/JEIT160488 [12] HE Jin, LI Linna, and SHU Ting. 2-D direction finding using parallel nested arrays with full co-array aperture extension[J]. Signal Processing, 2021, 178: 107795. doi: 10.1016/j.sigpro.2020.107795 [13] ZHENG Zhi and MU Shilin. 2-D direction finding with pair-matching operation for L-shaped nested array[J]. IEEE Communications Letters, 2021, 25(3): 975–979. doi: 10.1109/LCOMM.2020.3033152 [14] VAIDYANATHAN P P and PAL P. Sparse sensing with co-prime samplers and arrays[J]. IEEE Transactions on Signal Processing, 2011, 59(2): 573–586. doi: 10.1109/TSP.2010.2089682 [15] 周成伟, 郑航, 顾宇杰, 等. 互质阵列信号处理研究进展: 波达方向估计与自适应波束成形[J]. 雷达学报, 2019, 8(5): 558–577. doi: 10.12000/JR19068ZHOU Chengwei, ZHENG Hang, GU Yujie, et al. Research progress on coprime array signal processing: Direction-of-arrival estimation and adaptive beamforming[J]. Journal of Radars, 2019, 8(5): 558–577. doi: 10.12000/JR19068 [16] LIU Chunlin and VAIDYANATHAN P P. Super nested arrays: Linear sparse arrays with reduced mutual coupling- Part I: Fundamentals[J]. IEEE Transactions on Signal Processing, 2016, 64(15): 3997–4012. doi: 10.1109/TSP.2016.2558159 [17] LIU Jianyan, ZHANG Yanmei, LU Yilong, et al. Augmented nested arrays with enhanced DOF and reduced mutual coupling[J]. IEEE Transactions on Signal Processing, 2017, 65(21): 5549–5563. doi: 10.1109/TSP.2017.2736493 [18] SHI Junpeng, HU Guoping, ZHANG Xiaofei, et al. Generalized nested array: Optimization for degrees of freedom and mutual coupling[J]. IEEE Communications Letters, 2018, 22(6): 1208–1211. doi: 10.1109/LCOMM.2018.2821672 [19] HE Jin, LI Linna, and SHU Ting. Sparse nested arrays with spatially spread orthogonal dipoles: High accuracy passive direction finding with less mutual coupling[J]. IEEE Transactions on Aerospace and Electronic Systems, 2021, 57(4): 2337–2345. doi: 10.1109/TAES.2021.3054056 [20] MA Penghui, LI Jianfeng, ZHAO Gaofeng, et al. CAP-3 coprime array for DOA estimation with enhanced uniform degrees of freedom and reduced mutual coupling[J]. IEEE Communications Letters, 2021, 25(6): 1872–1875. doi: 10.1109/LCOMM.2021.3057403 [21] MENDEL J M. Tutorial on higher-order statistics (spectra) in signal processing and system theory: Theoretical results and some applications[J]. Proceedings of the IEEE, 1991, 79(3): 278–305. doi: 10.1109/5.75086 [22] SIDIROPOULOS N D, BRO R, and GIANNAKIS G B. Parallel factor analysis in sensor array processing[J]. IEEE Transactions on Signal Processing, 2000, 48(8): 2377–2388. doi: 10.1109/78.852018 [23] BALANIS C A. Antenna Theory: Analysis and Design[M]. 3rd ed. Hoboken, NJ, USA: John Wiley and Sons, 2005: 471–478. -

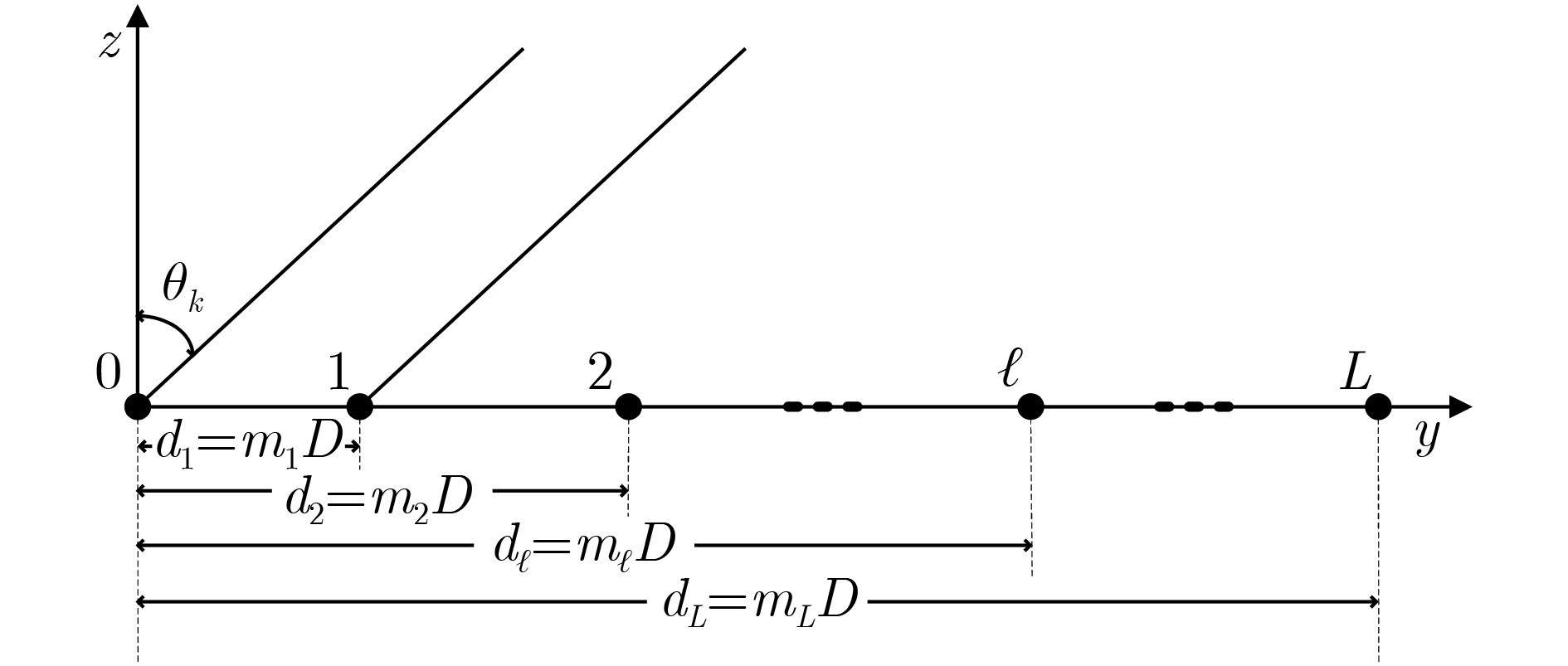
 下载:
下载:
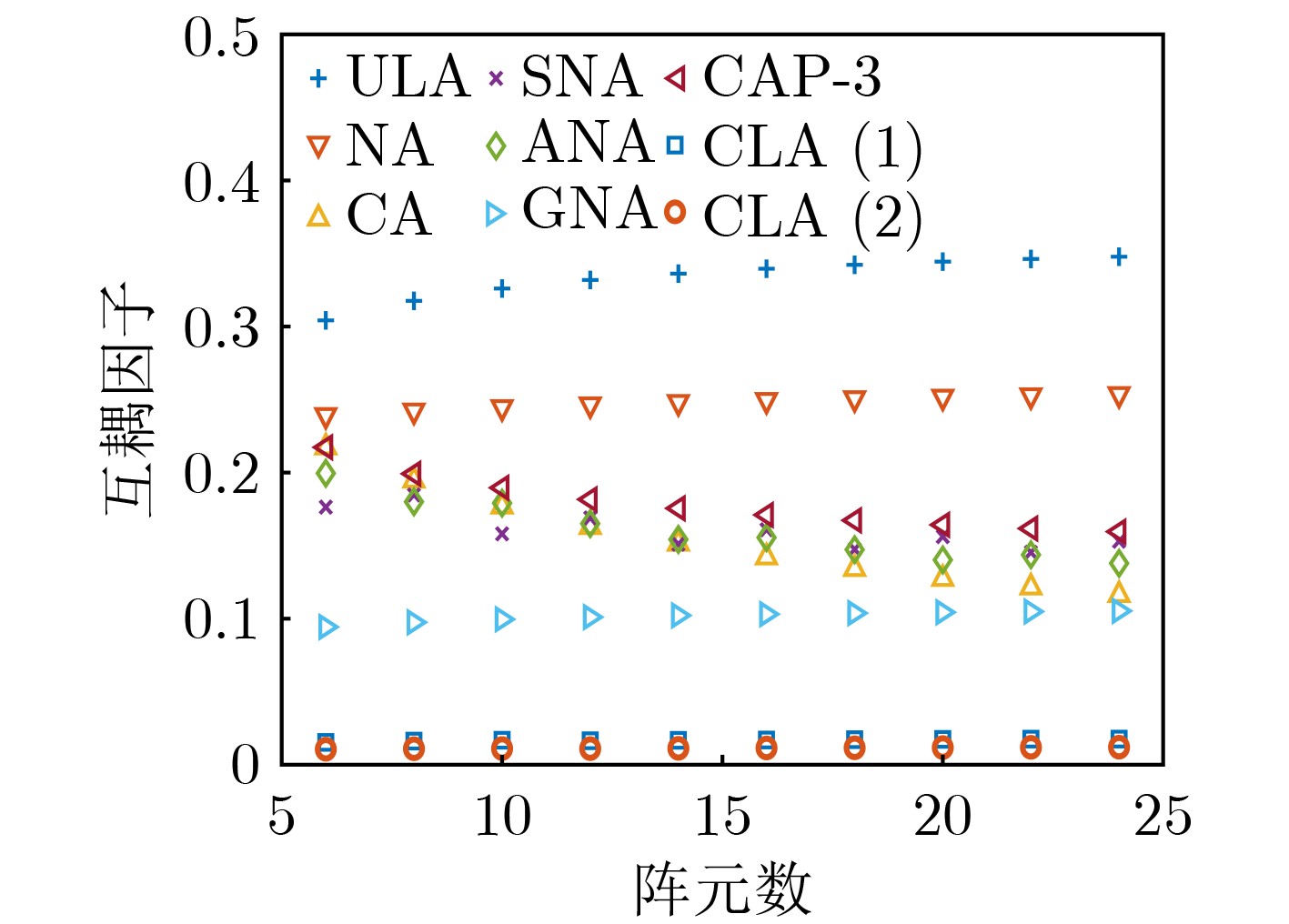
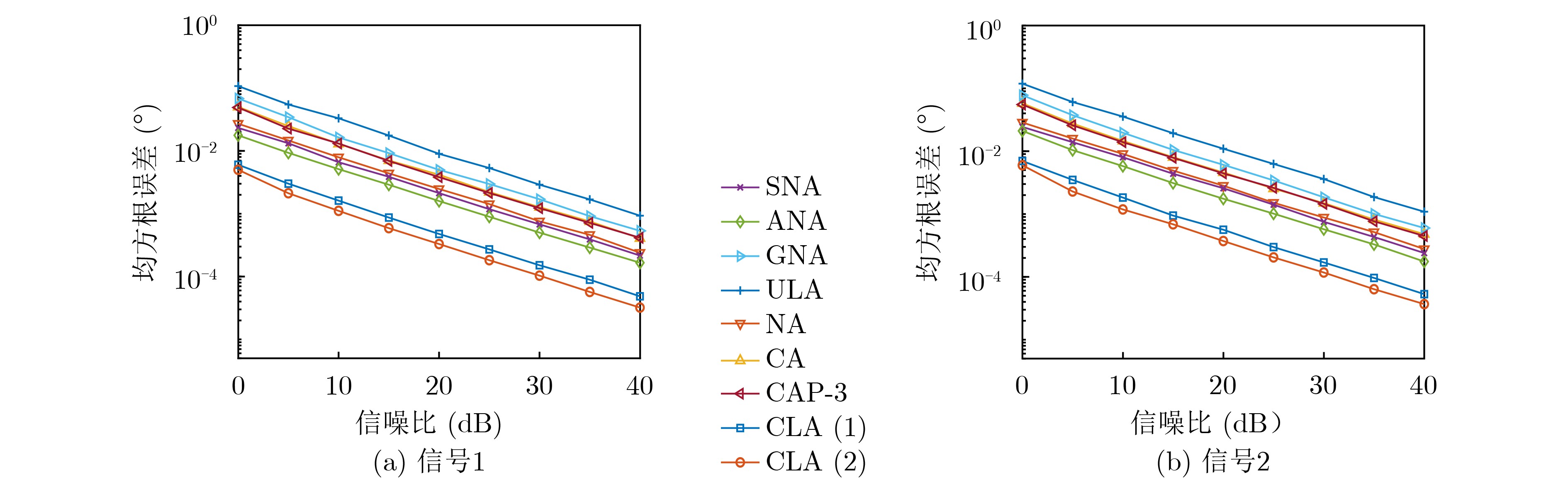
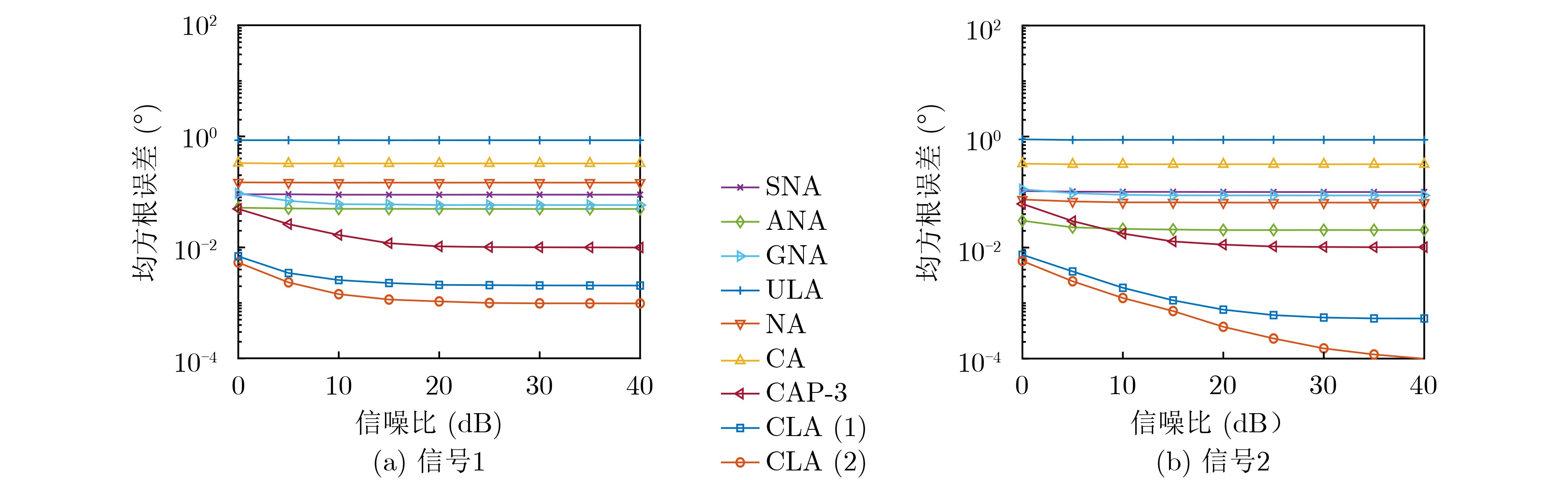
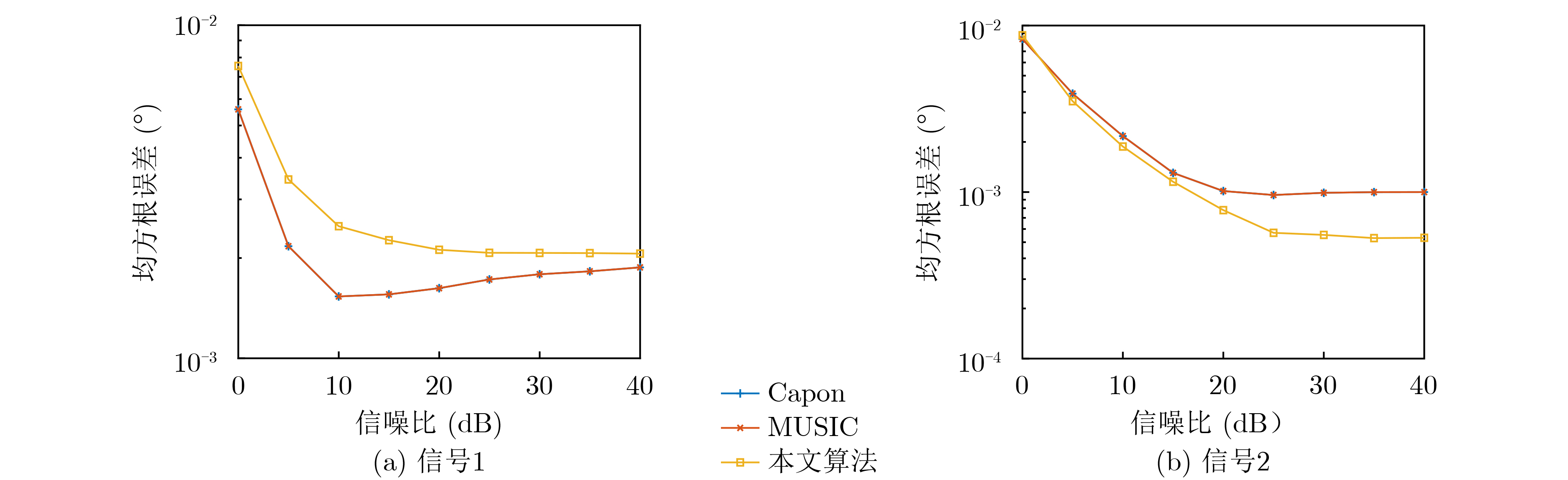


图(5)
计量
- 文章访问数: 1199
- HTML全文浏览量: 1323
- PDF下载量: 154
- 被引次数: 0
 下载:
下载:
