

Scene Constrained Object Detection Method in High-Resolution Remote Sensing Images by Relation-Aware Global Attention
-
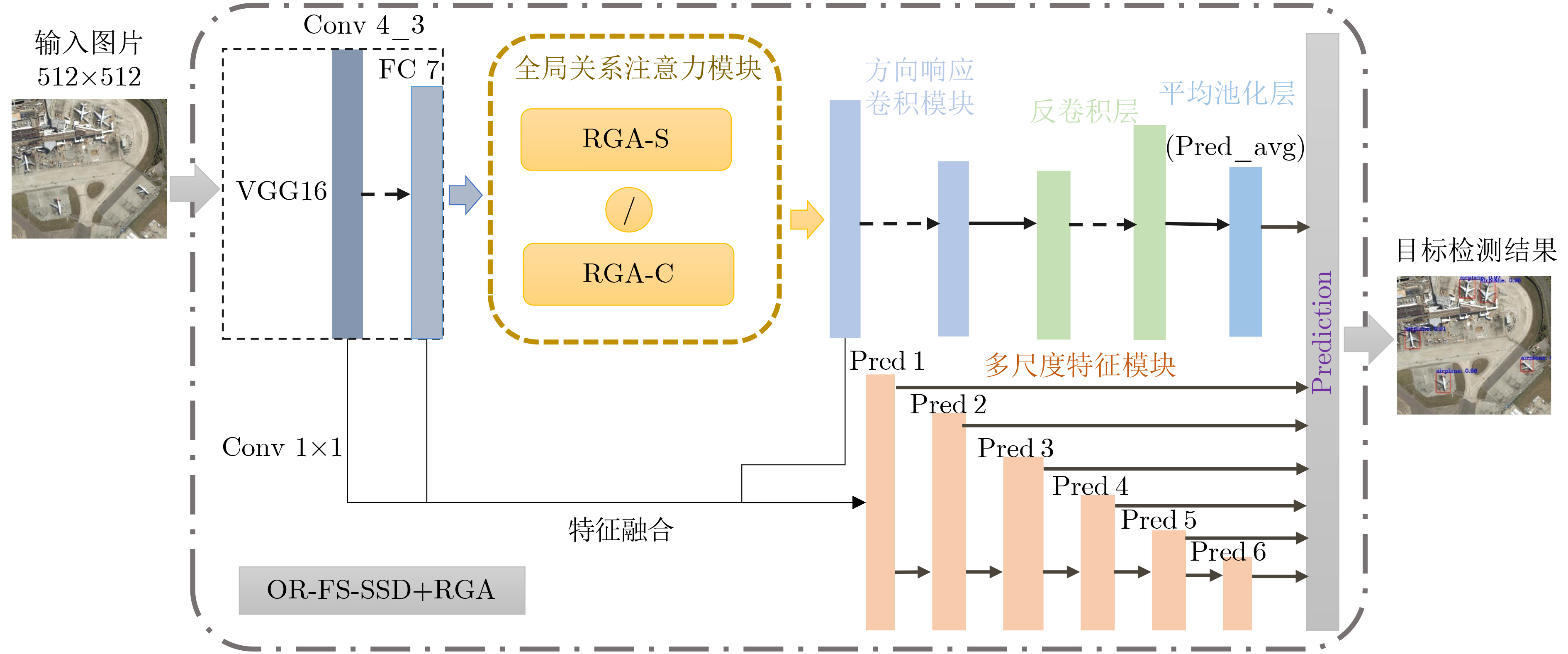
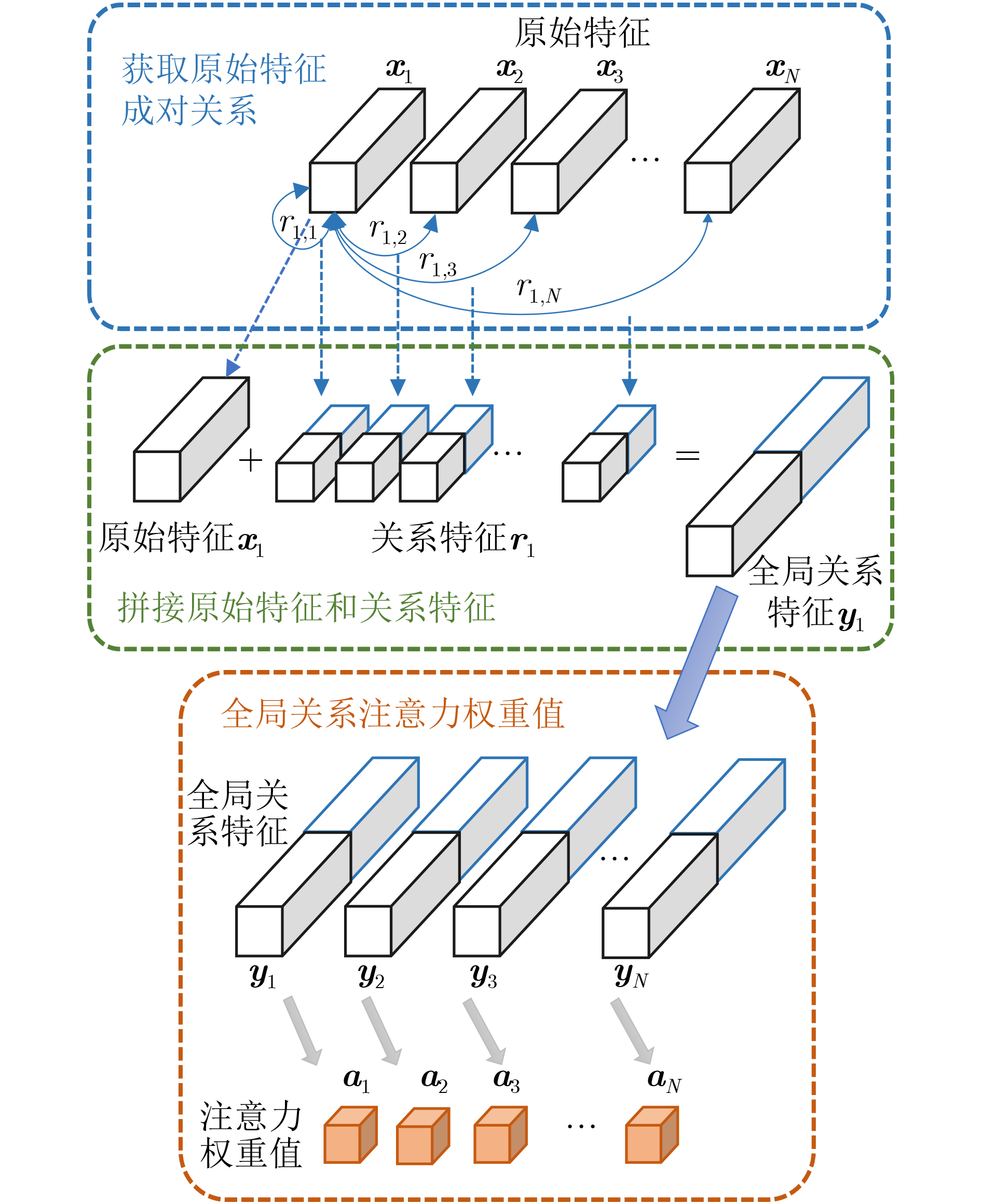
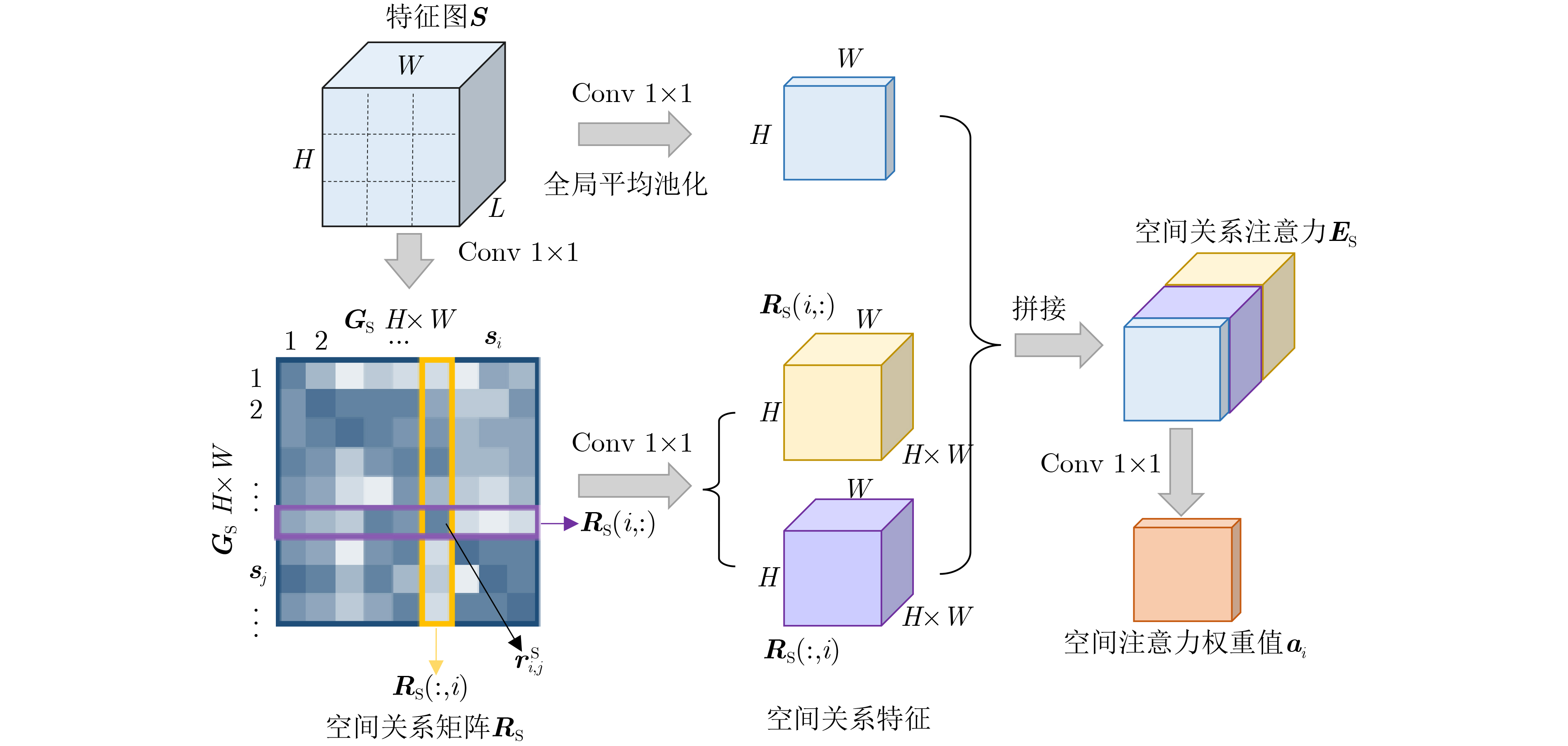
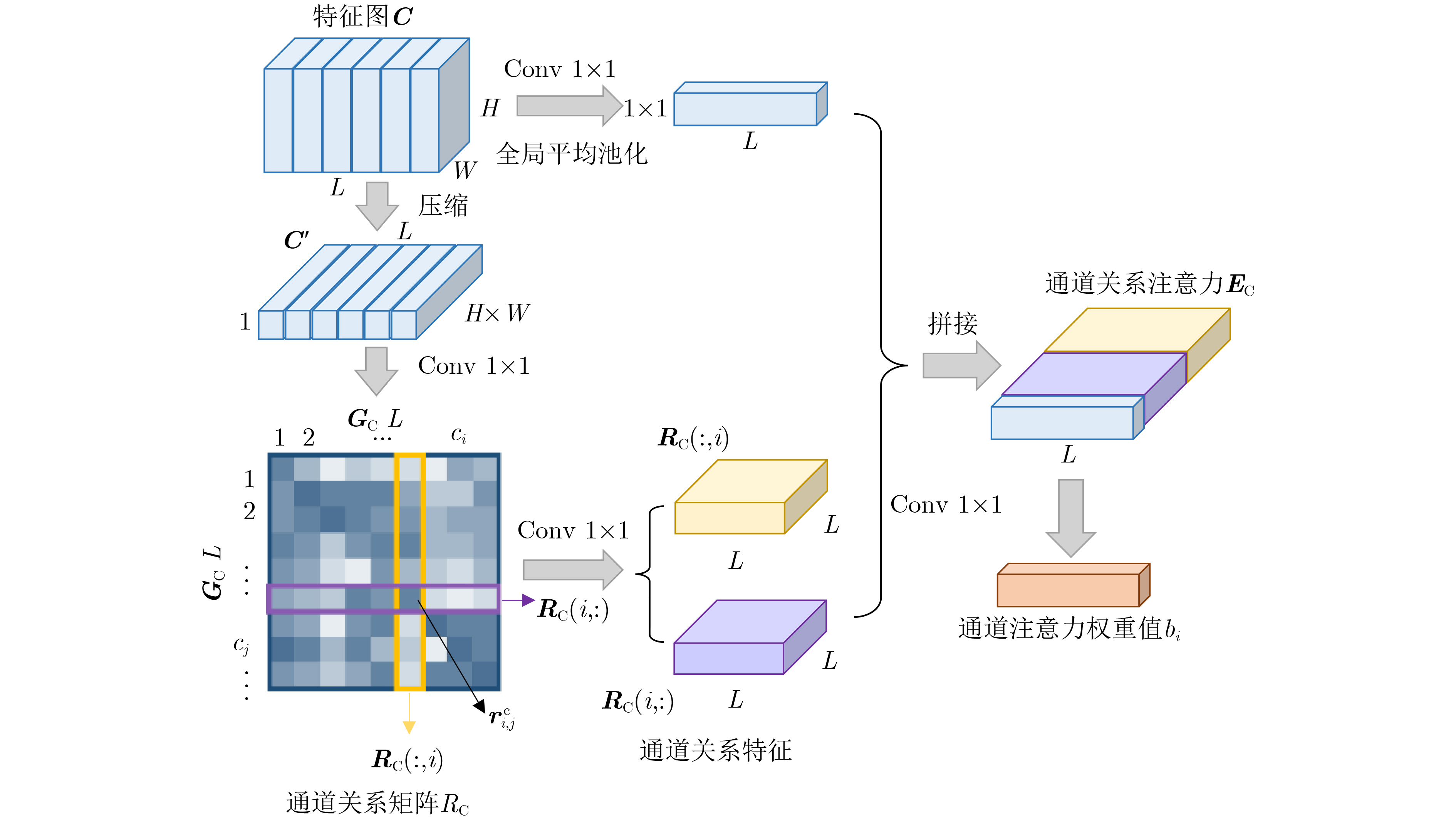
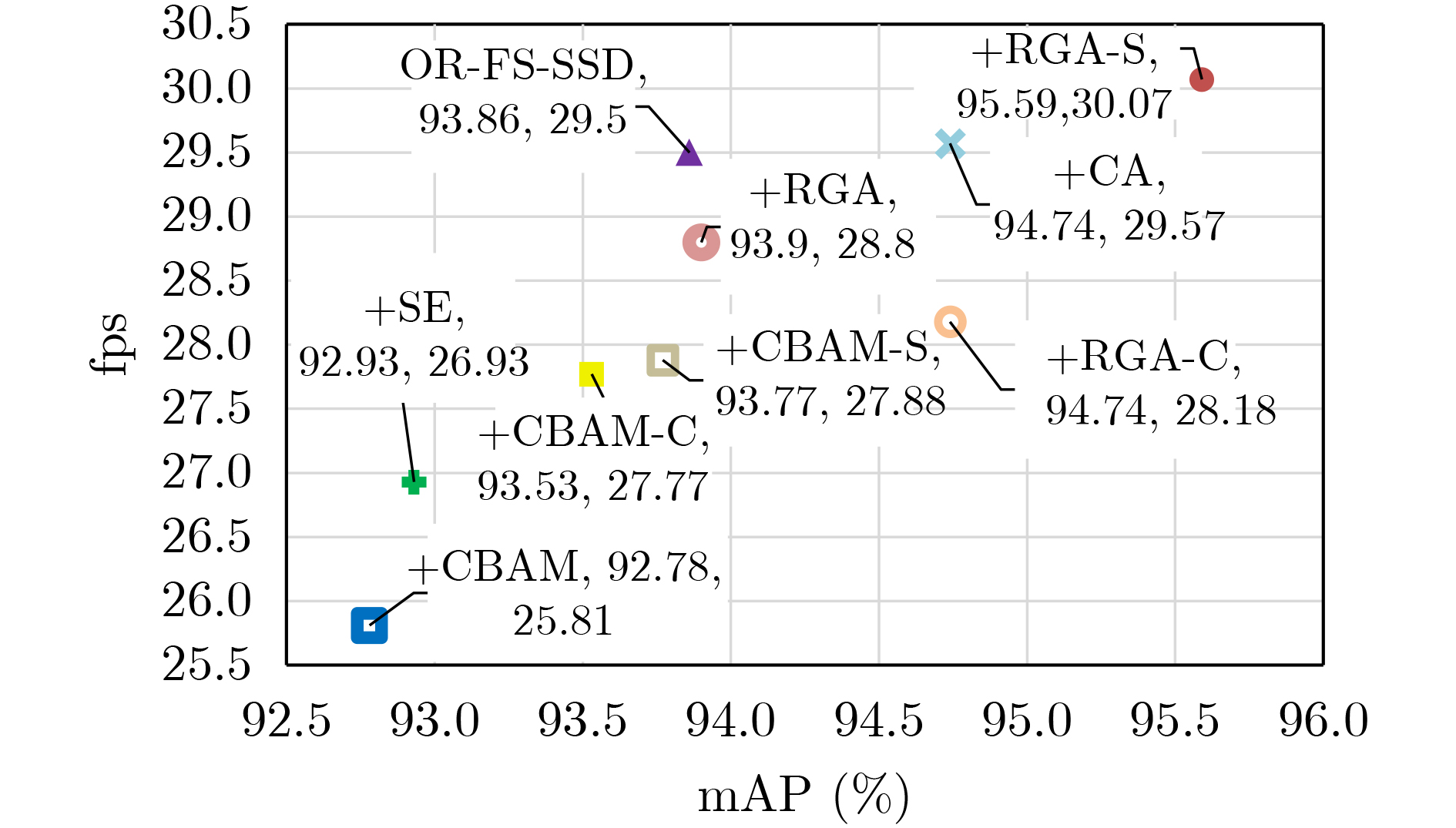
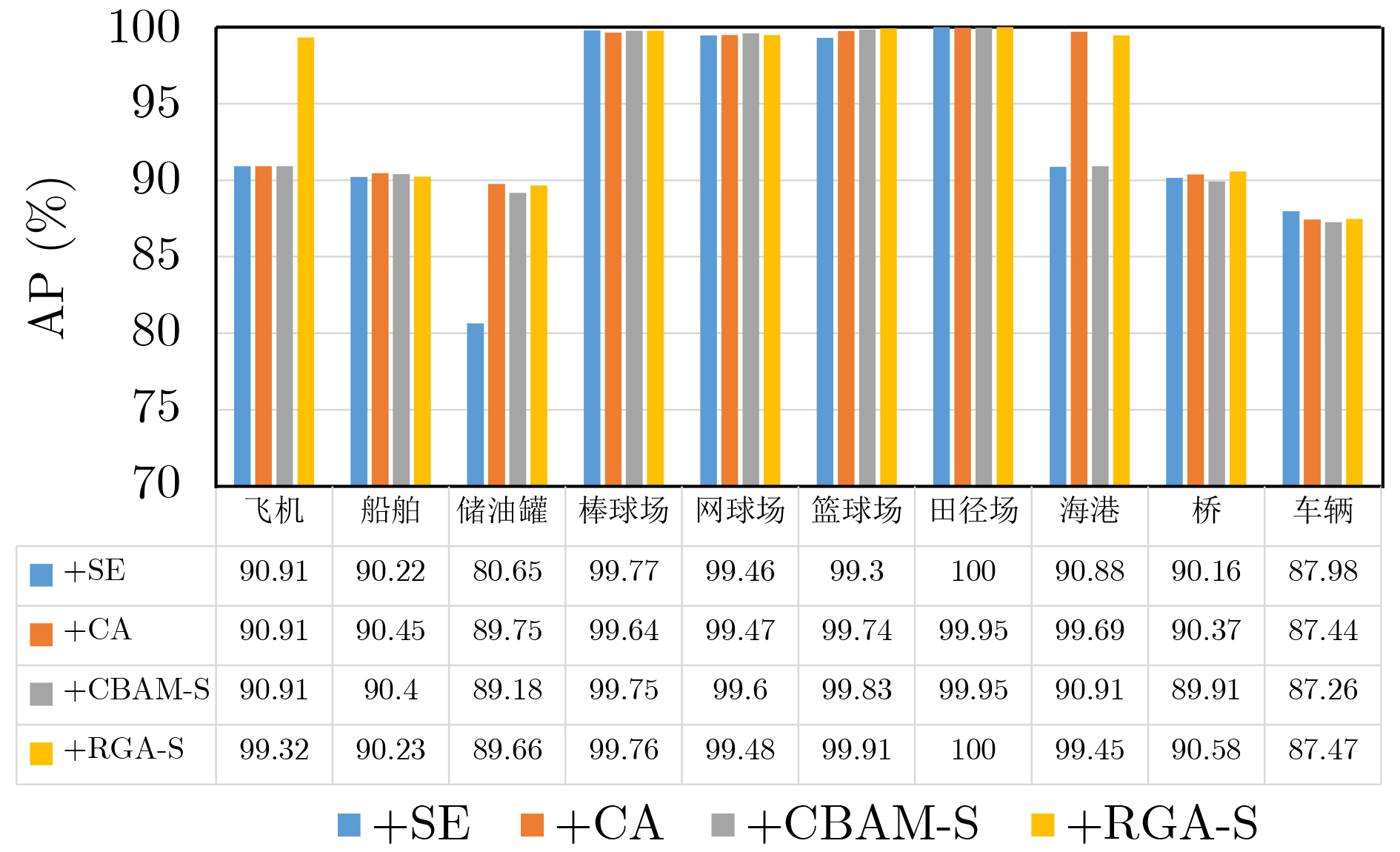
摘要: 高分辨率遥感影像中地物目标往往与所处场景类别息息相关,如能充分利用场景对地物目标的约束信息,有望进一步提升目标检测性能。考虑到场景信息和地物目标之间的关联关系,提出全局关系注意力(RGA)引导场景约束的高分辨率遥感影像目标检测方法。首先在多尺度特征融合检测器的基础网络之后,加入全局关系注意力学习全局场景特征;然后以学到的全局场景特征作为约束,结合方向响应卷积模块和多尺度特征模块进行目标预测;最后利用两个损失函数联合优化网络实现目标检测。在NWPU VHR-10数据集上进行了4组实验,在场景信息约束的条件下取得了更好的目标检测性能。Abstract: Ground objects in high-resolution remote sensing images are often closely related to the scene categories. If the constraint information of the scene on the ground object can be usefully employed, it is expected to improve further the performance of object detection. Considering the relationship between scene information and objects, a scene constrained object detection method in high-resolution remote sensing images by Relation-aware Global Attention (RGA) is proposed. First, the global scene features are learned by adding the global relational attention to the basic network in Feature fusion and Scaling-based Single Shot Detector (FS-SSD). Then, object is predicted by combining the oriented response convolution module with the multiscale feature module under the constraints of learned global scene features. Finally, two loss functions are used to optimize jointly the network to achieve object detection. Four experiments are conducted on NWPU VHR-10 dataset and better object detection performance is achieved under the constraints of scene information.
-
表 1 OR-FS-SSD+RGA最终预测特征图尺寸
Pred1 Pred2 Pred3 Pred4 Pred5 Pred6 Pred_avg 64×64 32×32 16×16 8×8 4×4 2×2 16×16  下载: 导出CSV
下载: 导出CSV
-
[1] CHENG Gong, ZHOU Peicheng, and HAN Junwei. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(12): 7405–7415. doi: 10.1109/TGRS.2016.2601622 [2] RADOVIC M, ADARKWA O, and WANG Qiaosong. Object recognition in aerial images using convolutional neural networks[J]. Journal of Imaging, 2017, 3(2): 21. doi: 10.3390/jimaging3020021 [3] LI Ke, WAN Gang, CHENG Gong, et al. Object detection in optical remote sensing images: A survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296–307. doi: 10.1016/j.isprsjprs.2019.11.023 [4] WANG Chen, BAI Xiao, WANG Shuai, et al. Multiscale visual attention networks for object detection in VHR remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(2): 310–314. doi: 10.1109/LGRS.2018.2872355 [5] LIANG Xi, ZHANG Jing, ZHUO Li, et al. Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(6): 1758–1770. doi: 10.1109/TCSVT.2019.2905881 [6] ZHAO Xiaolei, ZHANG Jing, TIAN Jimiao, et al. Multiscale object detection in high-resolution remote sensing images via rotation invariant deep features driven by channel attention[J]. International Journal of Remote Sensing, 2021, 42(15): 5764–5783. doi: 10.1080/01431161.2021.1931537 [7] DIVVALA S K, HOIEM D, HAYS J H, et al. An empirical study of context in object detection[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 1271–1278. [8] LIU Yong, WANG Ruiping, SHAN Shiguang, et al. Structure inference net: Object detection using scene-level context and instance-level relationships[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6985–6994. [9] ZHANG Zhizheng, LAN Cuiling, ZENG Wenjun, et al. Relation-aware global attention for person re-identification[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 3183–3192. [10] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. [11] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. [12] FU Jun, LIU Jing, TIAN Haijie, et al. Dual attention network for scene segmentation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3141–3149. [13] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. [14] LI Ke, CHENG Gong, BU Shuhui, et al. Rotation-insensitive and context-augmented object detection in remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2337–2348. doi: 10.1109/TGRS.2017.2778300 [15] ZENG Xingyu, OUYANG Wanli, YAN Junjie, et al. Crafting GBD-net for object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(9): 2109–2123. doi: 10.1109/TPAMI.2017.2745563 [16] ZHANG Jun, XIE Changming, XU Xia, et al. A contextual bidirectional enhancement method for remote sensing image object detection[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 4518–4531. doi: 10.1109/JSTARS.2020.3015049 [17] WU Xin, HONG Danfeng, TIAN Jiaojiao, et al. ORSIm detector: A novel object detection framework in optical remote sensing imagery using spatial-frequency channel features[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(7): 5146–5158. doi: 10.1109/TGRS.2019.2897139 -




图(7) / 表(3)
计量
- 文章访问数: 1112
- HTML全文浏览量: 498
- PDF下载量: 124
- 被引次数: 0
 下载:
下载:
