

Online Trajectory Optimization for the UAV-Enabled Base Station Multicasting System Based on Reinforcement Learning
-
摘要: 针对无人机(UAV)基站(BS)多播通信系统的通信时延最小化问题,该文提出飞行路线在线优化算法。在该系统中无人机基站向多个地面用户同时发送公共信息,其中每次通信任务中地面用户位置是随机的。为了保证地面用户能够接收完整的公共信息以及考虑到无人机的能量有限性,该文以最小化无人机基站完成通信任务的平均时间为目标。首先将问题转化成一个马尔可夫决策过程(MDP);然后把通信时延引入到动作价值函数中;最后提出使用Q-Learning算法对无人机飞行路线进行学习和在线优化,从而实现平均通信时延最小化。仿真结果显示,与其他基准方案相比,该文所提方案能够有效地为无人机多播通信系统飞行路线实现在线优化,并有效降低通信任务的完成时间。Abstract: In order to deal with the communication delay problem in an Unmanned Aerial Vehicle (UAV) enabled Base Station (BS) multicasting communication system, the online trajectory design for the UAV BS is investigated. A UAV BS is dispatched to disseminate common information to multiple ground users simultaneously in this system, where the locations of the ground users are random in each multicasting communication task. To ensure that the ground users can receive the complete multicasting information and considering the limited energy of the UAV, this paper focuses on minimizing the average duration for the UAV BS to complete the multicasting task. First, the considered problem is casted as a Markov Decision Process (MDP), and then the communication delay is introduced into the action value function. Finally, an online trajectory optimization algorithm based on the Q-Learning algorithm is proposed to minimize the average duration for the UAV BS to complete the multicasting task. Simulation results show that the proposed algorithm can effectively optimize the trajectory of the UAV BS for its multicasting task in an online manner and can effectively reduce the duration of the multicast task, as compared to other benchmark schemes.
-
[1] WU Qingqing, XU Jie, ZENG Yong, et al. A comprehensive overview on 5G-and-beyond networks with UAVs: From communications to sensing and intelligence[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(10): 2912–2945. doi: 10.1109/JSAC.2021.3088681 [2] LYU Jiangbin, ZENG Yong, and ZHANG Rui. UAV-aided offloading for cellular hotspot[J]. IEEE Transactions on Wireless Communications, 2018, 17(6): 3988–4001. doi: 10.1109/TWC.2018.2818734 [3] FENG Wanmei, TANG Jie, ZHAO Nan, et al. NOMA-based UAV-aided networks for emergency communications[J]. China Communications, 2020, 17(11): 54–66. doi: 10.23919/JCC.2020.11.005 [4] ZENG Yong, ZHANG Rui, and LIM T J. Throughput maximization for UAV-enabled mobile relaying systems[J]. IEEE Transactions on Communications, 2016, 64(12): 4983–4996. doi: 10.1109/TCOMM.2016.2611512 [5] MOZAFFARI M, SAAD W, BENNIS M, et al. Mobile Unmanned Aerial Vehicles (UAVs) for energy-efficient internet of things communications[J]. IEEE Transactions on Wireless Communications, 2017, 16(11): 7574–7589. doi: 10.1109/TWC.2017.2751045 [6] WANG Zhe, DUAN Lingjie, and ZHANG Rui. Adaptive deployment for UAV-aided communication networks[J]. IEEE Transactions on Wireless Communications, 2019, 18(9): 4531–4543. doi: 10.1109/TWC.2019.2926279 [7] ZENG Yong, XU Jie, and ZHANG Rui. Energy minimization for wireless communication with rotary-wing UAV[J]. IEEE Transactions on Wireless Communications, 2019, 18(4): 2329–2345. doi: 10.1109/TWC.2019.2902559 [8] WU Qingqing, ZENG Yong, and ZHANG Rui. Joint trajectory and communication design for multi-UAV enabled wireless networks[J]. IEEE Transactions on Wireless Communications, 2017, 17(3): 2109–2121. doi: 10.1109/TWC.2017.2789293 [9] LIU Tianyu, CUI Miao, ZHANG Guangchi, et al. 3D trajectory and transmit power optimization for UAV-enabled multi-link relaying systems[J]. IEEE Transactions on Green Communications and Networking, 2021, 5(1): 392–405. doi: 10.1109/TGCN.2020.3048135 [10] ZENG Yong and XU Xiaoli. Path design for cellular-connected UAV with reinforcement learning[C]. 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, USA, 2019: 1–6. [11] KHAMIDEHI B and SOUSA E S. Reinforcement learning-based trajectory design for the aerial base stations[C]. The 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkey, 2019: 1–6. [12] LIU Xiao, LIU Yuanwei, and CHEN Yue. Reinforcement learning in multiple-UAV networks: Deployment and movement design[J]. IEEE Transactions on Vehicular Technology, 2019, 68(8): 8036–8049. doi: 10.1109/TVT.2019.2922849 [13] SAXENA V, JALDÉN J, and KLESSIG H. Optimal UAV base station trajectories using flow-level models for reinforcement learning[J]. IEEE Transactions on Cognitive Communications and Networking, 2019, 5(4): 1101–1112. doi: 10.1109/TCCN.2019.2948324 [14] ZENG Yong, XU Xiaoli, and ZHANG Rui. Trajectory design for completion time minimization in UAV-enabled multicasting[J]. IEEE Transactions on Wireless Communications, 2018, 17(4): 2233–2246. doi: 10.1109/TWC.2018.2790401 [15] GOLDSMITH A. Wireless Communications[M]. Cambridge: Cambridge University Press, 2005: 26–27. [16] SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 2018: 1–130. [17] BELLMAN R. A markovian decision process[J]. Journal of Mathematics and Mechanics, 1957, 6(5): 679–684. doi: 10.1512/iumj.1957.6.56038 -


 下载:
下载:
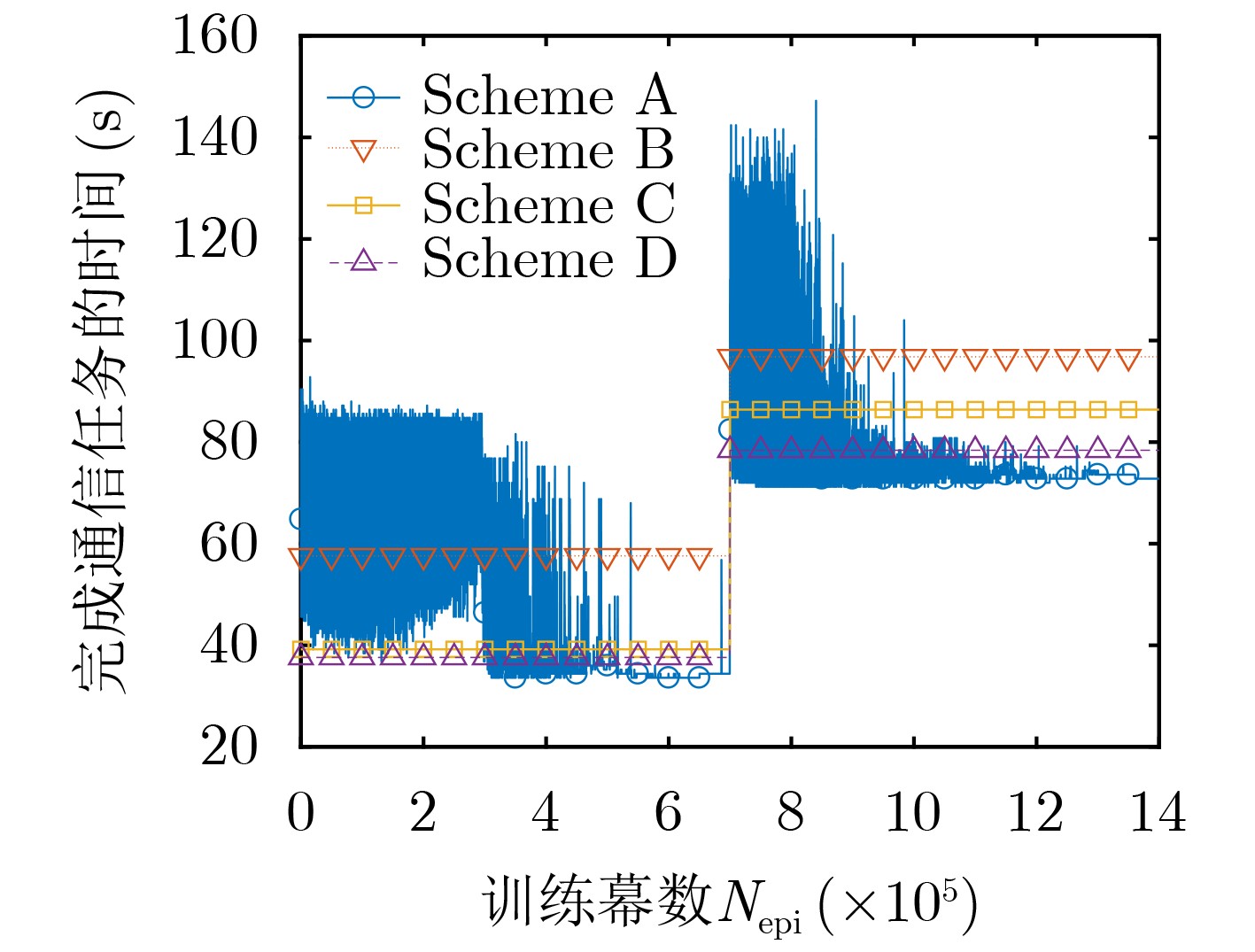
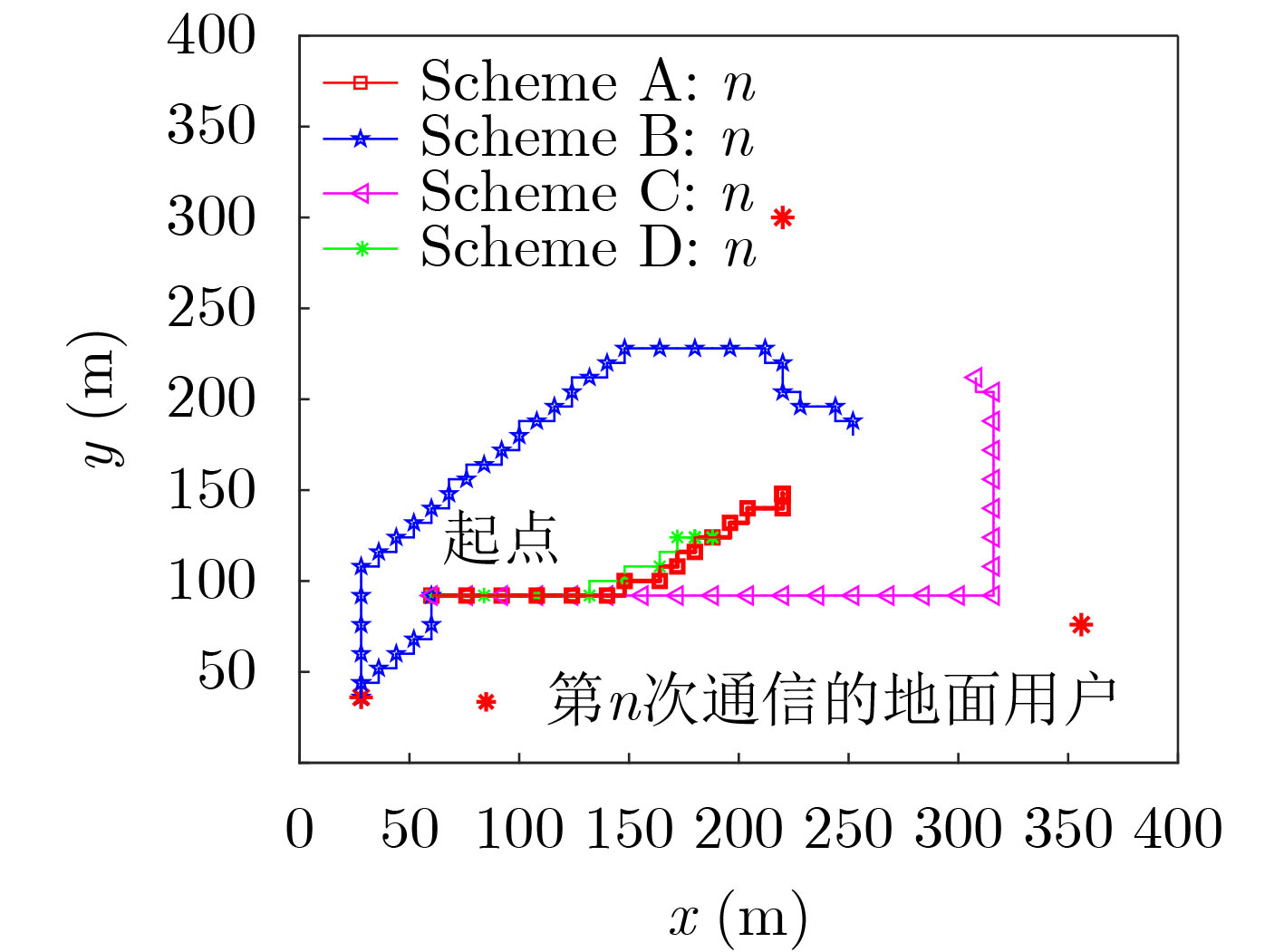
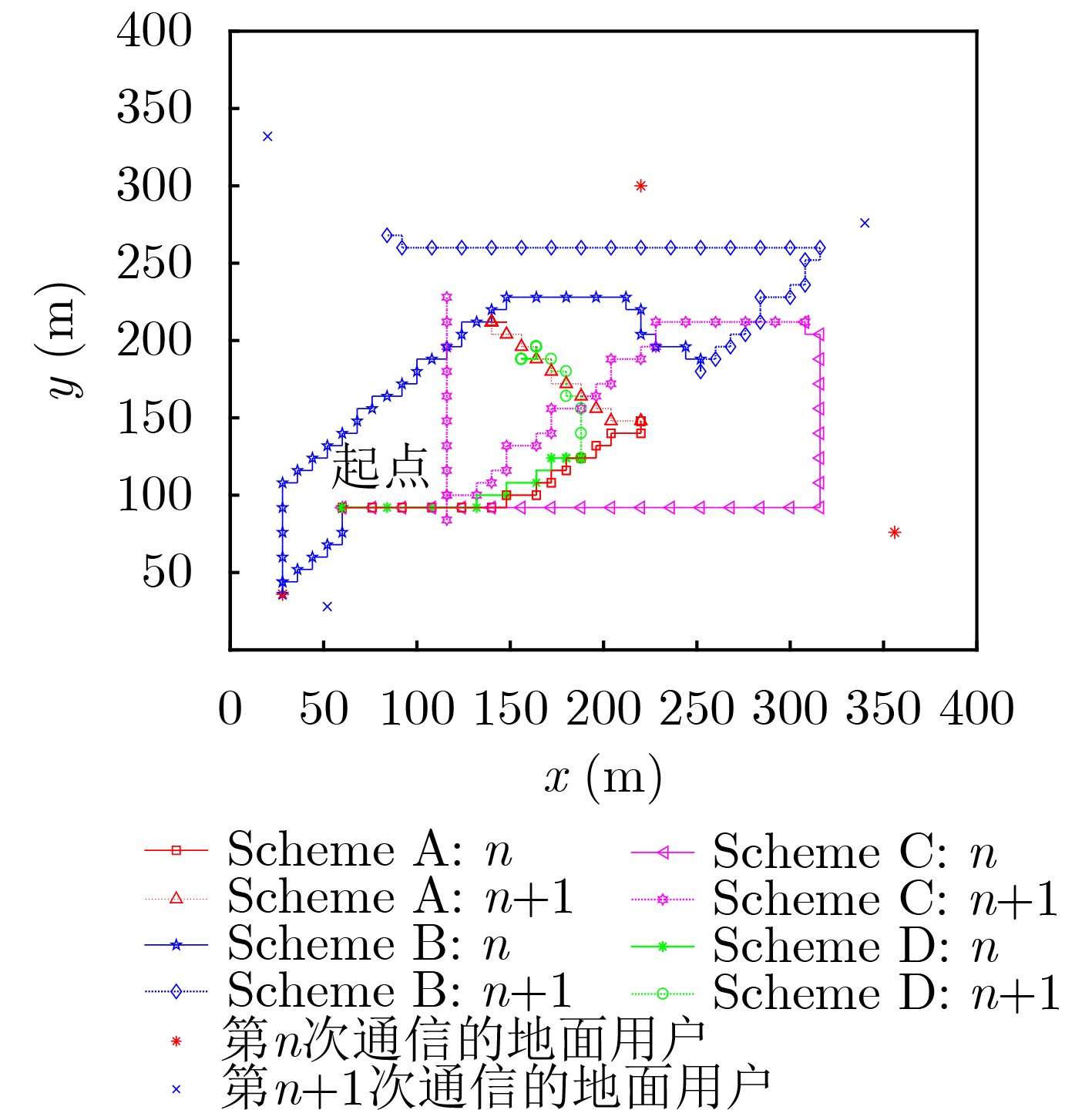
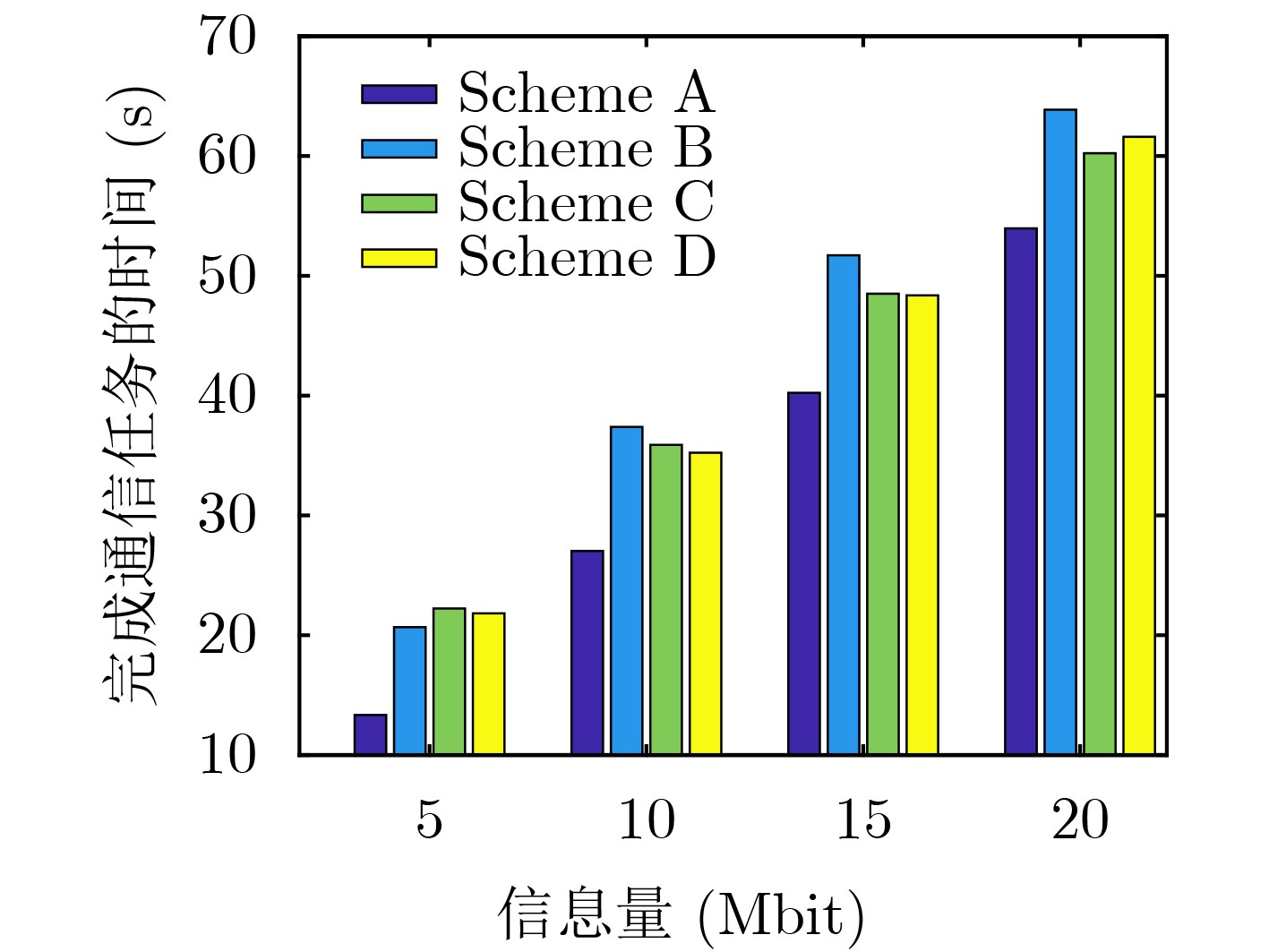
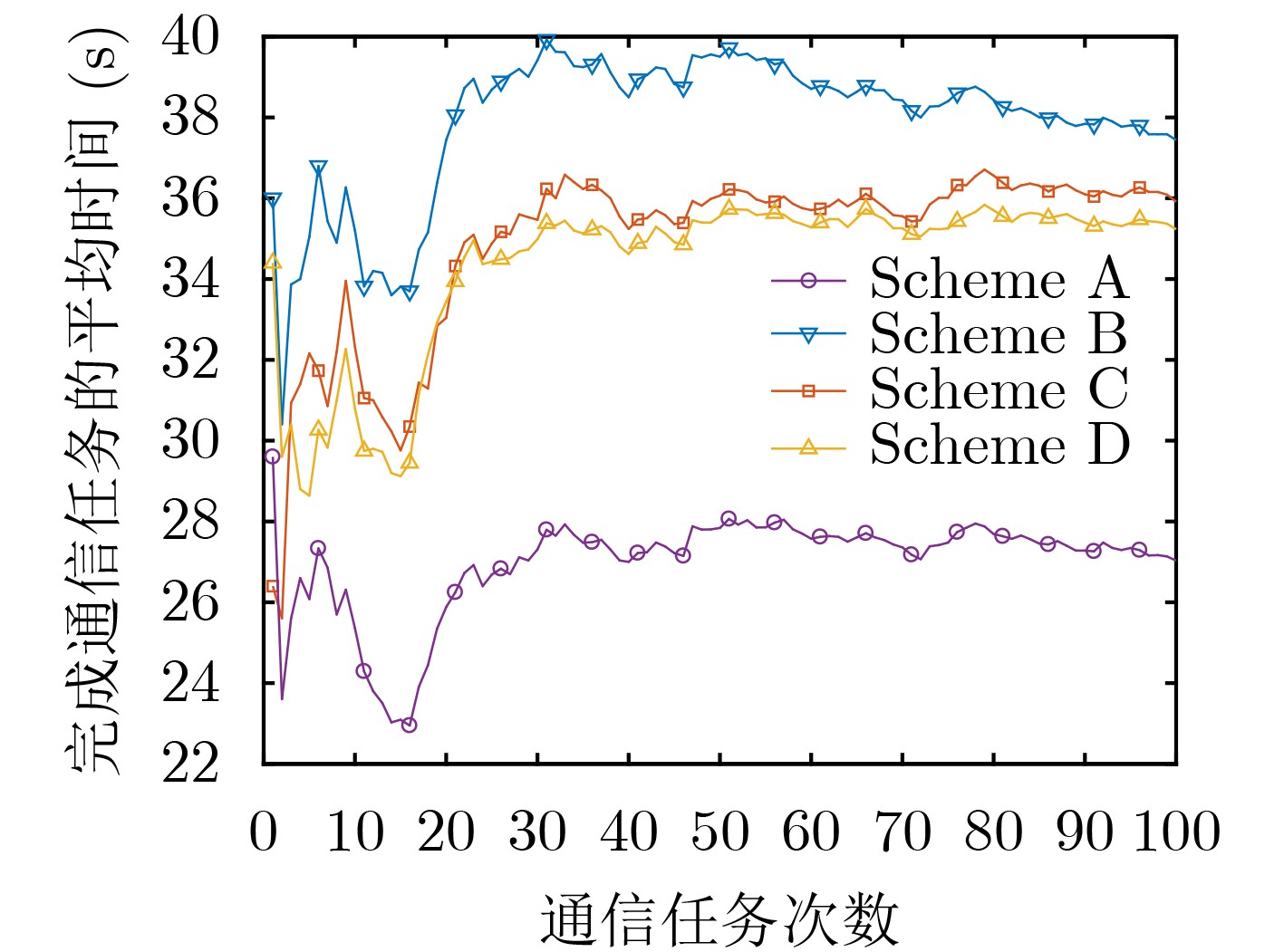


图(6)
计量
- 文章访问数: 1139
- HTML全文浏览量: 755
- PDF下载量: 154
- 被引次数: 0
