

Multi-feature Fusion Pedestrian Detection Combining Head and Overall Information
-
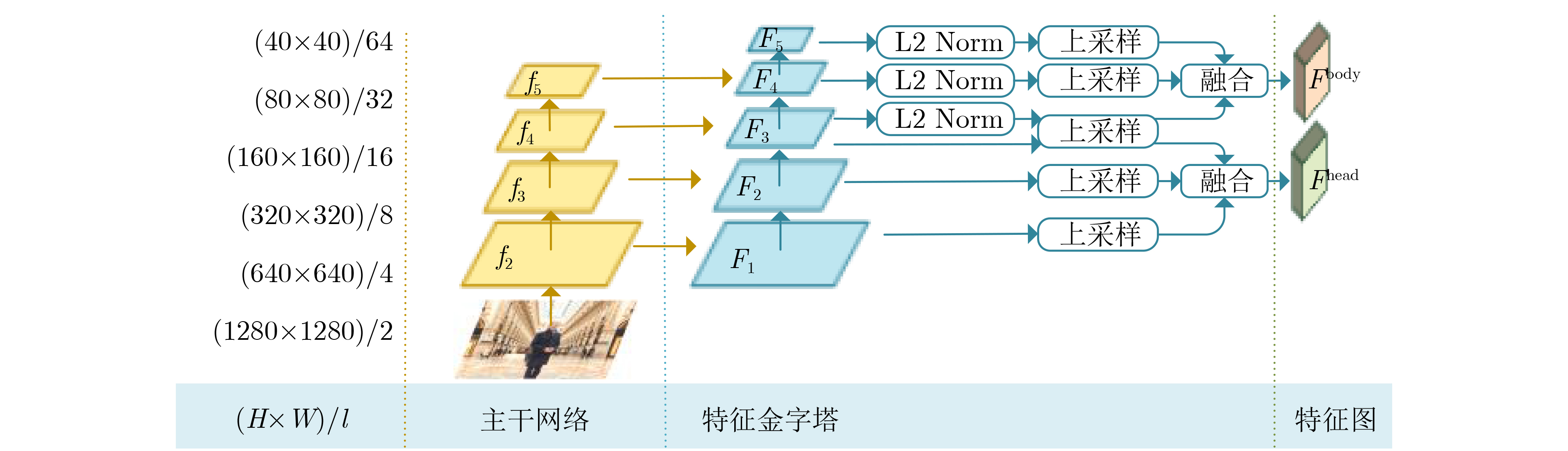
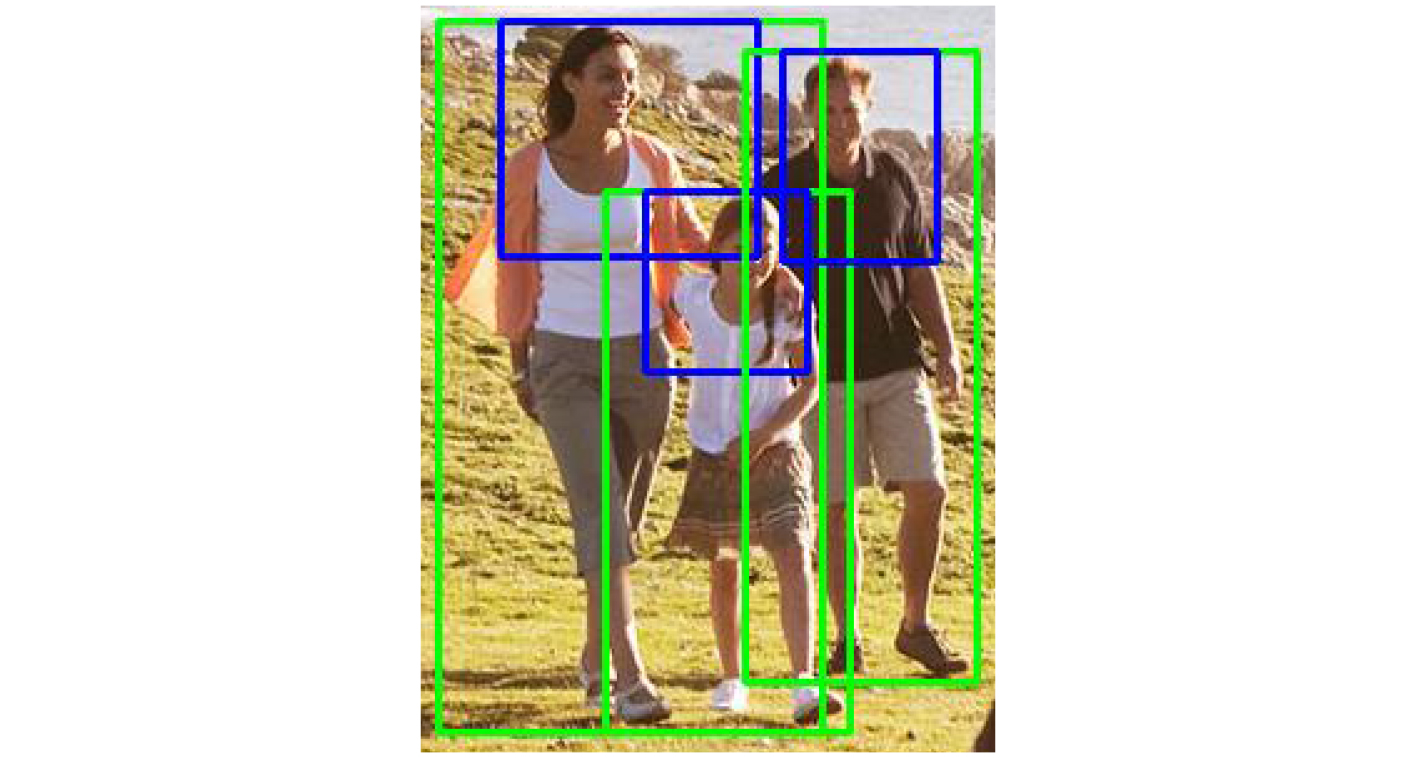
摘要: 尺度过小或被遮挡是造成行人检测准确率降低的主要原因。由于行人头部不易被遮挡且其边界框包含的背景干扰较少,对此,该文提出一种结合头部和整体信息的多特征融合行人检测方法。首先,设计了一种具有多层结构的特征金字塔以引入更丰富的特征信息,融合该特征金字塔不同子结构输出的特征图从而为头部检测和整体检测提供有针对性的特征信息。其次,设计了行人整体与头部两个检测分支同时进行检测。然后,模型采用无锚框的方式从特征图中预测中心点、高度及偏移量并分别生成行人头部边界框和整体边界框,从而构成端到端的检测。最后,对非极大值抑制算法进行改进使其能较好地利用行人头部边界框信息。所提算法在CrowdHuman数据集和CityPersons数据集Reasonable子集上的漏检率分别为50.16%和10.1%,在Caltech数据集Reasonable子集上的漏检率为7.73%,实验表明所提算法对遮挡行人的检测效果以及泛化性能与对比算法相比得到一定的提升。Abstract: The decrease in accuracy of pedestrian detection mainly caused by occlusion and too small scale. Since the pedestrian head is not easily occluded and it’s bounding box contains less background interference, a multi-feature fusion pedestrian detection method combines head and overall information is proposed. Firstly, a feature pyramid with multi-layer structure is designed to introduce richer information, feature maps output from different substructures of the feature pyramid are fused to provide targeted information for head and overall detection. Secondly, two branches are designed to perform the detection simultaneously. Then, the model generates pedestrian head and overall bounding boxes respectively from predicted centers, heights and offsets thus constituting end-to-end detection. Finally, non-maximum suppression algorithm is improved to make better use of the pedestrian head information. The experimental results show that the proposed algorithm has 50.16% miss rate on CrowdHuman dataset and 10.1% miss rate on the Reasonable subset of CityPersons dataset, and 7.73% miss rate on the Reasonable subset of Caltech dataset. Experimental results show the detection efficiency and generalization performance of the proposed algorithm are improved compared with the contrast algorithms.
-
Key words:
- Pedestrian detection /
- Feature pyramid /
- Feature fusion /
- Center detection
-
表 1 Caltech数据集中部分子集划分标准
子集 行人高度 遮挡程度 Reasonable >50 PXs 遮挡比例<0.35 Partial >50 PXs 0.1<遮挡比例≤0.35 Heavy >50 PXs 0.35<遮挡比例≤0.8  下载: 导出CSV
下载: 导出CSV
表 2 CityPersons数据集中部分子集划分标准
子集 行人高度 遮挡程度 Bare >50 PXs 0.1≤遮挡比例 Reasonable >50 PXs 遮挡比例<0.35 Partial >50 PXs 0.1<遮挡比例≤0.35 Heavy >50 PXs 0.35<遮挡比例≤0.8
下载: 导出CSV
表 4 CityPersons数据集漏检率(MR)的实验结果(%)
方法 Bare Reasonable Partial Heavy Small Medium Large FRCNN[6] – 15.4 – – 25.6 7.2 7.9 OR-CNN[12] 6.7 12.8 15.3 55.7 – – – FRCNN+Seg[22] – 14.8 – – 22.6 6.7 8.0 CSP[15] 7.3 11.0 10.4 49.3 16.0 3.7 6.5 ALFNet[25] 8.4 12.0 11.4 51.9 19.0 5.7 6.6 LBST[10] – 12.8 – – – – – CAFL[14] 7.6 11.4 12.1 50.4 – – – 本文方法(City训练) 7.5 10.6 10.2 49.5 15.0 4.4 7.0 本文方法(Crowd训练) 7.9 10.1 9.8 50.2 14.3 3.5 7.2
下载: 导出CSV
-
[1] 王进, 陈知良, 李航, 等. 一种基于增量式超网络的多标签分类方法[J]. 重庆邮电大学学报:自然科学版, 2019, 31(4): 538–549. doi: 10.3979/j.issn.1673-825X.2019.04.015WANG Jin, CHEN Zhiliang, LI Hang, et al. Hierarchical multi-label classification using incremental hypernetwork[J]. Journal of Chongqing University of Posts and Telecommunications:Natural Science Edition, 2019, 31(4): 538–549. doi: 10.3979/j.issn.1673-825X.2019.04.015 [2] 孟琭, 杨旭. 目标跟踪算法综述[J]. 自动化学报, 2019, 45(7): 1244–1260. doi: 10.16383/j.aas.c180277MENG Lu and YANG Xu. A survey of object tracking algorithms[J]. Acta Automatica Sinica, 2019, 45(7): 1244–1260. doi: 10.16383/j.aas.c180277 [3] LU Chengye, WU Sheng, JIANG Chunxiao, et al. Weak harmonic signal detection method in chaotic interference based on extended Kalman filter[J]. Digital Communications and Networks, 2019, 5(1): 51–55. doi: 10.1016/j.dcan.2018.10.004 [4] 高新波, 路文, 查林, 等. 超高清视频画质提升技术及其芯片化方案[J]. 重庆邮电大学学报:自然科学版, 2020, 32(5): 681–697. doi: 10.3979/j.issn.1673-825X.2020.05.001GAO Xinbo, LU Wen, ZHA Lin, et al. Quality elevation technique for UHD video and its VLSI solution[J]. Journal of Chongqing University of Posts and Telecommunications:Natural Science Edition, 2020, 32(5): 681–697. doi: 10.3979/j.issn.1673-825X.2020.05.001 [5] 张功国, 吴建, 易亿, 等. 基于集成卷积神经网络的交通标志识别[J]. 重庆邮电大学学报:自然科学版, 2019, 31(4): 571–577. doi: 10.3979/j.issn.1673-825X.2019.04.019ZHANG Gongguo, WU Jian, YI Yi, et al. Traffic sign recognition based on ensemble convolutional neural network[J]. Journal of Chongqing University of Posts and Telecommunications:Natural Science Edition, 2019, 31(4): 571–577. doi: 10.3979/j.issn.1673-825X.2019.04.019 [6] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [7] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318–327. doi: 10.1109/TPAMI.2018.2858826 [8] 李春伟, 于洪涛, 李邵梅, 等. 一种基于可变形部件模型的快速对象检测算法[J]. 电子与信息学报, 2016, 38(11): 2864–2870. doi: 10.11999/JEIT160080LI Chunwei, YU Hongtao, LI Shaomei, et al. Rapid object detection algorithm based on deformable part models[J]. Journal of Electronics &Information Technology, 2016, 38(11): 2864–2870. doi: 10.11999/JEIT160080 [9] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 936–944. doi: 10.1109/CVPR.2017.106. [10] CAO Jiale, PANG Yanwei, HAN Jungong, et al. Taking a look at small-scale pedestrians and occluded pedestrians[J]. IEEE Transactions on Image Processing, 2019, 29: 3143–3152. doi: 10.1109/TIP.2019.2957927 [11] 赵斌, 王春平, 付强. 显著性背景感知的多尺度红外行人检测方法[J]. 电子与信息学报, 2020, 42(10): 2524–2532. doi: 10.11999/JEIT190761ZHAO Bin, WANG Chunping, and FU Qiang. Multi-scale pedestrian detection in infrared images with salient background-awareness[J]. Journal of Electronics &Information Technology, 2020, 42(10): 2524–2532. doi: 10.11999/JEIT190761 [12] ZHANG Shifeng, WEN Longyin, XIAO Bian, et al. Occlusion-aware R-CNN: Detecting pedestrians in a crowd[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 637–653. doi: 10.1007/978-3-030-01219-9_39. [13] DU Xianzhi, EL-KHAMY M, LEE J, et al. Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection[C]. 2017 IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, USA, 2017: 953–961. doi: 10.1109/WACV.2017.111. [14] FEI Chi, LIU Bin, CHEN Zhu, et al. Learning pixel-level and instance-level context-aware features for pedestrian detection in crowds[J]. IEEE Access, 2019, 7: 94944–94953. doi: 10.1109/ACCESS.2019.2928879 [15] LIU Wei, LIAO Shengcai, REN Weiqiang, et al. High-level semantic feature detection: A new perspective for pedestrian detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5182–5191. doi: 10.1109/CVPR.2019.00533. [16] LIU Songtao, HUANG Di, and WANG Yunhong. Adaptive NMS: Refining pedestrian detection in a crowd[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 6452–6461. doi: 10.1109/CVPR.2019.00662. [17] XU Ruiyue, CUAN Yepeng, and HUANG Yizhen. Multiple human detection and tracking based on head detection for real-time video surveillance[J]. Multimedia Tools and Applications, 2015, 74(3): 729–742. doi: 10.1007/s11042-014-2177-x [18] LU Ruiqi, MA Huimin, and WANG Yu. Semantic head enhanced pedestrian detection in a crowd[J]. Neurocomputing, 2020, 400: 343–351. doi: 10.1016/j.neucom.2020.03.037 [19] SHAO Shuai, ZHAO Zijian, LI Boxun, et al. CrowdHuman: A benchmark for detecting human in a crowd[EB/OL]. https://arxiv.org/abs/1805.00123, 2020. [20] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [21] LIN Chunze, LU Jiwen, WANG Gang, et al. Graininess-aware deep feature learning for robust pedestrian detection[J]. IEEE Transactions on Image Processing, 2020, 29: 3820–3834. doi: 10.1109/TIP.2020.2966371 [22] ZHANG Shanshan, BENENSON R, and SCHIELE B. CityPersons: A diverse dataset for pedestrian detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4457–4465. doi: 10.1109/CVPR.2017.474. [23] DOLLAR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: An evaluation of the state of the art[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743–761. doi: 10.1109/TPAMI.2011.155 [24] ZHANG Yongming, ZHANG Shifeng, ZHUANG Chubin, et al. Feature enhancement for joint human and head detection[C]. The 14th Chinese Conference on Biometric Recognition, Zhuzhou, China, 2019: 511–518. doi: 10.1007/978-3-030-31456-9_56. [25] LIU Wei, LIAO Shengcai, HU Weidong, et al. Learning efficient single-stage pedestrian detectors by asymptotic localization fitting[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 618–634. doi: 10.1007/978-3-030-01264-9_38. [26] ZHANG Shanshan, YANG Jian, and SCHIELE B. Occluded pedestrian detection through guided attention in CNNs[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6995–7003. doi: 10.1109/CVPR.2018.00731. [27] CAI Zhaowei, FAN Quanfu, FERIS R S, et al. A unified multi-scale deep convolutional neural network for fast object detection[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 354–370. doi: 10.1007/978-3-319-46493-0_22. -


 下载:
下载:





图(6) / 表(5)
计量
- 文章访问数: 1400
- HTML全文浏览量: 1193
- PDF下载量: 152
- 被引次数: 0
