

Sound Event Detection width Audio Tagging Consistency Constraint CRNN
-
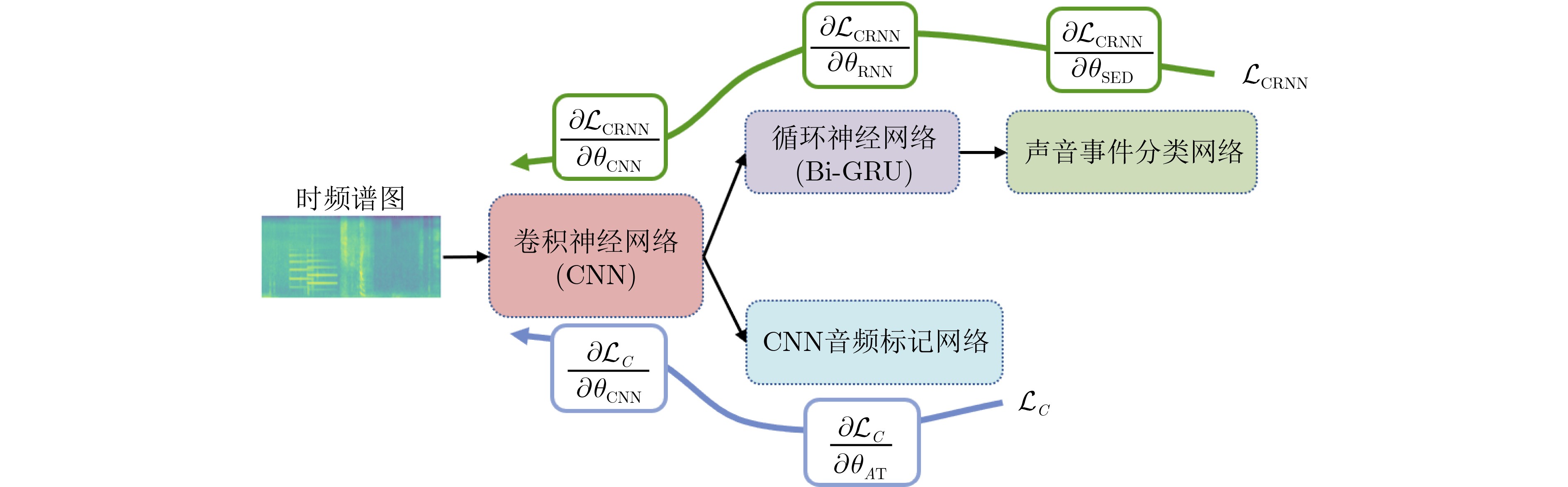
摘要: 级联卷积神经网络(CNN)结构和循环神经网络(RNN)结构的卷积循环神经网络(CRNN)及其改进是当前主流的声音事件检测模型。然而,以端到端方式训练的CRNN声音事件检测模型无法从功能上约束CNN和RNN结构的作用。针对这一问题,该文提出了音频标记一致性约束CRNN声音事件检测方法(ATCC-CRNN)。该方法在CRNN模型的声音事件分类网络中添加了CRNN音频标记分支,同时增加了CNN音频标记网络对CRNN网络CNN结构输出的特征图进行音频标记。然后,通过在模型训练阶段限定CNN和CRNN的音频标记预测结果一致使CRNN模型的CNN结构更关注音频标记任务,RNN结构更关注建立音频样本的帧间关系。从而使CRNN模型的CNN和RNN结构具备了不同的特征描述功能。该文在IEEE DCASE 2019国际竞赛家庭环境声音事件检测任务(任务4)的数据集上进行了实验。实验结果显示:提出的ATCC-CRNN方法显著提高了CRNN模型的声音事件检测性能,在验证集和评估集上的F1得分提高了3.7%以上。这表明提出的ATCC-CRNN方法促进了CRNN模型的功能划分,有效改善了CRNN声音事件检测模型的泛化能力。Abstract: Convolutional Recurrent Neural Network (CRNN), which cascades Convolutional Neural Network (CNN) structure and Recurrent Neural Network (RNN) structure, and its reformations are the mainstreams for sound event detection. However, CRNN models trained in end-to-end way can not make CNN and RNN structures have meaningful functions, which may affect the performances of sound event detection. To alleviate this problem, this paper proposes an Audio Tagging Consistency Constraint CRNN (ATCC-CRNN) method for sound event detection. In ATCC-CRNN, a CRNN audio tagging branch is embedded in the sound event classification network, meanwhile a CNN audio tagging network is designed to predict the audio tag of CNN structure. Thereafter, in the training stage of CRNN, the audio tagging prediction results of CNN and CRNN are limited to be consistent to make the CNN structure concentrating on audio tagging task and the RNN structure concentrating on modelling the inter-frame relationship of audio sample. As a result, the CNN structure and RNN structure of CRNN have different feature description functions for sound event detection. Experiments are carried out on the dataset of IEEE DCASE 2019 domestic environments sound event detection task (task 4). Experimental results demonstrate that the proposed ATCC-CRNN method improves significantly the performance of CRNN model in sound event detection. The event-based F1 scores on validation dataset and evaluation dataset are improved by more than 3.7%. These results indicate that the proposed ATCC-CRNN makes the CNN and RNN structures of CRNN functional clearly and improves the generalization ability of CRNN sound event detection model.
-
表 1 不同CRNN模型的声音事件检测F1得分及DR, IR
模型 验证集 评估集 F1(%) DR IR F1(%) DR IR Baseline 23.3 0.78 0.62 28.6 0.75 0.46 ATCC-Baseline 28.6 0.76 0.35 34.6 0.72 0.27 CRNN 38.9 0.64 0.51 42.1 0.62 0.40 ATCC-CRNN 43.0 0.60 0.46 45.8 0.60 0.35  下载: 导出CSV
下载: 导出CSV
表 2 CRNN网络在验证集和评估集中对每种声音事件检测的F1得分和错误率结果
声音事件 CRNN ATCC-CRNN 验证集 评估集 验证集 评估集 F1(%) ER F1(%) ER F1(%) ER F1(%) ER alarm 46.2 0.91 40.4 0.93 44.4 1.02 54.2 0.76 blender 40.7 1.09 33.3 1.38 48.0 1.22 45.1 1.27 cat 34.5 1.30 53.7 0.88 32.2 1.27 46.5 0.97 dishes 23.9 1.33 31.9 1.05 33.2 1.28 31.6 1.03 dog 26.7 1.24 39.3 1.04 29.0 1.15 37.0 1.01 electric 50.0 1.02 35.2 1.06 54.8 0.86 57.5 0.71 frying 23.8 1.69 42.1 1.10 29.2 1.33 37.3 1.12 running water 35.8 1.15 31.2 1.21 41.7 1.03 37.0 1.09 speech 53.8 0.82 57.3 0.75 56.6 0.79 59.7 0.73 vacuum cleaner 53.9 0.89 56.0 0.83 61.0 0.65 52.5 0.79 overall 38.9 1.14 42.0 1.02 43.0 1.06 45.8 0.95
下载: 导出CSV
表 3 ATCC-CRNN与几种代表性CRNN网络在DCASE竞赛任务4上的声音事件检测F1得分比较(%)
下载: 导出CSV
表 4 CRNN网络的各模型结构的参数量与计算复杂度(Flops)
模型结构 参数量(个) Flops ${\theta _{{\rm{CNN}}} }$ 1242304 5.12G ${\theta _{{\rm{CNN}}} }$ 494592 0.06G ${\theta _{{\rm{SED}}} }$ 5140 0.66M ${\theta _{{\rm{AT}}} }$ 17802 17.80K 总计 1759838 5.18G
下载: 导出CSV
-
[1] HUMAYUN A I, GHAFFARZADEGAN S, FENG Z, et al. Learning front-end filter-bank parameters using convolutional neural networks for abnormal heart sound detection[C]. Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Honolulu, USA, 2018: 1408–1411. [2] BANDI A K, RIZKALLA M, and SALAMA P. A novel approach for the detection of gunshot events using sound source localization techniques[C]. Proceedings of the IEEE 55th International Midwest Symposium on Circuits and Systems (MWSCAS), Boise, USA, 2012: 494–497. [3] DARGIE W. Adaptive audio-based context recognition[J]. IEEE Transactions on Systems, Man, and Cybernetics - Part A:Systems and Humans, 2009, 39(4): 715–725. doi: 10.1109/TSMCA.2009.2015676 [4] ZHANG Haomin, MCLOUGHLIN I, and SONG Yan. Robust sound event recognition using convolutional neural networks[C]. Proceedings of 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia, 2015: 559–563. [5] HIRATA K, KATO T, and OSHIMA R. Classification of environmental sounds using convolutional neural network with bispectral analysis[C]. Proceedings of 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, China, 2019: 1–2. [6] ÇAKIR E, PARASCANDOLO G, HEITTOLA T, et al. Convolutional recurrent neural networks for polyphonic sound event detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(6): 1291–1303. doi: 10.1109/TASLP.2017.2690575 [7] HAYASHI T, WATANABE S, TODA T, et al. Duration-controlled LSTM for polyphonic sound event detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(11): 2059–2070. doi: 10.1109/TASLP.2017.2740002 [8] KONG Qiuqiang, XU Yong, SOBIERAJ I, et al. Sound event detection and time–frequency segmentation from weakly labelled data[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(4): 777–787. doi: 10.1109/TASLP.2019.2895254 [9] LU Jiakai. Mean teacher convolution system for DCASE 2018 task 4[R]. Technical Report of DCASE 2018 Challenge, 2018. [10] CHATTERJEE C C, MULIMANI M, and KOOLAGUDI S G. Polyphonic sound event detection using transposed convolutional recurrent neural network[C]. Proceedings of 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 661–665. [11] LI Yanxiong, LIU Mingle, DROSSOS K, et al. Sound event detection via dilated convolutional recurrent neural networks[C]. Proceedings of 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 286–290. [12] XU Yong, KONG Qiuqiang, WANG Wenwu, et al. Large-scale weakly supervised audio classification using gated convolutional neural network[C]. Proceedings of 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 2018: 121–125. [13] YAN Jie, SONG Yan, GUO Wu, et al. A region based attention method for weakly supervised sound event detection and classification[C]. Proceedings of 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019: 755–759. [14] HU Jie, SHEN Li, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011–2023. doi: 10.1109/TPAMI.2019.2913372 [15] BA J L, KIROS J R, and HINTON G E. Layer normalization[OL]. arXiv: 1607.06450, 2016. [16] IOFFE S and SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[OL]. Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 2015: 448–456. [17] TARVAINEN A and VALPOLA H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 1195–1204. [18] TURPAULT N, SERIZEL R, SALAMON J, et al. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis[C]. 2019 Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE 2019), New York, USA, 2019: 253–257. [19] GEMMEKE J F, ELLIS D P W, FREEDMAN D, et al. Audio set: An ontology and human-labeled dataset for audio events[C]. Proceedings of 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, USA, 2017: 776–780. [20] DELPHIN-POULAT L and PLAPOUS C. Mean teacher with data augmentation for DCASE 2019 task 4[R]. Technical Report of DCASE 2019 Challenge, 2019. [21] SHI Ziqiang, LIU Liu, LIN Huibin, et al. HODGEPODGE: Sound event detection based on ensemble of semi-supervised learning methods[C]. Proceedings of 2019 Workshop on Detection and Classification of Acoustic Scenes and Events, New York, USA, 2019: 224–228. [22] TURPAULT N and SERIZEL R. Training sound event detection on a heterogeneous dataset[C]. 2020 Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE2020), Tokyo, Japan, 2020: 200–204. [23] HOU Z W and HAO J Y. Efficient CRNN network based on context gating and channel attention mechanism[R]. Technical Report of DCASE 2020 Challenge, 2020. -


 下载:
下载:



图(3) / 表(4)
计量
- 文章访问数: 2989
- HTML全文浏览量: 1814
- PDF下载量: 188
- 被引次数: 0
