

Reconfigurable Hardware Design of Multi-lanes Number Theoretic Transform for Lattice-based Cryptography
-
摘要: 针对不同格密码体制带来的数论变换参数多样性,以及数论变换的性能优化设计,该文提出一种基于随机存取存储器(RAM)的可重构多通道数论变换单元。在数论变换单元设计中,在按时间抽取的基础上改进多通道架构,并提出一种优化地址分配方法。最后基于Xilinx Artix-7现场可编程逻辑门阵列(FPGA)平台进行原型实现,结果显示,所设计的数论变换单元消耗的资源为1744 Slices, 16 DSP,完成1次多项式乘法的时间为2.01 μs(n=256), 3.57 μs(n=512), 6.71 μs(n=1024)和13.43 μs(n=2048),支持256~2048的不同参数n和13~32 bit模q的可重构配置,工作频率最高可达232 MHz。Abstract: The performance of number theoretic transformation in lattice-based cryptography is insufficient, and the number theoretic transformation parameters are different. A Random Access Memory (RAM)-based reconfigurable multi-lanes number theoretic transform is proposed. In the design of number theory transformation unit, the multi-lanes architecture is improved on the time decimation operation architecture, and an optimized address allocation method is proposed. The number theory transform unit is implemented on Xilinx artix-7 Field Programmable Gate Array (FPGA) platform. The results show that the resource consumed by the unit is 1744 slices and 16 DSP, and the time to complete a polynomial multiplication is 2.01 μs (n=256), 3.57 μs (n=512), 6.71 μs (n=1024) and 13.43 μs (n=2048). The unit supports reconfigurable configurations of 256~2048 parameters n and 13~32-bit modulus q, and the maximum operating frequency is 232 MHz.
-
表 1 基2 DIT-NTT算法
输入:$ {\boldsymbol{A}}\left(x\right),{\omega }_{N} \in {R}_{q},N $ 输出:$ {\boldsymbol{A}}\left(x\right) $ (1) for m = 1 to N/2 by m = 2m do (2) for i = 0 to N–1 do (3) for j = 0 to N–1 do (4) $ u={\boldsymbol{A}}[k+j] $ (5) $ t={\boldsymbol{A}}[k+j+m]\times {\omega }_{N} $ (6) $ {\boldsymbol{A}}[k+j]\mathrm{ }=\mathrm{ }(u+t)\mathrm{ }\mathrm{m}\mathrm{o}\mathrm{d}\;q $ (7) $ {\boldsymbol{A}}[k+j+N]\mathrm{ }=\mathrm{ }(u-t)\mathrm{ }\mathrm{m}\mathrm{o}\mathrm{d}\;q $ (8) end for (9) end for (10) end for (11) return $ A\left(x\right) $  下载: 导出CSV
下载: 导出CSV
表 2 可重构参数表
n 256 512 1024 2048 – – – – 模q 7681 12289 40961 65537 786433 5767169 7640033 23068673 104857601 16772161 469762049 998244353 1004535809 1998585857 2013265921 –
下载: 导出CSV
表 3 多项式乘法结果比较表
文献 n q位数 LUTs Slices Memory(36 kB) DSPs MHz 周期数 时延(μs) ATP1) (×105) NTT[5] 1024 30 2317 997 11.5 BRAMs 4 194 21405 110.34 1.100 NTT[5] 2048 57 3846 1310 22.5 BRAMs 16 161 45453 282.32 3.698 NTT[6] 2048 17 2323 – 287820 Bits 22 228.99 10289 44.93 1.9652) NTT[11] 512 23 – 18 K 2.5 BRAMs 128 233.1 412 1.77 0.4483) FFT[12] 2048 22 – 4406 50 BRAMs 12 208.12 17402 83.615 3.684 本设计 256 32 4780 1744 24 BRAMs/655360 Bits 16 232 1627 7.00 0.122 512 2798 12.03 0.210 1024 5251 22.58 0.394 2048 10455 44.96 0.784 1)ATP是通过将消耗的Slices乘以时延来计算的。
2)NTT[3]由于未提供消耗的Slices数量,因此ATP的计算采用LUTs×Time,而本设计对应的ATP为2.149。
3)为了合理地比较,多通道NTT[7]的ATP计算公式为(1.5n×9+2n) / (n×9+2n) ×1.77×18k=0.448×105。
下载: 导出CSV
-
[1] SHOR P W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer[J]. SIAM Journal on Computing, 1997, 26(5): 1484–1509. doi: 10.1137/S0097539795293172 [2] ARUTE F, ARYA K, BABBUSH R, et al. Quantum supremacy using a programmable superconducting processor[J]. Nature, 2019, 574(7779): 505–510. doi: 10.1038/s41586-019-1666-5 [3] 赵勇, 戚巍, 徐兵杰, 等. 量子安全技术白皮书(2020)[R]. 2020. [4] CHEN Zhaohui, MA Yuan, CHEN Tianyu, et al. Towards efficient kyber on FPGAs: A processor for vector of polynomials[C]. The 2020 25th Asia and South Pacific Design Automation Conference, Beijing, China, 2020. doi: 10.1109/ASP-DAC47756.2020.9045459. [5] PÖPPELMANN T and GÜNEYSU T. Towards efficient arithmetic for lattice-based cryptography on reconfigurable hardware[C]. The 2nd International Conference on Cryptology and Information Security in Latin America, Santiago, Chile, 2012. doi: 10.1007/978-3-642-33481-8_8" target="_blank">href="http://dx.doi.org/10.1007/978-3-642-33481-8_8">10.1007/978-3-642-33481-8_8. [6] RENTERÍA-MEJÍA C P and VELASCO-MEDINA J. Hardware design of an NTT-Based polynomial multiplier[C]. The 2014 IX Southern Conference on Programmable Logic, Buenos Aires, Argentina, 2014: 1–5. doi: 10.1109/SPL.2014.7002209. [7] YE J H and SHIEH M D. High-performance NTT Architecture for large integer multiplication[C]. 2018 International Symposium on VLSI Design, Automation and Test, Hsinchu, China, 2018: 1–4. doi: 10.1109/VLSI-DAT.2018.8373254. [8] ZHANG Neng, QIN Qiao, YUAN Hang, et al. NTTU: An area-efficient low-power NTT-uncoupled architecture for NTT-based multiplication[J]. IEEE Transactions on Computers, 2020, 69(4): 520–533. doi: 10.1109/TC.2019.2958334 [9] AYSU A, PATTERSON C, and SCHAUMONT P. Low-cost and area-efficient FPGA implementations of lattice-based cryptography[C]. Proceedings of 2013 IEEE International Symposium on Hardware-Oriented Security and Trust, Austin, USA, 2013. [10] RENTERÍA-MEJÍA C R and VELASCO-MEDINA J. Lattice-based cryptoprocessor for CCA-Secure identity-based encryption[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2020, 67(7): 2331–2344. doi: 10.1109/TCSI.2020.2981089 [11] FENG Xiang, LI Shuguo, and XU Sufen. RLWE-oriented high-speed polynomial multiplier utilizing multi-lane stockham NTT algorithm[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2020, 67(3): 556–559. doi: 10.1109/TCSII.2019.2917621 [12] CHEN D D, MENTENS N, VERCAUTEREN F, et al. High-speed polynomial multiplication architecture for ring-LWE and SHE cryptosystems[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2015, 62(1): 157–166. doi: 10.1109/TCSI.2014.2350431 [13] MERT A C, KARABULUT E, OZTURK E, et al. An extensive study of flexible design methods for the number theoretic transform[J/OL]. IEEE Transactions on Computers, 2020, 1–15. [14] LIU Dongsheng, ZHANG Cong, LIN Hui, et al. A resource-efficient and side-channel secure hardware implementation of ring-LWE cryptographic processor[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2019, 66(4): 1474–1483. doi: 10.1109/TCSI.2018.2883966 [15] KIM S, LEE K, CHO W, et al. Hardware architecture of a number theoretic transform for a bootstrappable RNS-based homomorphic encryption scheme[C]. The 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines, Fayetteville, USA, 2020, 56–64. doi: 10.1109/FCCM48280.2020.00017. -

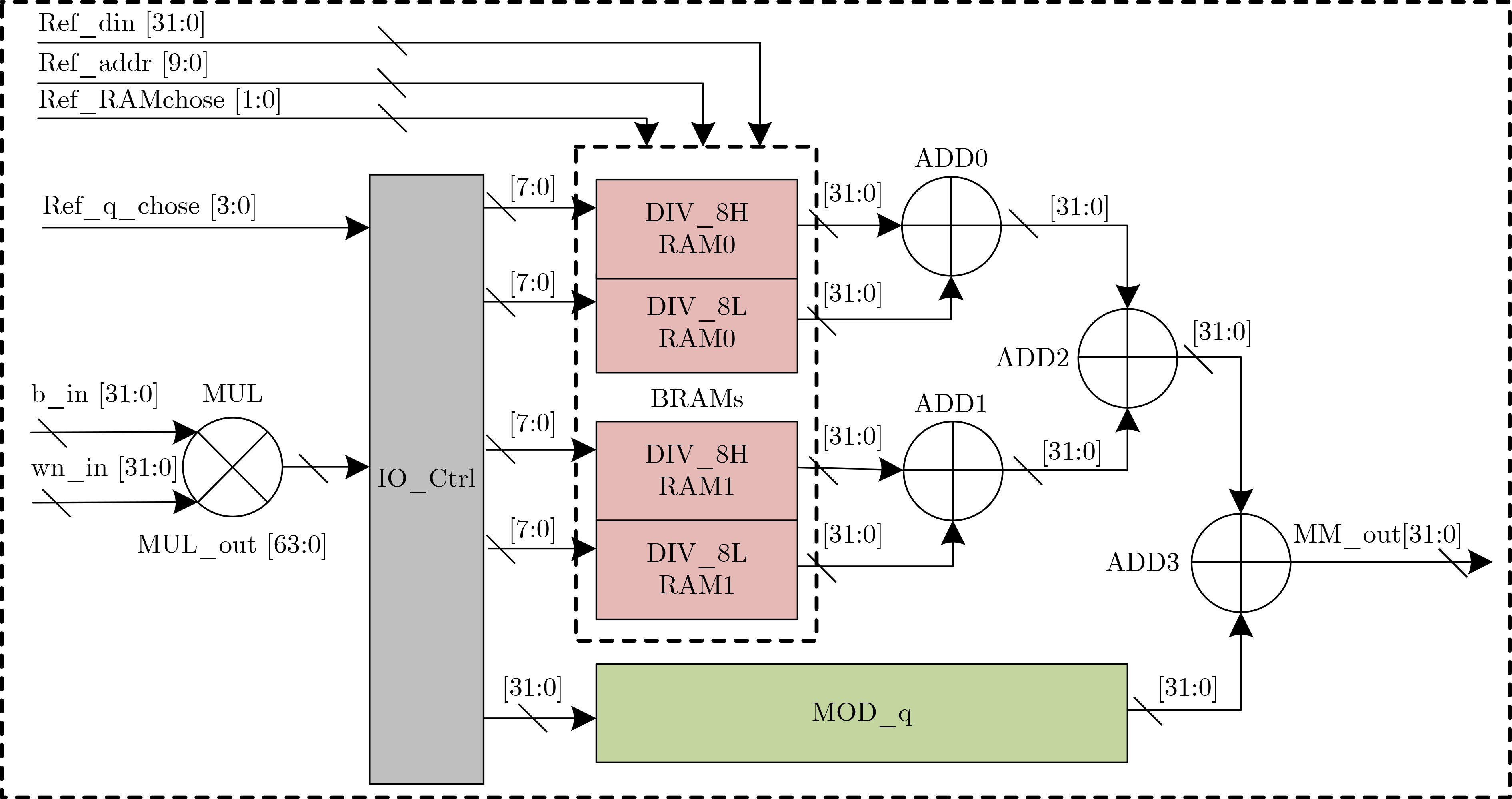
 下载:
下载:
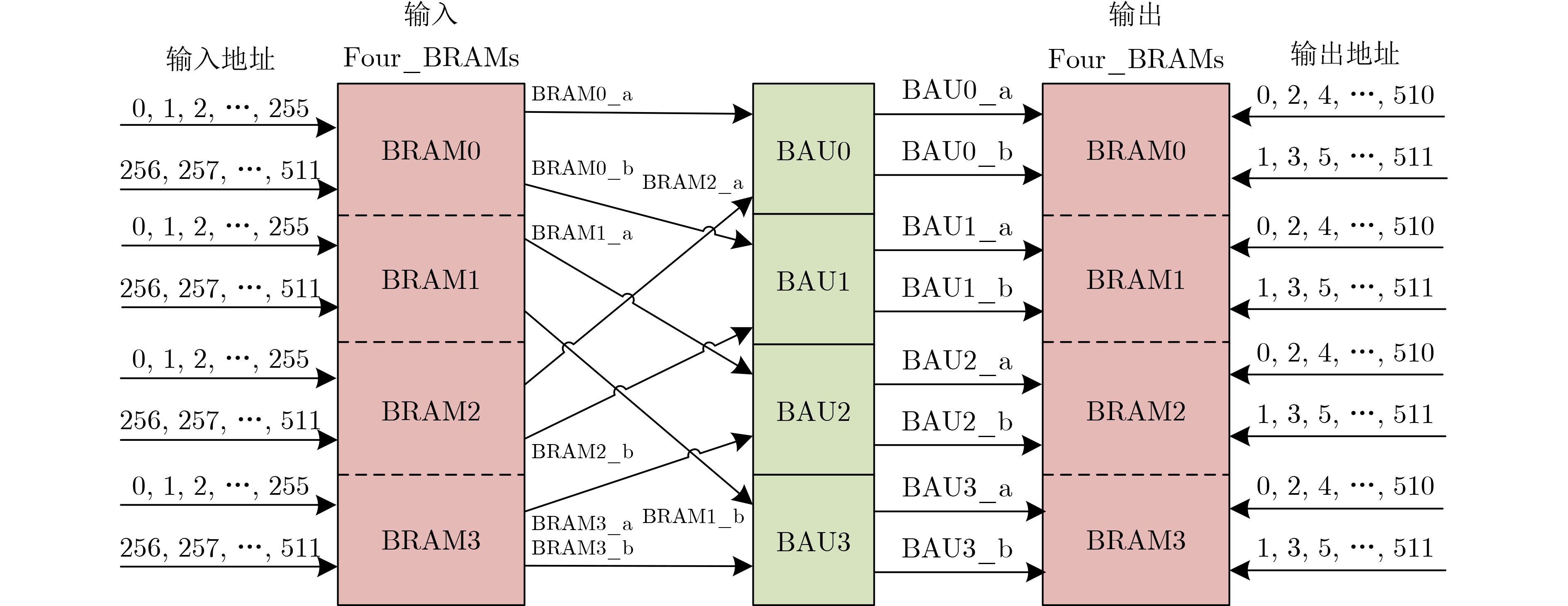
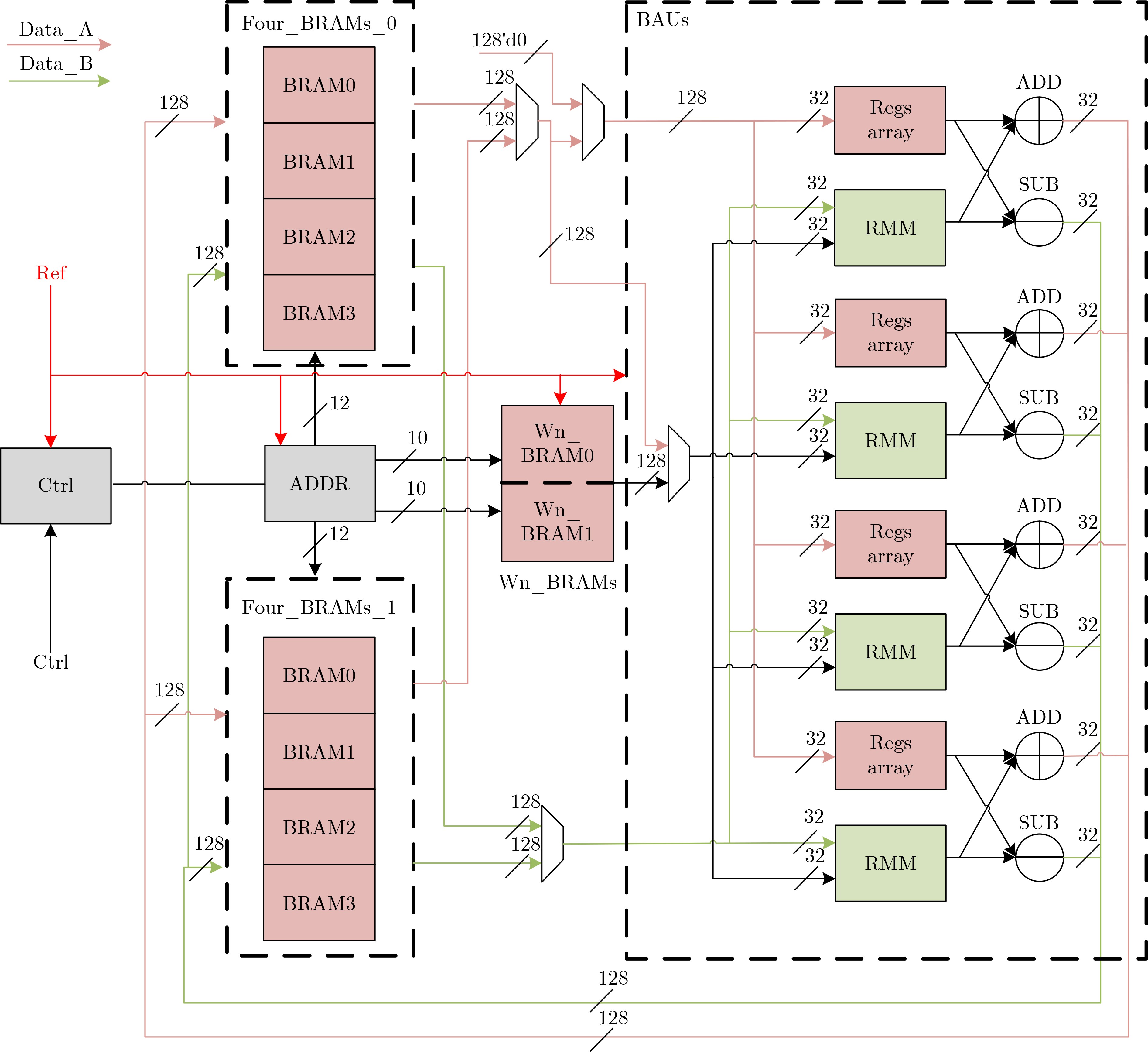


图(3) / 表(3)
计量
- 文章访问数: 2030
- HTML全文浏览量: 1214
- PDF下载量: 195
- 被引次数: 0
