

Applications of Generic In-memory Computing Architecture Platform Based on SRAM to Internet of Things
-
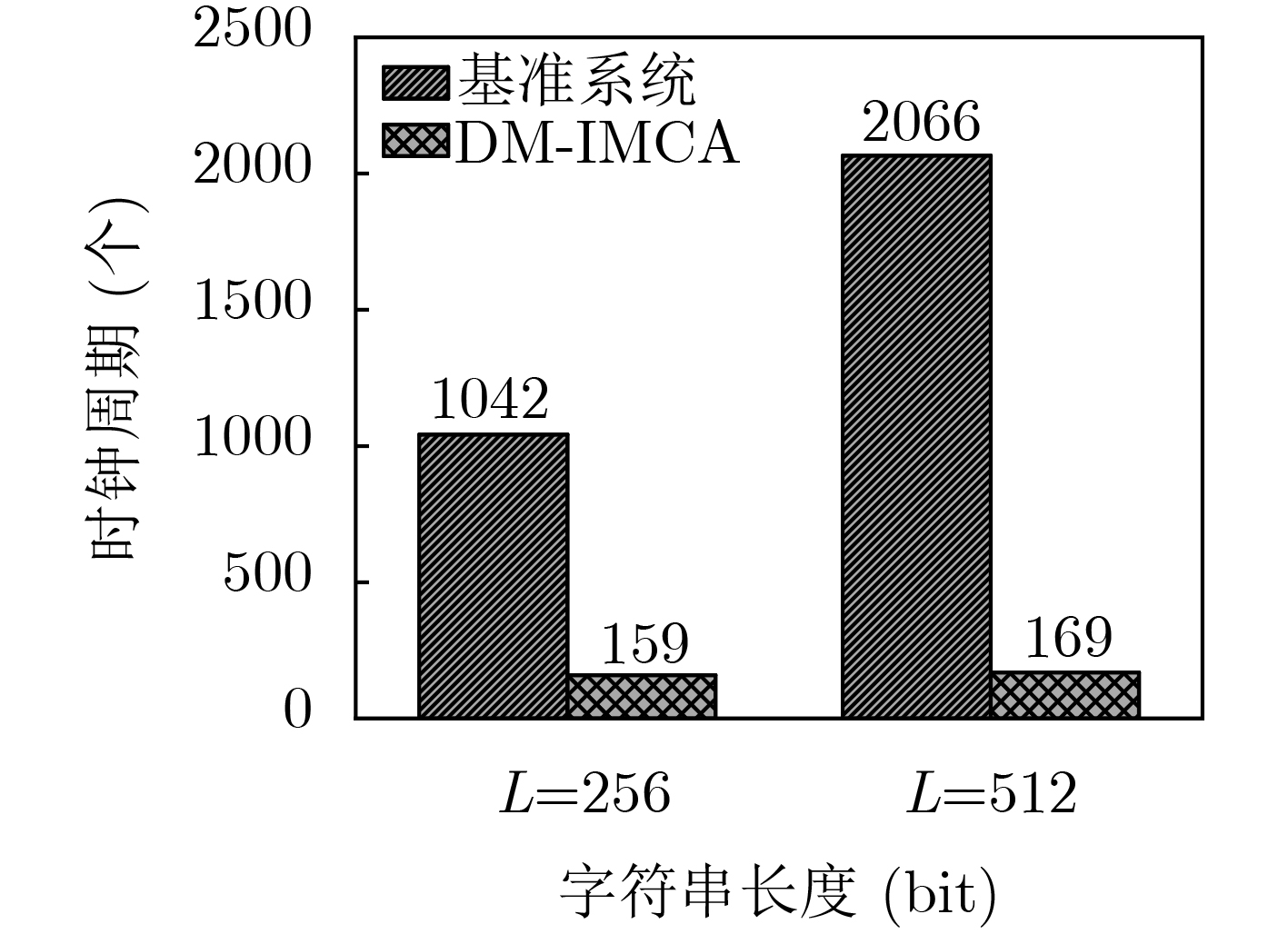
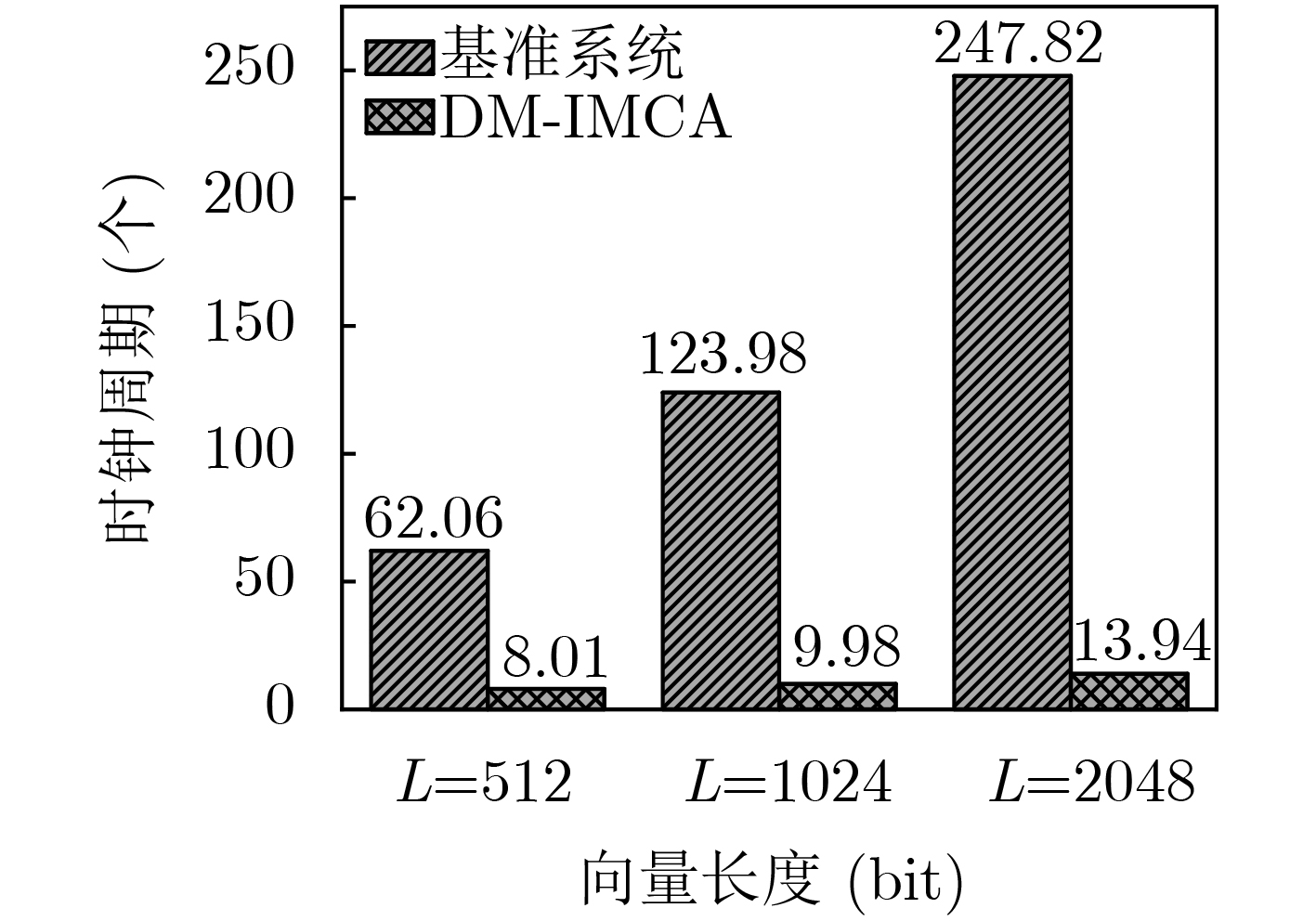
摘要: 最近,存算一体(IMC)架构引起了广泛关注,并被认为有望成为突破冯诺依曼瓶颈的新型计算机架构,特别是在数据密集型(data-intensive)计算中能够带来显著的性能和功耗优势。其中,基于SRAM的IMC架构方案也被大量研究与应用。该文在一款基于SRAM的通用存算一体架构平台——DM-IMCA的基础上,探索IMC架构在物联网领域中的应用价值。具体来说,该文选取了物联网中包括信息安全、二值神经网络和图像处理在内的多个轻量级数据密集型应用,对算法进行分析或拆分,并将关键算法映射到DM-IMCA中的SRAM中,以达到加速应用计算的目的。实验结果显示,与基于传统冯诺依曼架构的基准系统相比,利用DM-IMCA来实现物联网中的轻量级计算密集型应用,可获得高达24倍的计算加速比。Abstract: In-Memory Computing (IMC) architectures have aroused much attention recently, and are regarded as promising candidates to break the von Neumann bottleneck. IMC architectures can bring significant performance and energy-efficiency improvement especially in data-intensive computation. Among those emerging IMC architectures, SRAM-based ones have also been extensively researched and applied to many scenarios. In this paper, IoT applications are explored based on a SRAM-based generic IMC architecture platform named DM-IMCA. To be specific, the algorithms of several lightweight data-intensive applications in IoT area including information security, Binary Neural Networks (BNN) and image processing are analyzed, decomposed and then mapped to SRAM macros of DM-IMCA, so as to accelerate the computation of these applications. Experimental results indicate that DM-IMCA can offer up to 24 times performance speed-up, compared to a baseline system with conventional von Neumann architecture, in terms of realizing lightweight data-intensive applications in IoT.
-
表 1 IMC指令集编码格式
指令 字段 名称 储配置指令:
memCfg Rn31–27 op (11001) 26–4 Reserved 3–0 rn 地址配置指令:
addrCfg R3, R2, R131–27 op (11000) 26–20 r3 19–13 r2 12–6 r1 5–0 Reserved 计算指令:
opcode vl (vl: vector length,矢量长度)31–27 op (11010) 26–23 function 22–15 vl 14–0 Reserved  下载: 导出CSV
下载: 导出CSV
表 2 IMC指令集
指令类型 指令 操作/功能 配置指令 存储配置 memCfg 配置寄存器Rn 地址配置 addrCfg 配置存内计算地址寄存器R1~R3 计算指令 逻辑计算 mand $c = a\& b$ mor $c = a|b$ mxor $c = a \oplus b$ mnor $c = \sim(a|b)$ mnand $c = \sim(a + b)$ mnot $c = \sim a$ 算术计算 madd $c = a + b$(有符号) maddu $c = a + b$(无符号) mop $c = - a$ minc $c = a + 1$ mdec $c = a - 1$ msl $c = a \ll 1$ msr $c = a \gg 1$ 存储操作 mcopy $c = a$
下载: 导出CSV
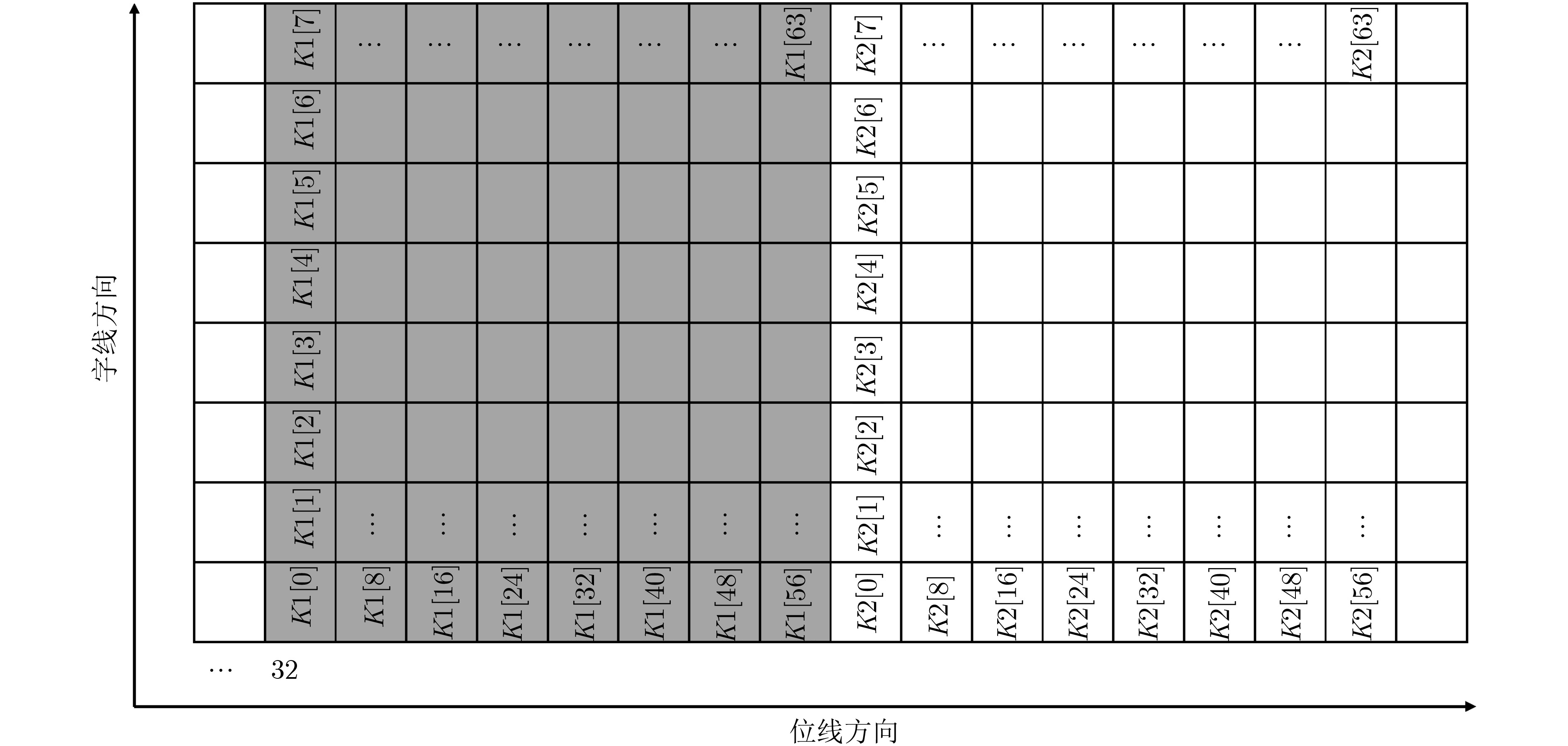
表 3 OTP算法
输入: plaintext P[N], key K[N], N为数组P和K的字长 输出: ciphertext C[N] (1) for (unsigned i = 0; i < N; i++) do (2) C[i] = P[i]⊕K[i]; (3) end for
下载: 导出CSV
表 4 加法哈希算法
输入: char *key, uint32_t len, uint32_t prime 输出: result (1) uint32_t hash, i (2) for (hash = len, i = 0; i < len; i++) do (3) hash +=key[i] (4) end for (5) return (hash % prime)
下载: 导出CSV
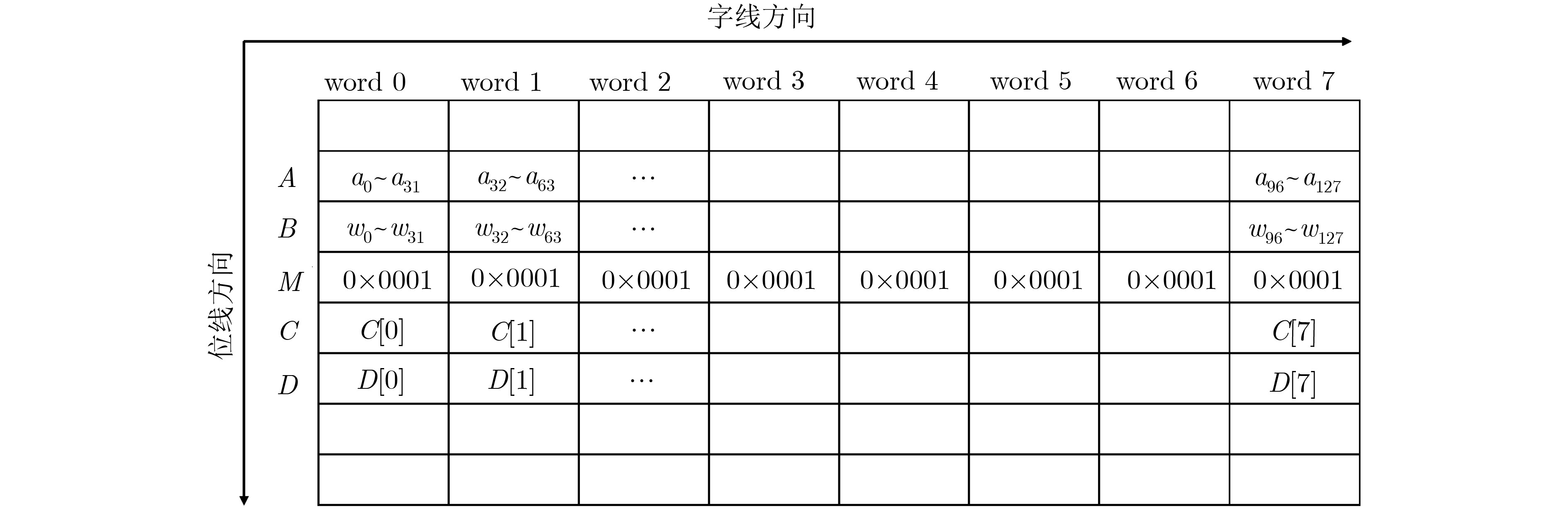
表 6 存内矢量XOR运算和popcount操作算法
输入: int $A[N]$, $B[N]$, $N$为数组A和B长度 输出: S (1) $M[i] \leftarrow {\rm{0x}}0001,i \in [0,N - 1]$ (2) $D[i] \leftarrow 0,i \in \in [0,N - 1]$ (3) $S \leftarrow 0$ (4) $A[i] \leftarrow A[i] \oplus B[i],i \in [0,N - 1]$ (5) $C[i] \leftarrow A[i]\& M[i],i \in [0,N - 1]$ (6) $D[i] \leftarrow D[i] + C[i],i \in [0,N - 1]$ (7) for (i = 0; i < 31; i++) do (8) $C[i] \leftarrow A[i] \gg 1,i \in [0,N - 1]$ (9) $C[i] \leftarrow A[i]\& M[i],i \in [0,N - 1]$ (10) $D[i] \leftarrow D[i] + C[i],i \in [0,N - 1]$ (11) end for (12) for (i = 0; i < N; i++) do (13) $S \leftarrow S + D[i],i \in [0,N - 1]$ (14) end for (15) return $S$
下载: 导出CSV
-
[1] JIN Xiaolong, WAH B W, CHENG Xueqi, et al. Significance and challenges of big data research[J]. Big Data Research, 2015, 2(2): 59–64. doi: 10.1016/j.bdr.2015.01.006 [2] SCHILIZZI R T. The square kilometer array[C]. Proceedings SHE, Ground-based Telescopes, Glasgow, UK, 2004: 62–71. [3] JONGERIUS R, WIJNHOLDS S, NIJBOER R, et al. An end-to-end computing model for the square kilometre array[J]. Computer, 2014, 47(9): 48–54. doi: 10.1109/MC.2014.235 [4] ZASLAVSKY A, PERERA C, and GEORGAKOPOULOS D. Sensing as a service and big data[J]. arXiv preprint arXiv: 1301.0159, 2013. [5] FLORIDI L. Big data and their epistemological challenge[J]. Philosophy & Technology, 2012, 25(4): 435–437. doi: 10.1007/s13347-012-0093-4 [6] REINSEL D, GANTZ J, and RYDNING J. Data age 2025: The digitization of the world from edge to core[R]. IDC White Paper–#US44413318, 2018. [7] SIEGL P, BUCHTY R, and BEREKOVIC M. Data-Centric computing frontiers: A survey on processing-in-memory[C]. Proceedings of the Second International Symposium on Memory Systems (MEMSYS'16), Alexandria, USA, 2016: 295–308. doi: 10.1145/2989081.2989087. [8] PATTERSON D, ANDERSON T, CARDWELL N, et al. A case for intelligent RAM[J]. IEEE Micro, 1997, 17(2): 34–44. doi: 10.1109/40.592312 [9] ROGERS B M, KRISHNA A, BELL G B, et al. Scaling the bandwidth wall: Challenges in and avenues for CMP scaling[J]. ACM SIGARCH Computer Architecture News, 2009, 37(3): 371–382. doi: 10.1145/1555815.1555801 [10] DAS R. Blurring the lines between memory and computation[J]. IEEE Micro, 2017, 37(6): 13–15. doi: 10.1109/MM.2017.4241340 [11] ZHU Qiuling, AKIN B, SUMBUL H E, et al. A 3D-stacked logic-in-memory accelerator for application-specific data intensive computing[C]. 2013 IEEE International 3D Systems Integration Conference (3DIC), San Francisco, USA, 2013: 1–7. doi: 10.1109/3DIC.2013.6702348. [12] AHN J, HONG S, YOO S, et al. A scalable processing-in-memory accelerator for parallel graph processing[C]. Proceeding of the ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA'15), Portland, USA, 2015: 105–117. doi: 10.1145/2749469.2750386. [13] AHN J, YOO S, MUTLU O, et al. PIM-enabled instructions: A low-overhead, locality-aware processing-in-memory architecture[C]. The 42nd Annual International Symposium on Computer Architecture (ISCA'15), Portland, USA, 2015: 336–348. doi: 10.1145/2749469.2750385. [14] CHI Ping, LI Shuangchen, XU Cong, et al. PRIME: A novel processing-in-memory architecture for neural network computation in ReRAM-based main memory[J]. ACM SIGARCH Computer Architecture News, 2016, 44(3): 27–39. doi: 10.1145/3007787.3001140 [15] HALAWANI Y, MOHAMMAD B, LEBDEH M A, et al. ReRAM-based in-memory computing for search engine and neural network applications[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2019, 9(2): 388–397. doi: 10.1109/JETCAS.2019.2909317 [16] ZHANG Bin, CHEN Weilin, ZENG Jianmin, et al. 90% yield production of polymer nano-memristor for in-memory computing[J]. Nature Communications, 2021, 12(1): 1984. doi: 10.1038/s41467-021-22243-8 [17] JELOKA S, AKESH N B, SYLVESTER D, et al. A 28 nm configurable memory (TCAM/BCAM/SRAM) using push-rule 6T bit cell enabling logic-in-memory[J]. IEEE Journal of Solid-State Circuits, 2016, 51(4): 1009–1021. doi: 10.1109/JSSC.2016.2515510 [18] AGA S, JELOKA S, SUBRAMANIYAN A, et al. Compute caches[C]. 2017 IEEE International Symposium on High Performance Computer Architecture, Austin, USA, 2017: 481–492. doi: 10.1109/hpca.2017.21. [19] ZHANG Yiqun, XU Li, DONG Qing, et al. Recryptor: A reconfigurable cryptographic cortex-M0 processor with in-memory and near-memory computing for IoT security[J]. IEEE Journal of Solid-State Circuits, 2018, 53(4): 995–1005. doi: 10.1109/JSSC.2017.2776302 [20] ZENG Jianmin, ZHANG Zhang, CHEN Runhao, et al. DM-IMCA: A dual-mode in-memory computing architecture for general purpose processing[J]. IEICE Electronics Express, 2020, 17(4): 20200005. doi: 10.1587/elex.17.20200005 [21] AGRAWAL A, JAISWAL A, ROY D, et al. Xcel-RAM: Accelerating binary neural networks in high-throughput SRAM compute arrays[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2019, 66(8): 3064–3076. doi: 10.1109/TCSI.2019.2907488 [22] YIN Shihui, JIANG Zhewei, SEO J S, et al. XNOR-SRAM: In-memory computing SRAM macro for binary/ternary deep neural networks[J]. IEEE Journal of Solid-State Circuits, 2020, 55(6): 1733–1743. doi: 10.1109/jssc.2019.2963616 [23] LIU Rui, PENG Xiaochen, SUN Xiaoyu, et al. Parallelizing SRAM arrays with customized bit-cell for binary neural networks[C]. 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, USA, 2018: 1–6. doi: 10.1109/DAC.2018.8465935. [24] KANG Mingu, GONUGONDLA S K, PATIL A, et al. A multi-functional in-memory inference processor using a standard 6T SRAM array[J]. IEEE Journal of Solid-State Circuits, 2018, 53(2): 642–655. doi: 10.1109/JSSC.2017.2782087 [25] BELLOVIN S M. Frank miller: Inventor of the one-time pad[J]. Cryptologia, 2011, 35(3): 203–222. doi: 10.1080/01611194.2011.583711 [26] SOBTI R and GEETHA G. Cryptographic hash functions: A review[J]. IJCSI International Journal of Computer Science Issues, 2012, 9(2): 461–479. [27] SEOK B, PARK J, and PARK J H. A lightweight hash-based blockchain architecture for industrial IoT[J]. Applied Sciences, 2019, 9(18): 3740. doi: 10.3390/app9183740 [28] SZE V, CHEN Y H, YANG T J, et al. Efficient processing of deep neural networks: A tutorial and survey[J]. Proceedings of the IEEE, 2017, 105(12): 2295–2329. doi: 10.1109/JPROC.2017.2761740 [29] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791 [30] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv: 1409.1556, 2014. [31] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR'16), Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [32] COURBARIAUX M, HUBARA I, SOUDRY D, et al. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or –1[J]. arXiv preprint arXiv: 1602.02830, 2016. [33] RASTEGARI M, ORDONEZ V, REDMON J, et al. XNOR-Net: ImageNet classification using binary convolutional neural networks[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 525–542. doi: 10.1007/978-3-319-46493-0_32. [34] FOLEY J D, VAN F D, VAN DAM A, et al. Computer Graphics: Principles and Practice[M]. Boston: Addison-Wesley Professional, 1996: 1–1175. [35] WAN Yi and XIE Qisong. A novel framework for optimal RGB to grayscale image conversion[C]. The 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 2016: 345–348. doi: 10.1109/IHMSC.2016.201. [36] PRATT W K. Introduction to Digital Image Processing[M]. Boca Ration: CRC Press, 2013: 1–756. -


 下载:
下载:


图(9) / 表(6)
计量
- 文章访问数: 1999
- HTML全文浏览量: 1750
- PDF下载量: 168
- 被引次数: 0
