

Efficient Hardware Optimization Strategies for Deep Neural Networks Acceleration Chip
-
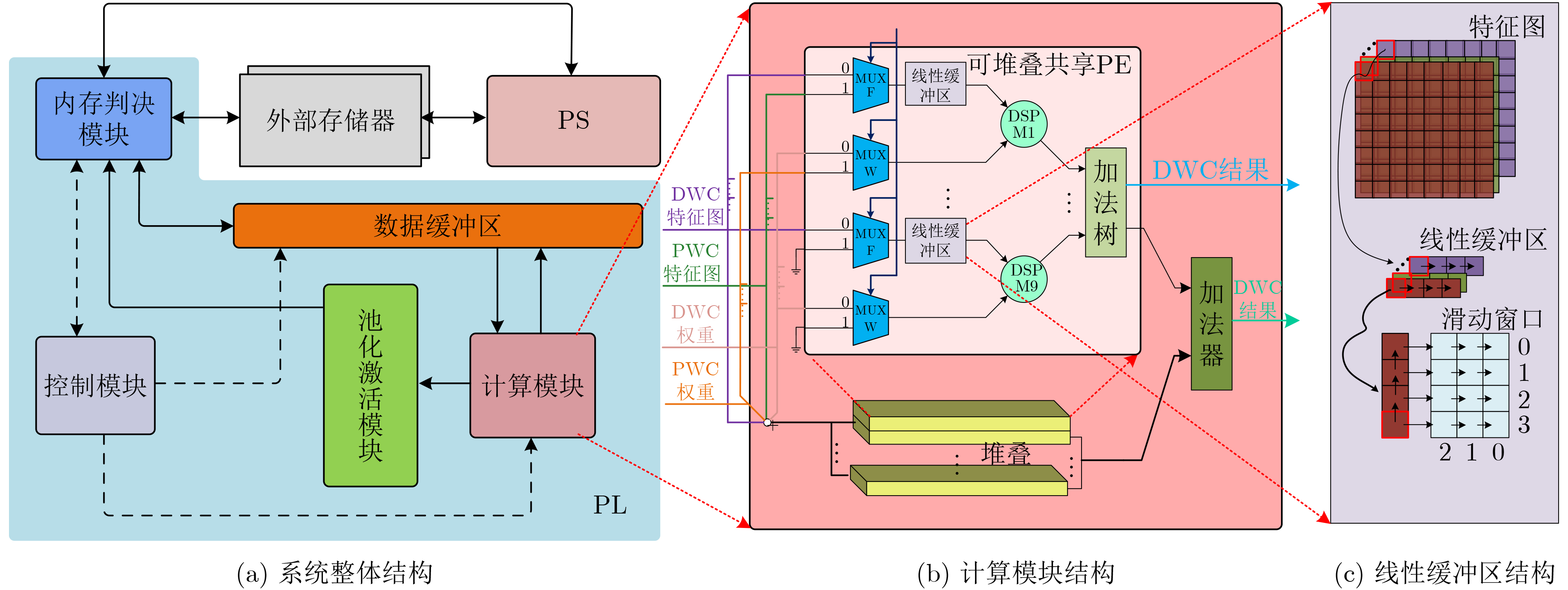
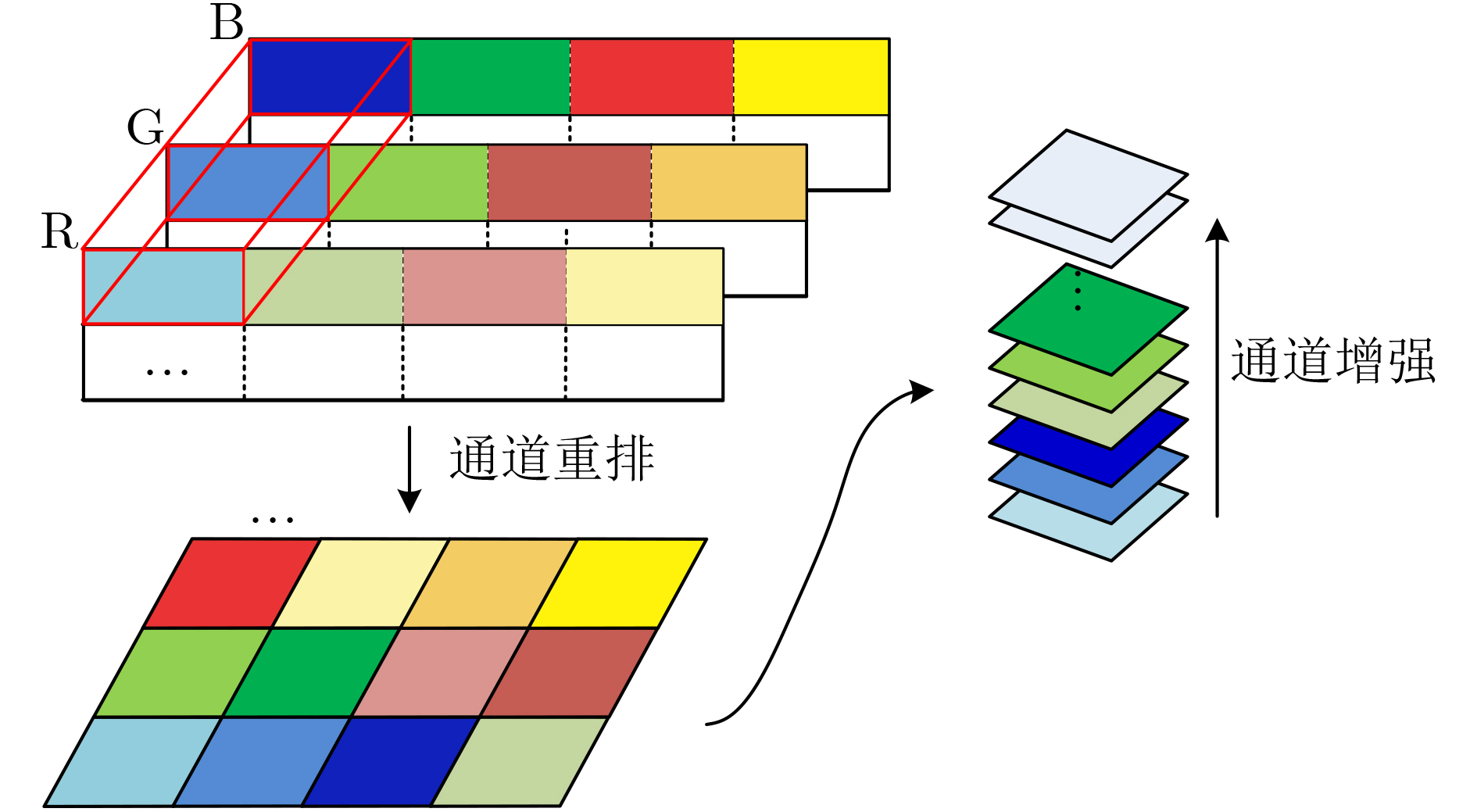
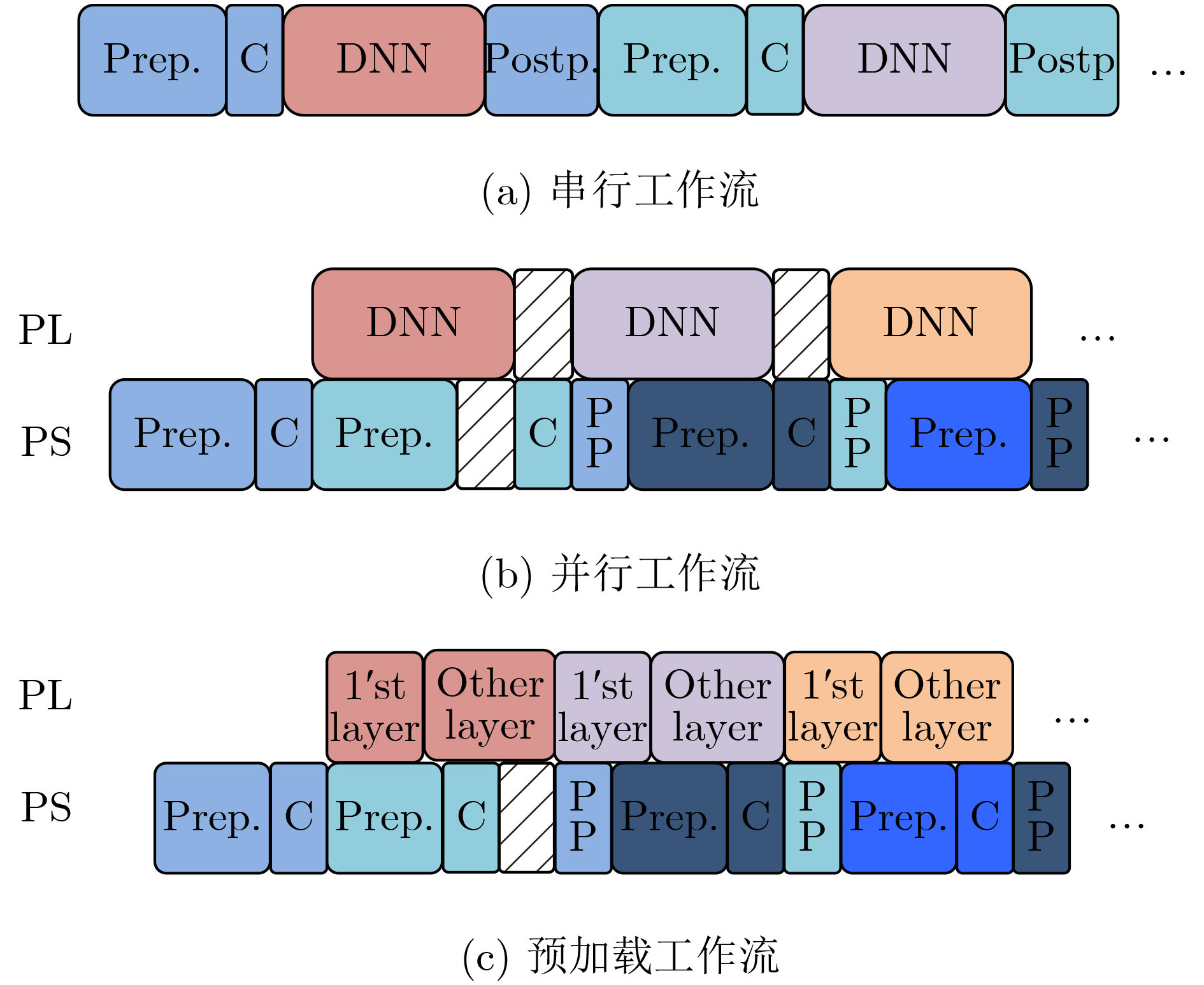
摘要: 轻量级神经网络部署在低功耗平台上的解决方案可有效用于无人机(UAV)检测、自动驾驶等人工智能(AI)、物联网(IOT)领域,但在资源有限情况下,同时兼顾高精度和低延时来构建深度神经网络(DNN)加速器是非常有挑战性的。该文针对此问题提出一系列高效的硬件优化策略,包括构建可堆叠共享计算引擎(PE)以平衡不同卷积中数据重用和内存访问模式的不一致;提出了可调的循环次数和通道增强方法,有效扩展加速器与外部存储器之间的访问带宽,提高DNN浅层网络计算效率;优化了预加载工作流,从整体上提高了异构系统的并行度。经Xilinx Ultra96 V2板卡验证,该文的硬件优化策略有效地改进了iSmart3-SkyNet和SkrSkr-SkyNet类的DNN加速芯片设计。结果显示,优化后的加速器每秒处理78.576帧图像,每幅图像的功耗为0.068 J。Abstract: Lightweight neural networks deployed on low-power platforms have proven to be effective solutions for Artificial Intelligence (AI) and Internet Of Things (IOT) domains such as Unmanned Aerial Vehicle (UAV) detection and unmanned driving. However, in the case of limited resources, it is very challenging to build Deep Neural Networks (DNN) accelerator with both high precision and low delay. In this paper, a series of efficient hardware optimization strategies are proposed, including stackable shared Processing Engine (PE) to balance the inconsistency of data reuse and memory access patterns in different convolutions; Regulable loop parallelism and channel augmentation are proposed to increase effectively the access bandwidth between accelerator and external memory. It also improve the efficiency of DNN shallow layers computing; Pre-Workflow is applied to improve the overall parallelism of heterogeneous systems. Verified by Xilinx Ultra96 V2 board, the hardware optimization strategies in this paper improve effectively the design of DNN acceleration chips like iSmart3-SkyNet and SkrSkr-SkyNet. The results show that the optimized accelerator processes 78.576 frames per second, and the power consumption of each picture is 0.068 Joules.
-
表 1 SkyNet的体系结构和每个捆绑包的推理速度表格
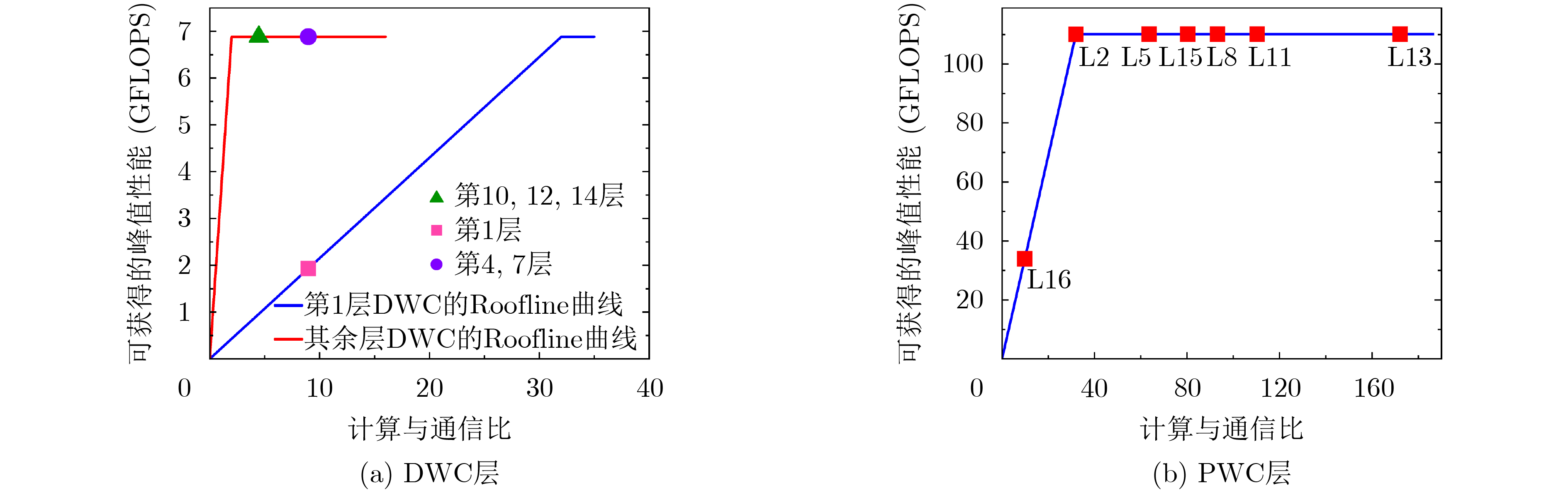
捆绑包 层数 输入尺寸 操作类型 计算量、计算量占比(%) 延迟占比(%) #1 1 3×160×320 DW-Conv3 119.61M, 20.6 33.90 2 3×160×320 PW-Conv1 3 48×160×320 POOLING #2 4 48×80×160 DW-Conv3 86.02M, 14.42 16.54 5 48×80×160 PW-Conv1 6 96×80×160 POOLING #3 7 96×40×80 DW-Conv3 61.75M, 10.36 6.23 8 96×40×80 PW-Conv1 9 192×40×80 POOLING #4 10 192×20×40 DW-Conv3 60.36M, 10.13 4.92 11 192×20×40 PW-Conv1 #5 12 384×20×40 DW-Conv3 160.05M, 26.85 12.43 13 384×20×40 PW-Conv1 #6 – 合并第9层输出 107.52M, 18.04 20.08 14 1280×20×40 [旁路] DW-Conv3 15 1280×20×40 PW-Conv1 #7 16 96×20×40 PW-Conv1 0.77M, 0.14 0.10 – 17 10×20×40 计算回归框 0.16 CPU – – – – 5.64  下载: 导出CSV
下载: 导出CSV
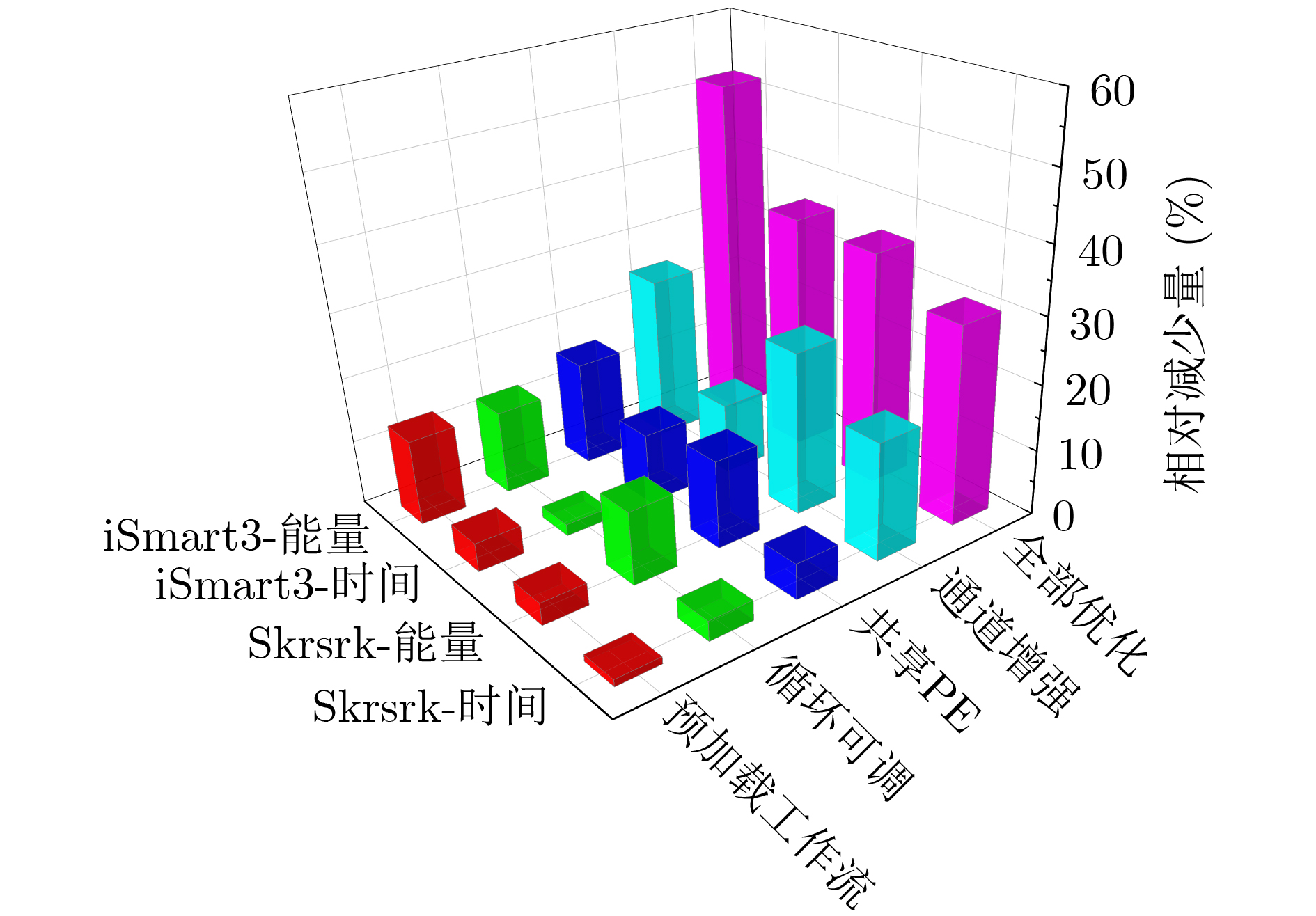
表 2 优化策略效果对比
加速器 iSmart3 [9] SEUer A Skrskr [10] SEUer B 网络模型 SkyNet SkyNet SkyNet SkyNet 量化精度 A9/W11 A9/W11 A8/W6 A8/W6 硬件平台 Ultra96V2 Ultra96V2 Ultra96V2 Ultra96V2 准确率(DJI) 0.716 0.724 0.731 0.731 时钟频率(MHz) 215 215 300 300 DSP数量 329 287 360 360 LUT数量(k) 54 54 56 46 FF数量(k) 60 70 68 51 帧率(fps) 25.05 37.393 52.429 78.576 GOPS/W 3.21 5.95 7.22 11.19 Energy/Pic.(J) 0.289 0.135 0.129 0.068
下载: 导出CSV
-
[1] 王巍, 周凯利, 王伊昌, 等. 基于快速滤波算法的卷积神经网络加速器设计[J]. 电子与信息学报, 2019, 41(11): 2578–2584. doi: 10.11999/JEIT190037WANG Wei, ZHOU Kaili, WANG Yichang, et al. Design of convolutional neural networks accelerator based on fast filter algorithm[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2578–2584. doi: 10.11999/JEIT190037 [2] ZHANG Xiaofan, WANG Junsong, ZHU Chao, et al. DNNBuilder: An automated tool for building high-performance DNN hardware accelerators for FPGAs[C]. 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, USA, 2018: 1–8. [3] LI Huimin, FAN Xitian, JIAO Li, et al. A high performance FPGA-based accelerator for large-scale convolutional neural networks[C]. The 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 2016: 1–9. [4] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. [5] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [6] TAN Mingxing, PANG Ruoming, and LE Q V. EfficientDet: Scalable and efficient object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10781–10790. [7] YU Yunxuan, WU Chen, ZHAO Tiandong, et al. OPU: An FPGA-based overlay processor for convolutional neural networks[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2020, 28(1): 35–47. doi: 10.1109/TVLSI.2019.2939726 [8] YU Yunxuan, ZHAO Tiandong, WANG Kun, et al. Light-OPU: An FPGA-based overlay processor for lightweight convolutional neural networks[C]. 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, USA, 2020: 122–132. [9] ZHANG Xiaofan, LU Haoming, HAO Cong, et al. SkyNet: A hardware-efficient method for object detection and tracking on embedded systems[J]. arXiv: 1909.09709, 2019. [10] JIANG W, LIU X, SUN H, et al. Skrskr: Dacsdc. 2020 2nd place winner in fpga track[EB/OL]. https://github.com/jiangwx/SkrSkr/, 2020. [11] ZHANG Chen, LI Peng, SUN Guangyu, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks[C]. 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2015: 161–170. [12] HAO Cong, ZHANG Xiaofan, LI Yuhong, et al. FPGA/DNN Co-Design: An efficient design methodology for 1ot intelligence on the edge[C]. The 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, USA, 2019: 1–6. [13] MOTAMEDI M, GYSEL P, AKELLA V, et al. Design space exploration of FPGA-based deep convolutional neural networks[C]. The 21st Asia and South Pacific Design Automation Conference (ASP-DAC), Macao, China, 2016: 575–580. [14] FAN Hongxiang, LIU Shuanglong, FERIANC M, et al. A real-time object detection accelerator with compressed SSDLite on FPGA[C]. 2018 International Conference on Field-Programmable Technology (FPT), Naha, Japan, 2018: 14–21. [15] LI Fanrong, MO Zitao, WANG Peisong, et al. A system-level solution for low-power object detection[C]. 2019 IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea (South), 2019: 2461–2468. [16] DONG Zhen, WANG Dequan, HUANG Qijing, et al. CoDeNet: Efficient deployment of input-adaptive object detection on embedded FPGAs[J]. arXiv: 2006.08357, 2020. [17] WU Di, ZHANG Yu, JIA Xijie, et al. A high-performance CNN processor based on FPGA for MobileNets[C]. The 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 2019: 136–143. -

 下载:
下载:



图(6) / 表(2)
计量
- 文章访问数: 1968
- HTML全文浏览量: 1106
- PDF下载量: 208
- 被引次数: 0
