

Gesture Recognition Based on Improved YOLOv4-tiny Algorithm
-
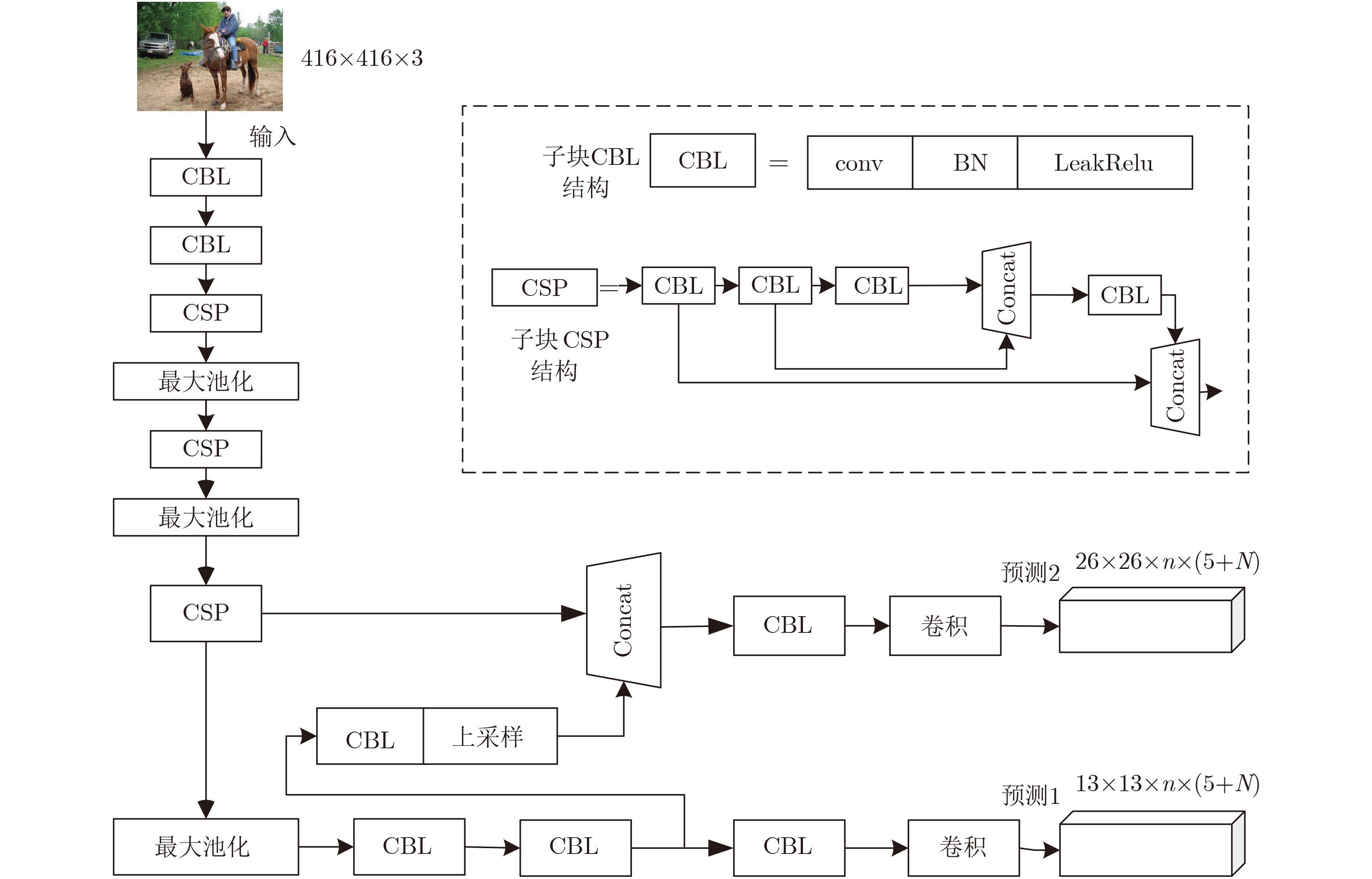
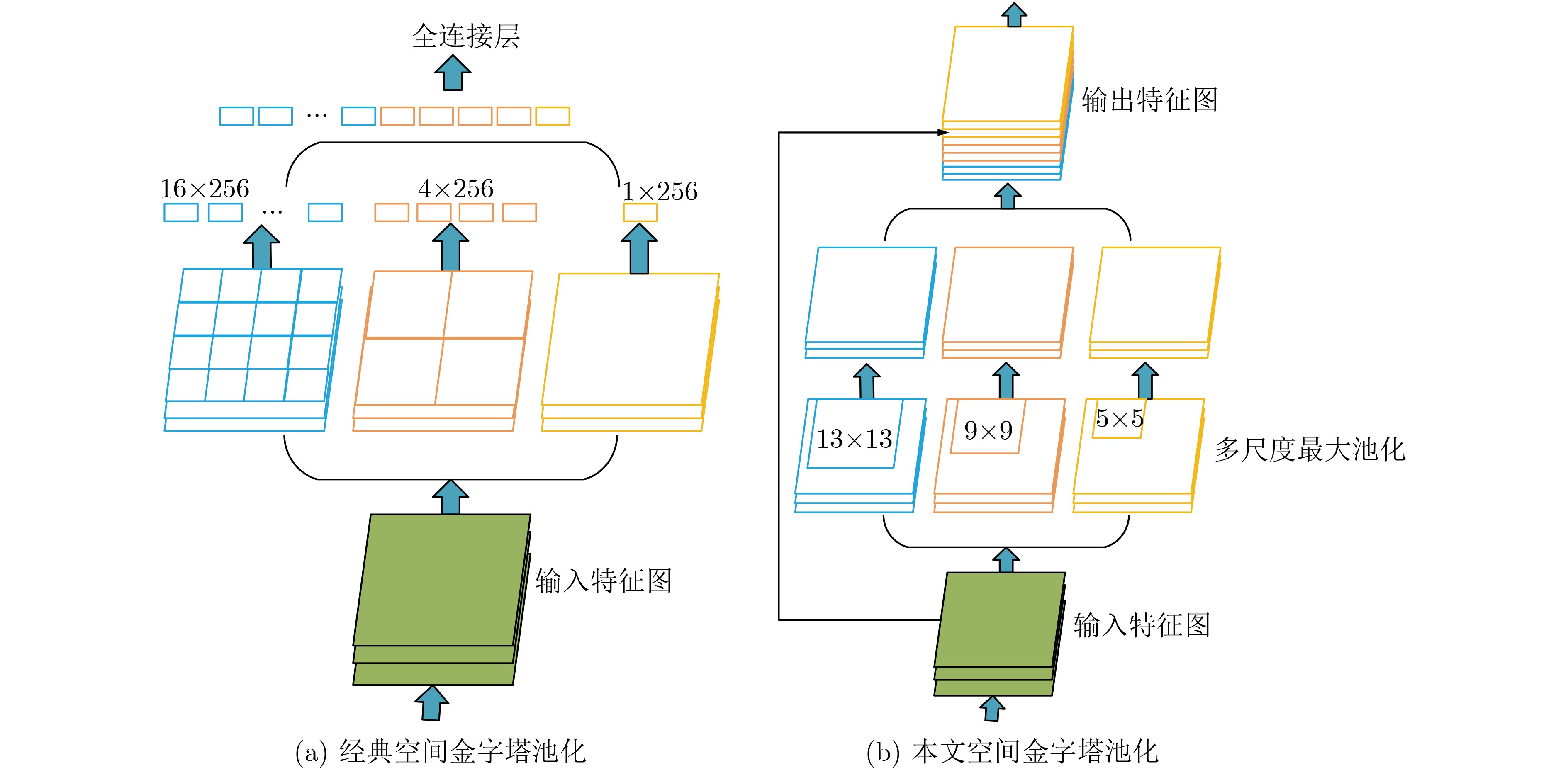
摘要: 随着人机交互的发展,手势识别越来越重要。同时,移动端应用发展迅速,将人机交互技术在移动端实现是一个发展趋势。该文提出一种改进YOLOv4-tiny的手势识别算法。首先,在YOLOv4-tiny网络基础上,添加空间金字塔池化(SPP)模块,融合了图像的局部和全局特征,增强网络的准确定位能力。其次,在YOLOv4-tiny原网络的3个最大池化层和新增SPP模块后各添加一个1×1的卷积模块,减少了网络的参数,提高网络的预测速度。在此基础上,利用K-means++算法生成适合检测手势的先验框,加快网络检测手势。在手势数据集NUS-II上,与YOLOv3-tiny算法和YOLOv4-tiny算法进行对比,改进算法平均精度均值(mAP)为100%,每秒传输帧数(fps)为377,可以快速准确地检测识别手势。将该文改进算法部署在安卓(Android)移动端,实现了移动端实时的手势检测与识别,对人机交互的发展有很大的研究意义。
-
关键词:
- 手势识别 /
- 人机交互 /
- YOLOv4-tiny /
- 安卓
Abstract: With the development of human-computer interaction, gesture recognition is becoming more and more important. At the same time, mobile terminal applications are developing rapidly, it is a development trend to implement human-computer interaction technology on the mobile terminal. An improved YOLOv4-tiny gesture recognition algorithm is proposed. Firstly, on the basis of YOLOv4-tiny network, the Spatial Pyramid Pooling(SPP) module is added to integrate the local and global features of the image to enhance the accurate positioning ability of the network. Secondly, a 1×1 convolution is added after the 3 maximum pooling layers of the original YOLOv4-tiny network and the newly added SPP module, which reduces the network parameters and improves the prediction speed of the network. On this basis, the K-means++ algorithm is used to generate an anchor box suitable for detecting gestures to speed up the network detection of gestures. In the gesture dataset NUS-II, compared with the YOLOv3-tiny algorithm and the YOLOv4-tiny algorithm, the improved algorithm mean Average Precision(mAP) is 100%, frames per second (fps) is 377, which can detect and recognize gestures quickly and accurately. The improved algorithm of this paper is deployed on the Android mobile terminal to realize the real-time gesture detection and recognition on the mobile terminal, which has great research significance for the development of human-computer interaction.-
Key words:
- Gesture recognition /
- Human computer interaction /
- YOLOv4-tiny /
- Android
-
[1] 夏朝阳, 周成龙, 介钧誉, 等. 基于多通道调频连续波毫米波雷达的微动手势识别[J]. 电子与信息学报, 2020, 42(1): 164–172. doi: 10.11999/JEIT190797XIA Zhaoyang, ZHOU Chenglong, JIE Junyu, et al. Micro-motion gesture recognition based on multi-channel frequency modulated continuous wave millimeter wave radar[J]. Journal of Electronics &Information Technology, 2020, 42(1): 164–172. doi: 10.11999/JEIT190797 [2] OYEDOTUN O K and KHASHMAN A. Deep learning in vision-based static hand gesture recognition[J]. Neural Computing and Applications, 2017, 28(12): 3941–3951. doi: 10.1007/s00521-016-2294-8 [3] 王龙, 刘辉, 王彬, 等. 结合肤色模型和卷积神经网络的手势识别方法[J]. 计算机工程与应用, 2017, 53(6): 209–214. doi: 10.3778/j.issn.1002-8331.1508-0251WANG Long, LIU Hui, WANG Bin, et al. Gesture recognition method combining skin color models and convolution neural network[J]. Computer Engineering and Applications, 2017, 53(6): 209–214. doi: 10.3778/j.issn.1002-8331.1508-0251 [4] MOHANTY A, RAMBHATLA S S, and SAHAY R R. Deep gesture: Static hand gesture recognition using CNN[C]. International Conference on Computer Vision and Image Processing, Singapore, 2017: 449–461. doi: 10.1007/978-981-10-2107-7_41. [5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91. [6] REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6517–6525. doi: 10.1109/CVPR.2017.690. [7] REDMON J and FARHADI A. YOLOv3: An incremental improvement[EB/OL]. http://arxiv.org/abs/1804.02767, 2018. [8] BOCHKOVSKIY A, WANG C Y, and LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detector[EB/OL]. https://arxiv.org/abs/2004.10934v1, 2020. [9] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2. [10] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]. The IEEE Transactions on Pattern Analysis and Machine Intelligence, Venice, Italy, 2017: 2999–3007. doi: 10.1109/TPAMI.2018.2858826. [11] LAW H and DENG Jia. CornerNet: Detecting objects as paired keypoints[C]. The 15th European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 765–781. doi: 10.1007/978-3-030-01264-9_45. [12] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81. [13] GIRSHICK R. Fast R-CNN[C]. IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1440–1448. doi: 10.1109/ICCV.2015.169. [14] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [15] DAI Jifeng, LI Yi, HE Kaiming, et al. R-FCN: Object detection via region-based fully convolutional networks[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 379–387. doi: 10.5555/3157096.3157139. [16] SOE H M and NAING T M. Real-time hand pose recognition using faster region-based convolutional neural network[C]. The First International Conference on Big Data Analysis and Deep Learning, Singapore, 2019: 104–112. doi: 10.1007/978-981-13-0869-7_12. [17] PISHARADY P K, VADAKKEPAT P, and LOH A P. Attention based detection and recognition of hand postures against complex backgrounds[J]. International Journal of Computer Vision, 2013, 101(3): 403–419. doi: 10.1007/s11263-012-0560-5 [18] 常建红. 基于改进Faster RCNN算法的手势识别研究[D]. [硕士论文], 河北大学, 2020. doi: 10.27103/d.cnki.ghebu.2020.001315.CHANG Jianhong. The gesture recognition research based on the improved faster RCNN algorithm[D]. [Master dissertation], Hebei University, 2020. doi: 10.27103/d.cnki.ghebu.2020.001315. [19] 张勋, 陈亮, 胡诚, 等. 一种基于深度学习的静态手势实时识别方法[J]. 现代计算机, 2017(34): 6–11. doi: 10.3969/j.issn.1007-1423.2017.34.002ZHANG Xun, CHEN Liang, HU Cheng, et al. A real-time recognition method of static gesture based on depth learning[J]. Modern Computer, 2017(34): 6–11. doi: 10.3969/j.issn.1007-1423.2017.34.002 [20] 彭玉青, 赵晓松, 陶慧芳, 等. 复杂背景下基于深度学习的手势识别[J]. 机器人, 2019, 41(4): 534–542. doi: 10.13973/j.cnki.robot.180568PENG Yuqing, ZHAO Xiaosong, TAO Huifang, et al. Hand gesture recognition against complex background based on deep learning[J]. Robot, 2019, 41(4): 534–542. doi: 10.13973/j.cnki.robot.180568 [21] 王粉花, 黄超, 赵波, 等. 基于YOLO算法的手势识别[J]. 北京理工大学学报, 2020, 40(8): 873–879. doi: 10.15918/j.tbit1001-0645.2019.030WANG Fenhua, HUANG Chao, ZHAO Bo, et al. Gesture recognition based on YOLO algorithm[J]. Transactions of Beijing Institute of Technology, 2020, 40(8): 873–879. doi: 10.15918/j.tbit1001-0645.2019.030 [22] JIANG Zicong, ZHAO Liquan, LI Shuaiyang, et al. Real-time object detection method based on improved YOLOv4-tiny[EB/OL]. https://arxiv.org/abs/2011.04244, 2020. [23] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824 [24] GitHub, Inc. NIHUI. ncnn[EB/OL]. https://github.com/Tencent/ncnn, 2021. -

 下载:
下载:









图(10) / 表(1)
计量
- 文章访问数: 3892
- HTML全文浏览量: 2951
- PDF下载量: 443
- 被引次数: 0
