

Seal Text Detection and Recognition Algorithm with Angle Optimization Network
-
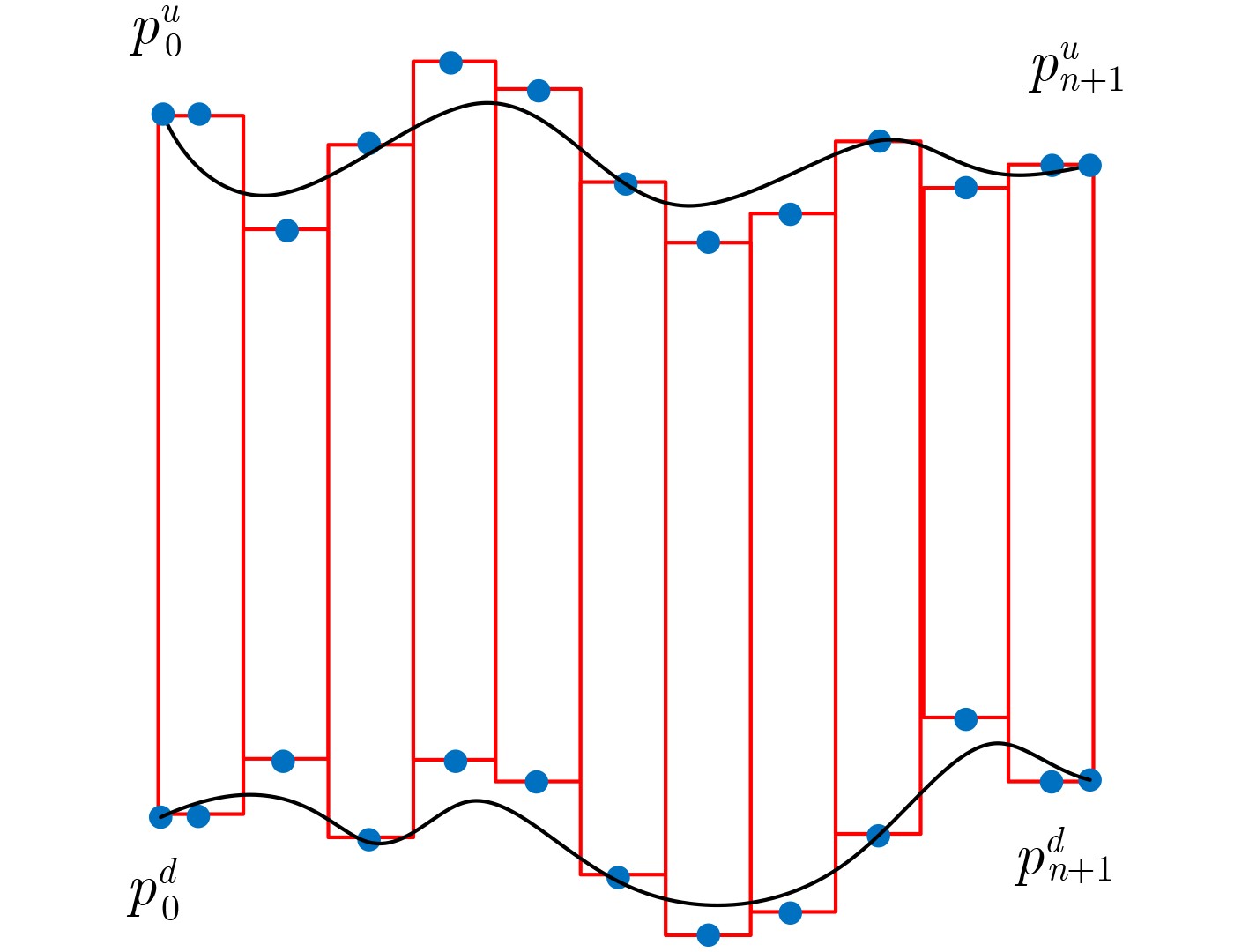
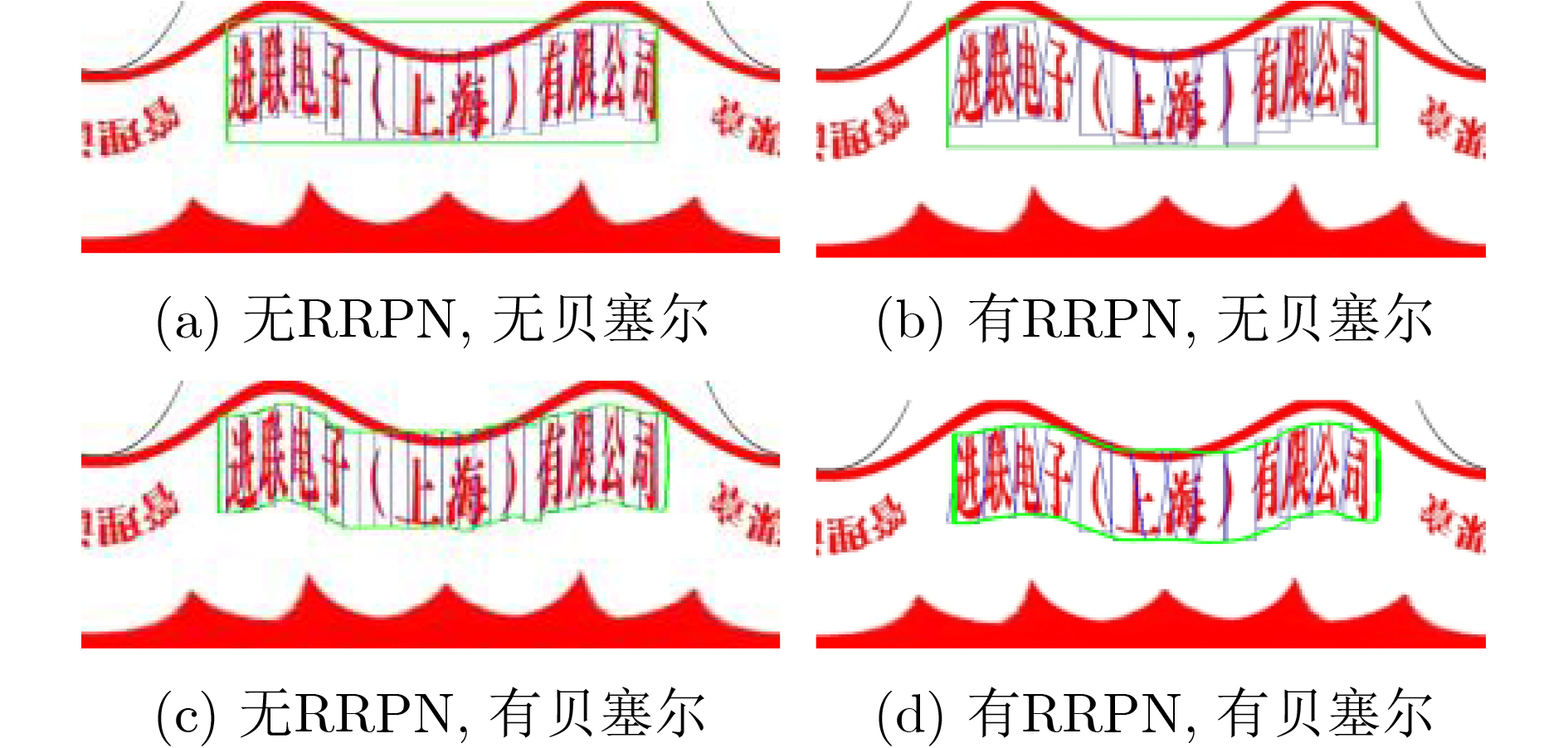
摘要: 利用光学字符识别方法对印章文字进行检测与识别,能够加快各类合同的分类处理速度与鉴别效率。该文针对圆形印章文字呈环形排列的特点,利用极坐标展开对印章文字进行预处理,克服了印章文字方向不统一的问题。对于展开后上下起伏的文本区域,利用带角度信息的联结文本提议网(CTPN)对印章文字区域进行检测,并使用贝塞尔拟合文本区域,实现了对印章区域的准确检测。最后利用注意力转移机制和该文匹配算法对检测的文字区域进行识别,输出印章文字内容。运用该算法对输出印章文字内容自制的中文印章数据集进行实验,印章内容的文字检测F值可以达到84.73%,文字识别召回率达到84.4%,表明该算法可以有效地检测识别印章内容,对文档的分类与鉴别研究具有重要的意义。Abstract: Using the methods of Optical Character Recognition (OCR) to detect and recognize the seal characters can speed up the classification speed and identification efficiency of all kinds of contracts. According to the characteristics of the cycle seal characters arranged in a ring, polar coordinate conversion is used to preprocess the seal characters, which overcomes the problem that the direction of the seal characters is not uniform. The Connectionist Text Proposal Network (CTPN) with angle information is used to detect the undulating text area, and the Bezier curve is used to achieve the accurate detection of the seal area. Finally, a method combined with the attention mechanism and the matching algorithm is used to recognize the detected text area and the seal text content is obtained. Using this algorithm to test the self-made Chinese seal data set, the F-measure of the seal content can reach 84.73%, and the recall rate of the character recognition is 84.4%, which shows that this algorithm can detect and recognize the seal content effectively, and has an important meaning for the research of document classification and identification.
-
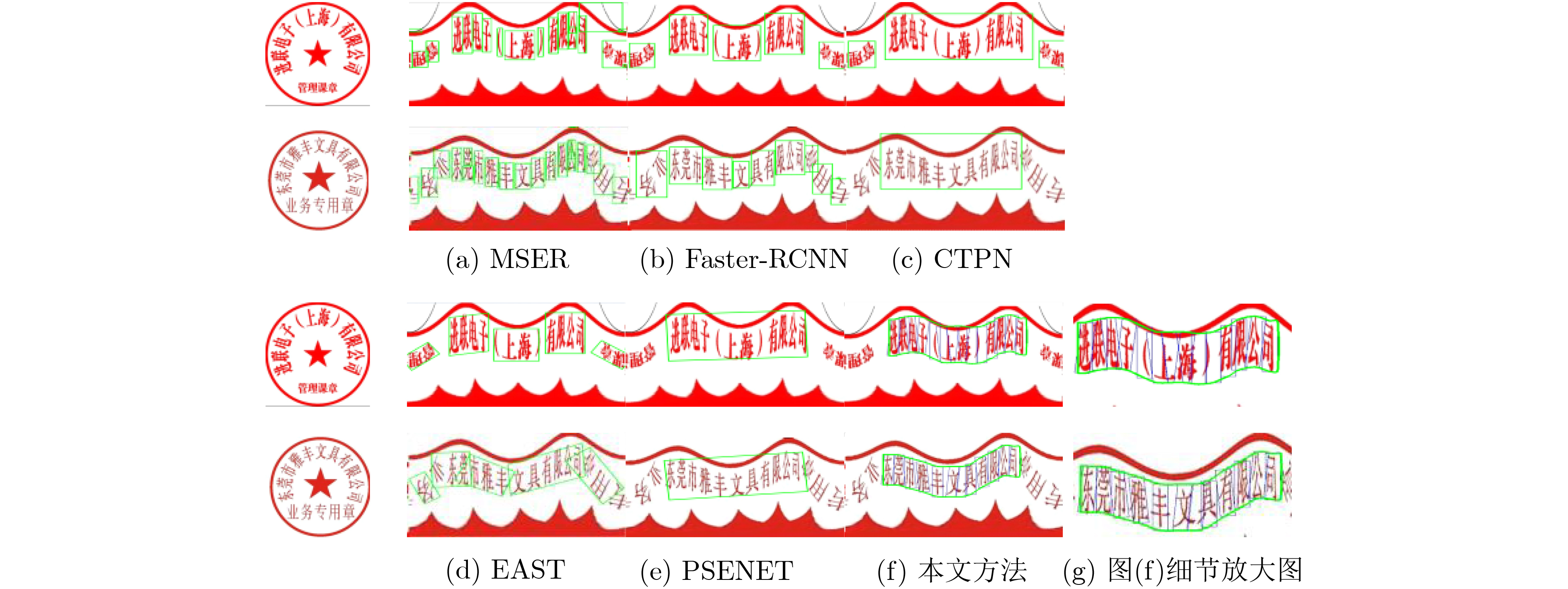
表 1 印章文字检测效果对比(%)
方法 召回率 准确率 F值 MSER 36.27 44.36 39.69 Faster-RCNN 36.55 40.23 37.77 CTPN 51.56 74.22 60.82 EAST 77.33 85.27 81.06 PSENET 74.24 96.07 83.76 本文方法 82.17 87.47 84.73  下载: 导出CSV
下载: 导出CSV
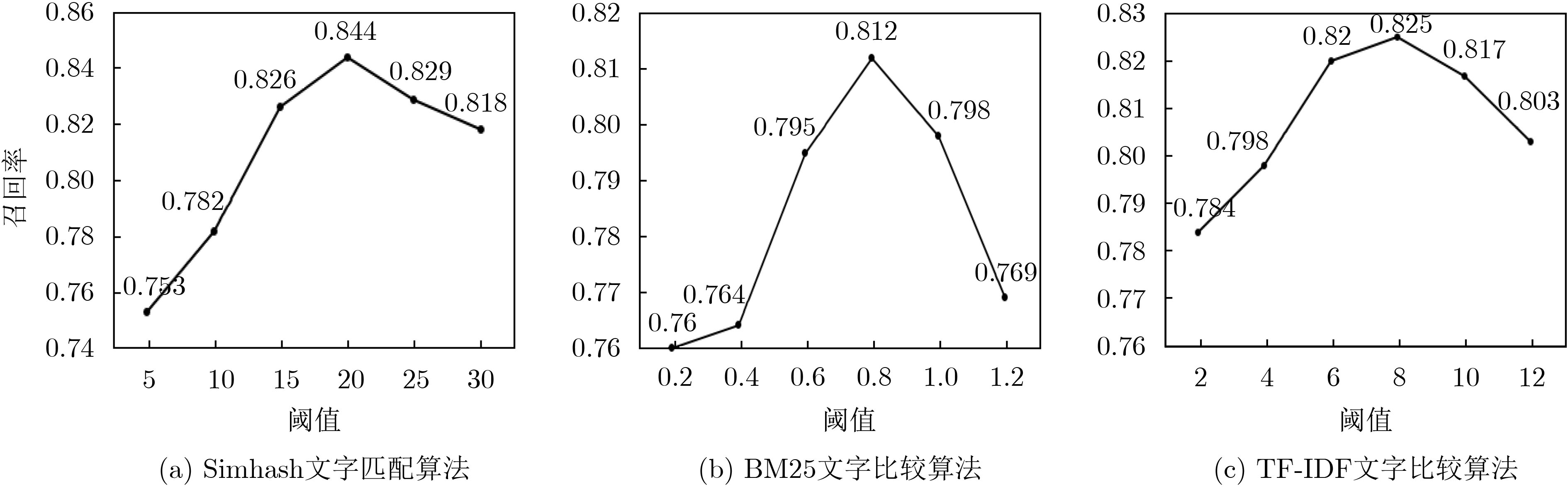
表 2 印章文字识别效果对比
方法 印章数据集 召回率(%) 耗时(s) CNN+RNN+CTC 71.3 0.722 CNN+RNN+Seq2Seq 74.8 0.612 CNN+RNN+CTC+Simhash 82.3 0.833 CNN+RNN+Seq2Seq+Simhash (本文) 84.4 0.640
下载: 导出CSV
-
[1] LIN Han, YANG Peng, and ZHANG Fanlong. Review of scene text detection and recognition[J]. Archives of Computational Methods in Engineering, 2020, 27(2): 433–454. doi: 10.1007/s11831-019-09315-1 [2] TIAN Zhi, HUANG Weilin, HE Tong, et al. Detecting text in natural image with connectionist text proposal network[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 56–72. [3] SHI Baoguang, BAI Xiang, and BELONGIE S. Detecting oriented text in natural images by linking segments[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3482–3490. [4] ZHOU Xinyu, YAO Cong, WEN He, et al. EAST: An efficient and accurate scene text detector[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2642–2651. [5] LONG J, SHELHAMER E, DARRELL T, et al. Fully convolutional networks for semantic segmentation[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3431–3440. [6] SHI Baoguang, BAI Xiang, and YAO Cong. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(11): 2298–2304. doi: 10.1109/TPAMI.2016.2646371 [7] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5998–6008. [8] STAUDEMEYER R C and MORRIS E R. Understanding LSTM—a tutorial into long short-term memory recurrent neural networks[J]. arXiv: 1909.09586, 2019. [9] WANG Qingqing, HUANG Ye, JIA Wenjing, et al. FACLSTM: ConvLSTM with focused attention for scene text recognition[J]. Science China Information Sciences, 2020, 63(2): 120103. doi: 10.1007/s11432-019-2713-1 [10] MA Jianqi, SHAO Weiyuan, YE Hao, et al. Arbitrary-oriented scene text detection via rotation proposals[J]. IEEE Transactions on Multimedia, 2018, 20(11): 3111–3122. doi: 10.1109/TMM.2018.2818020 [11] 李彩林, 张青华, 陈文贺, 等. 基于深度学习的绝缘子定向识别算法[J]. 电子与信息学报, 2020, 42(4): 1033–1040. doi: 10.11999/JEIT190350LI Cailin, ZHANG Qinghua, CHEN Wenhe, et al. Insulator orientation detection based on deep learning[J]. Journal of Electronics &Information Technology, 2020, 42(4): 1033–1040. doi: 10.11999/JEIT190350 [12] 杨旸, 杨书略, 柯闽. 加密云数据下基于Simhash的模糊排序搜索方案[J]. 计算机学报, 2017, 40(2): 431–444. doi: 10.11897/SP.J.1016.2017.00431YANG Yang, YANG Shulue, and KE Min. Ranked fuzzy keyword search based on Simhash over encrypted cloud data[J]. Chinese Journal of Computers, 2017, 40(2): 431–444. doi: 10.11897/SP.J.1016.2017.00431 [13] KARATZAS D, SHAFAIT F, UCHIDA S, et al. ICDAR 2013 robust reading competition[C]. The 12th International Conference on Document Analysis and Recognition, Washington, USA, 2013: 1484–1493. [14] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 91–99. [15] 陈乐乐, 黄松, 孙金磊, 等. 基于BM25算法的问题报告质量检测方法[J]. 清华大学学报: 自然科学版, 2020, 60(10): 829–836.CHEN Lele, HUANG Song, SUN Jinlei, et al. Bug report quality detection based on the BM25 algorithm[J]. Journal of Tsinghua University:Science and Technology, 2020, 60(10): 829–836. -


 下载:
下载:







图(10) / 表(2)
计量
- 文章访问数: 2933
- HTML全文浏览量: 1784
- PDF下载量: 146
- 被引次数: 0
