

Passive Tracking Method with Two-hierarchy Sampling Based on Leg-by-leg Maneuver
-
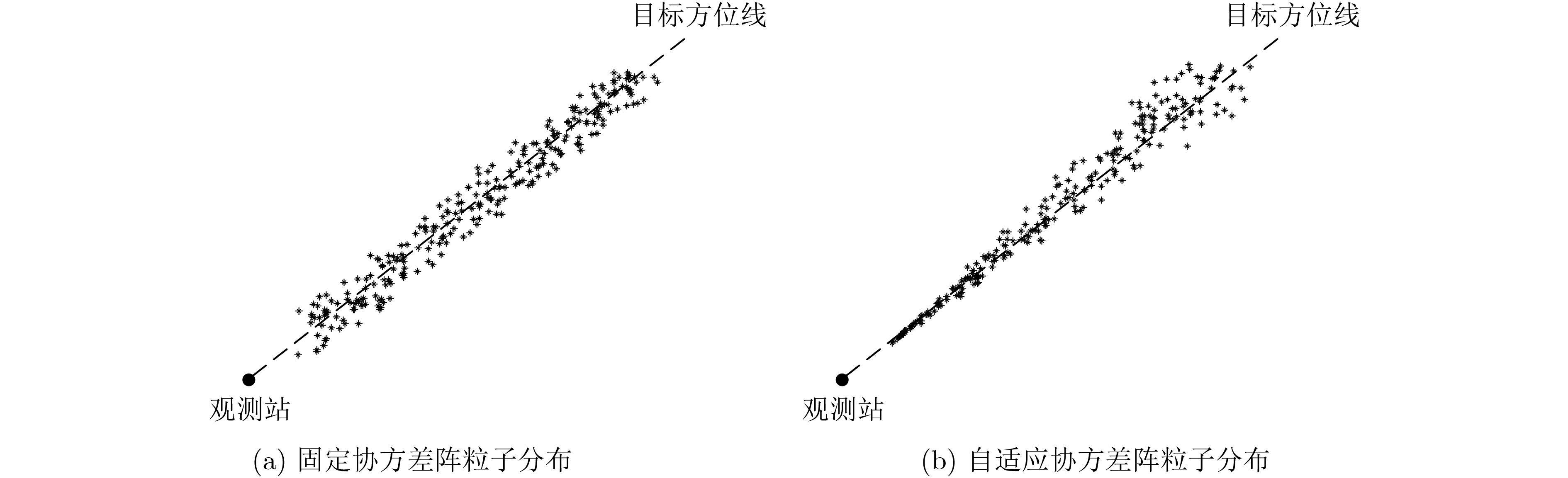
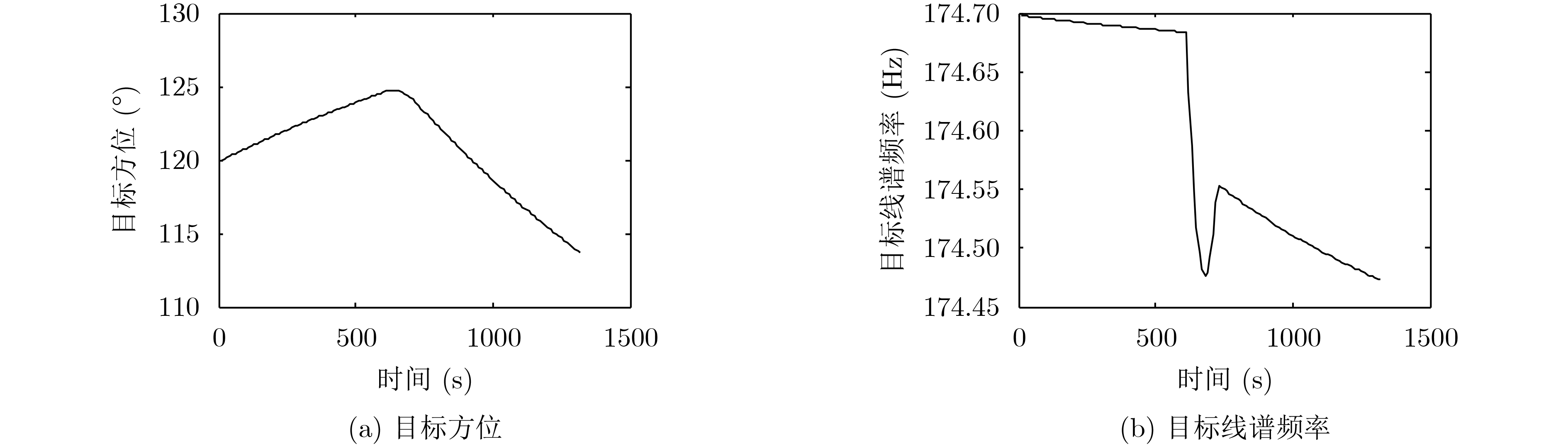
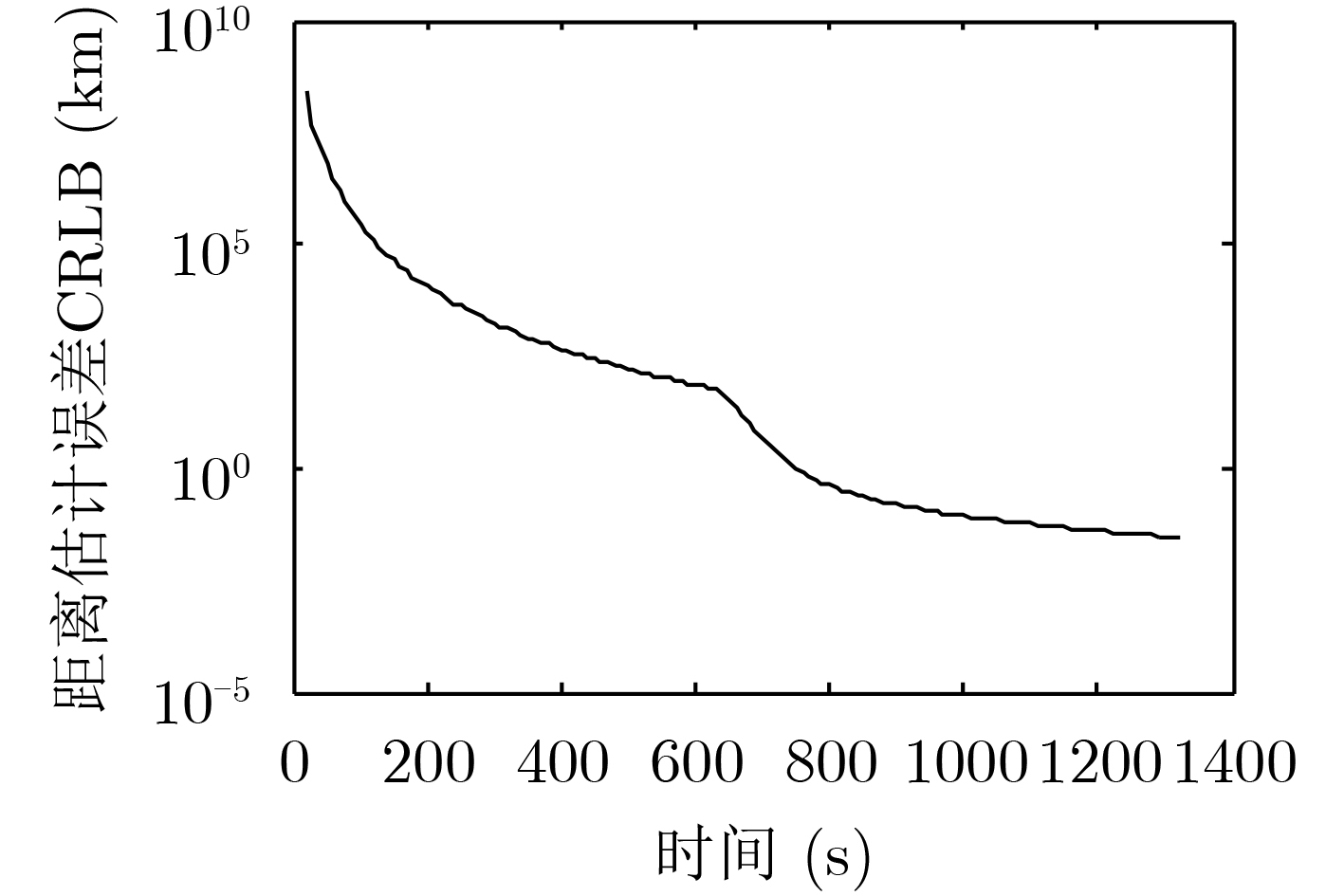
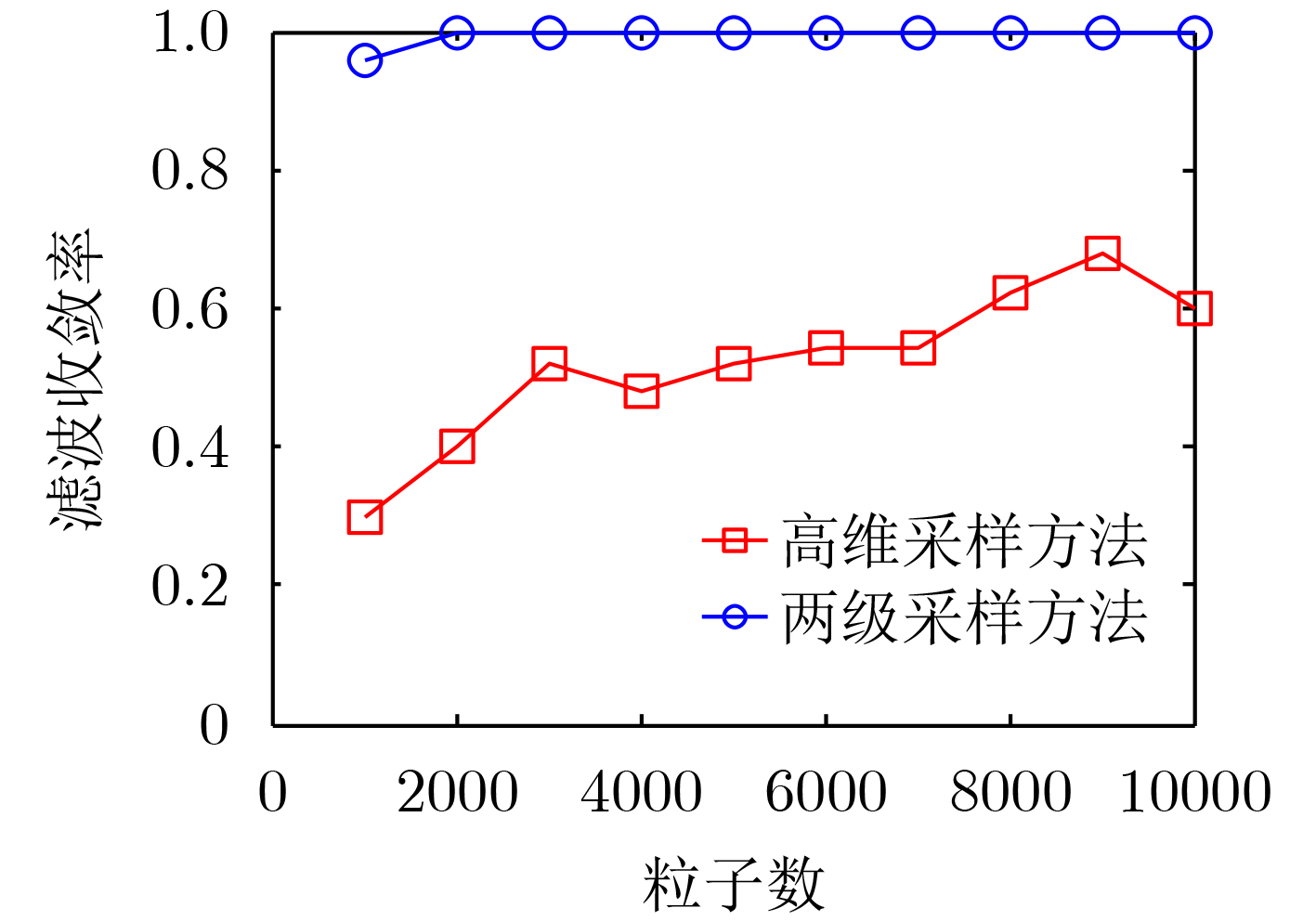
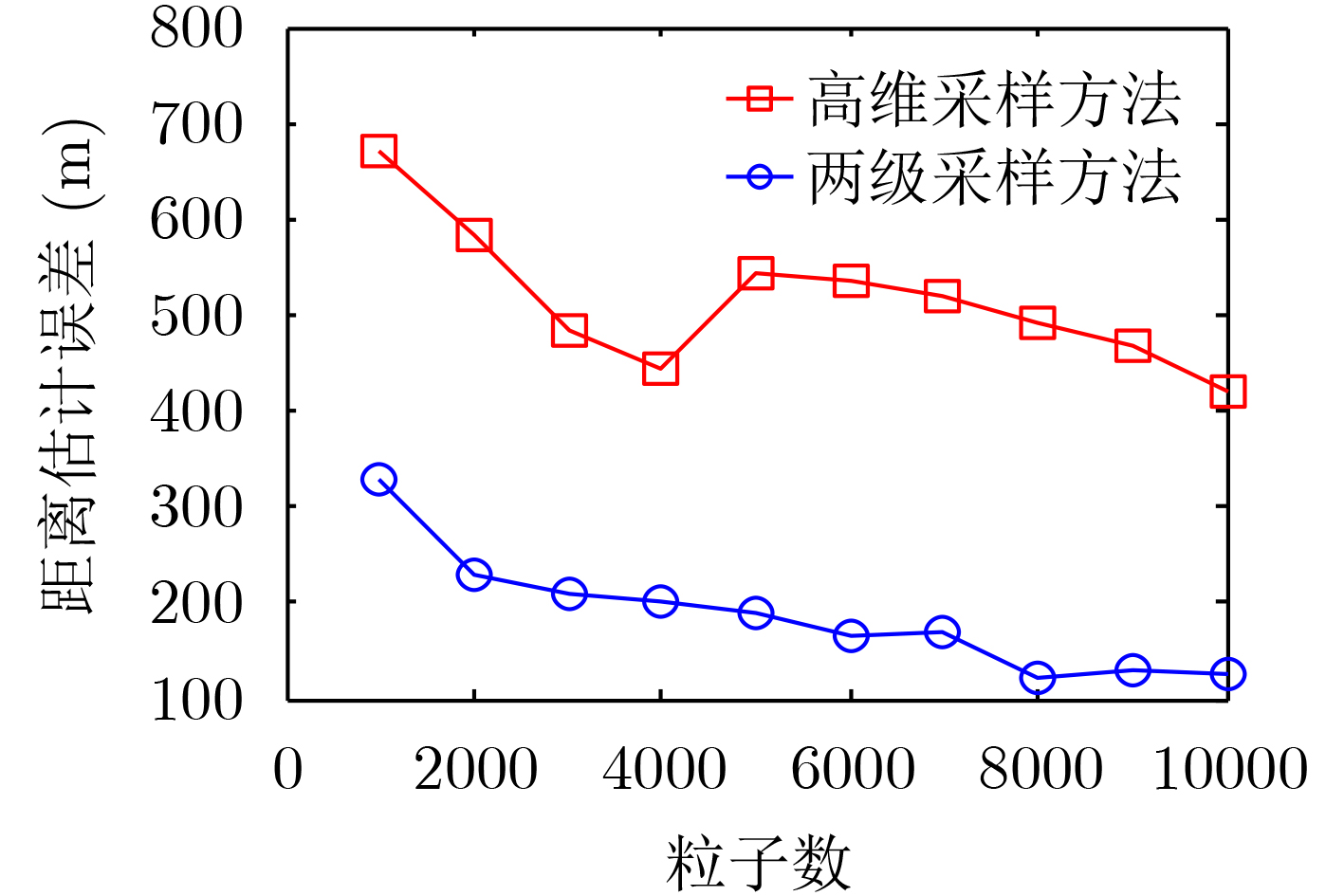
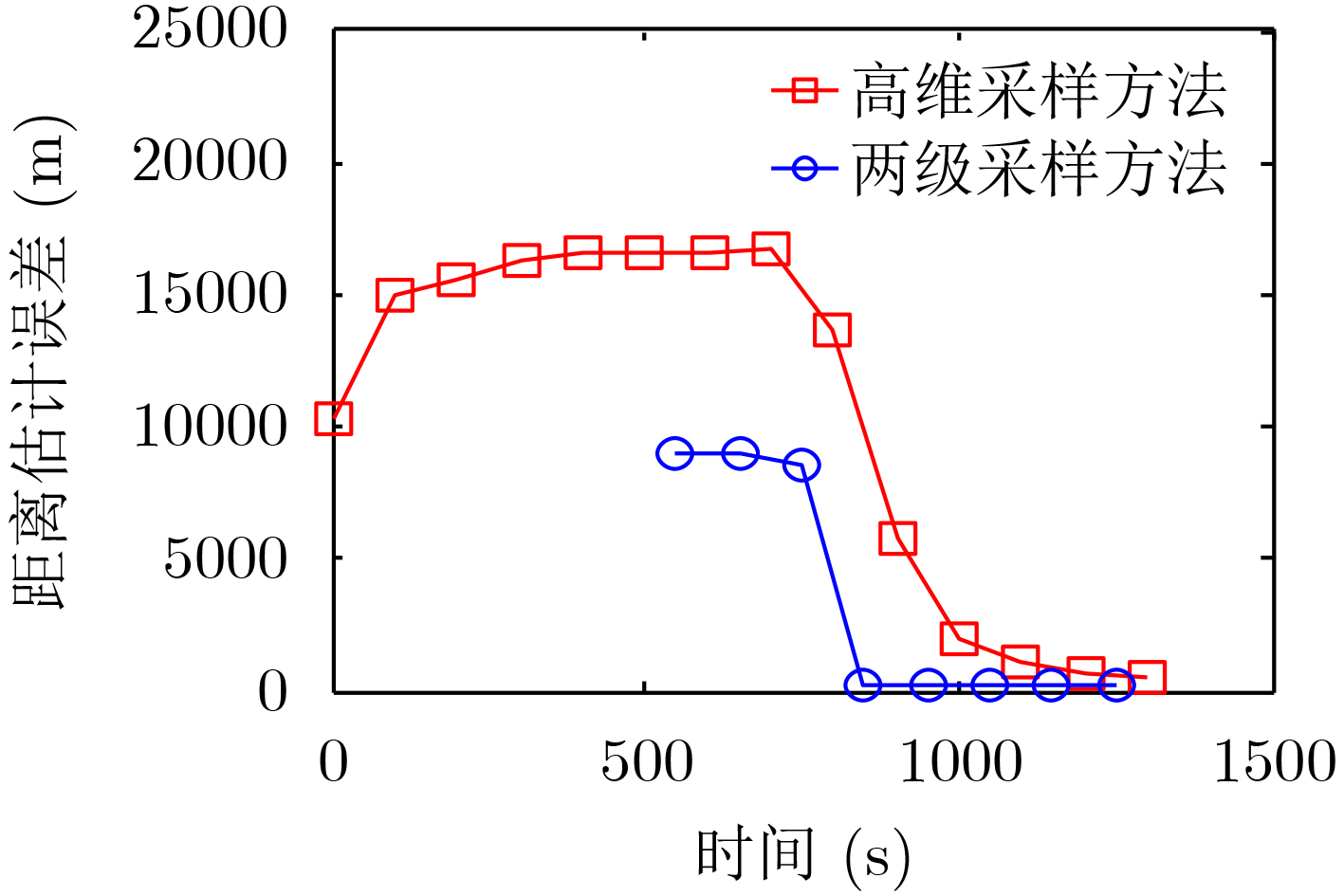
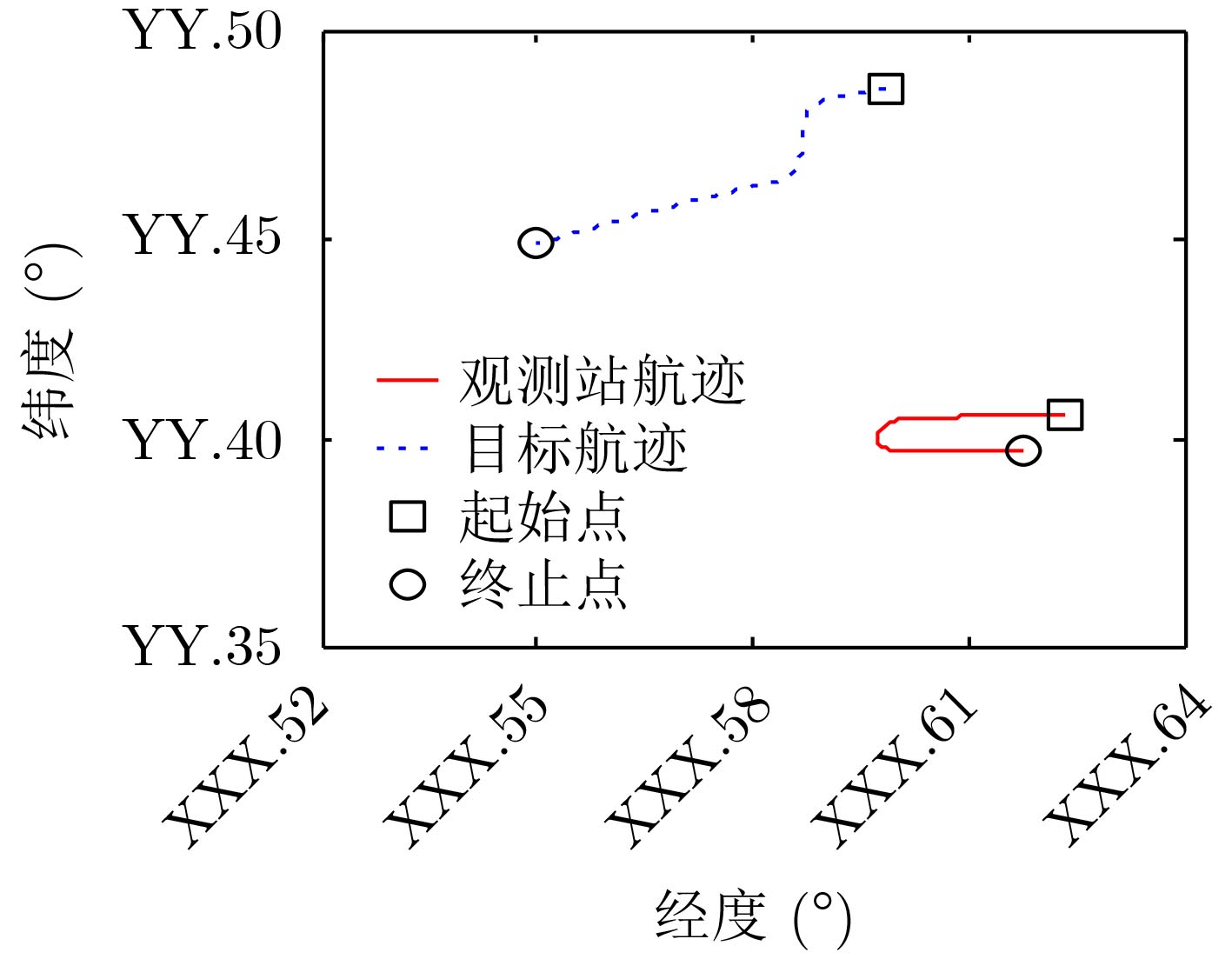
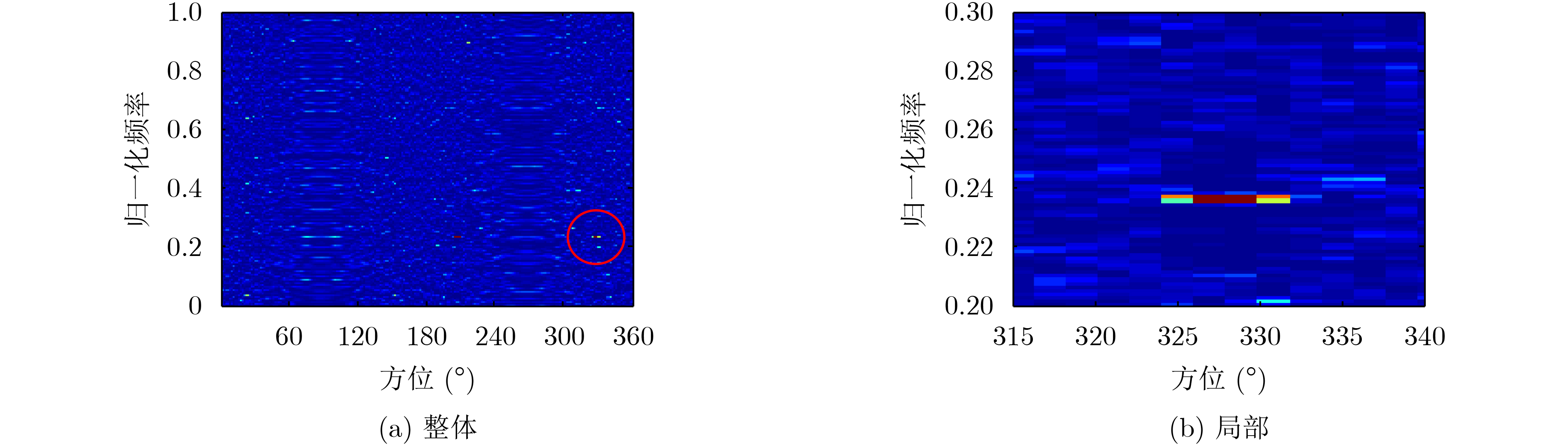
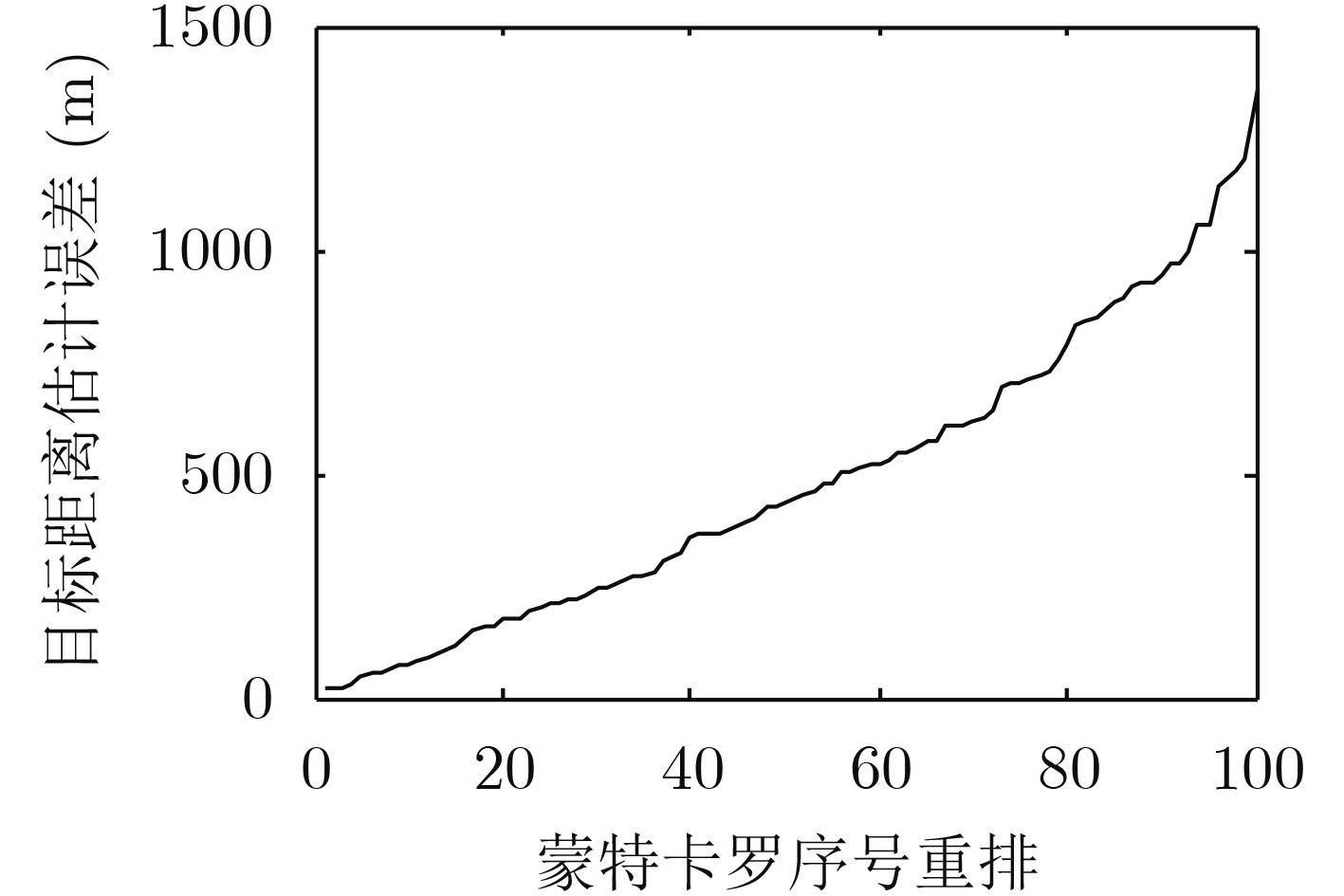
摘要: 针对被动声呐方位-频率观测情况下粒子滤波检测前跟踪算法中高维采样效率低的问题,该文提出一种利用leg-by-leg机动可观测性特点的两级采样方法。首先,对leg-by-leg机动的可观测性进行分析;然后,建立极坐标系下的目标运动状态模型,以粒子相对观测站的距离和法向速度均匀分布为准则,提出将极坐标系下的目标状态向量映射至直角坐标系的方法;最后,为改善滤波收敛性,提出根据粒子的空间分布特征自适应地调整过程噪声协方差矩阵。仿真结果表明,对于典型的水下目标跟踪场景,所提方法可使滤波收敛率增大约47.6%,距离估计误差减小约329 m,滤波收敛时间缩短约450 s。
-
关键词:
- 检测前跟踪 /
- 粒子滤波 /
- 方位-频率观测 /
- leg-by-leg机动 /
- 两级采样
Abstract: According to the low sampling efficiency of particle filter track before detecting in high dimension state space with bearing-frequency measurements of passive sonar, a two-hierarchy sampling method based on the observability of leg-by-leg maneuver is proposed. Firstly, the observability of leg-by-leg maneuver is analyzed. Secondly, the target motion model in polar coordinate system is build. Based on the uniform distribution of the distance and normal velocity of particles relative to the observation station, the method of mapping the target state vector in polar coordinate system to rectangular coordinate system is proposed. Finally, in order to improve the convergence of the filter, the covariance matrix of process noise is adaptively adjusted according to the spatial distribution of particle. Simulation results show that, compared with the traditional method, the proposed method can increase the filter convergence rate by about 47.6%, reduce the distance estimation error by about 329 m and reduce the convergence time by about 450 s. -
[1] HO K C and CHAN Y T. An asymptotically unbiased estimator for bearings-only and Doppler-bearing target motion analysis[J]. IEEE Transactions on Signal Processing, 2006, 54(3): 809–822. doi: 10.1109/TSP.2005.861776 [2] LEE M H, MOON J H, KIM I S, et al. Pre-processing faded measurements for bearing-and-frequency target motion analysis[J]. International Journal of Control, Automation, and Systems, 2008, 6(3): 424–433. [3] SALMOND D J and BIRCH H. A particle filter for track-before-detect[C]. 2001 American Control Conference, Arlington, USA, 2001: 3753–3760. [4] RUTTEN M G, GORDON N J, and MASKELL S. Efficient particle-based track-before-detect in Rayleigh noise[C]. The 7th International Conference on Information Fusion, Stockholm, Sweden, 2004. [5] BESKOS A, CRISAN D, and JASRA A. On the stability of sequential Monte Carlo methods in high dimensions[J]. The Annals of Applied Probability, 2014, 24(4): 1396–1445. [6] CHEN Z. Bayesian filtering: From Kalman filters to particle filters, and beyond[R]. Hamilton: McMaster University, 2003. [7] DAUM F and HUANG J. Curse of dimensionality and particle filters[C]. 2003 IEEE Aerospace Conference Proceedings, Big Sky, USA, 2003: 1979–1993. [8] SEPTIER F, PANG S K, CARMI A, et al. On MCMC-based particle methods for Bayesian filtering: Application to multitarget tracking[C]. The 3rd IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing, Aruba, Netherland Antilles, 2009: 1280–1287. [9] 梁新华, 潘泉, 杨峰, 等. 基于两级采样的粒子滤波检测前跟踪算法[J]. 系统工程与电子技术, 2011, 33(9): 1921–1926. doi: 10.3969/j.issn.1001-506X.2011.09.02LIANG Xinhua, PAN Quan, YANG Feng, et al. Particle filter track-before-detect algorithm based on tow-hierarchy sampling[J]. Systems Engineering and Electronics, 2011, 33(9): 1921–1926. doi: 10.3969/j.issn.1001-506X.2011.09.02 [10] 梁新华, 梁彦, 潘泉, 等. 一种基于局部搜索采样的粒子滤波检测前跟踪算法[J]. 控制与决策, 2012, 27(12): 1912–1916. doi: 10.13195/j.cd.2012.12.155.liangxh.019LIANG Xinhua, LIANG Yan, PAN Quan, et al. A particle filter track-before-detect algorithm based on local search sampling[J]. Control and Decision, 2012, 27(12): 1912–1916. doi: 10.13195/j.cd.2012.12.155.liangxh.019 [11] CASELLA G and ROBERT C P. Rao-Blackwellisation of sampling schemes[J]. Biometrika, 1996, 83(1): 81–94. doi: 10.1093/biomet/83.1.81 [12] LI W and JIA Y. Rao-Blackwellised unscented particle filtering for jump Markov non-linear systems: An ${H_\infty }$ approach[J]. IET Signal Processing, 2011, 5(2): 187–193. doi: 10.1049/iet-spr.2009.0306[13] AMOR N, CHEBBI S, and BOUAYNAYA N. A comparative study of particle filter, PMCMC and mixture particle filter methods for tracking in high dimensional state spaces[C]. The 3rd International Conference on Automation, Control, Engineering and Computer Science, 2016: 846–850. [14] BESKOS A, CRISAN D, JASRA A, et al. A stable particle filter for a class of high-dimensional state-space models[J]. Advances in Applied Probability, 2017, 49(1): 24–48. doi: 10.1017/apr.2016.77 [15] BUGALLO M F and DJURIĆ P M. Particle filtering in high-dimensional systems with Gaussian approximations[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 2014: 8013–8017. [16] FAWCETT J A. TMA Performance for Towed Arrays of Low Manoeuvrability[M]. CHAN Y T. Underwater Acoustic Data Processing. Dordrecht: Springer, 1989: 467–472. [17] LE CADRE J E and JAUFFRET C. Discrete-time observability and estimability analysis for bearings-only target motion analysis[J]. IEEE Transactions on Aerospace and Electronic Systems, 1997, 33(1): 178–201. doi: 10.1109/7.570737 [18] JAUFFRET C and PILLON D. Observability in passive target motion analysis[J]. IEEE Transactions on Aerospace and Electronic Systems, 1996, 32(4): 1290–1300. doi: 10.1109/7.543850 [19] RISTIC B and ARULAMPALAM M S. Tracking a manoeuvring target using angle-only measurements: Algorithms and performance[J]. Signal Processing, 2003, 83(6): 1223–1238. doi: 10.1016/S0165-1684(03)00042-2 [20] BECKER K. A general approach to TMA observability from angle and frequency measurements[J]. IEEE Transactions on Aerospace and Electronic Systems, 1996, 32(1): 487–494. doi: 10.1109/7.481293 [21] 夏佩伦, 李长文. 水下目标跟踪与攻击新理论[M]. 北京: 国防工业出版社, 2016: 86–91.XIA Peilun and LI Changwen. New Theory of Underwater Target Tracking and Attack[M]. Beijing: National Defense Industry Press, 2016: 86–91. [22] 杜选民, 周胜增, 高源. 声纳阵列信号处理技术[M]. 北京: 电子工业出版社, 2018: 165–166.DU Xuanmin, ZHOU Shengzeng, and GAO Yuan. Array Signal Processing Techniques for Sonar[M]. Beijing: Electronic Industry Press, 2018: 165–166. [23] 盛骤, 谢式千, 潘承毅. 概率论与数理统计[M]. 3版. 北京: 高等教育出版社, 2001. [24] AIDALA V J and HAMMEL S E. Utilization of modified polar coordinates for bearings-only tracking[J]. IEEE Transactions on Automatic Control, 1983, 28(3): 283–294. doi: 10.1109/TAC.1983.1103230 [25] ARULAMPALAM S and RISTIC B. Comparison of the particle filter with range-parameterized and modified polar EKFs for angle-only tracking[C]. SPIE 4048, Signal and Data Processing of Small Targets 2000, Orlando, United States, 2000: 288–299. doi: 10.1117/12.391985. -

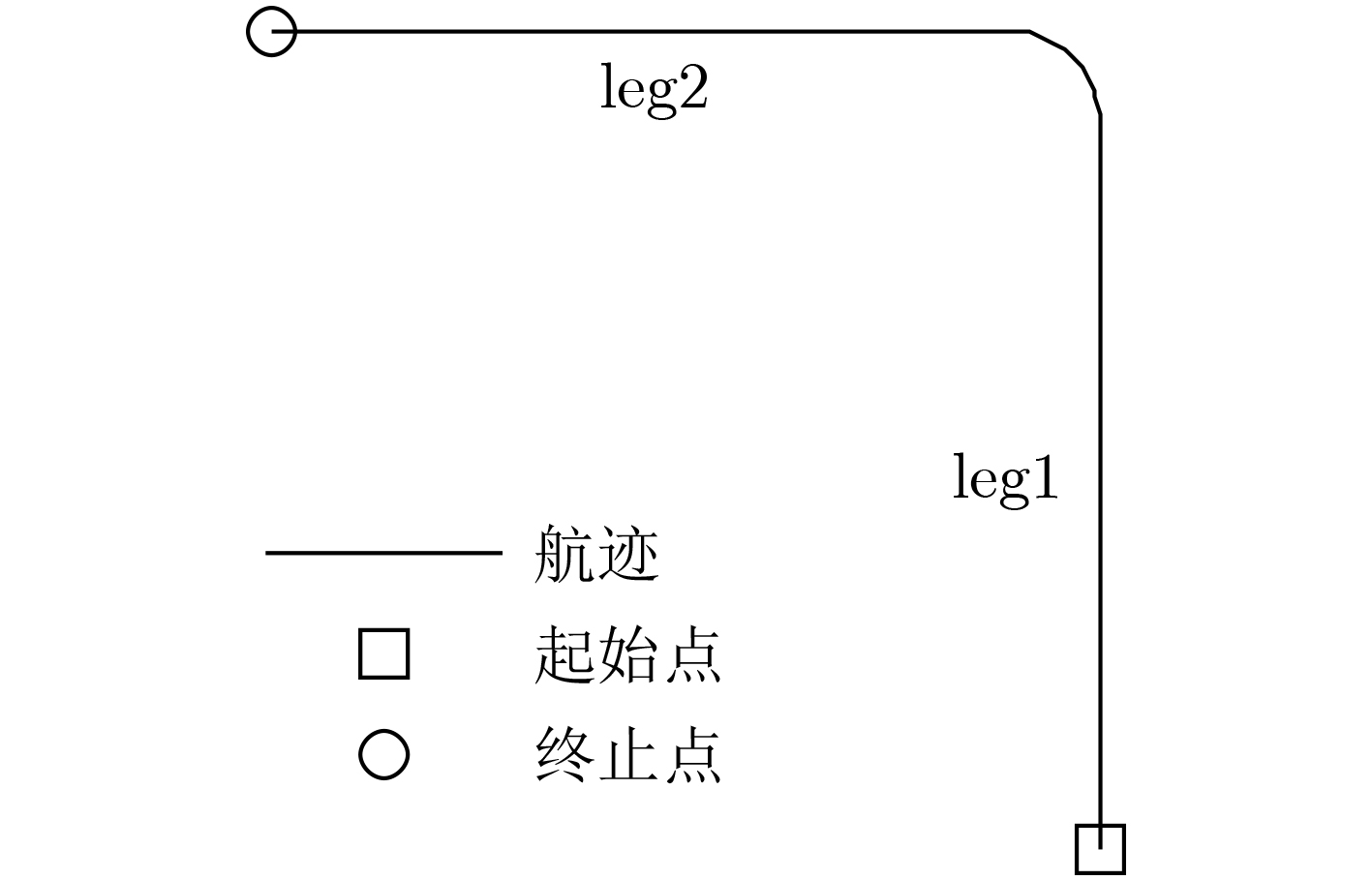
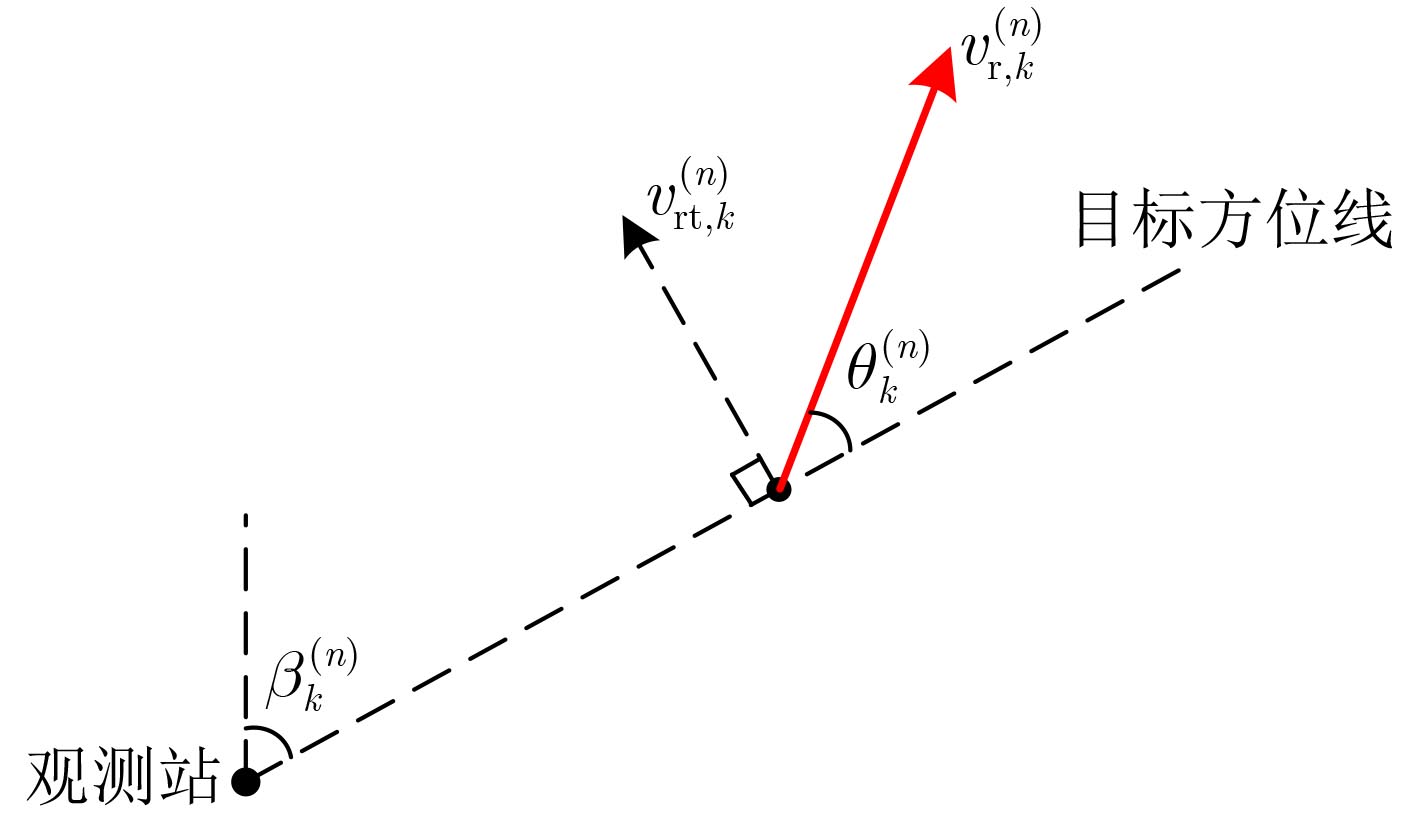
 下载:
下载:
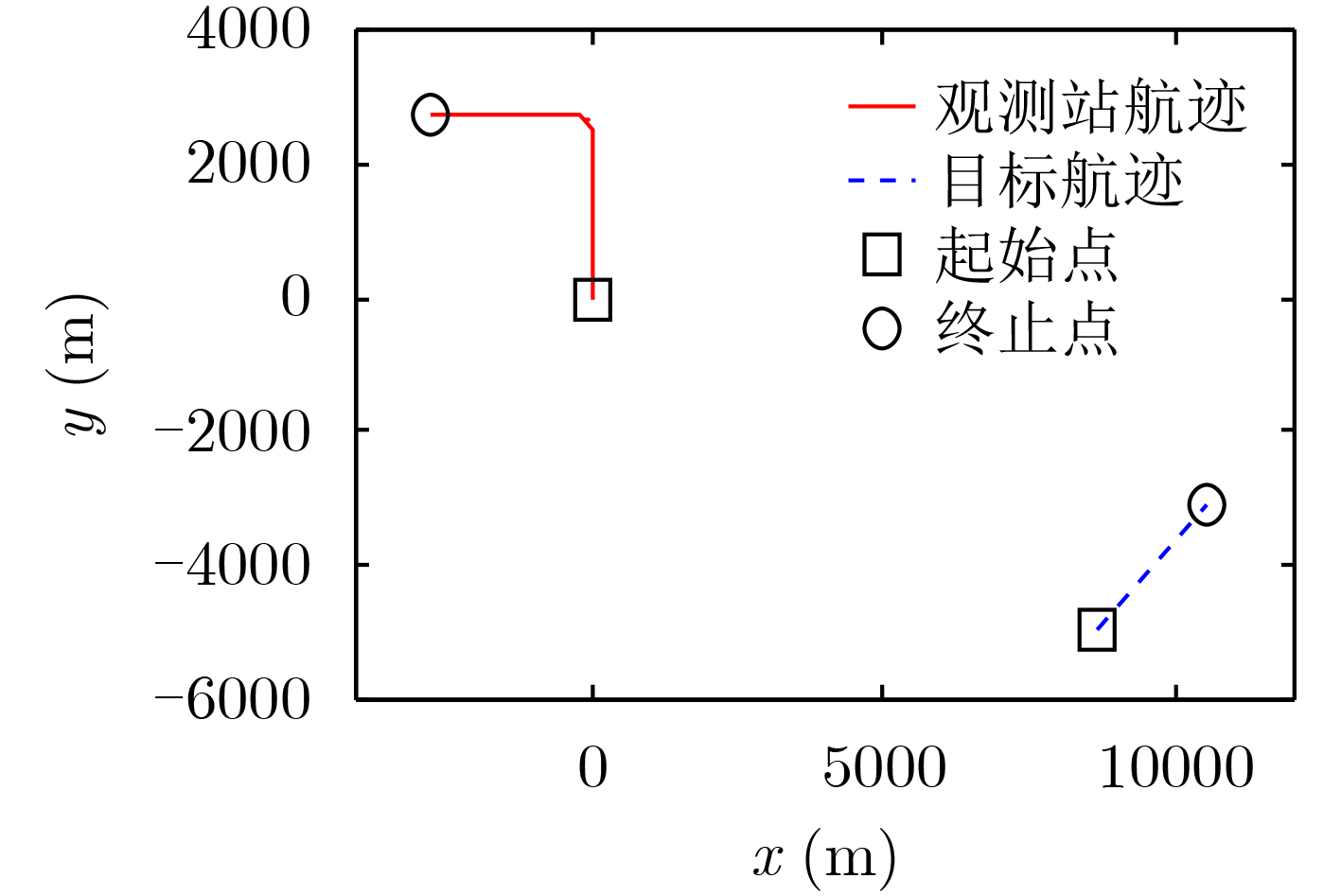




图(13)
计量
- 文章访问数: 747
- HTML全文浏览量: 664
- PDF下载量: 39
- 被引次数: 0
 下载:
下载:
