

A Multiscale Feature Extraction Method for Text-independent Speaker Recognition
-
摘要: 近些年来,多种基于卷积神经网络(CNNs)的模型结构表现出越来越强的多尺度特征表达能力,在说话人识别的各项任务中取得了持续的性能提升。然而,目前大多数方法只能利用更深更宽的网络结构来提升性能。该文引入一种更高效的多尺度说话人特征提取框架Res2Net,并对它的模块结构进行了改进。它以一种更细粒化的工作方式,获得多种感受野的组合,从而获得多种不同尺度组合的特征表达。实验表明,该方法在参数量几乎不变的情况下,等错误率(EER)相较ResNet有20%的下降,并且在VoxCeleb, SITW等多种不同录制环境和识别任务中都有稳定的性能提升,证明了该方法的高效性和鲁棒性。改进后的全连接模块结构能更充分利用训练信息,在数据充足和任务复杂时性能提升明显。具体代码可以在
https://github.com/czg0326/Res2Net-Speaker-Recognition 获得。Abstract: Recently in speaker recognition tasks, consistent performance gains have been continually achieved by various Convolutional Neural Networks (CNNs), which have shown increasingly stronger multiscale representation abilities. However, most existing methods enhance their strength with more layers and deeper structures. In this paper, a unique multiscale backbone architecture, Res2Net, is introduced for speaker recognition tasks, and its blocks are modified for assessment. This architecture works at a more granular level than most layer-wise networks. It improves the system by combining many equivalent receptive fields, resulting in a combination of different feature scales. The experiments results demonstrate that this architecture steadily achieves a 20% improvement on the Equal Error Rate (EER) over the baseline without additional computational burden. Its effectiveness and robustness are also verified in different environments and tasks, such as VoxCeleb and Speakers In The Wild (SITW). The modified full-connection block can make sure a more sufficient use of information and improves the performance obviously in more complex tasks. The code is available athttps://github.com/czg0326/Res2Net-Speaker-Recognition .-
Key words:
- Speaker recognition /
- Multiscale features /
- Robustness /
- Efficiency
-
表 1 VoxCeleb1测试集各系统性能表现(训练集:VoxCeleb1)
系统 等错误率EER(%) 最小检测代价函数minDCF P=0.1 P=0.01 P=0.001 x-vector 4.189 0.212 0.391 0.512 ResNet-50 3.955 0.212 0.404 0.483 Res2Net-50-sim 3.484 0.194 0.370 0.481 Res2Net-50-full 3.633 0.201 0.373 0.477  下载: 导出CSV
下载: 导出CSV
表 2 VoxCeleb1测试集各系统性能表现(训练集:VoxCeleb2)
系统 等错误率EER(%) 最小检测代价函数minDCF P=0.1 P=0.01 P=0.001 x-vector 2.985 0.179 0.336 0.465 ResNet-50 2.243 0.158 0.299 0.391 Res2Net-50-sim 1.729 0.143 0.271 0.405 Res2Net-50-full 1.403 0.136 0.259 0.364
下载: 导出CSV
表 4 SITW 4种测试条件下各系统性能表现
系统 训练集 SITW测试集EER(%) Core-core Core-multi Assist-core Assist-multi x-vector VoxCeleb1 6.698 8.661 8.476 9.920 ResNet-50 7.217 9.358 9.282 10.972 Res2Net-50-sim 6.483 8.520 8.306 9.740 Res2Net-50-full VoxCeleb2 6.603 8.575 8.297 9.516 Res2Net-50-sim 3.258 4.765 4.613 5.706 Res2Net-50-full 2.952 4.201 3.931 4.833
下载: 导出CSV
表 5 Res2Net-50调整width和scale在VoxCeleb性能表现
参数设置 等错误率EER(%) 最小检测代价函数minDCF P=0.1 P=0.01 P=0.001 7w4s 3.484 0.194 0.370 0.481 16w4s 3.446 0.186 0.357 0.491 7w8s 3.266 0.188 0.347 0.475
下载: 导出CSV
表 6 Res2Net-50调整width和scale在SITW性能表现
系统 SITW测试集EER(%) Core-core Core-multi Assist-core Assist-multi 7w4s 6.483 8.520 8.306 9.740 16w4s 6.370 8.382 8.601 9.411 7w8s 5.549 7.726 7.699 9.122
下载: 导出CSV
-
[1] 郭武, 戴礼荣, 王仁华. 采用因子分析和支持向量机的说话人确认系统[J]. 电子与信息学报, 2009, 31(2): 302–305. doi: 10.3724/SP.J.1146.2007.01289GUO Wu, DAI Lirong, and WANG Renhua. Speaker verification based on factor analysis and SVM[J]. Journal of Electronics &Information Technology, 2009, 31(2): 302–305. doi: 10.3724/SP.J.1146.2007.01289 [2] VARIANI E, LEI Xin, MCDERMOTT E, et al. Deep neural networks for small footprint text-dependent speaker verification[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 2014: 4052–4056. [3] SNYDER D, GARCIA-ROMERO D, POVEY D, et al. Deep neural network embeddings for text-independent speaker verification[C]. The Interspeech 2017, Stockholm, Sweden, 2017: 999–1003. [4] 王文超, 黎塔. 基于多时间尺度的深层说话人特征提取研究[J]. 网络新媒体技术, 2019, 8(5): 21–26.WANG Wenchao and LI Ta. Research on deep speaker embeddings extraction based on multiple temporal scales[J]. Journal of Network New Media, 2019, 8(5): 21–26. [5] NAGRANI A, CHUNG J S, and ZISSERMAN A. Voxceleb: A large-scale speaker identification dataset[EB/OL]. https://arxiv.org/abs/1706.08612, 2017. [6] HUANG Zili, WANG Shuai, and YU Kai. Angular softmax for short-duration text-independent speaker verification[C]. The Interspeech 2018, Hyderabad, India, 2018: 3623–3627. [7] YADAV S and RAI A. Learning discriminative features for speaker identification and verification[C]. The Interspeech 2018, Hyderabad, India, 2018: 2237–2241. [8] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [9] GAO Shanghua, CHENG Mingming, ZHAO Kai, et al. Res2net: A new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2): 652–662. [10] 柳长源, 王琪, 毕晓君. 基于多通道多尺度卷积神经网络的单幅图像去雨方法[J]. 电子与信息学报, 2020, 42(9): 2285–2292. doi: 10.11999/JEIT190755LIU Changyuan, WANG Qi, and BI Xiaojun. Research on rain removal method for single image based on multi-channel and multi-scale CNN[J]. Journal of Electronics &Information Technology, 2020, 42(9): 2285–2292. doi: 10.11999/JEIT190755 [11] CAI Weicheng, CHEN Jinkun, and LI Ming. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system[EB/OL]. https://arxiv.org/abs/1804.05160, 2018. [12] HEO H S, JUNG J W, YANG I H, et al. End-to-end losses based on speaker basis vectors and all-speaker hard negative mining for speaker verification[EB/OL]. https://arxiv.org/abs/1902.02455, 2019. [13] CHUNG J S, NAGRANI A, and ZISSERMAN A. Voxceleb2: Deep speaker recognition[EB/OL]. https://arxiv.org/abs/1806.05622, 2018. [14] ZAGORUYKO S and KOMODAKIS N. Wide residual networks[EB/OL]. https://arxiv.org/abs/1605.07146, 2016. [15] XIE Saining, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1492–1500. [16] MCLAREN M, FERRER L, CASTAN D, et al. The speakers in the wild (SITW) speaker recognition database[C]. The Interspeech 2016, San Francisco, USA, 2016: 818–822. [17] ZEINALI H, WANG Shuai, SILNOVA A, et al. BUT system description to VoxCeleb speaker recognition challenge 2019[EB/OL]. https://arxiv.org/abs/1910.12592, 2019. [18] OKABE K, KOSHINAKA T, and SHINODA K. Attentive statistics pooling for deep speaker embedding[EB/OL]. https://arxiv.org/abs/1803.10963, 2018. -

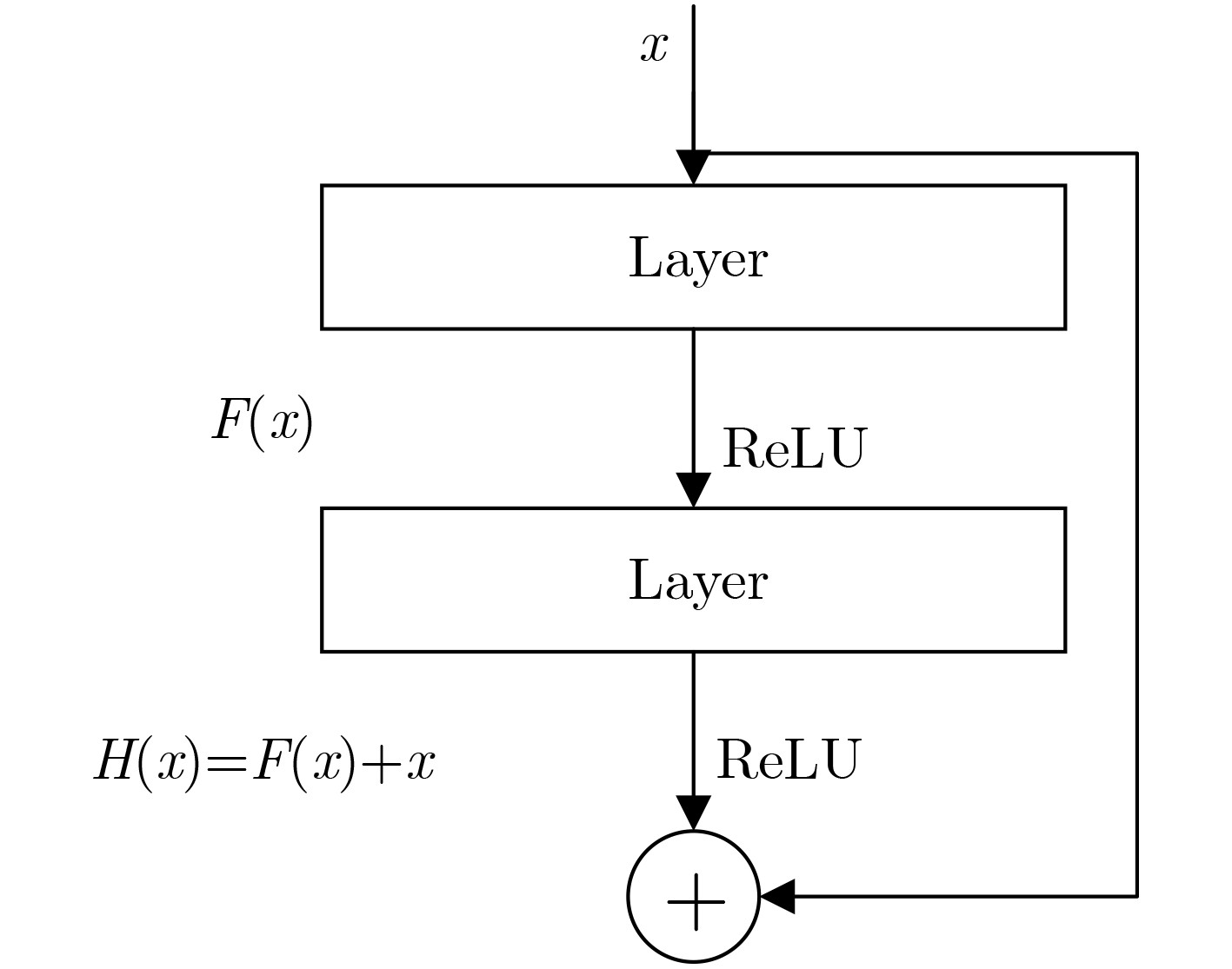
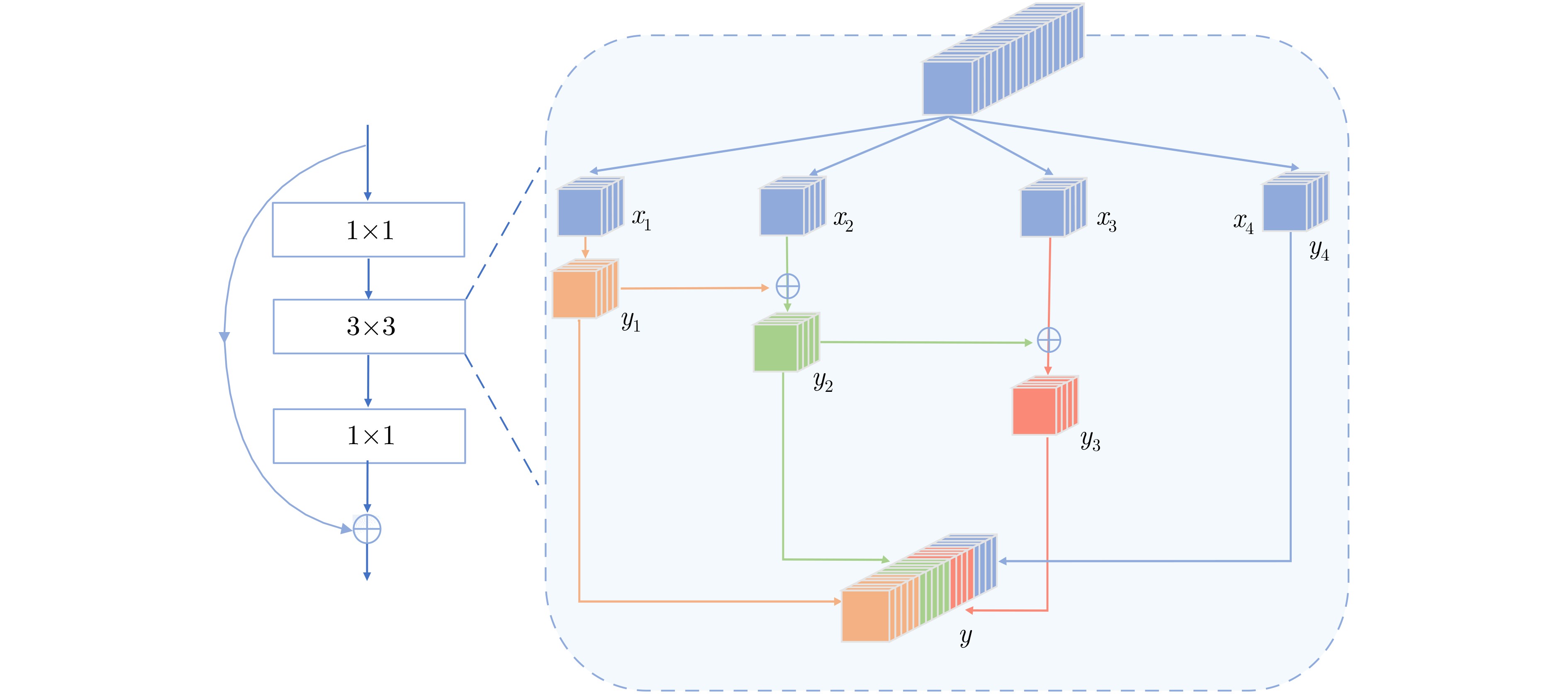
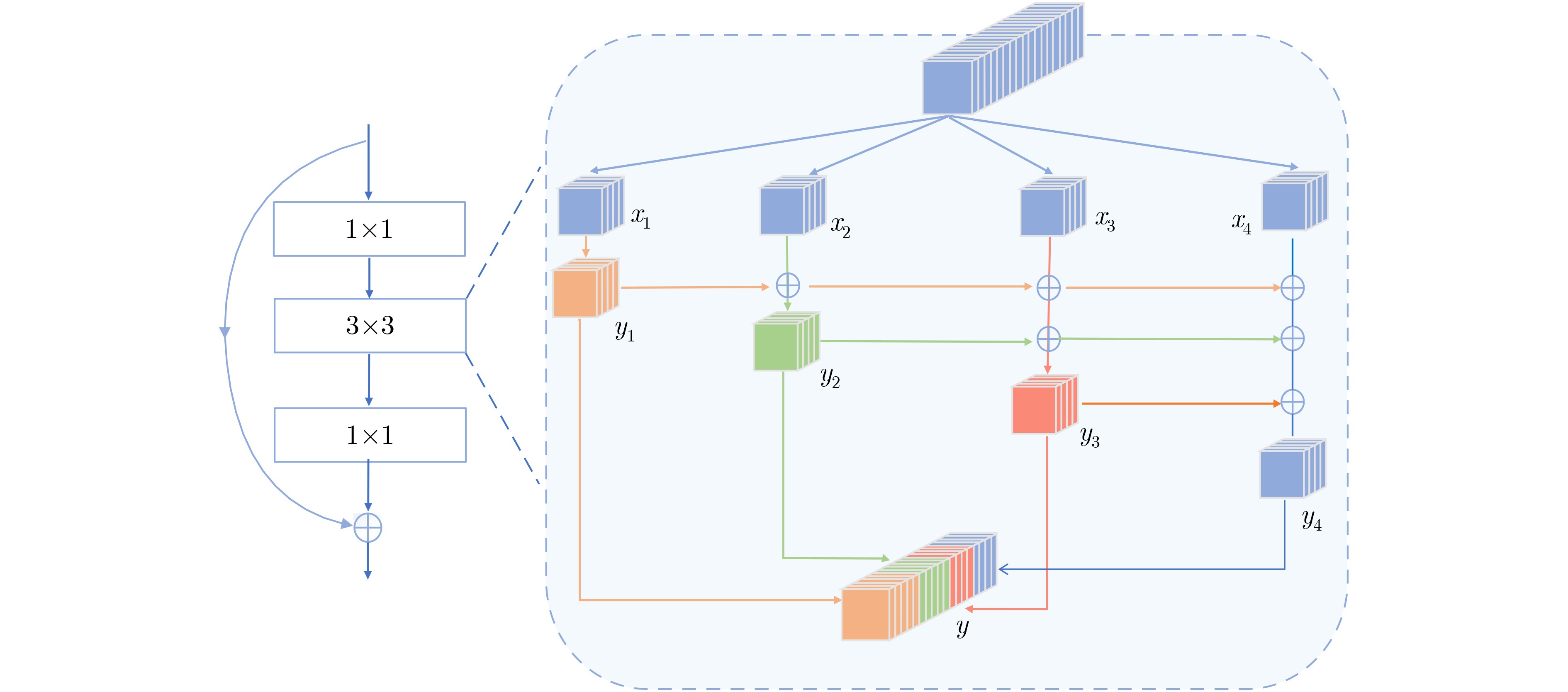


图(3) / 表(6)
计量
- 文章访问数: 1964
- HTML全文浏览量: 914
- PDF下载量: 126
- 被引次数: 0
 下载:
下载:
