

Bi-directional Feature Fusion for Fast and Accurate Text Detection of Arbitrary Shapes
-
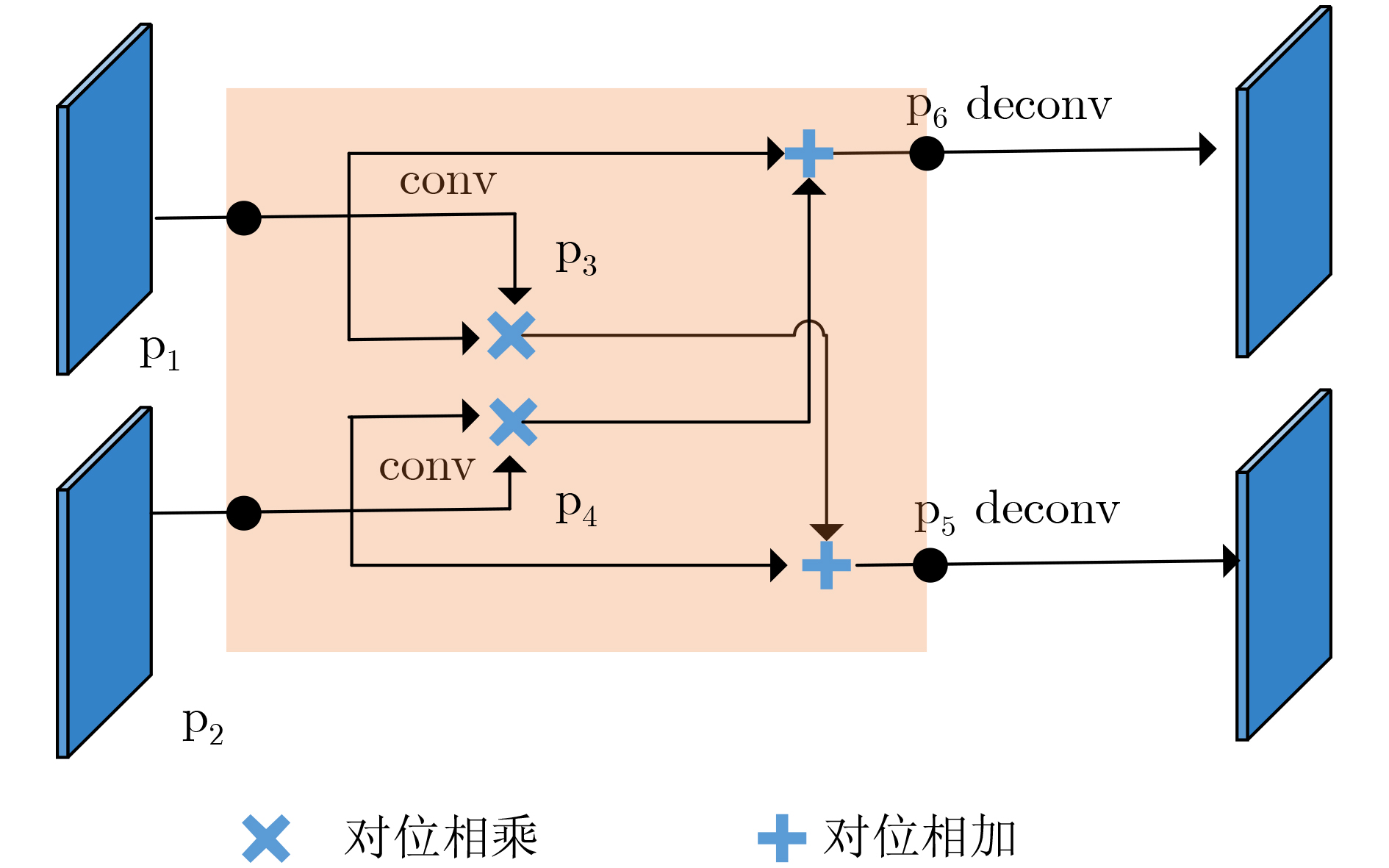
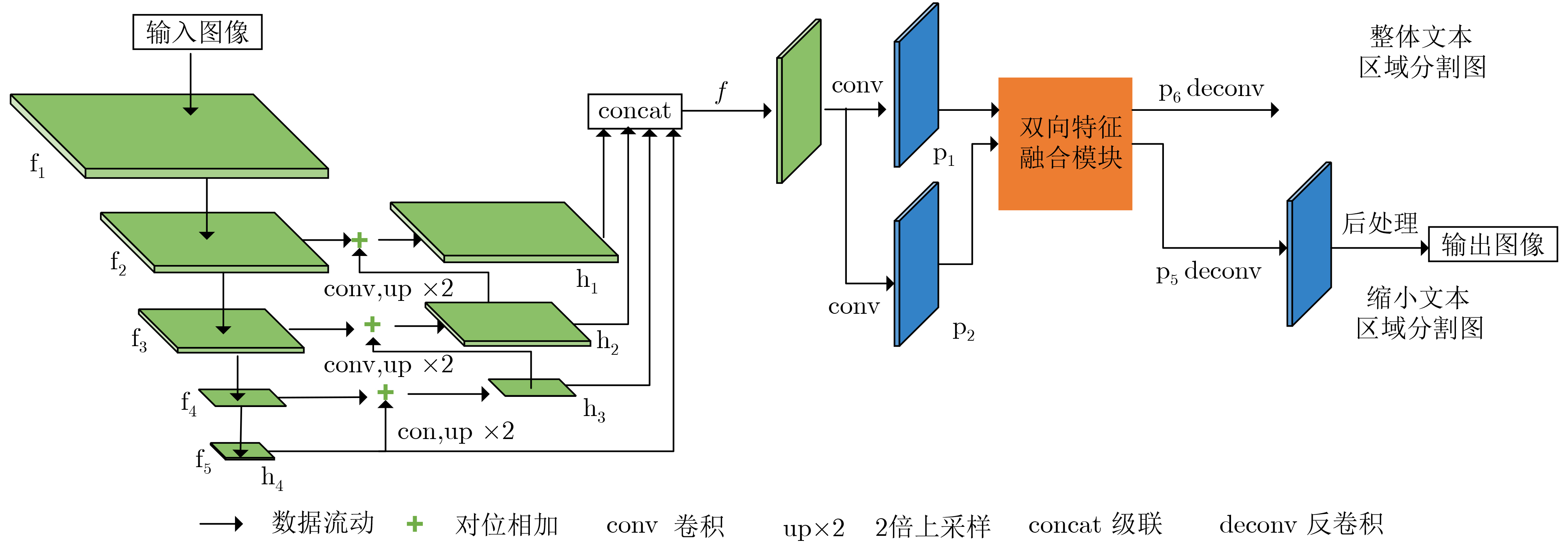
摘要: 现有的基于分割的场景文本检测方法仍较难区分相邻文本区域,同时网络得到分割图后后处理阶段步骤复杂导致模型检测效率较低。为了解决此问题,该文提出一种新颖的基于全卷积网络的场景文本检测模型。首先,该文构造特征提取器对输入图像提取多尺度特征图。其次,使用双向特征融合模块融合两个平行分支特征的语义信息并促进两个分支共同优化。之后,该文通过并行地预测缩小的文本区域图和完整的文本区域图来有效地区分相邻文本。其中前者可以保证不同的文本实例之间具有区分性,而后者能有效地指导网络优化。最后,为了提升文本检测的速度,该文提出一个快速且有效的后处理算法来生成文本边界框。实验结果表明:在相关数据集上,该文所提出的方法均实现了最好的效果,且比目前最好的方法在F-measure指标上最多提升了1.0%,并且可以实现将近实时的速度,充分证明了该方法的有效性和高效性。Abstract: Existing segmentation based methods have problems, such as the difficulty in distinguishing adjacent text areas and the low efficiency of model detection caused by the complex steps in the post-processing stage. In order to solve this problem, this article proposes a novel scene text detection model based on fully convolutional network, which can solve the problem that adjacent texts are difficult to distinguish in existing methods and improve the detection speed of the model. First, it constructs a feature extractor to extract multi-scale feature map from the input image. Secondly, the bidirectional feature fusion module is used to fuse the semantic information of the two parallel branches and promote the joint optimization of the two branches. It then effectively differentiates adjacent texts by predicting both a reduced text area map and a full text area map in parallel. The former can guarantee the distinction between different text instances, while the latter can effectively guide the network optimization. Finally, in order to improve the speed of text detection, it proposes a fast and effective post-processing algorithm to generate text boundary boxes. The experimental results show that: on relative datasets, the method proposed in this article achieves the best performance, and improves the F-measure index by 1.0% at most compared with the current best method, and can achieve near-real-time speed, which proves fully the effectiveness and high efficiency of the method.
-
表 1 双向特征融合模块及整体文本框分支在不同基础网络下的性能增益及检测效率
基础网络 双向特征
融合模块整体文本区
域预测分支评价指标(%) FPS 准确率 召回率 F综合指标 ResNet-50 × × 87.4 82.7 85.0 17.4 ResNet-50 × √ 87.8 83.1 85.4 16.8 ResNet-50 √ √ 88.0 83.5 85.7 16.0 ResNet-18 × × 86.6 79.8 83.1 31.0 ResNet-18 × √ 85.9 80.8 83.3 30.5 ResNet-18 √ √ 86.5 81.2 83.8 29.6  下载: 导出CSV
下载: 导出CSV
-
黄剑华, 承恒达, 吴锐, 等. 基于模糊同质性映射的文本检测方法[J]. 电子与信息学报, 2008, 30(6): 1376–1380.HUANG Jianhua, CHENG Hengda, WU Rui, et al. A new approach for text detection using fuzzy homogeneity[J]. Journal of Electronics &Information Technology, 2008, 30(6): 1376–1380. LONG Shangbang, RUAN Jiaqiang, ZHANG Wenjie, et al. Textsnake: A flexible representation for detecting text of arbitrary shapes[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 19–35. TIAN Zhuotao, SHU M, LYU P, et al. Learning shape-aware embedding for scene text detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 4229–4238. HUANG Weilin, QIAO Yu, and TANG Xiaoou. Robust scene text detection with convolution neural network induced MSER trees[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 497–511. JADERBERG M, VEDALDI A, and ZISSERMAN A. Deep features for text spotting[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 512–528. DENG Dan, LIU Haifeng, LI Xuelong, et al. Pixellink: Detecting scene text via instance segmentation[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 6773–6780. WANG Wenhai, XIE Enze, LI Xiang, et al. Shape robust text detection with progressive scale expansion network[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 9328–9337. XIE Enze, ZANG Yuhang, SHAO Shuai, et al. Scene text detection with supervised pyramid context network[C]. The 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 9038–9045. LIAO Minghui, WAN Zhaoyi, YAO Cong, et al. Real-time scene text detection with differentiable binarization[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11474–11481. doi: 10.1609/aaai.v34i07.6812 LIAO Minghui, SHI Baoguang, and BAI Xiang. Textboxes++: A single-shot oriented scene text detector[J]. IEEE Transactions on Image Processing, 2018, 27(8): 3676–3690. doi: 10.1109/TIP.2018.2825107 SHI Baoguang, BAI Xiang, and BELONGIE S. Detecting oriented text in natural images by linking segments[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3482–3490. ZHOU Xinyu, YAO Cong, WEN He, et al. EAST: An efficient and accurate scene text detector[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2642–2651. ZHANG Chengquan, LIANG Borong, HUANG Zuming, et al. Look more than once: An accurate detector for text of arbitrary shapes[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 10544–10553. DAI Jifeng, QI Haozhi, XIONG Yuwen, et al. Deformable convolutional networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 764–773. 谢金宝, 侯永进, 康守强, 等. 基于语义理解注意力神经网络的多元特征融合中文文本分类[J]. 电子与信息学报, 2018, 40(5): 1258–1265. doi: 10.11999/JEIT170815XIE Jinbao, HOU Yongjin, KANG Shouqiang, et al. Multi-feature fusion based on semantic understanding attention neural network for Chinese text categorization[J]. Journal of Electronics &Information Technology, 2018, 40(5): 1258–1265. doi: 10.11999/JEIT170815 GUPTA A, VEDALDI A, and ZISSERMAN A. Synthetic data for text localisation in natural images[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2315–2324. LIU Yuliang, JIN Lianwen, ZHANG Shuaitao, et al. Curved scene text detection via transverse and longitudinal sequence connection[J]. Pattern Recognition, 2019, 90: 337–345. CH’NG C K and CHAN C S. Total-text: A comprehensive dataset for scene text detection and recognition[C]. The 2017 14th IAPR International Conference on Document Analysis and Recognition, Kyoto, Japan, 2017: 935–942. YAO Cong, BAI Xiang, LIU Wenyu, et al. Detecting texts of arbitrary orientations in natural images[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 1083–1090. BAEK Y, LEE B, HAN D, et al. Character region awareness for text detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 9357–9366. XUE Chuhui, LU Shijian, ZHANG Wei. MSR: Multiscale shape regression for scene text detection[C]. KRAUS S. The 28th International Joint Conference on Artificial Intelligence, Macao, China, 2019: 989–995. XU Yongchao, WANG Yukang, ZHOU Wei, et al. Textfield: Learning a deep direction field for irregular scene text detection[J]. IEEE Transactions on Image Processing, 2019, 28(11): 5566–5579. MA Jianqi, SHAO Weiyuan, YE Hao, et al. Arbitraryoriented scene text detection via rotation proposals[J]. IEEE Transactions on Multimedia, 2018, 20(11): 3111–3122. LIU Zichuan, LIN Guosheng, YANG Sheng, et al. Learning markov clustering networks for scene text detection[C]. 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6936–6944. TIAN Zhi, HUANG Weilin, HE Tong, et al. Detecting text in natural image with connectionist text proposal network[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 56–72. -

 下载:
下载:







图(7) / 表(4)
计量
- 文章访问数: 1631
- HTML全文浏览量: 645
- PDF下载量: 99
- 被引次数: 0
