

Object Contour Partition Model with Consistent Properties
-
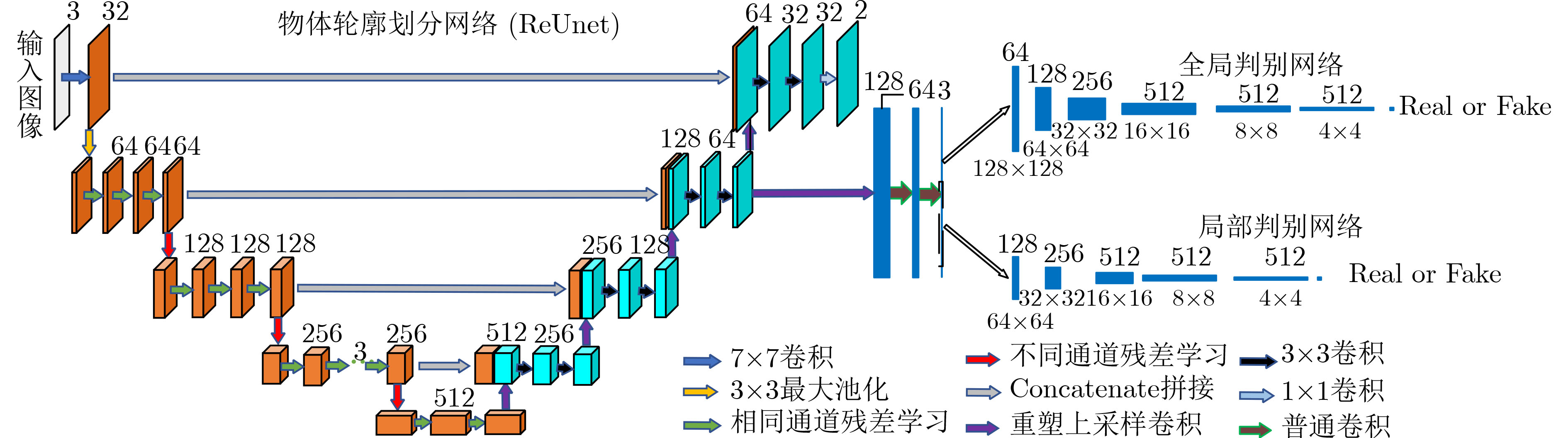
摘要: 该文提出一种基于全卷积深度残差网络、结合生成式对抗网络思想的基于属性一致的物体轮廓划分模型。采用物体轮廓划分网络作为生成器进行物体轮廓划分;该网络运用结构相似性作为区域划分的重构损失,从视觉系统的角度监督指导模型学习;使用全局和局部上下文判别网络作为双路判别器,对区域划分结果进行真伪判别的同时,结合对抗式损失提出一种联合损失用于监督模型的训练,使区域划分内容真实、自然且具有属性一致性。通过实例验证了该方法的实时性、有效性。Abstract: A new object contour partition model based on the fully convolutional network, combined with the idea of generative counter network and consistent attributes is proposed. Firstly, the image region partition network is used as a generator to divide the image region. Then the structural similarity is used as the reconstruction loss of regional division to supervise and guide model learning from the perspective of visual system. Finally, the global and local context discrimination networks are used as double-path similarity to supervise the reconstruction loss of regional division and guide model learning from the discriminators to distinguish the truth and falsity of the results of regional division, and a joint loss is proposed to train the supervision model in combination with the adversarial loss, so as to make the content of regional division true, natural and with attribute consistency. The instantaneity and effectiveness of the method are verified by living examples.
-
Key words:
- Region division /
- Rock granularity analyze /
- Dilated convolution /
- Skip connection /
- Adversarial loss
-
表 1 物体区域划分网络结构
类别层 卷积核 池化 残差 膨胀 重塑 步长 输出 conv1 7×7 max – – – 2 64×64×64 residual conv 3×3 – 4 – – 2 8×8×512 dilated conv 3×3 – – 3 – 2 8×8×512 reshape conv 1×1 – – – 4 1 256×256×256 conv2 3×3 2 256×256×256 conv3 1×1 – – – – 1 256×256×1  下载: 导出CSV
下载: 导出CSV
表 2 全局上下文判别网络结构
类别层 卷积核 步长 输出 conv 5×5 2×2 64 conv 5×5 2×2 128 conv 5×5 2×2 256 conv 5×5 2×2 512 conv 5×5 2×2 512 conv 5×5 2×2 512 FC – – 1024
下载: 导出CSV
表 3 局部上下文判别网络结构
类别层 卷积核 步长 输出 conv 5×5 2×2 128 conv 5×5 2×2 256 conv 5×5 2×2 512 conv 5×5 2×2 512 conv 5×5 2×2 512 FC – – 1024
下载: 导出CSV
-
[1] SHELHAMER E, LONG J, and DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640–651. doi: 10.1109/TPAMI.2016.2572683 [2] LIU Nian and HAN Junwei. DHSnet: Deep hierarchical saliency network for salient object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 678–686. doi: 10.1109/CVPR.2016.80. [3] LI Guanbin and YU Yizhou. Deep contrast learning for salient object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 478–487. doi: 10.1109/CVPR.2016.58. [4] XIE Saining and TU Zhuowen. Holistically-nested edge detection[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1395–1403. doi: 10.1109/ICCV.2015.164. [5] ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6230–6239. doi: 10.1109/cvpr.2017.660. [6] BADRINARAYANAN V, KENDALL A, and CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481–2495. doi: 10.1109/TPAMI.2016.2644615 [7] 余春艳, 徐小丹, 钟诗俊. 融合去卷积与跳跃嵌套结构的显著性区域检测[J]. 计算机辅助设计与图形学学报, 2018, 30(11): 2150–2158.YU Chunyan, XU Xiaodan, and ZHONG Shijun. Saliency region detection based on deconvolutional and skip nested module[J]. Journal of Computer-Aided Design &Computer Graphics, 2018, 30(11): 2150–2158. [8] 张冬明, 靳国庆, 代锋, 等. 基于深度融合的显著性目标检测算法[J]. 计算机学报, 2019, 42(9): 2076–2086. doi: 10.11897/SP.J.1016.2019.02076ZHANG Dongming, JIN Guoqing, DAI Feng, et al. Salient object detection based on deep fusion of hand-crafted features[J]. Chinese Journal of Computers, 2019, 42(9): 2076–2086. doi: 10.11897/SP.J.1016.2019.02076 [9] HOU Qibin, CHENG Mingming, HU Xiaowei, et al. Deeply supervised salient object detection with short connections[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 815–828. doi: 10.1109/TPAMI.2018.2815688 [10] 纪超, 黄新波, 曹雯, 等. 结合深度学习和全局-局部特征的图像显著区域计算[J]. 计算机辅助设计与图形学学报, 2019, 31(10): 1838–1846. doi: 10.3724/SP.J.1089.2019.17544JI Chao, HUANG Xinbo, CAO Wen, et al. Fusion of deep learning and global-local features of the image salient region calculation[J]. Journal of Computer-Aided Design &Computer Graphics, 2019, 31(10): 1838–1846. doi: 10.3724/SP.J.1089.2019.17544 [11] WU Huikai, ZHANG Junge, HUANG Kaiqi, et al. FastFCN: Rethinking dilated convolution in the backbone for semantic segmentation[J]. arXiv: 1903.11816, 2019. [12] 郭辉, 芮兰兰, 高志鹏. 车辆边缘网络中基于多参数MDP模型的动态服务迁移策略[J]. 通信学报, 2020, 41(1): 1–14. doi: 10.11959/j.issn.1000-436x.2020012GUO Hui, RUI Lanlan, and GAO Zhipeng. Dynamic service migration strategy based on MDP model with multiple parameter in vehicular edge network[J]. Journal on Communications, 2020, 41(1): 1–14. doi: 10.11959/j.issn.1000-436x.2020012 [13] 范九伦, 雷博. 倒数粗糙熵图像阈值化分割算法[J]. 电子与信息学报, 2020, 42(1): 214–221. doi: 10.11999/JEIT190559FAN Jiulun and LEI Bo. Image thresholding segmentation method based on reciprocal rough entropy[J]. Journal of Electronics &Information Technology, 2020, 42(1): 214–221. doi: 10.11999/JEIT190559 [14] 廖苗, 李阳, 赵于前, 等. 一种新的图像超像素分割方法[J]. 电子与信息学报, 2020, 42(2): 364–370. doi: 10.11999/JEIT190111LIAO Miao, LI Yang, ZHAO Yuqian, et al. A new method for image superpixel segmentation[J]. Journal of Electronics &Information Technology, 2020, 42(2): 364–370. doi: 10.11999/JEIT190111 [15] LI He, LI Gang, WANG Xuehu, et al. Edge detection of heterogeneity in transmission images based on frame accumulation and multiband information fusion[J]. Chemometrics and Intelligent Laboratory Systems, 2020, 204: 104117. doi: 10.1016/j.chemolab.2020.104117 [16] 刘健庄, 栗文青. 灰度图象的二维Otsu自动阈值分割法[J]. 自动化学报, 1993, 19(1): 101–105. doi: 10.16383/j.aas.1993.01.015LIU Jianzhuang and LI Wenqing. The automatic thresholding of gray-level pictures via two-dimensional Otsu method[J]. Acta Automatica Sinica, 1993, 19(1): 101–105. doi: 10.16383/j.aas.1993.01.015 -









图(7) / 表(5)
计量
- 文章访问数: 868
- HTML全文浏览量: 585
- PDF下载量: 30
- 被引次数: 0
 下载:
下载:
