

Joint Design of the Transmit and Receive Beamforming via Alternating Direction Method of Multipliers for LPI of Frequency Diverse Array MIMO Radar in the Presence of Clutter
-
摘要: 针对相控阵雷达无法有效实现特定区域能量控制的问题,该文提出一种杂波环境下基于交替方向乘子法(ADMM)的频控阵MIMO(FDA-MIMO)雷达低截获(LPI)优化设计方法。该方法的优化准则是在保证目标参数估计性能的条件下,通过联合设计发射波束和接收滤波器使FDA-MIMO雷达在目标2维(距离-方位)区域上辐射的能量尽量小,即尽可能地降低雷达被截获的概率;接着利用加权求和的方法将优化准则构造成多比例分式规划(FP)和的问题;然后利用循环迭代的方法,将优化问题转化成两个子优化问题;最后基于ADMM方法消除等式约束,并通过最小化2阶2次近似优化问题获得发射波束的闭合解。此外,也分析了该方法的计算复杂度。仿真部分通过输出信干燥比(SINR)、发射和接收方向图验证了该方法的有效性。Abstract: In view of the limitation of the phased-array on suppressing the range-dependent interference, a joint design of the transmit and receive beamforming via the Alternating Direction Method of Multipliers (ADMM) method for Low Probability of Intercept (LPI) of Multiple-Input Multiple-Output with Frequency Diverse Array (FDA-MIMO) radar in the presence of clutter is proposed. The problem of joint design is to maximize the performance of target parameter estimation, and minimize the transmit energy at the target region which enhances LPI capability. Following a weighted sum of the performance metric, the original problem is firstly recasts to a multiple-ratio Fractional Programming (FP) problem. Subsequently, an iterative algorithm is developed. Concretely, at each iteration, the transmit beamforming matrix is optimized by employing ADMM method and the quadratic approximation algorithm. Moreover, the computational complexity of the proposed algorithm is discussed. Numerical simulations are provided to demonstrate the effectiveness of the proposed algorithm.
-
[1] LAWRENCE D E. Low probability of intercept antenna array beamforming[J]. IEEE Transactions on Antennas and Propagation, 2010, 58(9): 2858–2865. doi: 10.1109/TAP.2010.2052573 [2] FISHLER E, HAIMOVICH A, BLUM R S, et al. Spatial diversity in radars-models and detection performance[J]. IEEE Transactions on Signal Processing, 2006, 54(3): 823–838. doi: 10.1109/TSP.2005.862813 [3] LI Jian and STOICA P. MIMO radar with colocated antennas[J]. IEEE Signal Processing Magazine, 2007, 24(5): 106–114. doi: 10.1109/MSP.2007.904812 [4] GONG Pengcheng, WANG Wenqin, and WAN Xianrong. Adaptive weight matrix design and parameter estimation via sparse modeling for MIMO radar[J]. Signal Processing, 2017, 139: 1–11. doi: 10.1016/j.sigpro.2017.03.028 [5] 廖雯雯, 程婷, 何子述. MIMO雷达射频隐身性能优化的目标跟踪算法[J]. 航空学报, 2014, 35(4): 1134–1141. doi: 10.7527/S1000-6893.2013.0368LIAO Wenwen, CHENG Ting, and HE Zishu. A target tracking algorithm for RF stealth performance optimization of MIMO radar[J]. Acta Aeronautica et Astronautica Sinica, 2014, 35(4): 1134–1141. doi: 10.7527/S1000-6893.2013.0368 [6] 杨少委, 程婷, 何子述. MIMO雷达搜索模式下的射频隐身算法[J]. 电子与信息学报, 2014, 36(5): 1017–1022. doi: 10.3724/SP.J.1146.2013.00994YANG Shaowei, CHENG Ting, and HE Zishu. Algorithm of radio frequency stealth for MIMO radar in searching mode[J]. Journal of Electronics &Information Technology, 2014, 36(5): 1017–1022. doi: 10.3724/SP.J.1146.2013.00994 [7] 赵宜楠, 亓玉佩, 赵占锋, 等. 分布式MIMO雷达的低截获特性分析[J]. 哈尔滨工业大学学报, 2014, 46(1): 59–63. doi: 10.11918/j.issn.0367-6234.2014.01.011ZHAO Yi’nan, QI Yupei, ZHAO Zhanfeng, et al. Analysis of LPI performance for distributed MIMO radar systems[J]. Journal of Harbin Institute of Technology, 2014, 46(1): 59–63. doi: 10.11918/j.issn.0367-6234.2014.01.011 [8] SHI Chenguang, WANG Fei, SELLATHURAI M, et al. Low probability of intercept-based distributed MIMO radar waveform design against barrage jamming in signal-dependent clutter and coloured noise[J]. IET Signal Processing, 2019, 13(4): 415–423. doi: 10.1049/iet-spr.2018.5212 [9] ANTONIK P, WICKS M C, GRIFFITHS H D, et al. Frequency diverse array radars[C]. The 2006 IEEE Conference on Radar, Verona, USA, 2006: 215–217. doi: 10.1109/RADAR.2006.1631800. [10] WANG Wenqin. Frequency diverse array antenna: New opportunities[J]. IEEE Antennas and Propagation Magazine, 2015, 57(2): 145–152. doi: 10.1109/MAP.2015.2414692 [11] 巩朋成, 刘刚, 黄禾, 等. 频控阵MIMO雷达中基于稀疏迭代的多维信息联合估计方法[J]. 雷达学报, 2018, 7(2): 194–201. doi: 10.12000/JR16121GONG Pengcheng, LIU Gang, HUANG He, et al. Multidimensional parameter estimation method based on sparse iteration in FDA-MIMO radar[J]. Journal of Radars, 2018, 7(2): 194–201. doi: 10.12000/JR16121 [12] XU Jingwei, LIAO Guisheng, ZHANG Yuhong, et al. An adaptive range-angle-doppler processing approach for FDA-MIMO radar using three-dimensional localization[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(2): 309–320. doi: 10.1109/JSTSP.2016.2615269 [13] GONG Pengcheng, WANG Wenqin, LI Fengcong, et al. Sparsity-aware transmit beamspace design for FDA-MIMO radar[J]. Signal Processing, 2018, 144: 99–103. doi: 10.1016/j.sigpro.2017.10.008 [14] BOYD S, PARIKH N, CHU E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations and Trends® in Machine Learning, 2011, 3(1): 1–122. doi: 10.1561/2200000016 [15] SHEN Kaiming and YU Wei. Fractional programming for communication systems-part I: Power control and beamforming[J]. IEEE Transactions on Signal Processing, 2018, 66(10): 2616–2630. doi: 10.1109/TSP.2018.2812733 [16] SOLTANALIAN M, HU Heng, and STOICA P. Single-stage transmit beamforming design for MIMO radar[J]. Signal Processing, 2014, 102: 132–138. doi: 10.1016/j.sigpro.2014.03.013 [17] HORN R A and JOHNSON C R. Matrix Analysis[M]. Cambridge: Cambridge University Press, 1990: 30–39. [18] CHENG Ziyang, HAN Chunlin, LIAO Bin, et al. Communication-aware waveform design for MIMO radar with good transmit beampattern[J]. IEEE Transactions on Signal Processing, 2018, 66(21): 5549–5562. doi: 10.1109/TSP.2018.2868042 -

 下载:
下载:
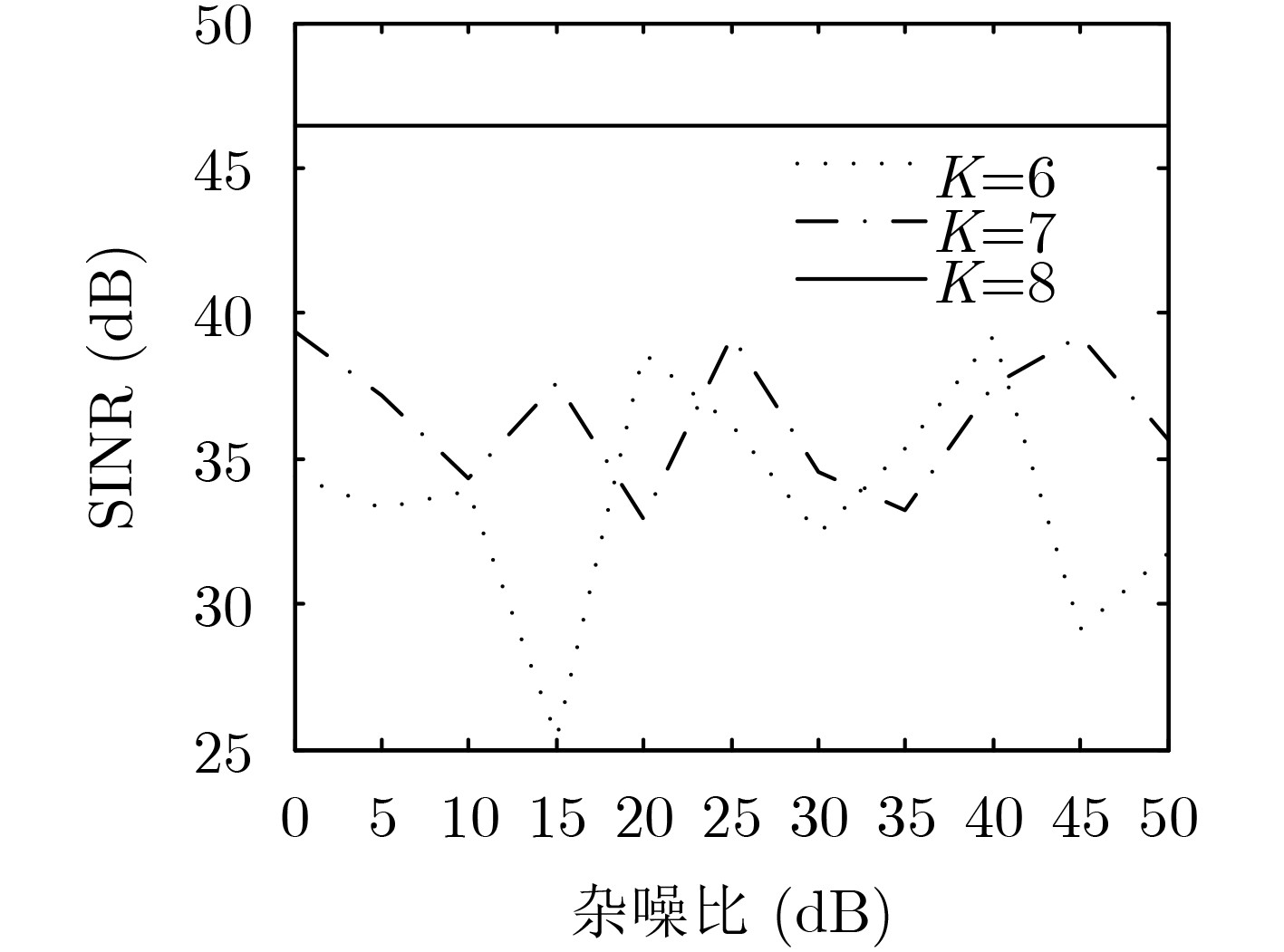
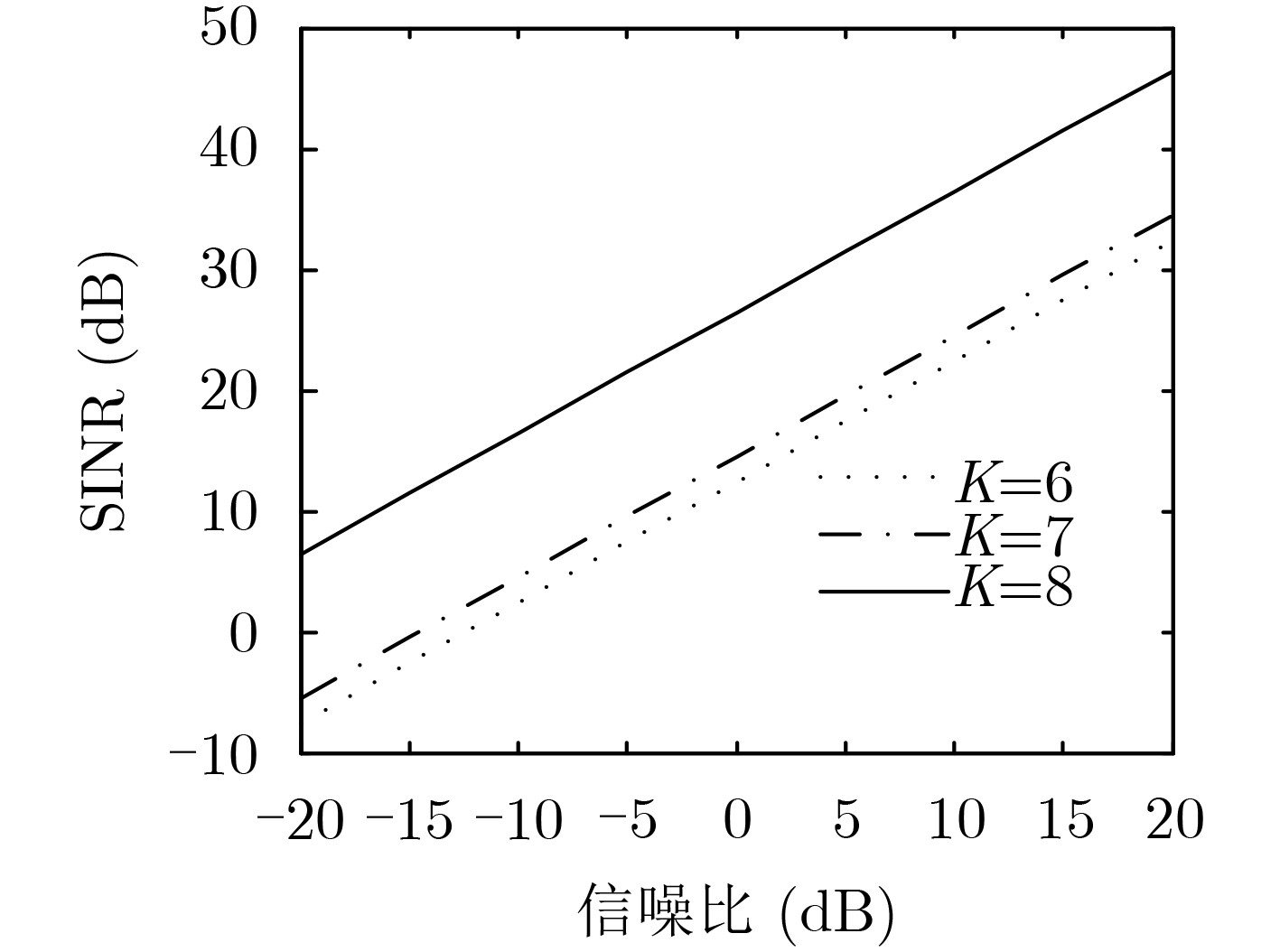
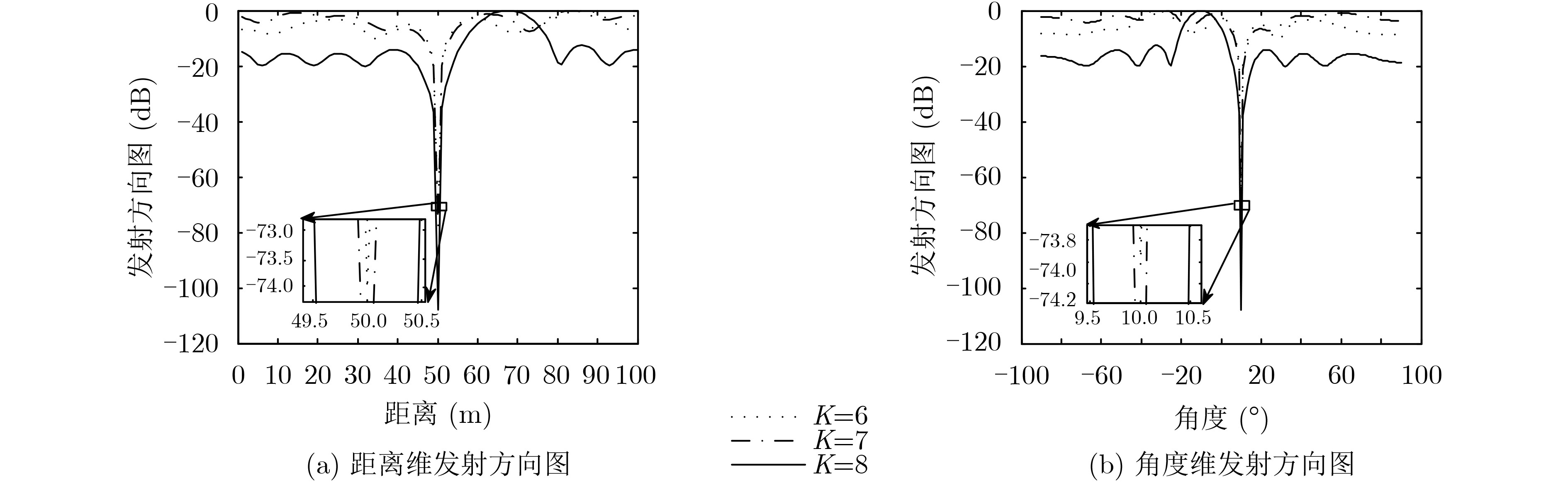
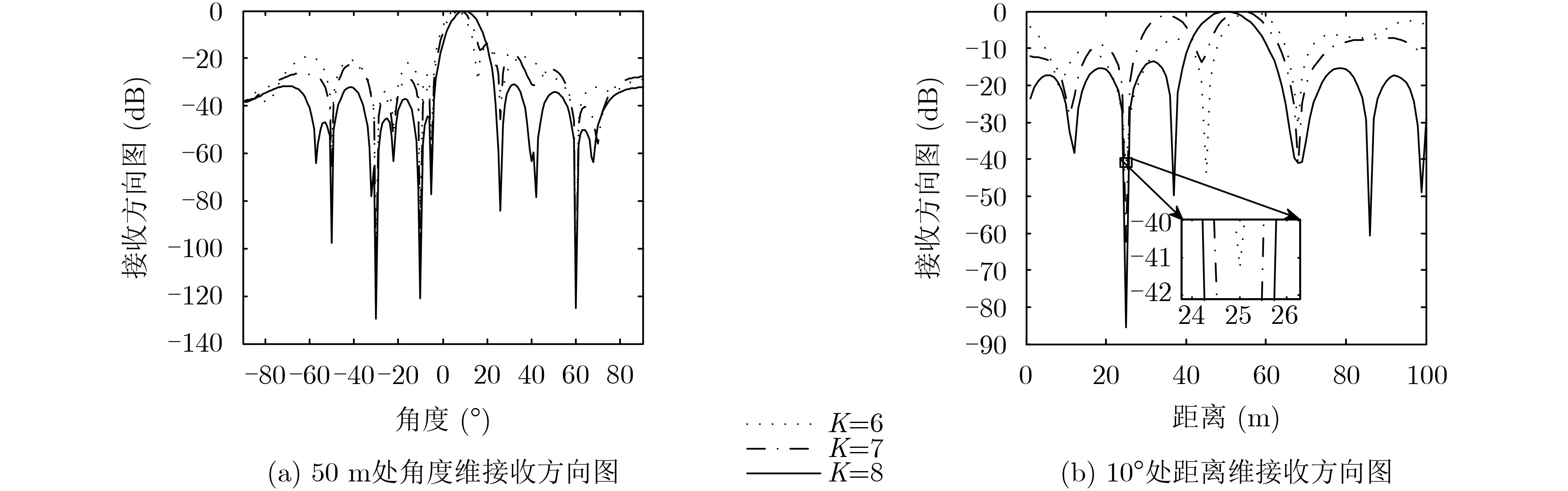
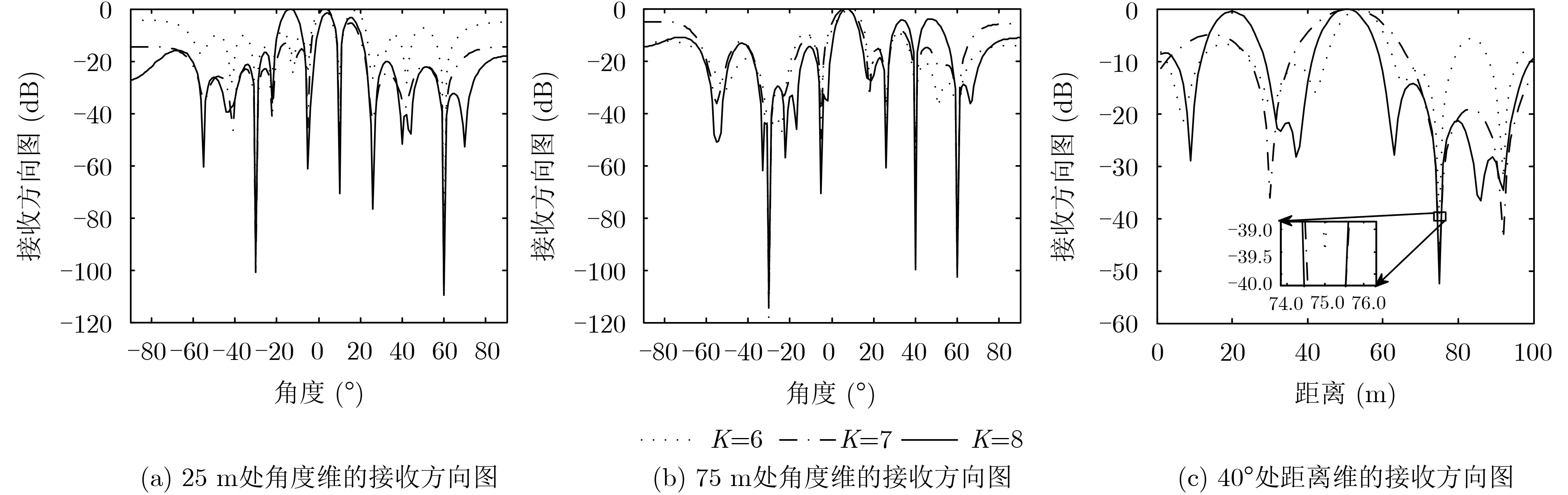


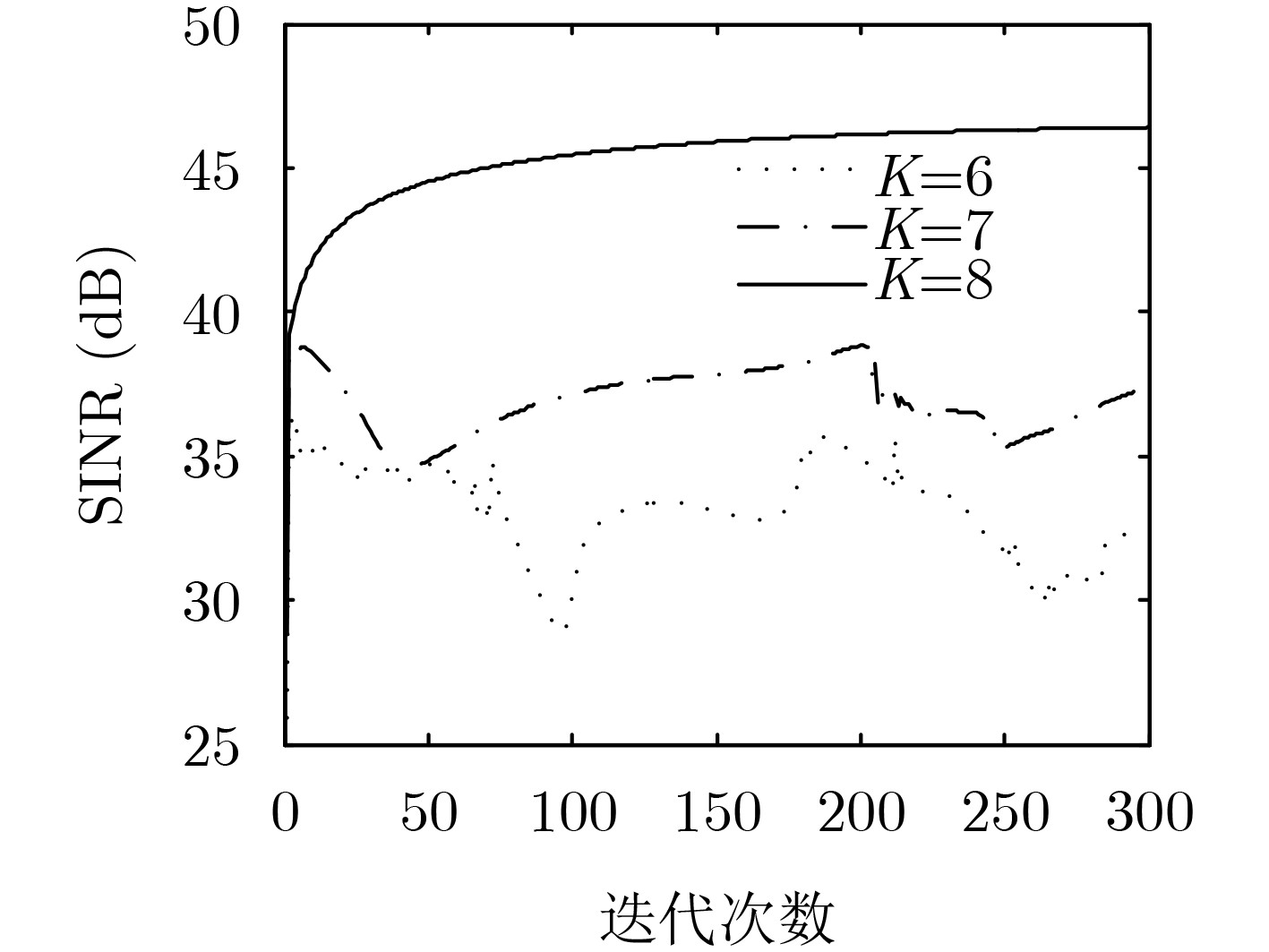
图(6)
计量
- 文章访问数: 2170
- HTML全文浏览量: 619
- PDF下载量: 127
- 被引次数: 0
