

Low-complexity Joint Channel Estimation and Decoding for LDPC Codes Via Sliding-Window Belief-Propagation over Non-stationary Channels
-
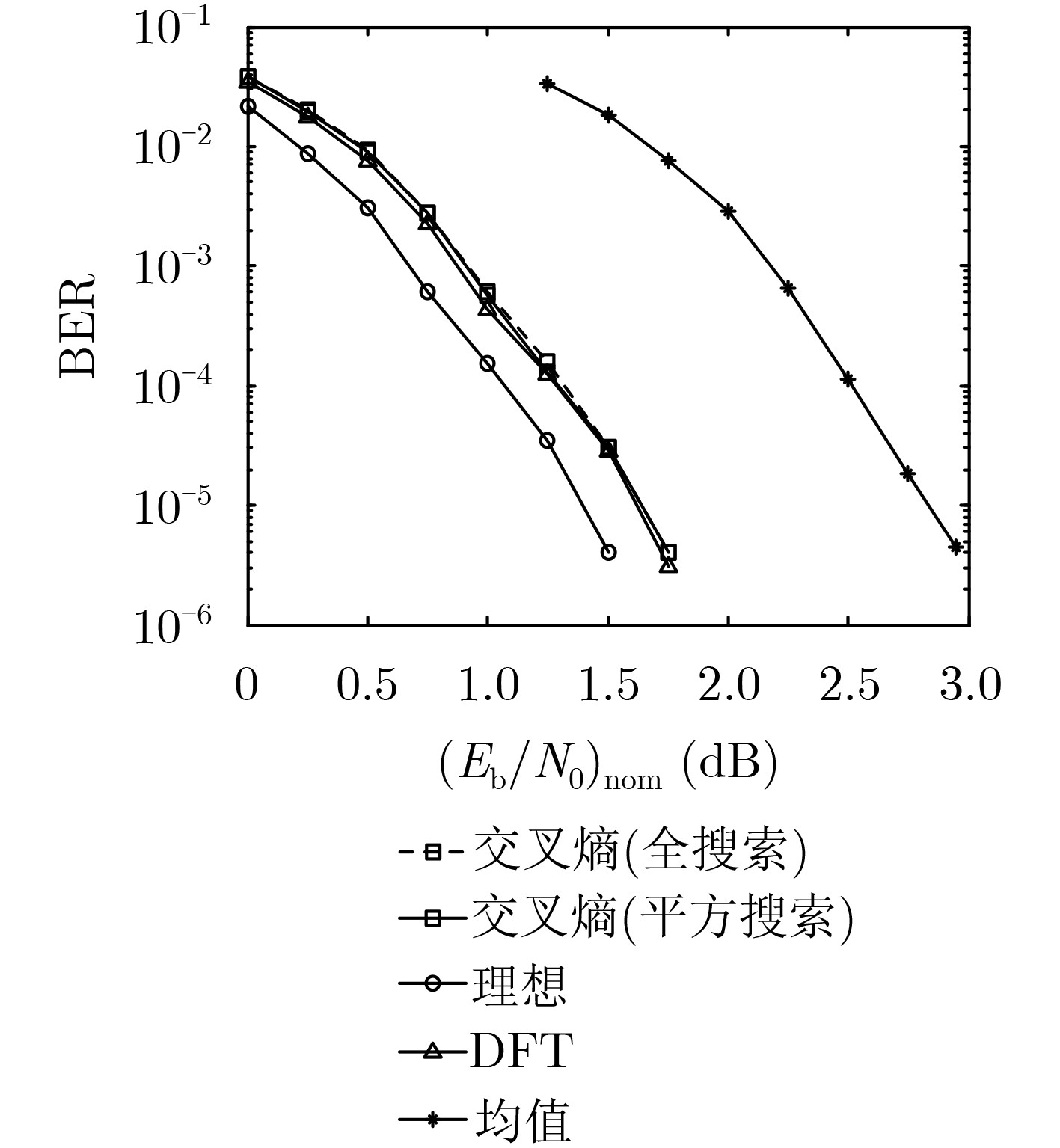
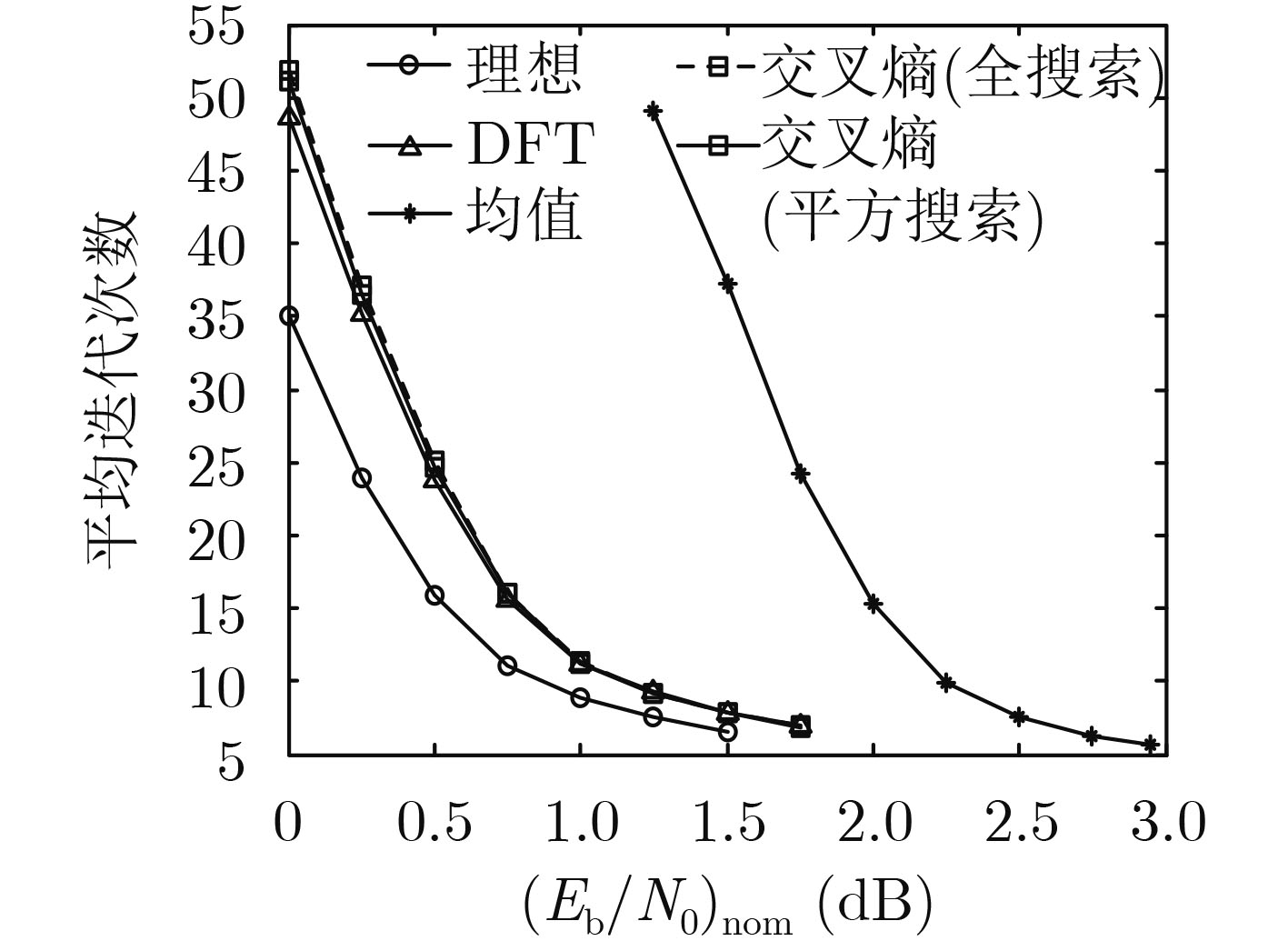
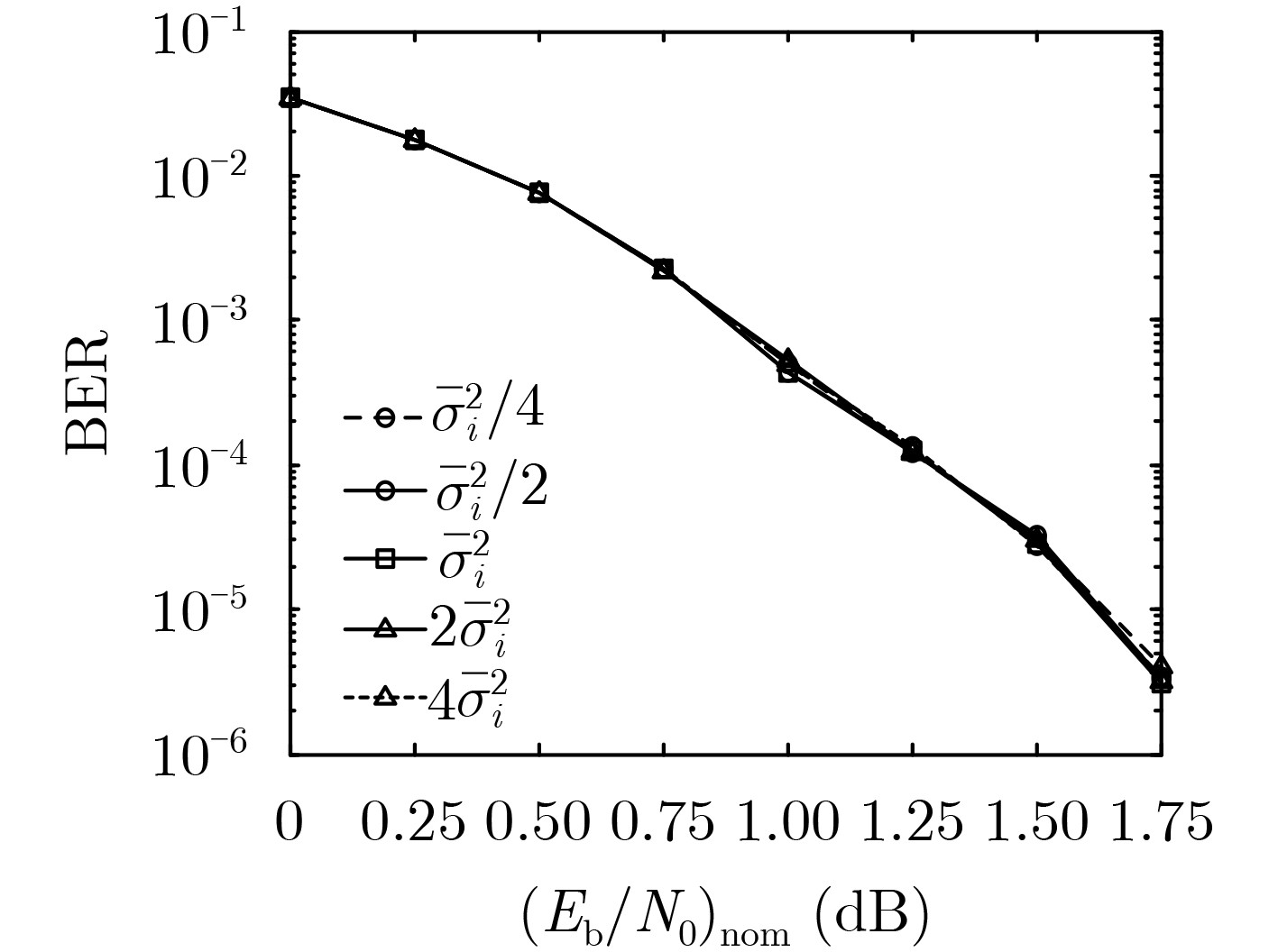
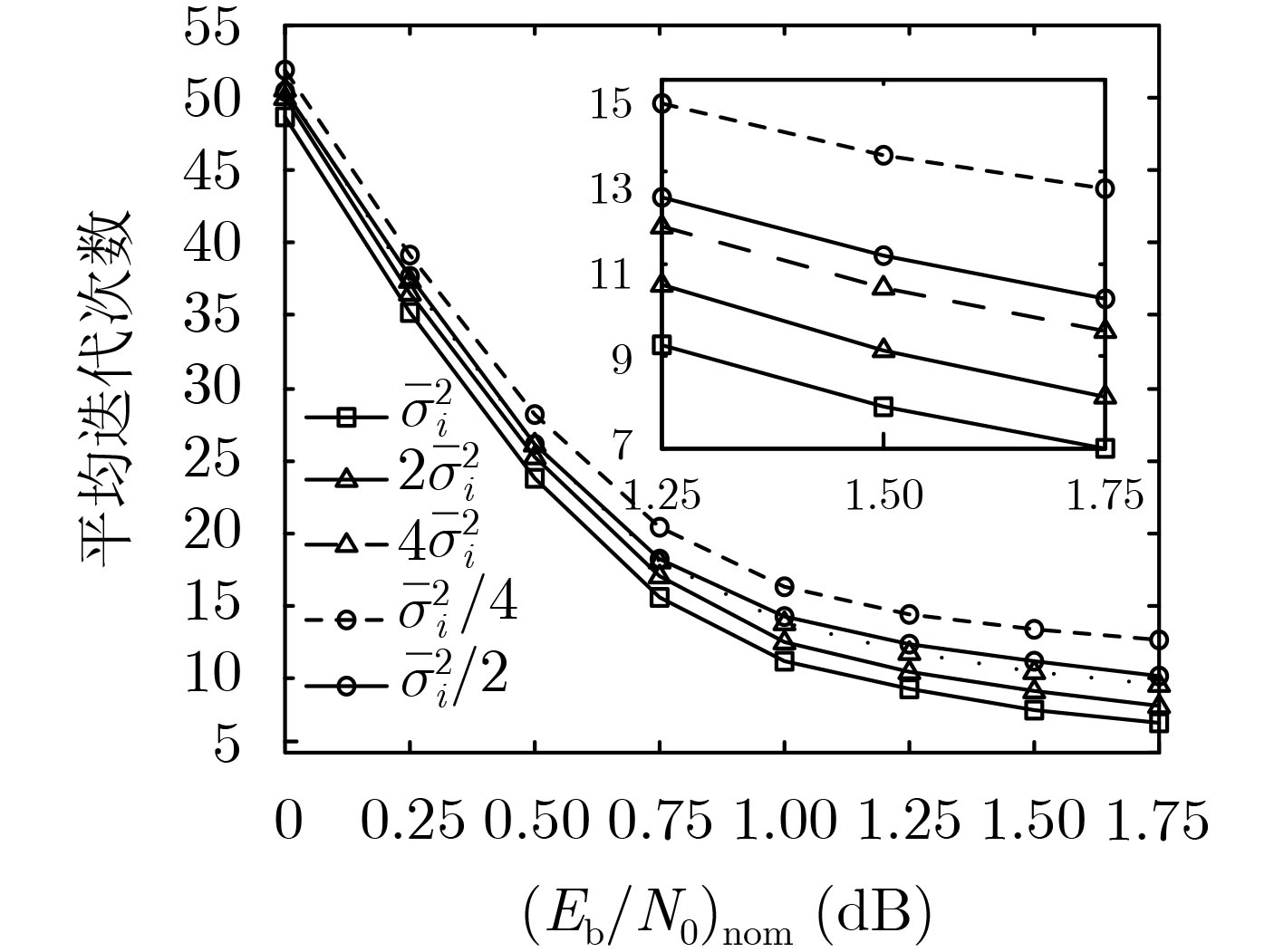
摘要: 随着移动通信应用场景的持续增多,非平稳信道成为越来越常见的传输环境,而非平稳信道下的可靠传输依赖于准确的信道估计。基于信源编码中用于信源参数估计和信源相关性估计的滑窗置信传播(SWBP)算法,该文提出一种非平稳信道下LDPC码的联合信道估计与译码(JCED)算法;同时,分别基于交叉熵和离散傅里叶变换提出两种在每轮JCED迭代中自适应设置滑窗长度的快速算法。仿真结果表明,在无导频辅助的前提下,所提算法具有接近理想信道估计下置信传播译码的性能以及高效率、低复杂度、强鲁棒性和不导致错误平层等优点。Abstract: With the continuous increase of possible usage scenarios of mobile networks, non-stationary channels become more and more common transmission environments, and reliable transmission over non-stationary channels relies on accurate channel estimation. Based on the Sliding-Window Belief-Propagation (SWBP) algorithm used to cope with source parameter estimation and source correlation estimation, a Joint Channel Estimation and Decoding (JCED) algorithm for LDPC codes over non-stationary channels is proposed. Two fast algorithms to set adaptively the window size in each JCED iteration are also proposed based on cross entropy and Discrete Fourier Transform (DFT), respectively. Simulation results reveal that, without the aid of pilots, the performance of the proposed algorithm approaches that of Belief-Propagation (BP) decoding under ideal channel estimation, and has the advantages of high efficiency, low complexity, strong robustness and not incurring error-floor.
-
RICHARDSON T and KUDEKAR S. Design of low-density parity check codes for 5G new radio[J]. IEEE Communications Magazine, 2018, 56(3): 28–34. doi: 10.1109/MCOM.2018.1700839 SAEEDI H and BANIHASHEMI A H. Performance of belief propagation for decoding LDPC codes in the presence of channel estimation error[J]. IEEE Transactions on Communications, 2007, 55(1): 83–89. doi: 10.1109/TCOMM.2006.887488 刘建航, 何怡静, 李世宝, 等. 基于预译码的极化码最大似然简化连续消除译码算法[J]. 电子与信息学报, 2019, 41(4): 959–966. doi: 10.11999/JEIT180324LIU Jianhang, HE Yijing, LI Shibao, et al. Pre-decoding based maximum-likelihood simplified successive-cancellation decoding of polar codes[J]. Journal of Electronics &Information Technology, 2019, 41(4): 959–966. doi: 10.11999/JEIT180324 王琼, 罗亚洁, 李思舫. 基于分段循环冗余校验的极化码自适应连续取消列表译码算法[J]. 电子与信息学报, 2019, 41(7): 1572–1578. doi: 10.11999/JEIT180716WANG Qiong, LUO Yajie, and LI Sifang. Polar adaptive successive cancellation list decoding based on segmentation cyclic redundancy check[J]. Journal of Electronics &Information Technology, 2019, 41(7): 1572–1578. doi: 10.11999/JEIT180716 LI Liping, XU Zuzheng, and HU Yanjun. Channel estimation with systematic polar codes[J]. IEEE Transactions on Vehicular Technology, 2018, 67(6): 4880–4889. doi: 10.1109/TVT.2018.2806364 JIAO Jian, LIANG Kexin, FENG Bowen, et al. Joint channel estimation and decoding for polar coded SCMA system over fading channels[J]. IEEE Transactions on Cognitive Communications and Networking, 2020. doi: 10.1109/TCCN.2020.2991425 HOU Yi, LIU Rongke, DAI Bin, et al. Joint channel estimation and LDPC decoding over time-varying impulsive noise channels[J]. IEEE Transactions on Communications, 2018, 66(6): 2376–2383. doi: 10.1109/TCOMM.2018.2800748 WANG Shuang, CUI Lijuan, CHENG S, et al. Noise adaptive LDPC decoding using particle filtering[J]. IEEE Transactions on Communications, 2011, 59(4): 913–916. doi: 10.1109/TCOMM.2011.011811.090309 ZHANG Zhengyu, LOU Jinming, JIN Mengdi, et al. Application of maximum entropy theorem in channel estimation[J]. Chinese Journal of Electronics, 2020, 29(2): 361–370. doi: 10.1049/cje.2020.01.015 ÖSTMAN J, DURISI G, STRÖM G, et al. Short packets over block-memoryless fading channels: Pilot-assisted or noncoherent transmission?[J]. IEEE Transactions on Communications, 2019, 67(2): 1521–1536. doi: 10.1109/TCOMM.2018.2874993 COŞKUN M C, LIVA G, OESTMAN J, et al. Low-complexity joint channel estimation and list decoding of short codes[C]. The 12th International ITG Conference on Systems, Communications and Coding, Rostock, Germany, 2019: 1–5. doi: 10.30420/454862046. XHEMRISHI M, COŞKUN M C, LIVA G, et al. List decoding of short codes for communication over unknown fading channels[C]. The 53rd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, USA, 2019: 810–814. doi: 10.1109/IEEECONF44664.2019.9048806. PANG Xu, YANG Chao, ZHANG Zaichen, et al. A channel-blind decoding for LDPC based on deep learning and dictionary learning[C]. 2019 IEEE International Workshop on Signal Processing Systems, Nanjing, China, 2019: 284–289. doi: 10.1109/SiPS47522.2019.9020628. FANG Yong. LDPC-based lossless compression of nonstationary binary sources using sliding-window belief propagation[J]. IEEE Transactions on Communications, 2012, 60(11): 3161–3166. doi: 10.1109/TCOMM.2012.080212.110108A FANG Yong. Asymmetric slepian-wolf coding of nonstationarily-correlated M-ary sources with sliding-window belief propagation[J]. IEEE Transactions on Communications, 2013, 61(12): 5114–5124. doi: 10.1109/TCOMM.2013.111313.130230 CCSDS 131.0-B-3. TM synchronization and channel coding[S]. Washington, USA: The Consultative Committee for Space Data Systems, 2017. 3GPP TS 38.212 V16.0.0. Multiplexing and channel coding (Release 16)[S]. 3rd Generation Partnership Project, 2019. -

 下载:
下载:


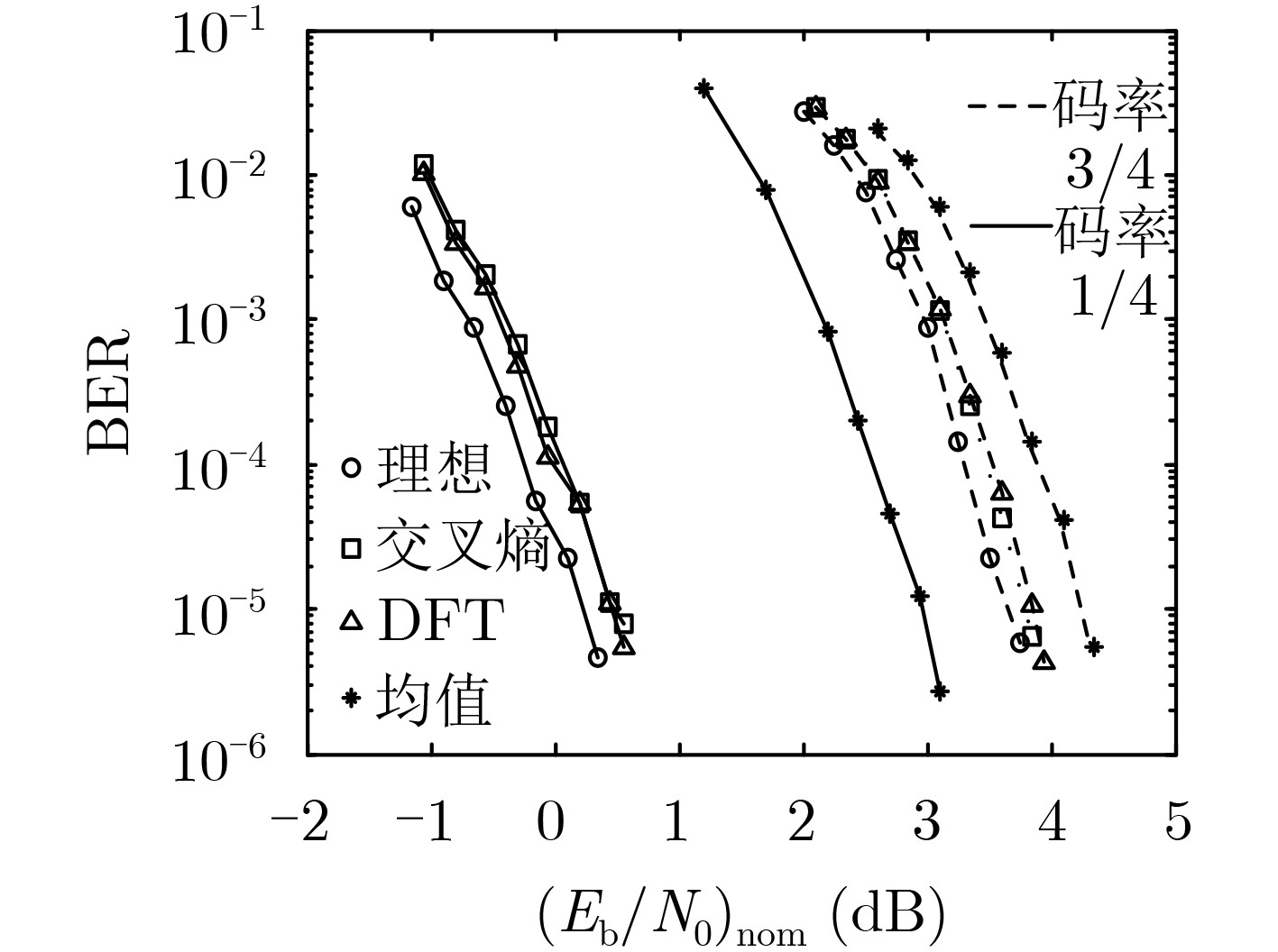

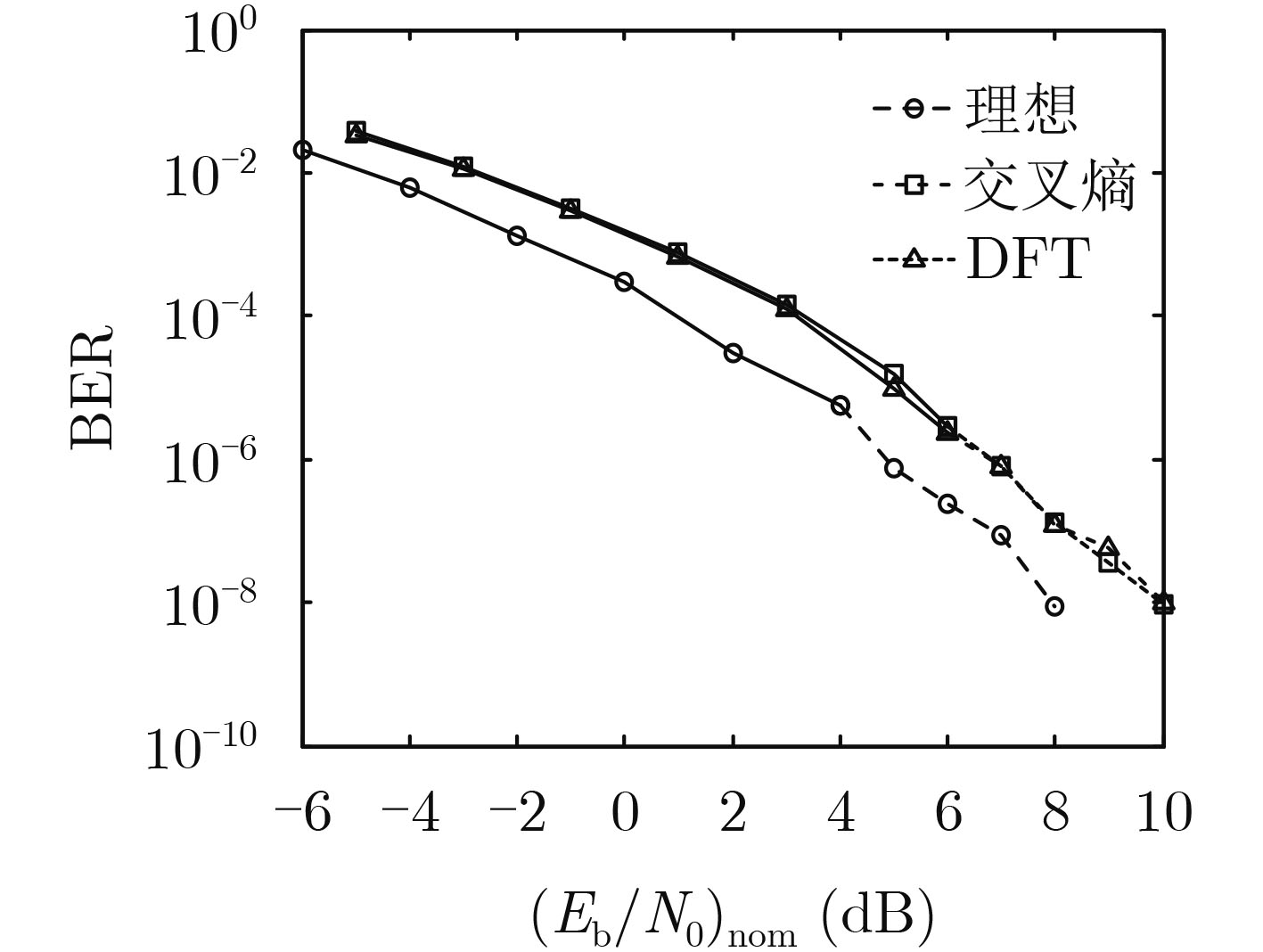


图(9)
计量
- 文章访问数: 1515
- HTML全文浏览量: 655
- PDF下载量: 103
- 被引次数: 0
 下载:
下载:
