

Attention Based Single Shot Multibox Detector
-
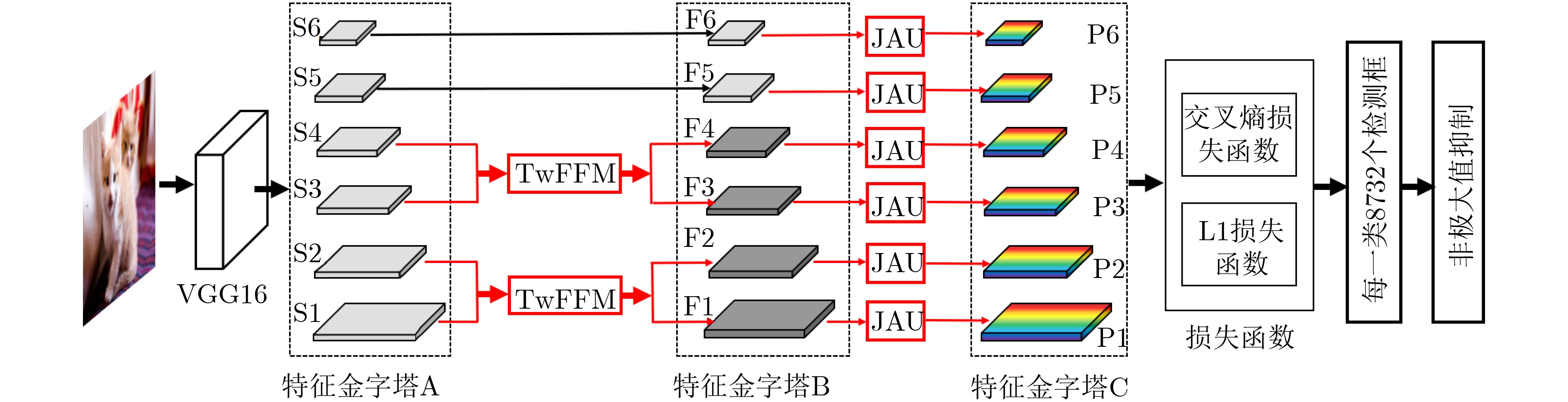
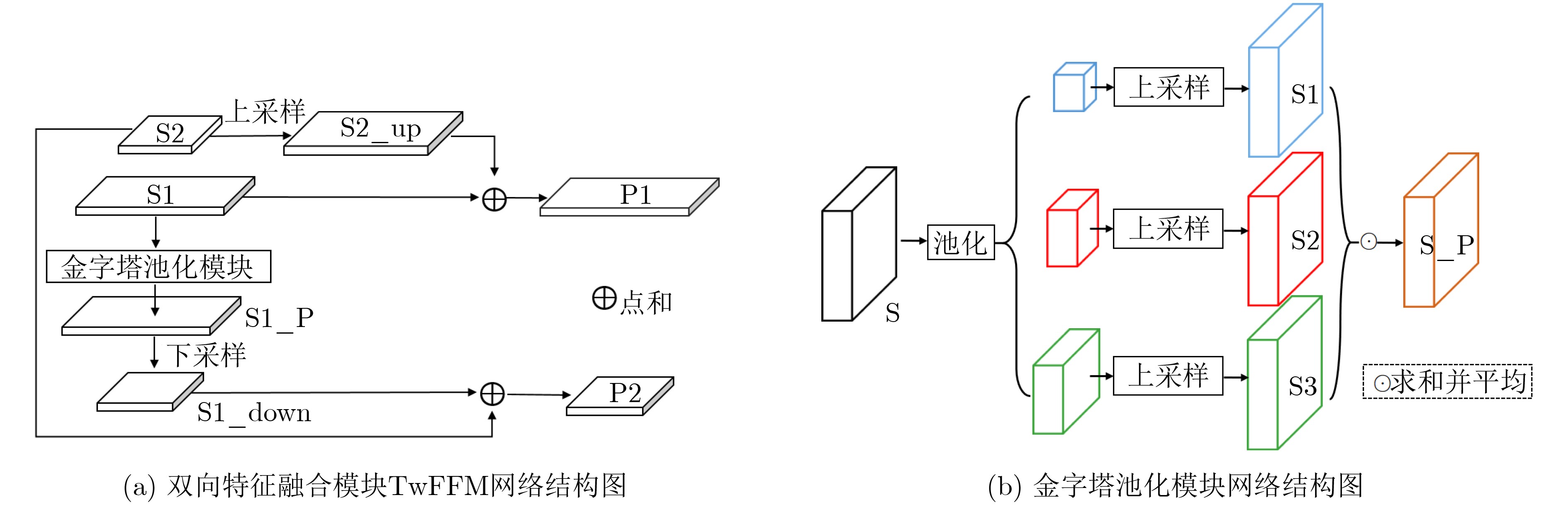
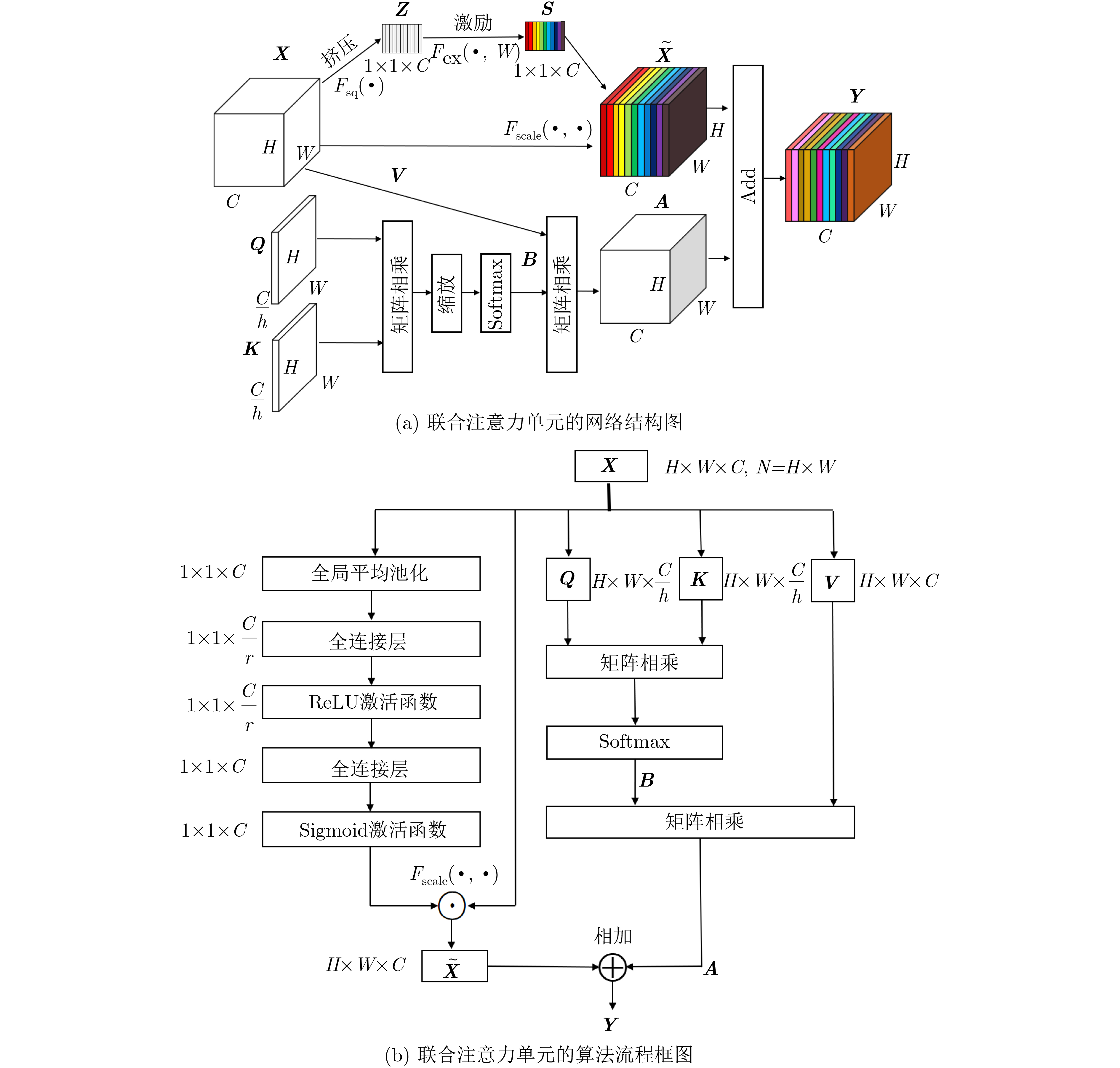
摘要: 单发多框检测器SSD是一种在简单、快速和准确性之间有着较好平衡的目标检测器算法。SSD网络结构中检测层单一的利用方式使得特征信息利用不充分,将导致小目标检测不够鲁棒。该文提出一种基于注意力机制的单发多框检测器算法ASSD。ASSD算法首先利用提出的双向特征融合模块进行特征信息融合以获取包含丰富细节和语义信息的特征层,然后利用提出的联合注意力单元进一步挖掘重点特征信息进而指导模型优化。最后,公共数据集上进行的一系列相关实验表明ASSD算法有效提高了传统SSD算法的检测精度,尤其适用于小目标检测。Abstract: Single Shot multibox Detector (SSD) is a object detection algorithm that provides the optimal trade-off among simplicity, speed and accuracy. The single use of detection layers in SSD network structure makes the feature information not fully utilized, which will lead to the small object detection are not robust enough. In this paper, an Attention based Single Shot multibox Detector (ASSD) is proposed. The ASSD algorithm first uses the proposed two-way feature fusion module to fuse the feature information to obtain the feature layer which containing rich details and semantic information. Then, the proposed joint attention unit is used to mine further the key feature information to guide the model optimization. Finally, a series of experiments on the common data set show that the ASSD algorithm effectively improves the detection accuracy of conventional SSD algorithm, especially for small object detection.
-
表 2 各种算法在Pascal VOC2007测试集上的性能对比
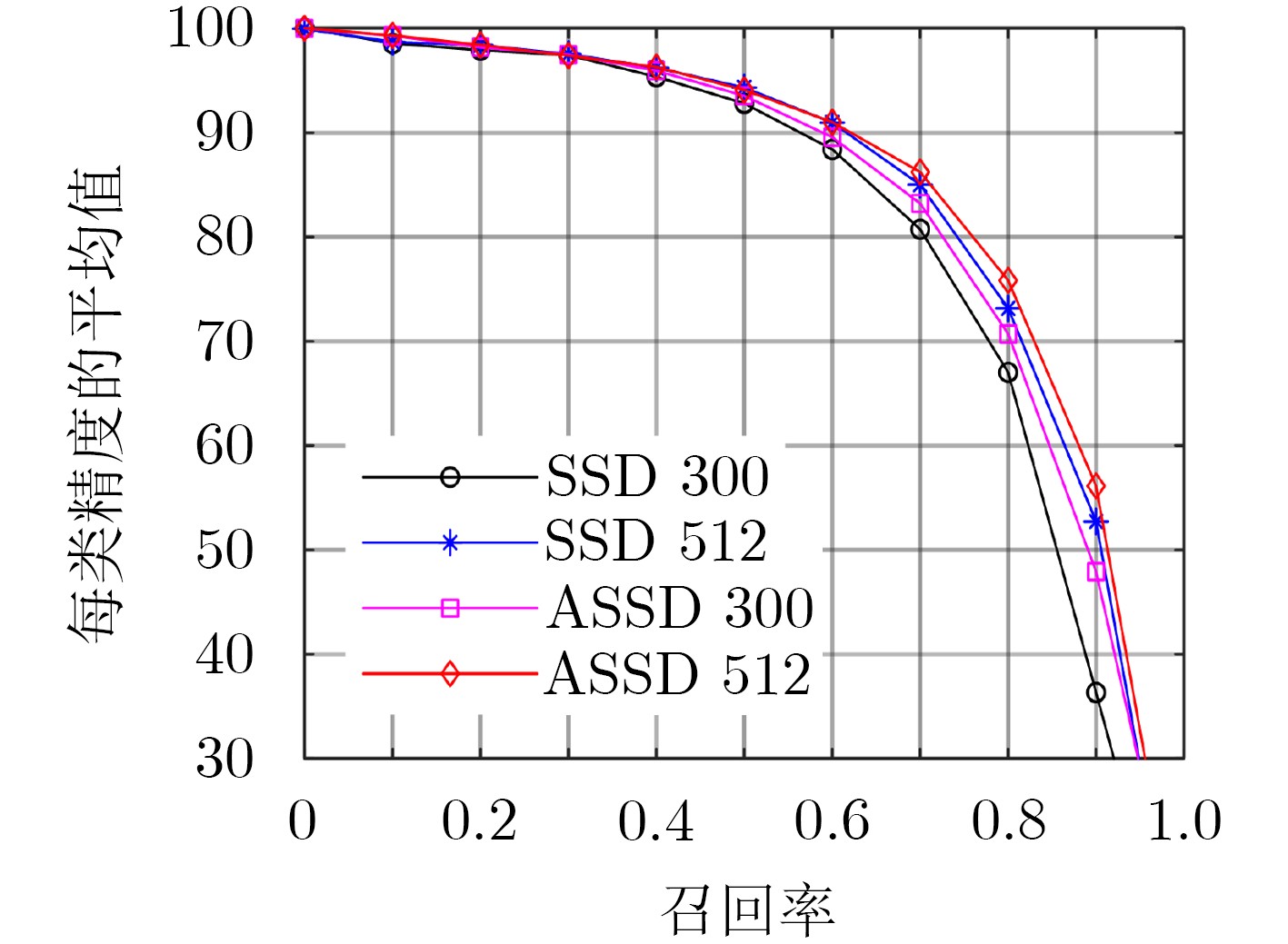
方法 基础骨干网 输入尺寸 mAP fps YOLOv2[11] Darkent-19 416×416 76.8 67 YOLOv2+[11] Darkent-19 544×544 78.6 40 Faster RCNN[7] ResNet-101 ~1000×600 76.4 2.4 SSD300 VGG-16 300×300 77.5 60.2 SSD512 VGG-16 512×512 79.8 25.2 DSSD321[16] ResNet-101 300×300 78.6 9.5 DSSD513[16] ResNet-101 513×513 81.5 5.5 RSSD300[20] VGG-16 300×300 78.5 35.0 RSSD512[20] VGG-16 300×300 80.8 16.6 FSSD300[21] VGG-16 300×300 78.8 65.8 FSSD512[21] VGG-16 512×512 80.9 35.7 ASSD300 VGG-16 300×300 79.1 39.6 ASSD512 VGG-16 512×512 81.0 20.8  下载: 导出CSV
下载: 导出CSV
表 3 各种算法在Pascal VOC2007测试集中20个类别的性能对比
方法 mAP aero bike bird boat bottle bus car cat chair cow SSD300 77.5 79.5 83.9 76.0 69.6 50.5 87.0 85.7 88.1 60.3 81.5 SSD512 79.8 85.8 85.6 79.5 74.1 59.9 86.8 88 89.1 63.8 86.3 ASSD300 79.1 85.4 84.1 78.7 71.8 54.0 86.2 85.3 89.5 60.4 87.4 ASSD512 81.0 86.8 85.2 84.1 75.2 60.5 88.3 88.4 89.3 63.5 87.6 方法 mAP table dog horse mbike person plant sheep sofa train tv SSD300 77.5 77.0 86.1 87.5 84.0 79.4 52.3 77.9 79.5 87.6 76.8 SSD512 79.8 75.8 87.4 87.5 83.2 83.5 56.3 81.6 77.7 87 77.4 ASSD300 79.1 77.1 87.4 86.8 84.8 79.5 57.8 81.5 80.1 87.4 76.9 ASSD512 81.0 76.6 88.2 86.7 85.7 82.8 59.2 83.6 80.5 87.5 80.8
下载: 导出CSV
-
[1] 赵凤, 孙文静, 刘汉强, 等. 基于近邻搜索花授粉优化的直觉模糊聚类图像分割[J]. 电子与信息学报, 2020, 42(4): 1005–1012. doi: 10.11999/JEIT190428ZHAO Feng, SUN Wenjing, LIU Hanqiang, et al. Intuitionistic fuzzy clustering image segmentation based on flower pollination optimization with nearest neighbor searching[J]. Journal of Electronics &Information Technology, 2020, 42(4): 1005–1012. doi: 10.11999/JEIT190428 [2] 孙彦景, 石韫开, 云霄, 等. 基于多层卷积特征的自适应决策融合目标跟踪算法[J]. 电子与信息学报, 2019, 41(10): 2464–2470. doi: 10.11999/JEIT180971SUN Yanjing, SHI Yunkai, YUN Xiao, et al. Adaptive strategy fusion target tracking based on multi-layer convolutional features[J]. Journal of Electronics &Information Technology, 2019, 41(10): 2464–2470. doi: 10.11999/JEIT180971 [3] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81. [4] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824 [5] GIRSHICK R. Fast R-CNN[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1440–1448. doi: 10.1109/ICCV.2015.169. [6] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large scale image recognition[C]. Proceedings of the 3rd International Conference on Learning Representations, San Diego, USA, 2015. [7] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [8] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91. [9] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2. [10] SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. doi: 10.1109/CVPR.2015.7298594. [11] REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7263–7271. doi: 10.1109/CVPR.2017.690. [12] ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 818–833. doi: 10.1007/978-3-319-10590-1_53. [13] CHEN Chenyi, LIU Mingyu, TUZEL O, et al. R-CNN for small object detection[C]. Proceedings of the 13th Asian Conference on Computer Vision, Taipei, China, 2016: 214–230. doi: 10.1007/978-3-319-54193-8_14. [14] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [15] HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4700–4708. doi: 10.1109/CVPR.2017.243. [16] FU Chengyang, LIU Wei, RANGA A, et al. DSSD: Deconvolutional single shot detector[J]. arXiv: 1701.06659, 2017. [17] SHEN Zhiqiang, LIU Zhuang, LI Jianguo, et al. Dsod: Learning deeply supervised object detectors from scratch[C]. Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1919–1927. doi: 10.1109/ICCV.2017.212. [18] ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 818–833. [19] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2117–2125. doi: 10.1109/CVPR.2017.106. [20] JEONG J, PARK H, and KWAK N. Enhancement of SSD by concatenating feature maps for object detection[C]. Proceedings of 2017 British Machine Vision Conference, London, UK, 2017. [21] LI Zuoxin and ZHOU Fuqiang. FSSD: Feature fusion single shot Multibox detector[J]. arXiv: 1712.00960, 2017. [22] MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2204–2212. [23] BAHDANAU D, CHO K, BENGIO Y, et al. Neural machine translation by jointly learning to align and translate[C]. Proceedings of the 3rd International Conference on Learning Representations, San Diego, USA, 2015. [24] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5998–6008. [25] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. doi: 10.1109/CVPR.2018.00745. [26] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4 -

 下载:
下载:



图(5) / 表(3)
计量
- 文章访问数: 1690
- HTML全文浏览量: 782
- PDF下载量: 145
- 被引次数: 0
