

A Review of Action Recognition Using Joints Based on Deep Learning
-
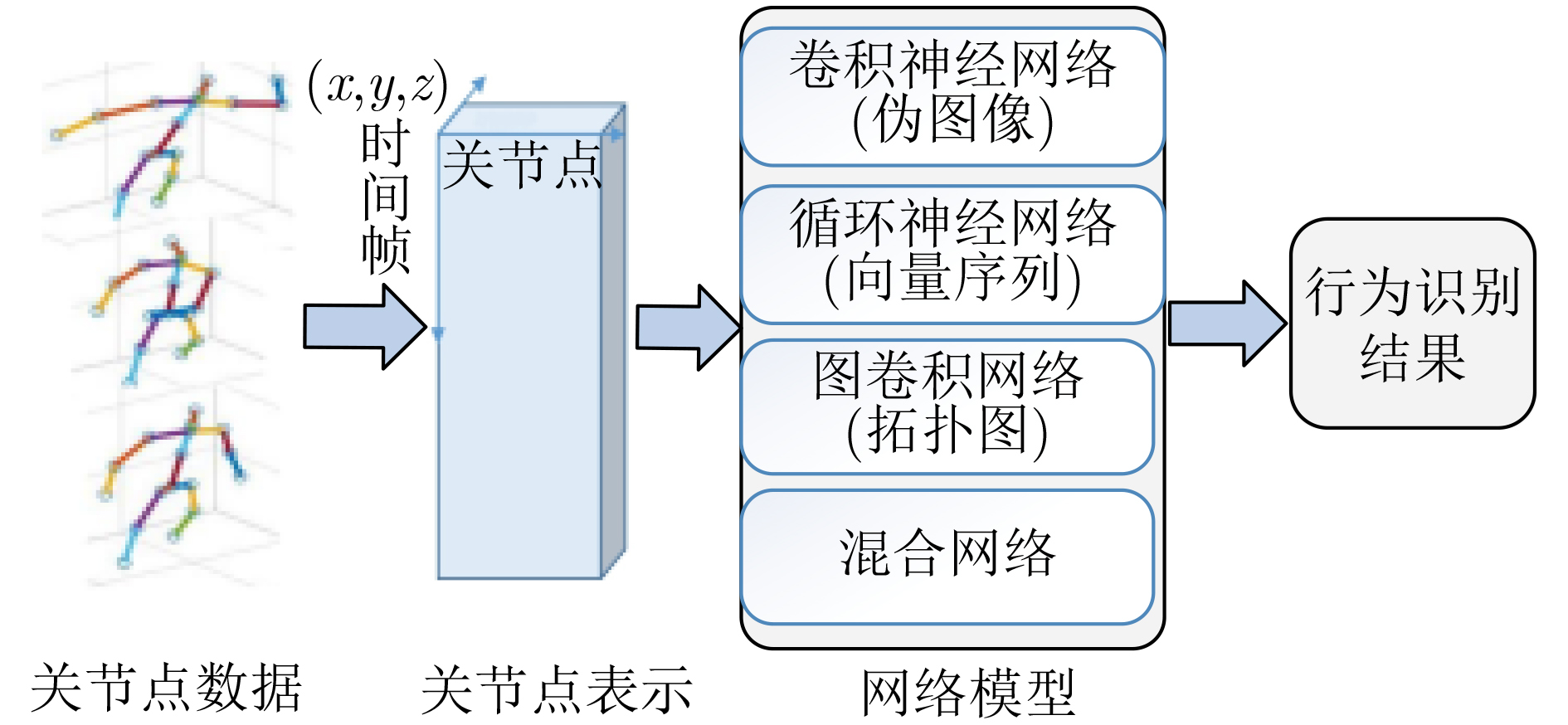
摘要: 关节点行为识别由于其不易受外观影响、能更好地避免噪声影响等优点备受国内外学者的关注,但是目前该领域的系统归纳综述较少。该文综述了基于深度学习的关节点行为识别方法,按照网络主体的不同将其划分为卷积神经网络(CNN)、循环神经网络(RNN)、图卷积网络和混合网络。卷积神经网络、循环神经网络、图卷积网络分别擅长处理的关节点数据表示方式是伪图像、向量序列、拓扑图。归纳总结了目前国内外常用的关节点行为识别数据集,探讨了关节点行为识别所面临的挑战以及未来研究方向,高精度前提下快速行为识别和实用化仍然需要继续推进。Abstract: Action recognition using joints has attracted the attention of scholars at home and abroad because it is not easily affected by appearance and can better avoid the impact of noise. However, there are few systematic reviews in this field. In this paper, the methods of action recognition using joints based on deep learning in recent years are summarized. According to the different subjects of the network, it is divided into Convolutional Neural Network(CNN), Recurrent Neural Network(RNN), graph convolution network and hybrid network. The representation of joint point data that convolution neural network, recurrent neural network and graph convolution network are good at is pseudo image, vector sequence and topological graph. This paper summarizes the current data sets of action recognition using joints at home and abroad, and discusses the challenges and future research directions of behavior recognition using joints. Under the premise of high precision, rapid action recognition and practicality still need to be further promoted.
-
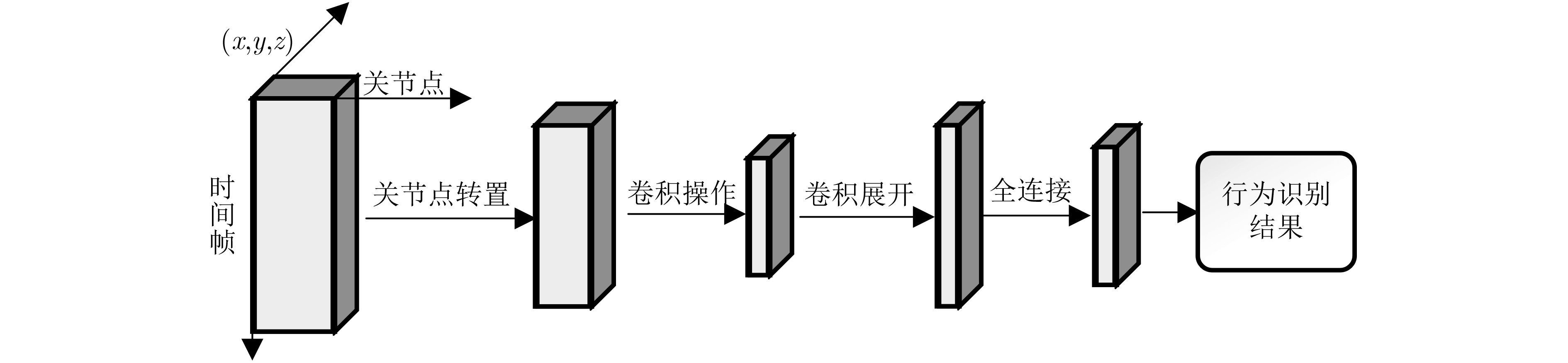
表 1 主干网络为卷积神经网络的关节点行为识别及代表性工作
年份 技术特点 模型优劣分析 实验结果(%) NTU RGB+D SBU JHMDB 2017 平移尺度不变图像映射和多尺度深度CNN[11] 可以在预训练的CNN网络上进行 CS:85.0 CV:96.3 – – 2017 残差时间卷积[12] 模型易于解释,但准确率一般 CS:74.3 CV:83.1 – – 2017 引入骨架变换的双流CNN架构[13] 证明了CNN具有时间模拟能力 CS:83.2 CV:89.3 – – 2017 多流卷积神经网络[14] 消除视图变化的影响且保留原始关节数据中的运动特征 CS:80.0 CV:87.2 – – 2017 卷积神经网络[15] 将迁移学习应用于关节点行为识别,提高了训练效率 CS:75.9 CV:81.2 – – 2017 卷积神经网络+多任务学习[16] 训练效率低 CS:79.6 CV:84.8 Acc:93.6 – 2018 从细到粗的卷积神经网络[17] 网络架构较浅,能避免数量不足容易过拟合的问题 CS:79.6 CV:84.6 Acc:99.1 – 2018 分层共现的卷积神经网络[18] 能利用不同关节之间的相关性 CS:86.5 CV:91.1 Acc:98.6 – 2019 双流的卷积神经(RGB信息和关节点信息结合)[20] 训练时间短 CS:80.09 Acc:92.55 – 2019 卷积神经网络(多姿势模态)[21] 网络框架简洁,准确率一般 – – Acc:69.5 2019 卷积神经网络(树结构和参考关节的图像表示方法)[22] 训练效率不高 – – Acc:69.5 2019 卷积神经网络(重新编码骨架关节的时间动态)[23] 能够有效过滤数据中的噪声 CS:76.5 CV:84.7 – – 2019 卷积神经网络(轻量级)[24] 速度快,准确率低 CS:67.7 CV:66.9 – Acc:78.0  下载: 导出CSV
下载: 导出CSV
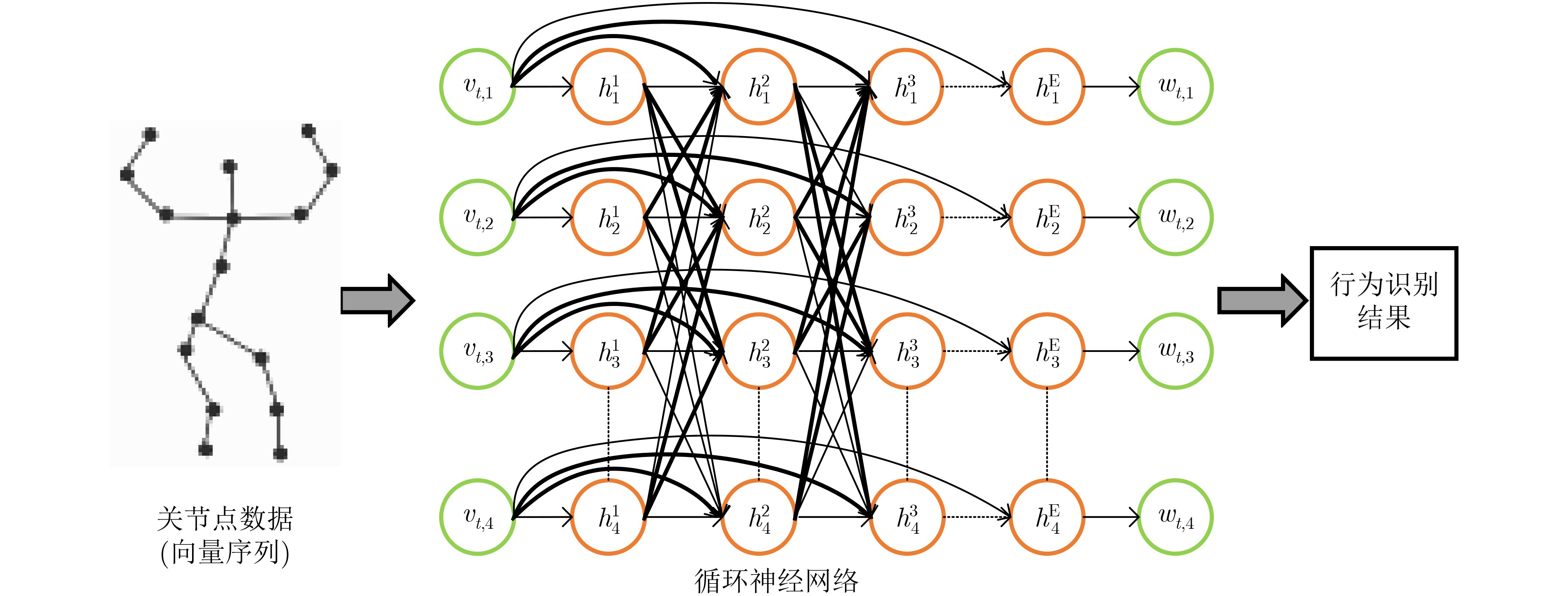
表 2 主干网络为循环神经网络的关节点行为识别及代表性工作
年份 技术特点 模型优劣分析 实验结果(%) NTU RGB+D UK-Kinect SYSU 3D 2016 长短期记忆模型(将身体分为5个部分)[26] 能有效且直观地保持上下文信息,
但是识别准确率不高CS: 62.9 CV:70.3 – – 2016 基于信任门的长短期记忆模型[27] 能够降低关节点数据的噪声 CS:69.2 CV:77.7 Acc:97.0 – 2017 基于信任门的长短期记忆模型(加入多模式特征融合策略)[28] 提高了识别准确率,降低了训练效率 CS:73.2 CV:80.6 Acc:98.0 Acc:76.5 2017 全局上下文感知长短期记忆模型
(注意力机制)[29]能够更好地聚焦每一帧中的关键关节点 CS:74.4 CV:82.8 Acc:98.5 – 2017 全局上下文感知长短期记忆模型(双流+注意力机制)[30] 提高了识别准确率,降低了训练效率 CS:77.1 CV:85.1 Acc:99.0 Acc:79.1 2019 双流长短期记忆模型(注意力
机制)[31]更充分地利用关节信息,提高识别准确率 CS:81.8 CV:89.6 – – 2018 独立递归神经网络[32] 能更好地在网络较深的情况下避免
梯度爆炸和梯度消失CS:81.8 CV:88.0 – –
下载: 导出CSV
表 3 主干网络为图卷积网络的关节点行为识别及代表性工作
年份 技术特点 模型优劣分析 实验结果(%) NTU RGB+D Kinects Florence 3D 2018 时空图卷积网络[34] 难以学习无物理联系关节之间的关系 CS:81.5 CV:88.3 Top1:30.7 Top5:52.8 – 2018 双流自适应图卷积[35] 充分利用骨架的2阶信息
(骨骼的长度的方向)CS:88.5 CV:95.1 Top1:36.1 Top5:58.7 – 2019 图卷积(编解码)[36] 模型复杂度高 CS:86.8 CV:94.2 Top1:34.8 Top5:56.5 – 2018 时空图卷积网络(图回归)[37] 充分利用关节之间的物理和非物理的
依赖关系以及连续帧上的时间连通性CS:87.5 CV:94.3 – Acc:98.4 2018 时空图卷积网络[38] 缺乏时间连通性 CS:74.9 CV:86.3 – Acc:99.1 2018 关键帧提取+图卷积网络[39] 关键帧的提取能够提高训练效率 CS:83.5 CV:89.8 – – 2019 图卷积网络(神经体系结构搜索)[41] 采样和存储效率高 CS:89.4 CV:95.7 Top1:37.1 Top5:60.1 – 2019 图卷积网络(空间残差层、密集连接)[42] 容易与主流时空图卷积方法结合 CS:89.6 CV:95.7 Top1:37.4 Top5:60.4 – 2019 图卷积网络(有向无环图)[43] 识别准确率高 CS:89.9 CV:96.1 Top1:36.9 Top5:59.6 – 2019 共生图卷积网络(行为识别和预测)[44] 增加预测功能,与识别功能相互
促进,提高准确率CS:90.1 CV:96.4 Top1:37.2 Top5:58.1 – 2020 时空和通道注意的伪图卷积网络[45] 能提取关键帧,但是可能会省略掉部分
关键信息CS:88.0 CV:93.6 – –
下载: 导出CSV
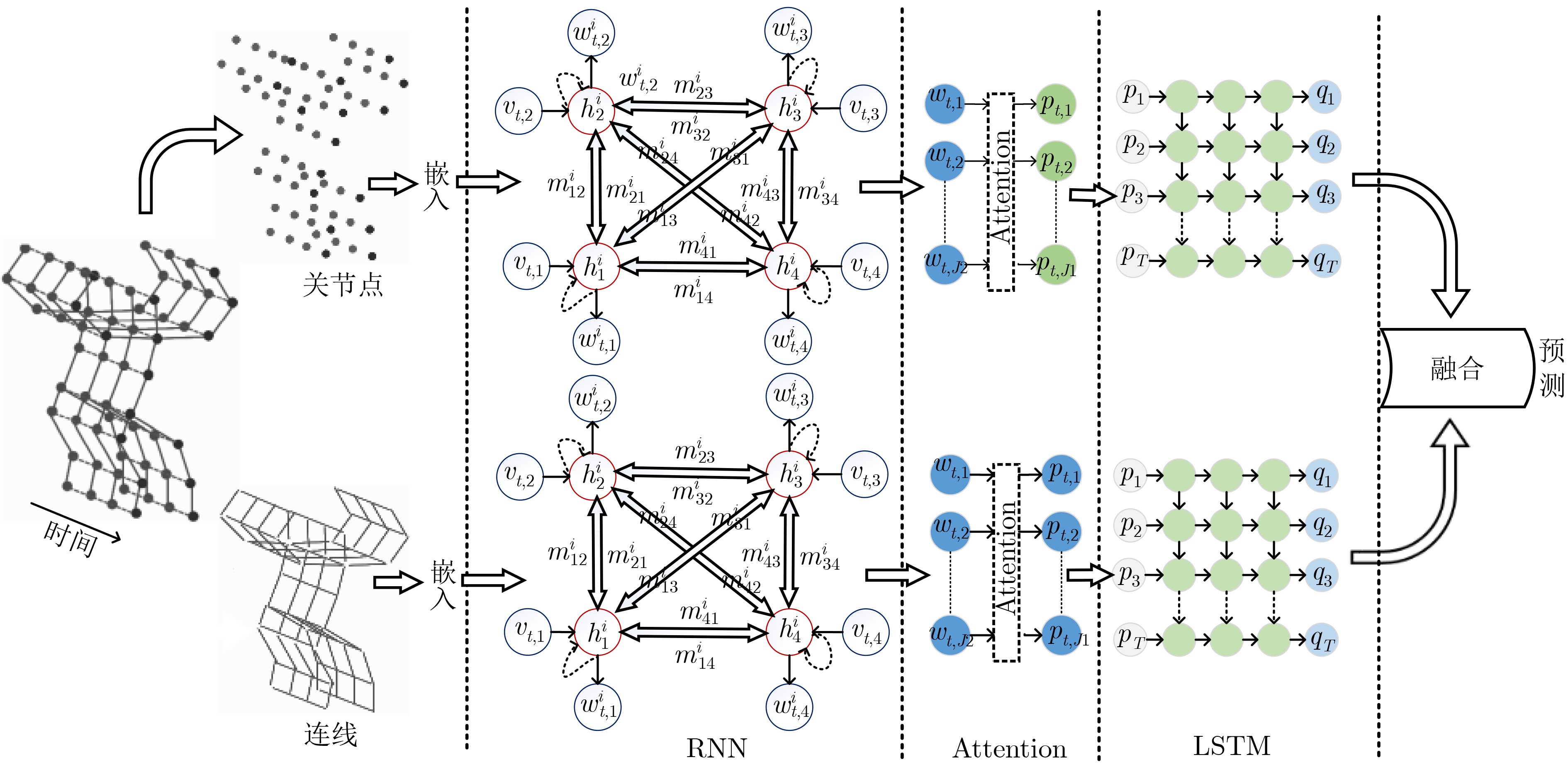
表 4 主干网络为混合网络的关节点行为识别及代表性工作
年份 技术特点 模型优劣分析 实验结果(%) NTU RGB+D Kinects N-UCLA 2018 LSTM+CNN[48] 视图自适应子网减弱了视角变化对识别的影响 CS:88.7 CV:94.3 – Acc:86.6 2018 CNN+图卷积(多域)[49] 增加了对频率的学习 CS:89.1 CV:94.9 Top1:36.6 Top5:59.1 – 2018 图卷积+LSTM[50] 能同时在空间和时间域上提取行为特征,但模型复杂度较高 CS:84.8 CV:92.4 – – 2019 图卷积+LSTM(注意力机制)[51] 增加顶层AGC-LSTM层的时间接受域,能够降低计算成本 CS:89.2 CV:95.0 – – 2019 图卷积+LSTM(双向注意力机制)[52] 非常高的识别准确率 CS:90.3 CV:96.3 Top1:37.3 Top5:60.2 – 2019 图卷积网络(语义)[53] 语义信息能够降低模型复杂度 CS:86.6 CV:93.4 – Acc:92.5 2018 RNN+CNN[54] 首次采用RNN+CNN的组合提取时空特征,
准确率不高CS:83.0 CV:93.2 – – 2018 可变形姿势遍历卷积网络+LSTM[55] 对嘈杂关节更具有鲁棒性,但是识别准确率较低 CS:76.8 CV:84.9 – –
下载: 导出CSV
表 5 关节点行为识别数据集简介
名称 样本数 动作类数 表演者数 视点数 来源 数据形式 年份 Hollywood2[70] 3669 12 -- -- 电影 RGB 2009 HMDB[71] 6849 51 -- -- 电影 RGB 2011 MSRDailyACtivity3D[56] 320 16 10 1 Kinect v1 RGB/深度/关节点 2011 SBU[57] 300 8 7 3 Kinect v1 RGB/深度/关节点 2012 UT-Kinect[9] 199 10 10 1 Kinect v1 RGB/深度/关节点 2012 3D Action Pairs[58] 360 12 10 1 Kinect v1 RGB/深度/关节点 2013 Florence 3D[59] 215 9 10 1 Kinect v1 RGB/关节点 2013 Multiview 3D Event[60] 3815 8 8 3 Kinect v1 RGB/深度/关节点 2013 Online RGB+D Action[61] 336 7 24 1 Kinect v1 RGB/深度/关节点 2014 N-UCLA[62] 1475 10 10 3 Kinect v1 RGB/深度/关节点 2014 UWA3D [63] 900 30 10 1 Kinect v1 RGB/深度/关节点 2014 UTD-MHAD[64] 861 27 8 1 Kinect v1+传感器 RGB/深度/关节点/惯性传感信号 2015 SYSU 3D[65] 480 12 40 1 Kinect v1 RGB/深度/关节点 2015 UWA 3D Multiview II[66] 1075 30 10 5 Kinect v1 RGB/深度/关节点 2015 M2I[67] 1800 22 22 2 Kinect v1 RGB/深度/关节点 2015 NTU RGB+D[26] 56880 60 40 80 Kinect v2 RGB/深度/关节点/红外信号 2016 Kinects[68] 306245 400 - - YouTube RGB/深度/声音 2017 NTU RGB+D 120[69] 114480 120 106 155 Kinect v2 RGB/深度/关节点/红外信号 2019
下载: 导出CSV
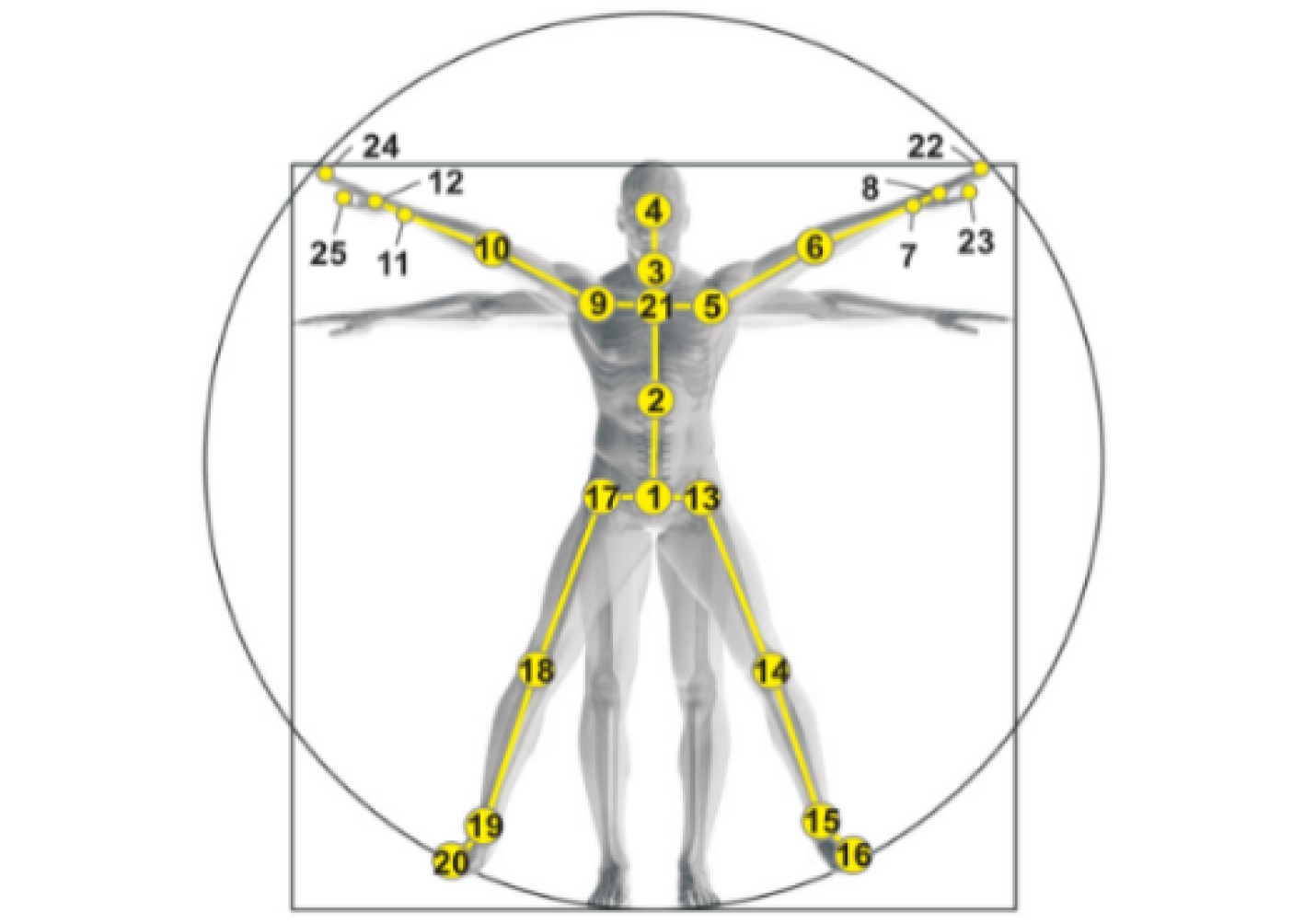
表 6 关节点位置对照表
序号 对应关节 序号 对应关节 序号 对应关节 序号 对应关节 序号 对应关节 1 脊柱底部 6 左肘 11 右腕 16 左脚 21 脊柱 2 脊柱中间 7 左腕 12 右手 17 右髋 22 左手尖 3 颈 8 左手 13 左髋 18 右膝 23 左手拇指 4 头 9 右肩 14 左膝 19 右踝 24 右手尖 5 左肩 10 右肘 15 左踝 20 右脚 25 右手拇指
下载: 导出CSV
-
[1] 吴培良, 杨霄, 毛秉毅, 等. 一种视角无关的时空关联深度视频行为识别方法[J]. 电子与信息学报, 2019, 41(4): 904–910. doi: 10.11999/JEIT180477WU Peiliang, YANG Xiao, MAO Bingyi, et al. A perspective-independent method for behavior recognition in depth video via temporal-spatial correlating[J]. Journal of Electronics &Information Technology, 2019, 41(4): 904–910. doi: 10.11999/JEIT180477 [2] 朱煜, 赵江坤, 王逸宁, 等. 基于深度学习的人体行为识别算法综述[J]. 自动化学报, 2016, 42(6): 848–857. doi: 10.16383/j.aas.2016.c150710ZHU Yu, ZHAO Jiangkun, WANG Yining, et al. A review of human action recognition based on deep learning[J]. Acta Automatica Sinica, 2016, 42(6): 848–857. doi: 10.16383/j.aas.2016.c150710 [3] 罗会兰, 王婵娟, 卢飞. 视频行为识别综述[J]. 通信学报, 2018, 39(6): 169–180. doi: 10.11959/j.issn.1000-436x.2018107LUO Huilan, WANG Chanjuan, and LU Fei. Survey of video behavior recognition[J]. Journal on Communications, 2018, 39(6): 169–180. doi: 10.11959/j.issn.1000-436x.2018107 [4] 张会珍, 刘云麟, 任伟建, 等. 人体行为识别特征提取方法综述[J]. 吉林大学学报: 信息科学版, 2020, 38(3): 360–370.ZHANG Huizhen, LIU Yunlin, REN Weijian, et al. Human behavior recognition feature extraction method: A survey[J]. Journal of Jilin University:Information Science Edition, 2020, 38(3): 360–370. [5] ZHU Fan, SHAO Ling, XIE Jin, et al. From handcrafted to learned representations for human action recognition: A survey[J]. Image and Vision Computing, 2016, 55(2): 42–52. doi: 10.1016/j.imavis.2016.06.007 [6] ZHANG Zhengyou. Microsoft kinect sensor and its effect[J]. IEEE Multimedia, 2012, 19(2): 4–10. doi: 10.1109/MMUL.2012.24 [7] YAN Yichao, XU Jingwei, NI Bingbing, et al. Skeleton-aided articulated motion generation[C]. The 25th ACM International Conference on Multimedia, Mountain View, USA, 2017: 199–207. doi: 10.1145/3123266.3123277. [8] HAN Fei, REILY B, HOFF W, et al. Space-time representation of people based on 3D skeletal data: A review[J]. Computer Vision and Image Understanding, 2017, 158: 85–105. doi: 10.1016/j.cviu.2017.01.011 [9] XIA Lu, CHEN C C, and AGGARWAL J K. View invariant human action recognition using histograms of 3D joints[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, USA, 2012: 20–27. [10] WENG Junwu, WENG Chaoqun, and YUAN Junsong. Spatio-temporal Naive-Bayes nearest-neighbor (ST-NBNN) for skeleton-based action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Tianjin, China, 2017: 4171–4180. [11] LI Bo, DAI Yuchao, CHENG Xuelian, et al. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN[C]. 2017 IEEE International Conference on Multimedia & Expo Workshops, Hong Kong, China, 2017: 4171–4180. doi: 10.1109/ICMEW.2017.8026282. [12] KIM T S and REITER A. Interpretable 3D human action analysis with temporal convolutional networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 2017: 1623–1631. dio: 10.1109/CVPRW. 2017.207. [13] LI Chao, ZHONG Qiaoyong, XIE Di, et al. Skeleton-based action recognition with convolutional neural networks[C]. 2017 IEEE International Conference on Multimedia & Expo Workshops, Hong Kong, China, 2017: 597–600. doi: 10.1109/ICMEW.2017.8026285. [14] LIU Mengyuan, LIU Hong, and CHEN Chen. Enhanced skeleton visualization for view invariant human action recognition[J]. Pattern Recognition, 2017, 68: 346–362. doi: 10.1016/j.patcog.2017.02.030 [15] KE Qiuhong, AN Senjian, BENNAMOUN M, et al. SkeletonNet: Mining deep part features for 3-D action recognition[J]. IEEE Signal Processing Letters, 2017, 24(6): 731–735. doi: 10.1109/LSP.2017.2690339 [16] KE Qiuhong, BENNAMOUN M, AN Senjian, et al. A new representation of skeleton sequences for 3D action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3288–3297. [17] LE T M, INOUE N, and SHINODA K. A fine-to-coarse convolutional neural network for 3D human action recognition[J]. arXiv preprint arXiv: 1805.11790, 2018. [18] LI Chao, ZHONG Qiaoyong, XIE Di, et al. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation[J]. arXiv preprint arXiv: 1804.06055, 2018. [19] 刘庭煜, 陆增, 孙毅锋, 等. 基于三维深度卷积神经网络的车间生产行为识别[J]. 计算机集成制造系统, 2020, 26(8): 2143–2156.LIU Tingyu, LU Zeng, SUN Yifeng, et al. Working activity recognition approach based on 3D deep convolutional neural network[J]. Computer Integrated Manufacturing Systems, 2020, 26(8): 2143–2156. [20] 姬晓飞, 秦琳琳, 王扬扬. 基于RGB和关节点数据融合模型的双人交互行为识别[J]. 计算机应用, 2019, 39(11): 3349–3354. doi: 772/j.issn.1001-9081.2019040633JI Xiaofei, QIN Linlin, and WANG Yangyang. Human interaction recognition based on RGB and skeleton data fusion model[J]. Journal of Computer Applications, 2019, 39(11): 3349–3354. doi: 772/j.issn.1001-9081.2019040633 [21] YAN An, WANG Yali, LI Zhifeng, et al. PA3D: Pose-action 3D machine for video recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7922–7931. doi: 10.1109/CVPR.2019.00811. [22] CAETANO C, BRÉMOND F, and SCHWARTZ W R. Skeleton image representation for 3D action recognition based on tree structure and reference joints[C]. The 32nd SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 2019: 16–23. [23] CAETANO C, SENA J, BRÉMOND F, et al. SkeleMotion: A new representation of skeleton joint sequences based on motion information for 3D action recognition[C]. The 16th IEEE International Conference on Advanced Video and Signal Based Surveillance, Taipei, China, 2019: 1–8. doi: 10.1109/AVSS.2019.8909840. [24] LI Yanshan, XIA Rongjie, LIU Xing, et al. Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition[C]. 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 2019: 1066–1071. doi: 10.1109/ICME.2019.00187. [25] YANG Fan, WU Yang, SAKTI S, et al. Make skeleton-based action recognition model smaller, faster and better[C]. The ACM Multimedia Asia, Beijing, China, 2019: 1–6. doi: 10.1145/3338533.3366569. [26] SHAHROUDY A, LIU Jun, NG T T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115. [27] LIU Jun, SHAHROUDY A, XU Dong, et al. Spatio-temporal LSTM with trust gates for 3D human action recognition[C]. The European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 816–833. doi: 10.1007/978-3-319-46487-9_50. [28] LIU Jun, SHAHROUDY A, XU Dong, et al. Skeleton-based action recognition using spatio-temporal LSTM network with trust gates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(12): 3007–3021. doi: 10.1109/TPAMI.2017.2771306 [29] LIU Jun, WANG Gang, HU Ping, et al. Global context-aware attention LSTM networks for 3D action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1647–1656. doi: 10.1109/CVPR.2017.391. [30] LIU Jun, WANG Gang, DUAN Lingyun, et al. Skeleton-based human action recognition with global context-aware attention LSTM networks[J]. IEEE Transactions on Image Processing, 2018, 27(4): 1586–1599. [31] ZHENG Wu, LI Lin, ZHANG Zhaoxiang, et al. Relational network for skeleton-based action recognition[C]. 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 2019: 826–831. [32] LI Shuai, LI Wanqing, COOK C, et al. Independently recurrent neural network (IndRNN): Building a longer and deeper RNN[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5457–5466. doi: 10.1109/CVPR.2018.00572. [33] 王佳铖, 鲍劲松, 刘天元, 等. 基于工件注意力的车间作业行为在线识别方法[J/OL]. 计算机集成制造系统, 2020: 1–13. http://kns.cnki.net/kcms/detail/11.5946.TP.20200623.1501.034.html.WANG Jiacheng, BAO Jinsong, LIU Tianyuan, et al. Online method for worker operation recognition based on the attention of workpiece[J/OL]. Computer Integrated Manufacturing Systems, 2020: 1–13. http://kns.cnki.net/kcms/detail/11.5946.TP.20200623.1501.034.html. [34] YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[J]. arXiv preprint arXiv: 1801.07455, 2018. [35] SHI Lei, ZHANG Yifan, CHENG Jia, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 12026–12035. [36] LI M, CHEN Siheng, CHEN Xu, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3595–3603. [37] GAO Xiang, HU Wei, TANG Jiaxiang, et al. Optimized skeleton-based action recognition via sparsified graph regression[C]. The 27th ACM International Conference on Multimedia, New York, USA, 2019: 601–610. [38] LI Chaolong, CUI Zhen, ZHENG Wenming, et al. Spatio-temporal graph convolution for skeleton based action recognition[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 247–254. [39] TANG Yansong, TIAN Yi, LU Jiwen, et al. Deep progressive reinforcement learning for skeleton-based action recognition[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5323–5332. [40] SONG Yifan, ZHANG Zhang, and WANG Liang. Richly activated graph convolutional network for action recognition with incomplete skeletons[C]. 2019 IEEE International Conference on Image Processing, Taipei, China, 2019: 1–5. doi: 10.1109/ICIP.2019.8802917. [41] PENG Wei, HONG Xiaopeng, CHEN Haoyu, et al. Learning graph convolutional network for skeleton-based human action recognition by neural searching[J]. arXiv preprint arXiv: 1911.04131, 2019. [42] WU Cong, WU Xiaojun, and KITTLER J. Spatial residual layer and dense connection block enhanced spatial temporal graph convolutional network for skeleton-based action recognition[C]. 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 2019: 1–5. [43] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Skeleton-based action recognition with directed graph neural networks[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7912–7921. [44] LI Maosen, CHEN Siheng, CHEN Xu, et al. Symbiotic graph neural networks for 3D skeleton-based human action recognition and motion prediction[J]. arXiv preprint arXiv: 1910.02212, 2019. [45] YANG Hongye, GU Yuzhang, ZHU Jianchao, et al. PGCN-TCA: Pseudo graph convolutional network with temporal and channel-wise attention for skeleton-based action recognition[J]. IEEE Access, 2020, 8: 10040–10047. doi: 10.1109/ACCESS.2020.2964115 [46] WU Felix, ZHANG Tianyi, DE SOUZA JR A H, et al. Simplifying graph convolutional networks[J]. arXiv preprint arXiv: 1902.07153, 2019. [47] CHEN Jie, MA Tengfei, and XIAO Cao. FastGCN: Fast learning with graph convolutional networks via importance sampling[J]. arXiv preprint arXiv: 1801.10247, 2018. [48] ZHANG Pengfei, LAN Cuiling, XING Junliang, et al. View adaptive neural networks for high performance skeleton-based human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 1963–1978. doi: 10.1109/TPAMI.2019.2896631 [49] HU Guyue, CUI Bo, and YU Shan. Skeleton-based action recognition with synchronous local and non-local spatio-temporal learning and frequency attention[C]. 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 2019: 1216–1221. [50] SI Chenyang, JING Ya, WANG Wei, et al. Skeleton-based action recognition with spatial reasoning and temporal stack learning[C]. The European Conference on Computer Vision, Munich, Germany, 2018: 103–118. [51] SI Chenyang, CHEN Wentao, WANG Wei, et al. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1227–1236. doi: 10.1109/CVPR.2019.00132. [52] GAO Jialin, HE Tong, ZHOU Xi, et al. Focusing and diffusion: Bidirectional attentive graph convolutional networks for skeleton-based action recognition[J]. arXiv preprint arXiv: 1912.11521, 2019. [53] ZHANG Pengfei, LAN Cuiling, ZENG Wenjun, et al. Semantics-guided neural networks for efficient skeleton-based human action recognition[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020. doi: 10.1109/CVPR42600.2020.00119. [54] XIE Chunyu, LI Ce, ZHANG Baochang, et al. Memory attention networks for skeleton-based action recognition[C]. The 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 2018. [55] WENG Junwu, LIU Mengyuan, JIANG Xudong, et al. Deformable pose traversal convolution for 3D action and gesture recognition[C]. The European Conference on Computer Vision, Munich, Germany, 2018: 768–775. doi: 10.1007/978-3-030-01234-2_9. [56] WANG Jiang, LIU Zicheng, WU Ying, et al. Mining actionlet ensemble for action recognition with depth cameras[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 1290–1297. doi: 10.1109/CVPR.2012.6247813. [57] YUN K, HONORIO J, CHATTOPADHYAY D, et al. Two-person interaction detection using body-pose features and multiple instance learning[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, USA, 2012: 28–35. doi: 10.1109/CVPRW.2012.6239234. [58] OREIFEJ O and LIU Zicheng. HON4D: Histogram of oriented 4D normals for activity recognition from depth sequences[C]. 2013 IEEE conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 716–723. doi: 10.1109/CVPR.2013.98. [59] SEIDENARI L, VARANO V, BERRETTI S, et al. Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, USA, 2013: 479–485. [60] WEI Ping, ZHAO Yibiao, ZHENG Nanning, et al. Modeling 4D human-object interactions for event and object recognition[C]. 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 2013: 3272–3279. [61] YU Gang, LIU Zicheng, and YUAN Junsong. Discriminative orderlet mining for real-time recognition of human-object interaction[C]. The Asian Conference on Computer Vision, Singapore, 2014: 50–65. doi: 10.1007/978-3-319-16814-2_4. [62] WANG Jiang, NIE Xiaohan, XIA Yin, et al. Cross-view action modeling, learning, and recognition[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2649–2656. doi: 10.1109/CVPR.2014.339. [63] RAHMANI H, MAHMOOD A, HUYNH D Q, et al. HOPC: Histogram of oriented principal components of 3D pointclouds for action recognition[C]. The European Conference on Computer Vision, Zurich, Switzerland, 2014: 742–757. doi: 10.1007/978-3-319-10605-2_48. [64] CHEN Chen, JAFARI R, and KEHTARNAVAZ N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor[C]. 2015 IEEE International Conference on Image Processing, Quebec, Canada, 2015: 168–172. [65] HU Jianfang, ZHENG Weishi, LAI Jianhuang, et al. Jointly learning heterogeneous features for RGB-D activity recognition[C]. 2015 IEEE conference on Computer Vision and Pattern Recognition, Boston, America, 2015: 5344–5352. [66] RAHMANI H, MAHMOOD A, HUYNH D, et al. Histogram of oriented principal components for cross-view action recognition[J]. IEEE transactions on Pattern Analysis and Machine Intelligence, 2016, 38(12): 2430–2443. doi: 10.1109/TPAMI.2016.2533389 [67] XU Ning, LIU Anan, NIE Weizhi, et al. Multi-modal & multi-view & interactive benchmark dataset for human action recognition[C]. The 23rd ACM International Conference on Multimedia, Brisbane, Australia, 2015: 1195–1198. [68] KAY W, CARREIRA J, SIMONYAN K, et al. The kinetics human action video dataset[J]. arXiv preprint arXiv: 1705.06950, 2017. [69] LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873 [70] MARSZALEK M, LAPTEV I, and SCHMID C. Actions in context[C]. 2019 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 2391–2396. doi: 10.1109/CVPR.2009.5206557. [71] KUEHNE H, JUANG H, GARROTE E, et al. HMDB: A large video database for human motion recognition[C]. 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2556-2563. doi:10.1007/978-3-642-33374-3_41 . [72] CAO Zhe, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 7291–7299. doi: 10.1109/CVPR.2017.143. [73] SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[J]. arXiv preprint arXiv: 1212.0402, 2012. [74] HAN Jungong, SHAO Ling, XU Dong, et al. Enhanced computer vision with microsoft kinect sensor: A review[J]. IEEE Transactions on Cybernetics, 2013, 43(5): 1318–1334. doi: 10.1109/TCYB.2013.2265378 -

 下载:
下载:






图(10) / 表(6)
计量
- 文章访问数: 3311
- HTML全文浏览量: 1903
- PDF下载量: 492
- 被引次数: 0
