

Twice Labels Number Estimation Algorithm Based on Gaussian Fitting and Chebyshev Inequality
-
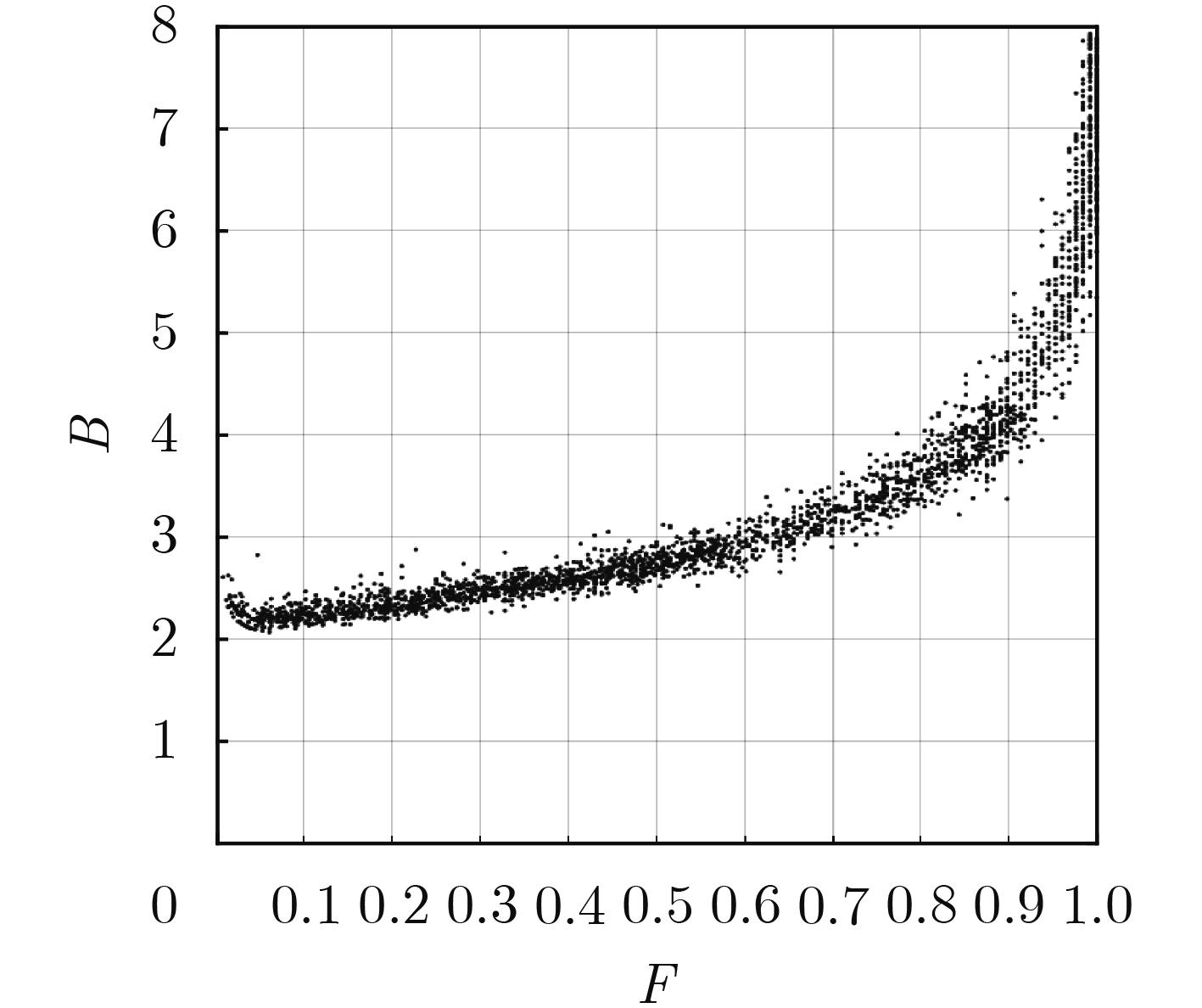
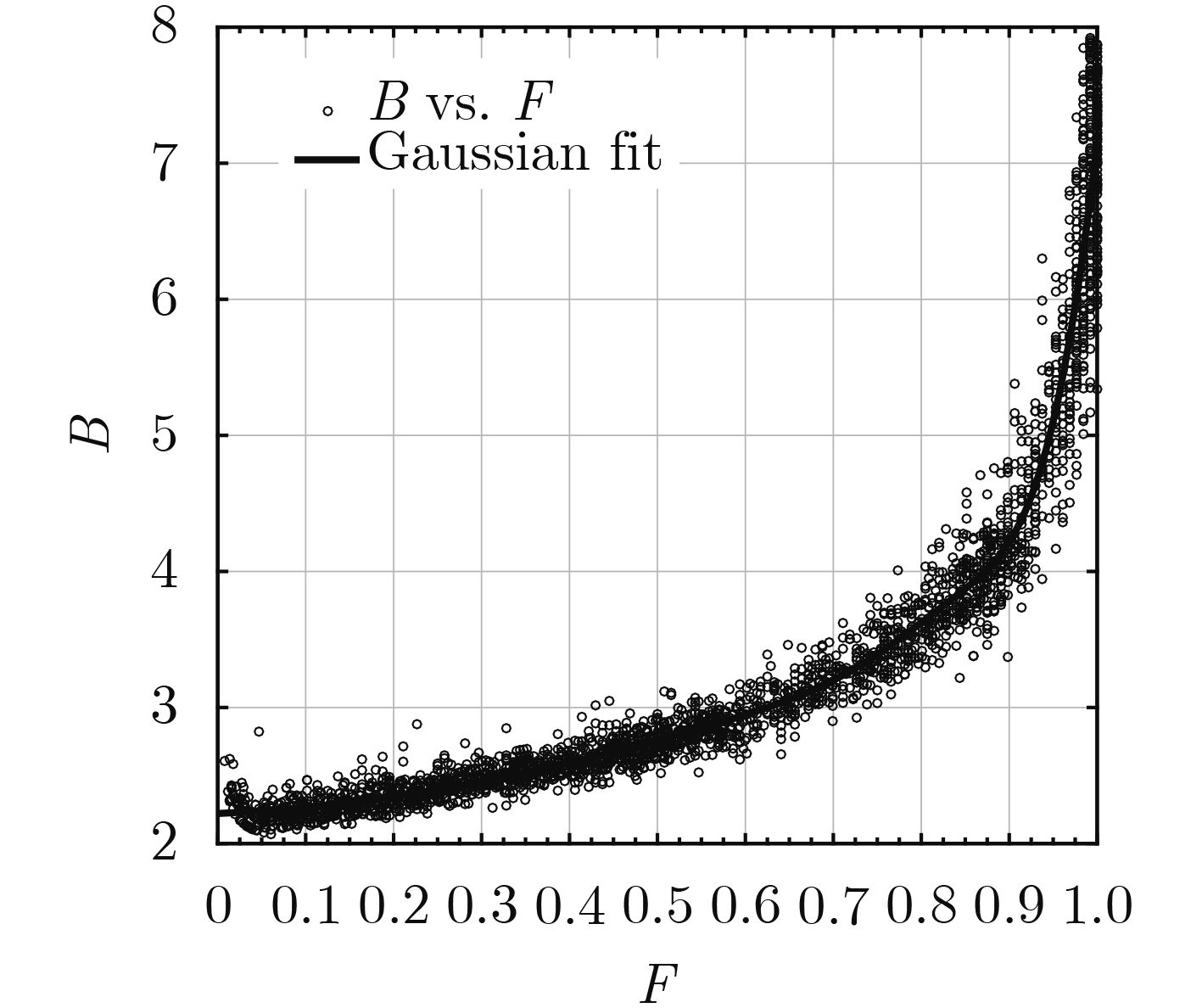
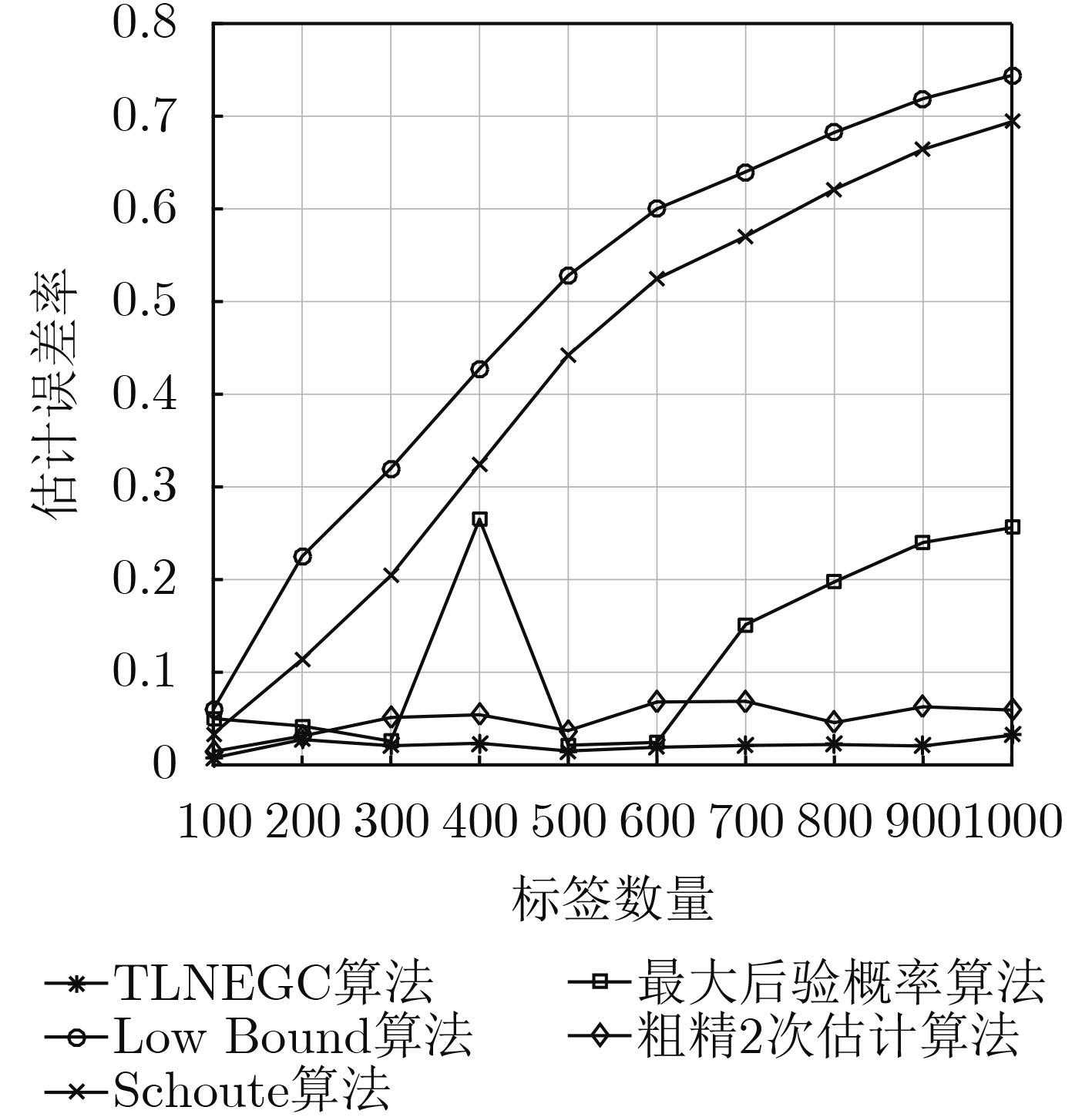
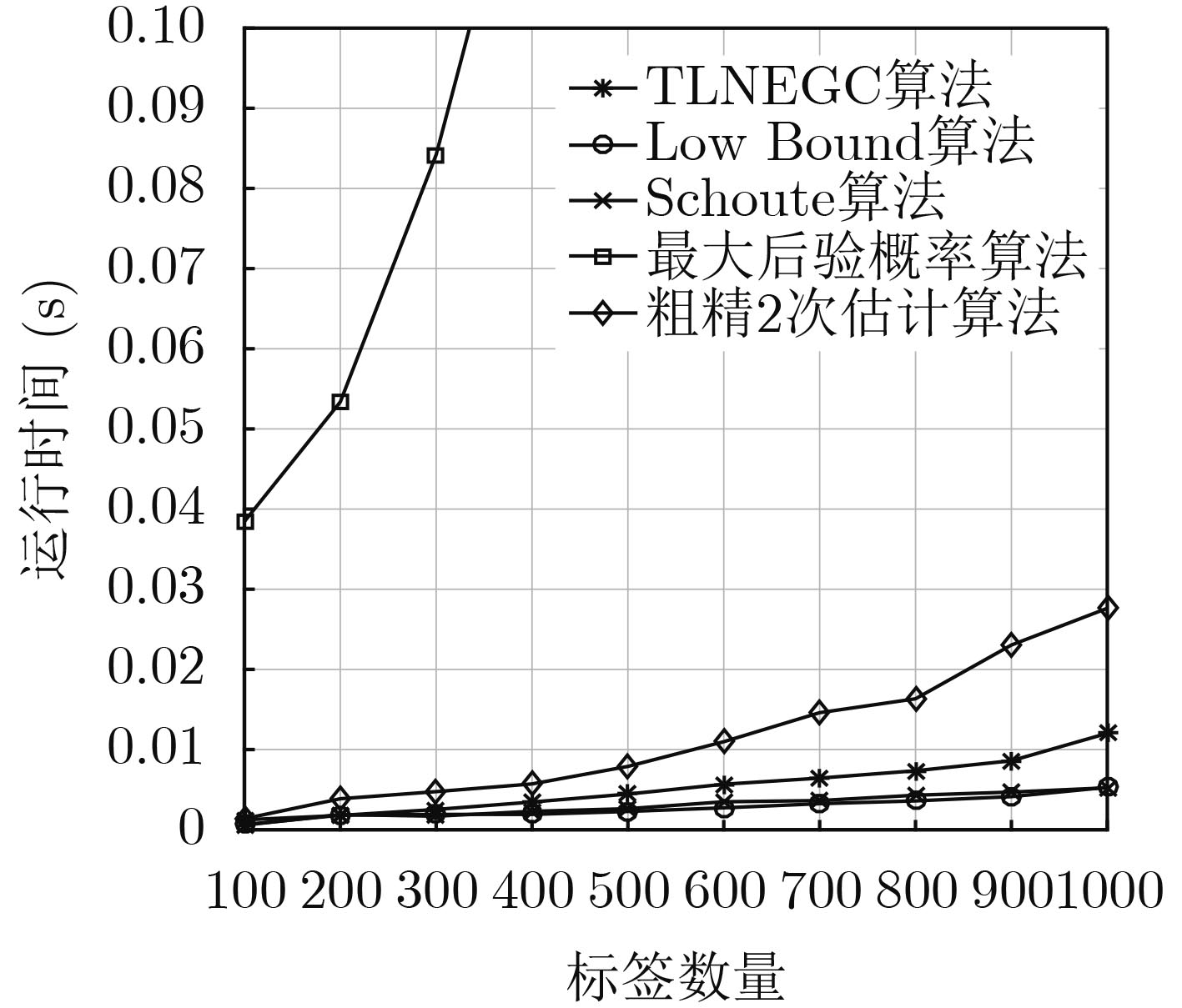
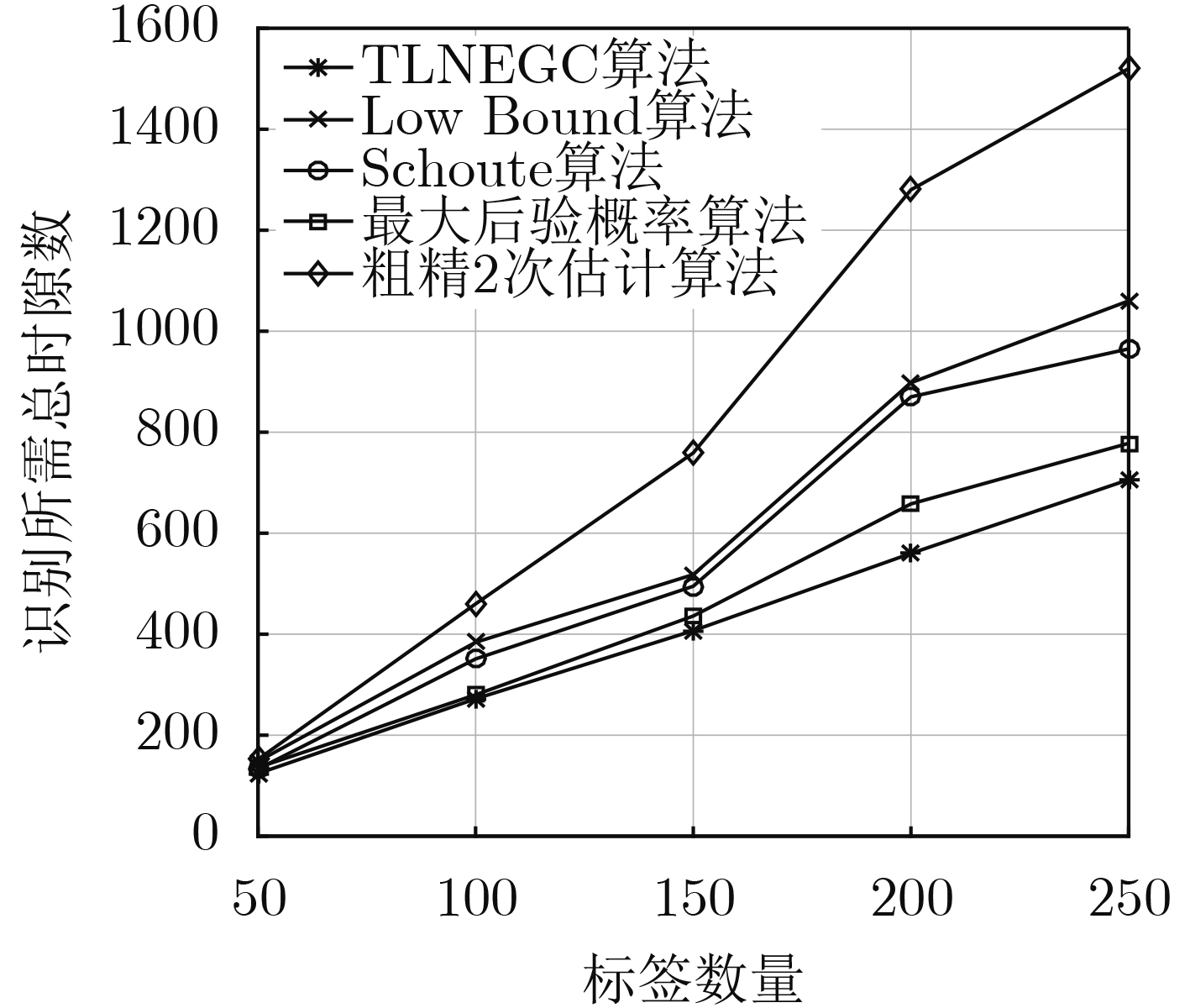
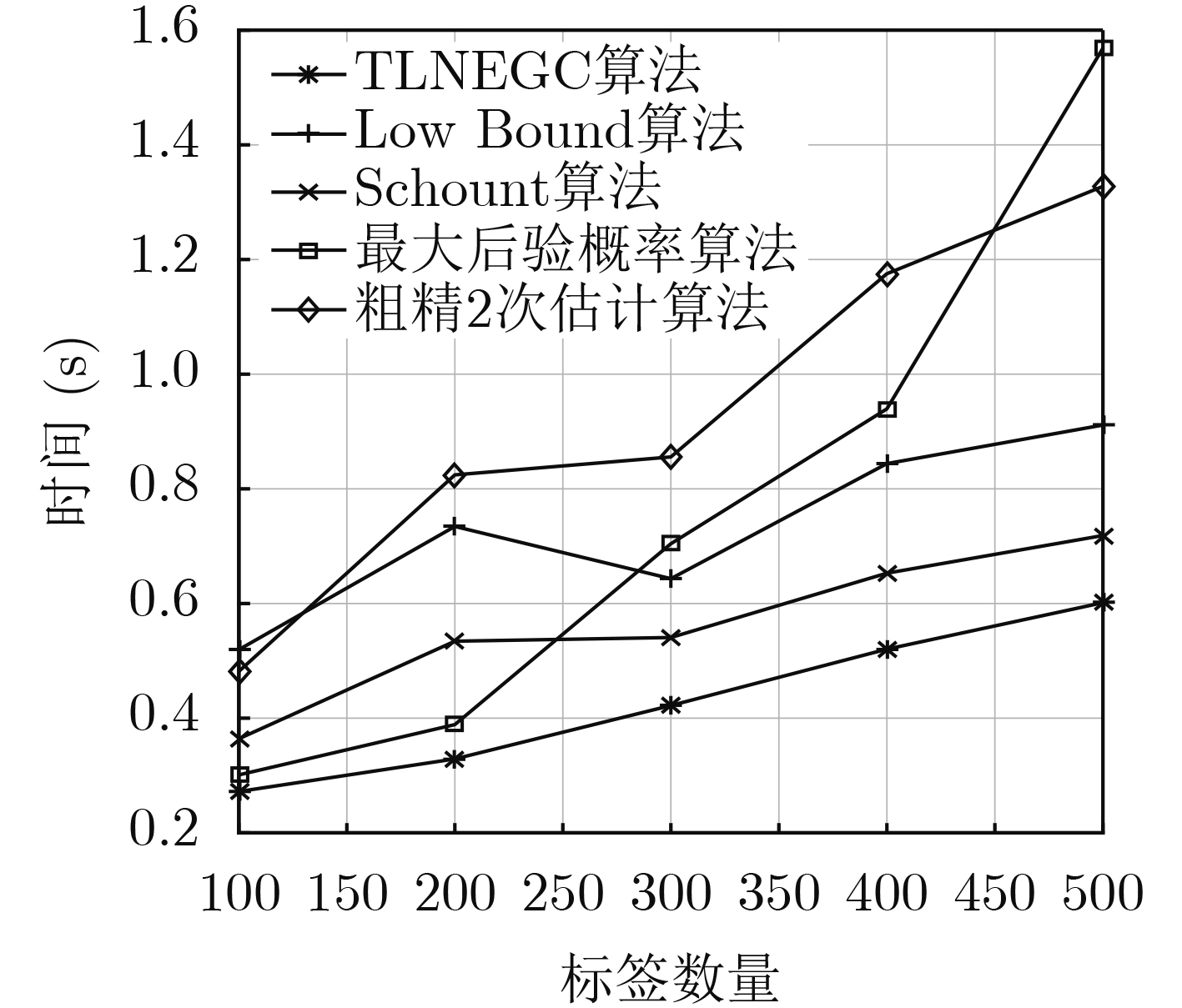
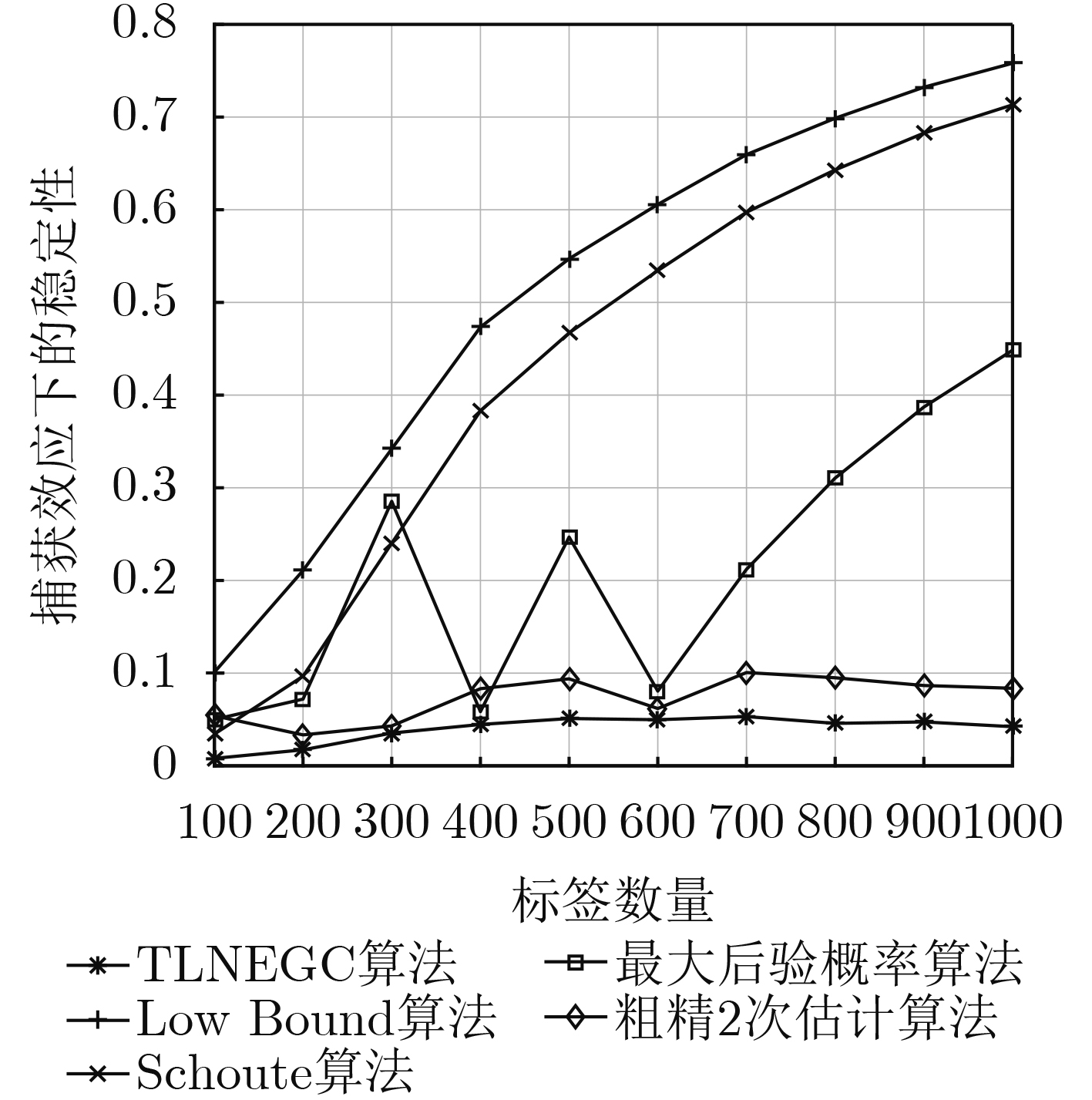
摘要: 针对射频识别技术(RFID)系统中现有标签数量估计算法存在的估计误差大、识别时延长、时间复杂度高的问题,该文提出一种基于高斯拟合与切比雪夫不等式的标签数量2次估计算法(TLNEGC)。首先根据碰撞因子与碰撞时隙比例的关系建立碰撞模型,采用高斯函数对碰撞模型中的离散数据点进行拟合逼近获得高斯估计模型;然后利用高斯估计模型初次估计标签的数量,根据初次估计的结果判断是否需要进行2次估计,2次估计是利用切比雪夫不等式对估计区间进行2次搜索以获得最佳估计值。MATLAB仿真分析表明,该文所提TLNEGC算法的平均估计误差和总时间消耗明显低于现有的高精度标签估计算法,同时具有较低的时间复杂度和较高的稳定性。Abstract: In order to solve the problems of large estimation error, prolonged identification and high time complexity, which exist in tag quantity estimation algorithm in Radio Frequency IDentification (RFID) system, The Twice Labels Number Estimation algorithm based on Gaussian fitting and Chebyshev inequality (TLNEGC) is proposed. Firstly, a collision model is established based on the relationship between the collision factor and the collision time slot ratio, and a Gaussian estimation model is obtained by fitting the Gaussian function to the discrete data points. Afterward, the Gaussian estimation model is used to initially estimate the number of labels, and then according to the results of the initial estimation, judge whether a second estimation is required. The second estimation is performed by using Chebyshev's inequality to search the estimation interval twice to obtain the best estimate. The MATLAB simulation analysis indicates that the average estimation error and total time consumption of the TLNEGC algorithm are significantly lower than those of existing high-precision label estimation algorithms, and it also has lower time complexity and higher stability.
-
表 1 TLNEGC的算法流程
(1) Initialization $L$ (2) Read ${{ESC}}$ (3) $F \leftarrow C/L$ (4) $B \leftarrow {\rm{Gaussian}}(F)$ (5) ${N_{\rm{e}}} \leftarrow S{ + }B C$ (6) If $N_{\rm{e} } < L_{\rm{then} }$ (7) Output ${N_{\rm{e}}}$ (8) Else if (9) Initialization $L = {N_{\rm{e}}}$ (10) For $i$ from $0.94N$ to $1.06N$ (11) ${c_{\rm{e}}} \leftarrow L{(1 - 1/L)^{{{{N}}_{\rm{e}}}}}$ (12) ${c_{\rm{s}}} \leftarrow N{(1 - 1/L)^{{{{N}}_{\rm{e}}} - 1}}$ (13) ${c_{\rm{c}}} \leftarrow L - {c_{\rm{e}}} - {c_{\rm{s}}}$
(14) Output $D(L,{c}_{{\rm{e}}},{c}_{{\rm{s}}},\;{c}_{{\rm{c}}})\leftarrow \underset{\varDelta ;n}{{\rm{Arg}}\mathrm{min} }\left|[E,S,C]-\right.$
$\left.{c}_{{\rm{e}}},{c}_{{\rm{s}}},\;{c}_{{\rm{c}}} \right|$(15) End for (16) End if  下载: 导出CSV
下载: 导出CSV
-
[1] KHADKA G, AREFIN M S, and KARMAKAR N C. Using Punctured Convolution Coding (PCC) for error correction in chipless RFID tag measurement[J]. IEEE Microwave and Wireless Components Letters, 2020, 30(7): 701–704. doi: 10.1109/LMWC.2020.2994189 [2] BUFFI A, MOTRONI A, NEPA P, et al. A SAR-based measurement method for passive-tag positioning with a flying UHF-RFID reader[J]. IEEE Transactions on Instrumentation and Measurement, 2019, 68(3): 845–853. doi: 10.1109/TIM.2018.2857045 [3] 袁莉芬, 杜余庆, 何怡刚, 等. 可并行识别的分组动态帧时隙ALOHA标签防碰撞算法[J]. 电子与信息学报, 2018, 40(4): 944–950. doi: 10.11999/JEIT170654YUAN Lifen, DU Yuqing, HE Yigang, et al. Grouped dynamic frame slotted ALOHA tag anti-collision algorithm based on parallelizable identification[J]. Journal of Electronics &Information Technology, 2018, 40(4): 944–950. doi: 10.11999/JEIT170654 [4] BABICH F and COMISSO M. Impact of segmentation and capture on slotted aloha systems exploiting interference cancellation[J]. IEEE Transactions on Vehicular Technology, 2019, 68(3): 2878–2892. doi: 10.1109/TVT.2019.2894705 [5] JIA Dia, FEI Zesong, and ZHANG Yasheng. Irregular repetition slotted ALOHA with total transmit power limitation[J]. Information Sciences, 2019, 64(2): 129301. doi: 10.1007/s11432-019-2728-x [6] FERREIRA H P A, ASSIS F M, and SERRES A R. Novel RFID method for faster convergence of tag estimation on dynamic frame size ALOHA algorithms[J]. IET Communications, 2019, 13(9): 1218–1224. doi: 10.1049/iet-com.2018.5506 [7] NGUYEN C T, NGUYEN V D, and PHAM A T. Tag cardinality estimation using expectation-maximization in ALOHA-Based RFID systems with capture effect and detection error[J]. IEEE Wireless Communications Letters, 2019, 8(2): 636–639. doi: 10.1109/LWC.2018.2890650 [8] 席雯. 捕获效应下RFID防碰撞算法的研究与应用[D]. [硕士论文], 北京交通大学, 2018.XI Wen. Research and application of RFID anti-collision algorithm coping with capture effect[D]. [Master dissertation], Beijing Jiaotong University, 2018. [9] WANG Zuliang, ZHANG Ting, FAN Linyan, et al. Dynamic frame-slotted ALOHA anti-collision algorithm in RFID based on non-linear estimation[J]. International Journal of Electronics, 2019, 106(11): 1769–1783. doi: 10.1080/00207217.2019.1625968 [10] KUMAR D, MONDAL S, KARUPPUSWAMI S, et al. Harmonic RFID communication using conventional UHF system[J]. IEEE Journal of Radio Frequency Identification, 2019, 3(4): 227–235. doi: 10.1109/JRFID.2019.2925527 [11] ALVAREZ-NARCIANDI G, MOTRONI A, PINO M R, et al. A UHF-RFID gate control system based on a recurrent neural network[J]. IEEE Antennas and Wireless Propagation Letters, 2019, 18(11): 2330–2334. doi: 10.1109/LAWP.2019.2929416 [12] SHAHZAD M and LIU A X. Fast and accurate estimation of RFID tags[J]. IEEE/ACM Transactions on Networking, 2014, 23(1): 241–254. doi: 10.1109/TNET.2014.2298039 [13] HAMMAD M, SHAHID N, NATHIRULLA M, et al. Improved efficient RFID tag estimation scheme[J]. International Journal of Computer Applications, 2012, 47(17): 16–19. [14] CHOI S S and SANGKYUNG K. A dynamic framed slotted ALOHA algorithm using collision factor for RFID identification[J]. IEICE Transactions on Communications, 2009, E92(3): 1023–1026. doi: 10.1587/transcom.E92.B.1023 [15] VOGT H. Efficient object identification with passive RFID tags[C]. The International Conference on Pervasive Computing, Zurich, Switzerland, 2002. doi: 10.1007/3-540-45866-2_9. [16] CHEN W T. An accurate tag estimate method for improving the performance of an RFID anticollision algorithm based on dynamic frame length ALOHA[J]. IEEE Transactions on Automation Science and Engineering, 2009, 6(1): 9–15. doi: 10.1109/TASE.2008.917093 [17] 丁建立, 韩宇超, 王家亮. 基于粗精二次估计的RFID标签数目估算方法[J]. 计算机应用, 2017, 37(9): 2722–2727. doi: 10.11772/j.issn.1001-9081.2017.09.2722DING Jianli, HAN Yuchao, and WANG Jialiang. Estimation method for RFID tags based on rough and fine double estimation[J]. Journal of Computer Applications, 2017, 37(9): 2722–2727. doi: 10.11772/j.issn.1001-9081.2017.09.2722 [18] 钟兆根, 于柯远, 孙雪丽. 基于序贯蒙特卡罗的非同步长码DS-CDMA信号扩频码及信息序列联合估计[J]. 电子与信息学报, 2019, 41(6): 1365–1373. doi: 10.11999/JEIT180157ZHONG Zhaogen, YU Keyuan, and SUN Xueli. Joint estimation of spreading codes and information sequences for asynchronous long code DS-CDMA signals based on sequential monte carlo[J]. Journal of Electronics &Information Technology, 2019, 41(6): 1365–1373. doi: 10.11999/JEIT180157 -

 下载:
下载:


图(7) / 表(1)
计量
- 文章访问数: 1329
- HTML全文浏览量: 661
- PDF下载量: 50
- 被引次数: 0
