

An Ensembling One-class Classification Method Based on Beta Process Max-margin One-class Classifier
-
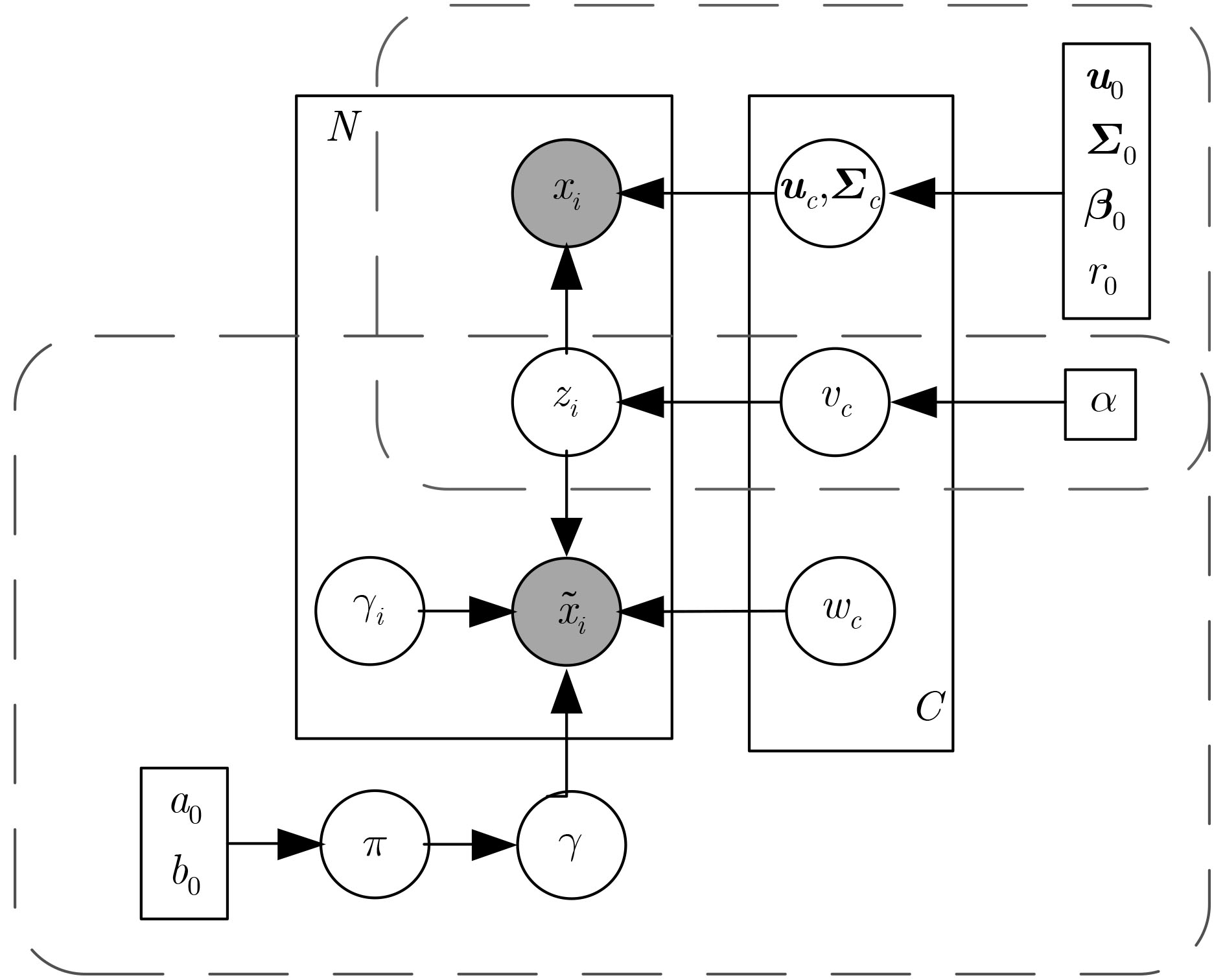
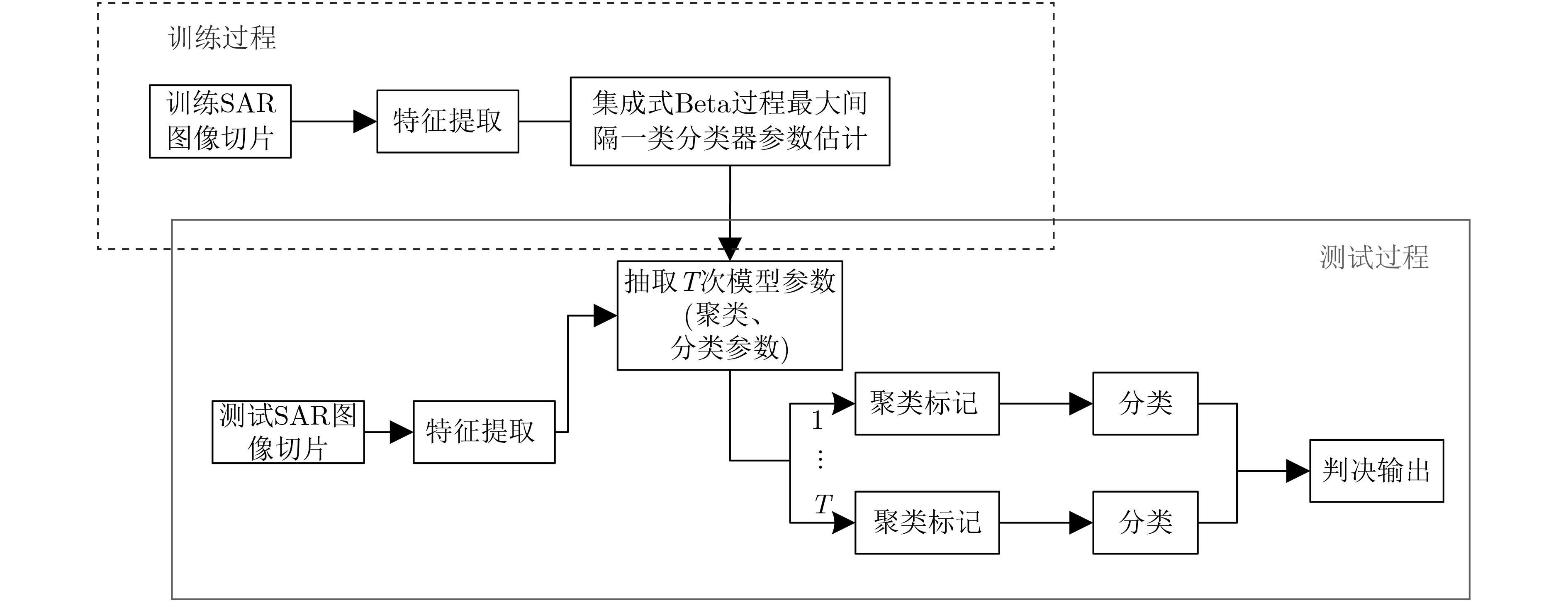
摘要: 一类分类是一种将目标类样本和其他所有的非目标类样本区分开的分类方法。传统的一类分类方法针对所有训练样本建立一个分类器,忽视了数据的内在结构,在样本分布复杂时,其分类性能会严重下降。为了提升复杂分布情况下的分类性能,该文提出一种集成式Beta过程最大间隔一类方法。该方法利用Dirichlet过程混合模型(DPM)对训练样本聚类,同时在每一个聚类学习一个Beta过程最大间隔一类分类器。通过多个分类器的集成,可以构造出一个描述能力更强的分类器,提升复杂分布下的分类效果。DPM聚类模型和Beta过程最大间隔一类分类器在同一个贝叶斯框架下联合优化,保证了每一个聚类样本的可分性。此外,在Beta过程最大间隔一类分类器中,加入了服从Beta过程先验分布的特征选择因子,从而可以降低特征冗余度以及提升分类效果。基于仿真数据、公共数据集和实测SAR图像数据的实验结果证明了所提方法的有效性。
-
关键词:
- 雷达信号处理 /
- 一类分类 /
- Dirichlet过程 /
- Beta过程
Abstract: In the problem of one-class classification, One-Class Classifier (OCC) tries to identify samples of a specific class, called the target class, among samples of all other classes. Traditional one-class classification methods design a classifier using all training samples and ignore the underlying structure of the data, thus their classification performance will be seriously degraded when dealing with complex distributed data. To overcome this problem, an ensembling one-class classification method based on Beta process max-margin one-class classifier is proposed in this paper. In the method, the input data is partitioned into several clusters with the Dirichlet Process Mixture (DPM), and a Beta Process Max-Margin One-Class Classifier (BPMMOCC) is learned in each cluster. With the ensemble of some simple classifiers, the complex nonlinear classification can be implemented to enhance the classification performance. Specifically, the DPM and BPMMOCC are jointly learned in a unified Bayesian frame to guarantee the separability in each cluster. Moreover, in BPMMOCC, a feature selection factor, which obeys the prior distribution of Beta process, is added to reduce feature redundancy and improve classification results. Experimental results based on synthetic data, benchmark datasets and Synthetic Aperture Radar (SAR) real data demonstrate the effectiveness of the proposed method. -
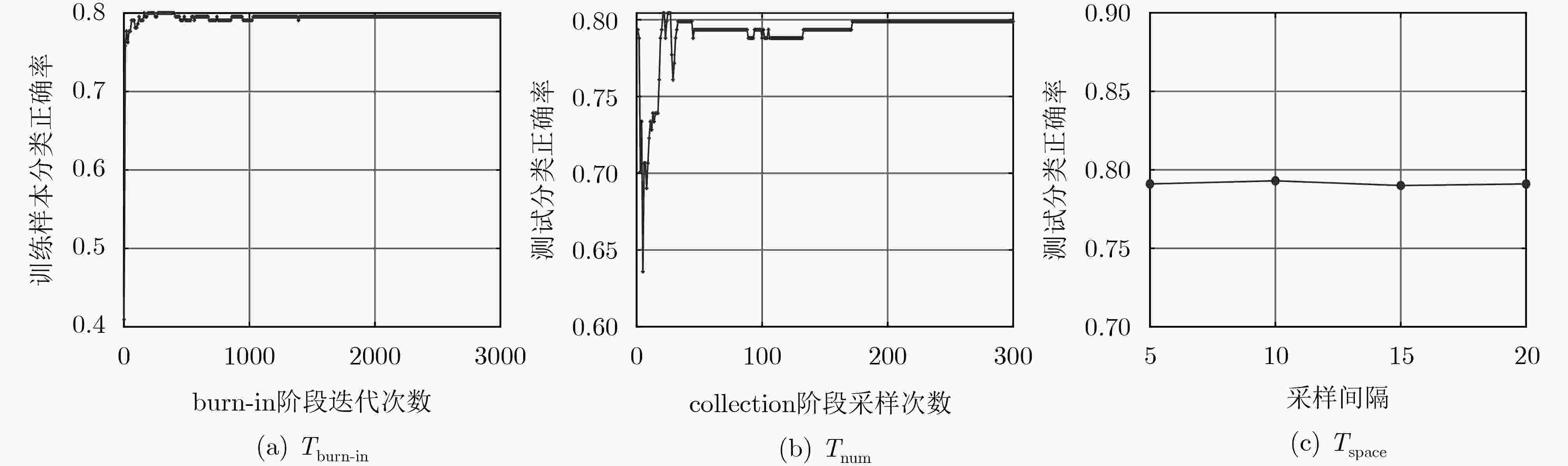
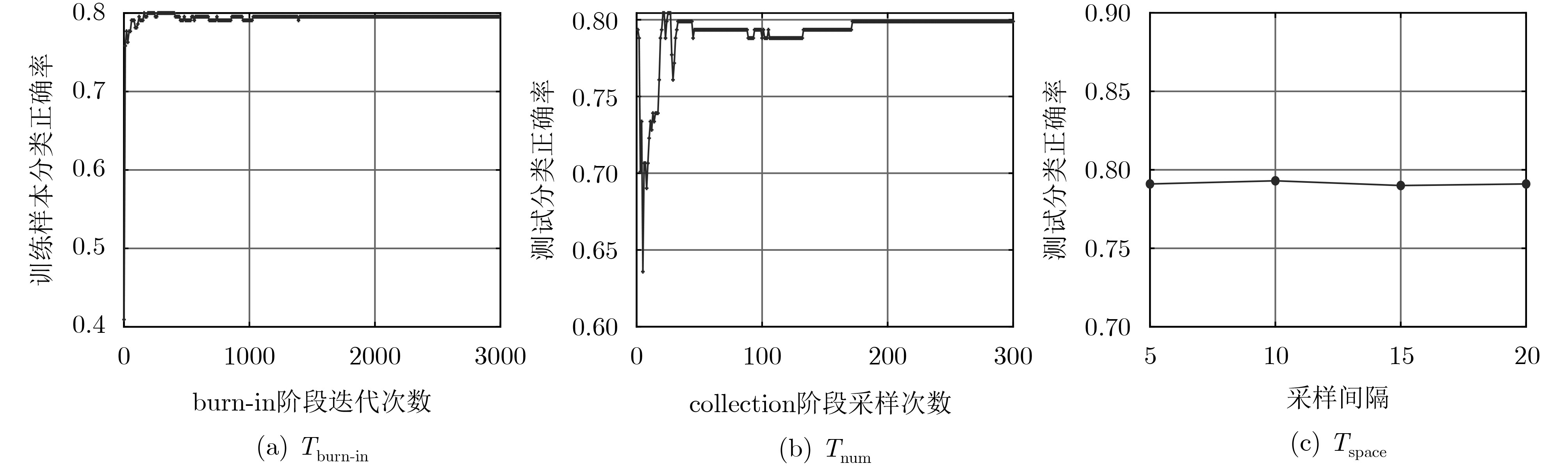
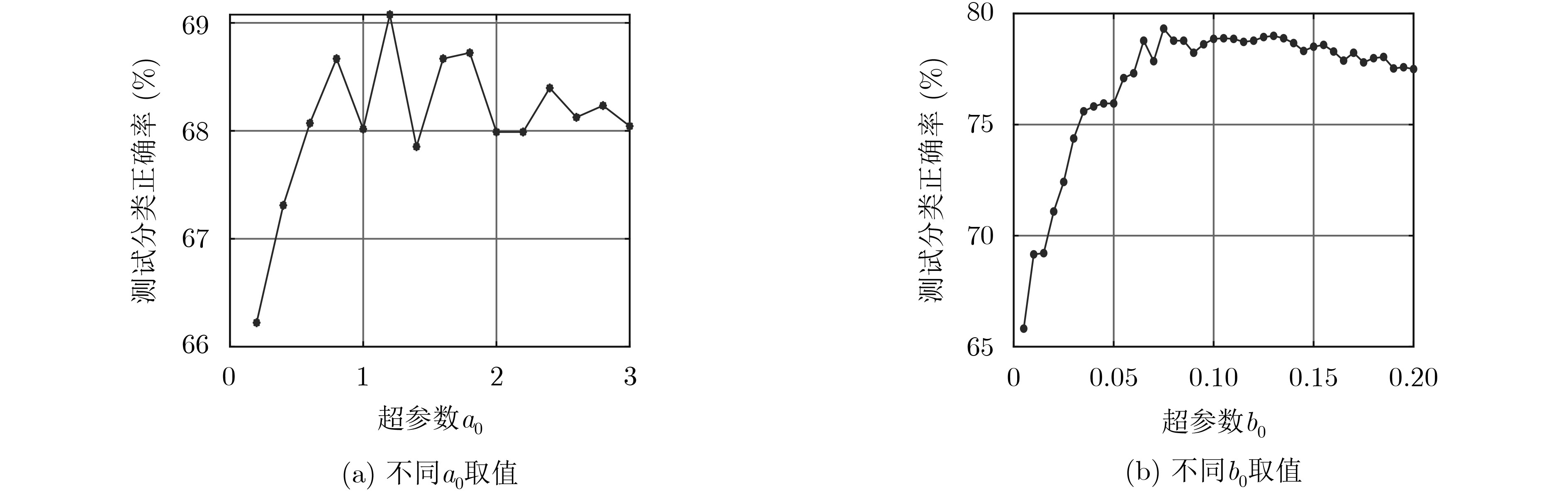
图 6 Australia数据集上分类正确率随超参数
${T_{{\rm{burn - in}}}}$ ,${T_{{\rm{num}}}}$ 和${T_{{\rm{space}}}}$ 的变化曲线图表 1 实验所用公共数据集介绍
数据集 类别数 目标类别 特征维度 训练样本数 测试目标样本数 测试非目标样本数 Australia 2 1 14 215 92 92 Landsat 6 4, 5, 6 36 500 418 1082 Waveform 3 1, 2 21 331 1652 1696 Pageblocks 5 1 10 2456 2457 560  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在Waveform数据集上的3个指标平均值(%)
指标 L-SVDD KOCSVM K-means PCA MST SOM AE MPM LPDD En-MMOCC 本文方法 准确率 57.05 64.14 66.94 55.26 61.19 67.74 58.00 72.44 74.25 75.92 77.22 F1分数 67.12 59.94 71.92 66.18 70.70 68.30 56.40 65.66 71.02 74.12 75.11 AUC 71.19 69.63 76.71 59.50 73.57 73.83 61.26 83.98 82.01 83.67 85.00
下载: 导出CSV
表 3 不同方法在Landsat数据集上的3个指标平均值 (%)
指标 L-SVDD KOCSVM K-means PCA MST SOM AE MPM LPDD En-MMOCC 本文方法 准确率 79.72 85.98 82.40 71.28 73.26 80.06 86.01 85.04 86.92 88.06 90.30 F1分数 71.25 73.25 73.76 63.27 65.86 70.29 71.84 69.95 74.54 77.87 81.79 AUC 91.54 90.88 92.72 80.11 87.25 87.76 92.35 89.96 91.69 92.21 94.18
下载: 导出CSV
表 4 不同方法在Australia数据集上的3个指标平均值 (%)
指标 L-SVDD KOCSVM K-means PCA MST SOM AE MPM LPDD En-MMOCC 本文方法 准确率 55.41 70.76 69.29 66.06 56.41 61.14 78.61 81.90 67.99 81.41 82.21 F1分数 66.67 67.44 74.69 72.13 67.99 67.33 77.65 75.18 67.54 80.36 81.71 AUC 74.42 73.84 82.53 78.32 66.23 67.84 83.14 80.73 71.73 82.57 84.16
下载: 导出CSV
表 5 不同方法在Pageblocks数据集上的3个指标平均值 (%)
指标 L-SVDD KOCSVM K-means PCA MST SOM AE MPM LPDD En-MMOCC 本文方法 准确率 89.63 90.69 90.06 89.23 90.19 89.79 90.06 87.74 90.09 91.05 92.21 F1分数 93.36 93.91 93.73 93.17 93.95 93.50 93.67 94.17 93.72 94.15 95.22 AUC 95.69 95.99 95.73 94.68 90.02 95.84 95.69 96.00 95.22 94.99 96.03
下载: 导出CSV
表 6 不同方法在实测SAR数据集上的3个指标平均值 (%)
指标 L-SVDD KOCSVM K-means PCA MST SOM AE MPM LPDD En-MMOCC 本文方法 准确率 82.14 84.72 84.82 73.83 84.13 80.23 83.42 84.67 83.24 85.77 86.12 F1分数 85.05 87.86 86.97 79.11 87.05 82.31 85.98 86.85 85.11 88.00 88.52 AUC 87.30 88.18 88.46 77.99 89.08 89.05 87.65 89.08 88.36 88.35 89.59
下载: 导出CSV
表 7 不同一类分类方法所需的计算时间(s)
数据集 L-SVDD KOCSVM K-means PCA MST SOM AE MPM LPDD 本文方法 Australia 训练 0.510 0.828 0.290 0.448 0.489 23.086 21.011 0.347 1.122 37.432 测试 0.097 0.252 0.024 0.013 0.049 0.023 0.277 0.026 0.187 0.535 Landsat 训练 1.572 1.822 0.363 0.512 2.934 122.611 530.921 1.176 10.177 531.735 测试 0.411 0.513 0.120 0.100 3.349 0.109 22.362 0.232 7.452 5.323
下载: 导出CSV
-
[1] TAX D M J. One-class classification: Concept-learning in the absence of counter-examples[D]. [Ph. D. dissertation], Delft University of Technology, 2001: 13–19. [2] 王布宏, 罗鹏, 李腾耀, 等. 基于粒子群优化多核支持向量数据描述的广播式自动相关监视异常数据检测模型[J]. 电子与信息学报, 2020, 42(11): 2727–2734. doi: 10.11999/JEIT190767WANG Buhong, LUO Peng, LI Tengyao, et al. ADS-B anomalous data detection model based on PSO-MKSVDD[J]. Journal of Electronics &Information Technology, 2020, 42(11): 2727–2734. doi: 10.11999/JEIT190767 [3] 王宝帅, 兰竹, 李正杰, 等. 毫米波雷达机场跑道异物分层检测算法[J]. 电子与信息学报, 2018, 40(11): 2676–2683. doi: 10.11999/JEIT180200WANG Baoshuai, LAN Zhu, LI Zhengjie, et al. A hierarchical foreign object debris detection method using millimeter wave radar[J]. Journal of Electronics &Information Technology, 2018, 40(11): 2676–2683. doi: 10.11999/JEIT180200 [4] 董书琴, 张斌. 基于深度特征学习的网络流量异常检测方法[J]. 电子与信息学报, 2020, 42(3): 695–703. doi: 10.11999/JEIT190266DONG Shuqin and ZHANG Bin. Network traffic anomaly detection method based on deep features learning[J]. Journal of Electronics &Information Technology, 2020, 42(3): 695–703. doi: 10.11999/JEIT190266 [5] 陈莹, 何丹丹. 基于贝叶斯融合的时空流异常行为检测模型[J]. 电子与信息学报, 2019, 41(5): 1137–1144. doi: 10.11999/JEIT180429CHEN Ying, HE Dandan. Spatial-temporal stream anomaly detection based on Bayesian fusion[J]. Journal of Electronics &Information Technology, 2019, 41(5): 1137–1144. doi: 10.11999/JEIT180429 [6] 王威丽, 陈前斌, 唐伦. 虚拟网络切片中的在线异常检测算法研究[J]. 电子与信息学报, 2020, 42(6): 1460–1467. doi: 10.11999/JEIT190531WANG Weili, CHEN Qianbin, and TANG Lun. Online anomaly detection for virtualized network slicing[J]. Journal of Electronics &Information Technology, 2020, 42(6): 1460–1467. doi: 10.11999/JEIT190531 [7] 孟令博, 耿修瑞. 基于协峭度张量的高光谱图像异常检测[J]. 电子与信息学报, 2019, 41(1): 150–155. doi: 10.11999/JEIT180280MENG Lingbo and GENG Xiurui. A hyperspectral imagery anomaly detection algorithm based on cokurtosis tensor[J]. Journal of Electronics &Information Technology, 2019, 41(1): 150–155. doi: 10.11999/JEIT180280 [8] PIMENTEL M A F, CLIFTON D A, CLIFTON L, et al. A review of novelty detection[J]. Signal Processing, 2014, 99: 215–249. doi: 10.1016/j.sigpro.2013.12.026 [9] LAMPARIELLO F and SCIANDRONE M. Efficient training of RBF neural networks for pattern recognition[J]. IEEE Transactions on Neural Networks, 2001, 12(5): 1235–1242. doi: 10.1109/72.950152 [10] SCHOLKOPF B and SMOLA A J. Learning with Kernels[M]. Cambridge: MIT Press, 2001: 469–513. [11] TAX D M J and DUIN R P W. Support vector domain description[J]. Pattern Recognition Letters, 1999, 20(11/13): 1191–1199. doi: 10.1016/s0167-8655(99)00087-2 [12] FERGUSON T S. A Bayesian analysis of some nonparametric problems[J]. Annals of Statistics, 1973, 1(2): 209–230. doi: 10.1214/aos/1176342360 [13] BLEI D M and JORDAN M I. Variational inference for Dirichlet process mixtures[J]. Bayesian Analysis, 2006, 1(1): 121–143. doi: 10.1214/06-BA104 [14] SOLLICH P. Bayesian methods for support vector machines: Evidence and predictive class probabilities[J]. Machine Learning, 2002, 46(1–3): 21–52. doi: 10.1023/a:1012489924661 [15] POLSON N G and SCOTT S L. Data augmentation for support vector machines[J]. Bayesian Analysis, 2011, 6(1): 1–23. doi: 10.1214/11-BA601 [16] GEMAN S and GEMAN D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1984, PAMI-6(6): 721–741. doi: 10.1109/TPAMI.1984.4767596 [17] WOLD S, ESBENSEN K, and GELADI P. Principal component analysis[J]. Chemometrics and Intelligent Laboratory Systems, 1987, 2(1/3): 37–52. doi: 10.1016/0169-7439(87)80084-9 [18] JUSZCZAK P, TAX D M J, PE¸KALSKA E, et al. Minimum spanning tree based one-class classifier[J]. Neurocomputing, 2009, 72(7/9): 1859–1869. doi: 10.1016/j.neucom.2008.05.003 [19] KOHONEN T and SOMERVUO P. Self-organizing maps of symbol strings[J]. Neurocomputing, 1998, 21(1/3): 19–30. doi: 10.1016/s0925-2312(98)00031-9 [20] LANCKRIET G R G, EL GHAOUI L, and JORDAN M I. Robust novelty detection with single-class MPM[C]. The 15th International Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, 2002: 929–936. [21] PĘKALSKA E, TAX D M J, and DUIN R P W. One-class LP classifier for dissimilarity representations[C]. Proceedings of the 15th International Conference on Neural Information Processing Systems, British Columbia, Canada, 2002: 777–784. [22] DUNSON D B and PARK J H. Kernel stick-breaking processes[J]. Biometrika, 2008, 95(2): 307–323. doi: 10.1093/biomet/asn012 [23] KRUSCHKE J K. Bayesian data analysis[J]. Wiley Interdisciplinary Reviews: Cognitive Science, 2010, 1(5): 658–676. doi: 10.1002/wcs.72 -

 下载:
下载:








图(8) / 表(7)
计量
- 文章访问数: 1194
- HTML全文浏览量: 756
- PDF下载量: 57
- 被引次数: 0
