

Heterogeneous Information Network Representation Learning Framework Based on Graph Attention Network
-
摘要: 常用的异质信息网络有知识图谱和具有简单模式层的异质信息网络,它们的表示学习通常遵循不同的方法。该文总结了知识图谱和具有简单模式层的异质信息网络之间的异同,提出了一个通用的异质信息网络表示学习框架。该文提出的框架可以分为3个部分:基础向量模型,基于图注意力网络的传播模型以及任务模型。基础向量模型用于学习基础的网络向量;传播模型通过堆叠注意力层学习网络的高阶邻居特征;可更换的任务模型适用于不同的应用场景。与基准模型相比,该文所提框架在知识图谱的链接预测任务和异质信息网络的节点分类任务中都取得了相对不错的效果。Abstract: Commonly used heterogeneous information networks include knowledge graphs and heterogeneous information networks with simple schemas. Their representation learning follows usually different methods. The similarities and differences between knowledge graphs and heterogeneous information networks with simple schemas are summarized, and a general heterogeneous information network representation learning framework is proposed. The proposed framework can be divided into three parts: the basic vector model, the graph attention network based propagation model, and the task model. The basic vector model is used to learn basic network vector; The propagation model learns the high-order neighbor features of the network by stacking attention layers. The replaceable task module is suitable for different application scenarios. Compared with the benchmark model, the proposed framework achieves relatively good results in the link prediction task of the knowledge graph and the node classification task of the heterogeneous information network.
-
表 1 简单模式层异质信息网络数据集的统计信息
数据集 节点 #节点 关系 #连边 #训练 #验证 #测试 DBLP Paper(P) 13769 AP
PC
PT30632
13769
867392400 400 1200 Author(A) 13941 Conference(C) 20 Term(T) 8623 IMDB Movie(M) 5473 MA
MD15814
54731800 300 900 Actor(A) 6725 Director(D) 2761  下载: 导出CSV
下载: 导出CSV
表 2 简单模式层异质信息网络的节点分类性能
数据集 指标 DeepWalk Esim Metapath2vec HAN HE-GAN-NC Variant1 Variant2 DBLP Macro-F1 83.15 92.47 91.63 92.52 94.31 92.26 94.16 Micro-F1 85.77 93.60 92.64 93.67 95.17 93.42 94.81 IMDB Macro-F1 48.34 33.89 45.13 52.29 53.58 50.35 53.11 Micro-F1 52.48 35.25 49.38 55.86 57.92 53.96 57.32
下载: 导出CSV
表 3 知识图谱的链接预测任务性能
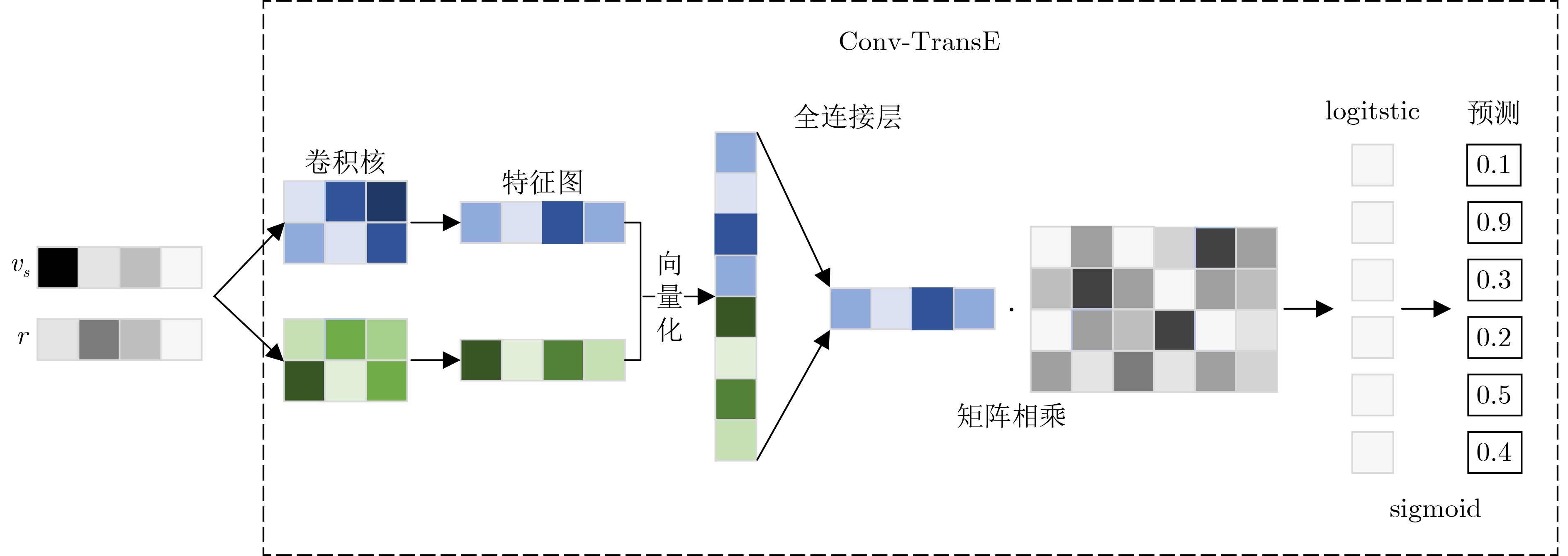
数据集 FB15k-237 WN18RR 指标 MRR Hits@1 Hits@3 Hits@10 MRR Hits@1 Hits@3 Hits@10 TransE 0.279 0.19 0.38 0.44 0.242 0.04 0.44 0.53 ConvE 0.315 0.24 0.35 0.49 0.461 0.42 0.47 0.53 ConvKB 0.285 0.19 0.32 0.47 0.263 0.06 0.45 0.55 SACN 0.352 0.26 0.39 0.54 0.463 0.43 0.48 0.54 relationPrediction 0.518 0.46 0.54 0.63 0.440 0.36 0.48 0.58 HE-GAN-LP 0.523 0.46 0.56 0.66 0.468 0.41 0.50 0.59 Variant3 0.520 0.45 0.55 0.64 0.447 0.37 0.48 0.58
下载: 导出CSV
-
SHI Chuan, LI Yitong, ZHANG Jiawei, et al. A survey of heterogeneous information network analysis[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(1): 17–37. doi: 10.1109/TKDE.2016.2598561 于洪涛, 丁悦航, 刘树新, 等. 一种基于超节点理论的本体关系消冗算法[J]. 电子与信息学报, 2019, 41(7): 1633–1640. doi: 10.11999/JEIT180793YU Hongtao, DING Yuehang, LIU Shuxin, et al. Eliminating structural redundancy based on super-node theory[J]. Journal of Electronics &Information Technology, 2019, 41(7): 1633–1640. doi: 10.11999/JEIT180793 BORDES A, USUNIER N, GARCIA-DURÁN A, et al. Translating embeddings for modeling multi-relational data[C]. The 26th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2013: 2787–2795. DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings[C]. The 32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, USA, 2018: 1811–1818. NATHANI D, CHAUHAN J, SHARMA C, et al. Learning attention-based embeddings for relation prediction in knowledge graphs[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 4710–4723. doi: 10.18653/v1/P19-1466. DONG Yuxiao, CHAWLA N V, SWAMI A, et al. Metapath2vec: Scalable representation learning for heterogeneous networks[C]. The 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA, 2017: 135–144. doi: 10.1145/3097983.3098036. WANG Xiao, JI Houye, SHI Chuan, et al. Heterogeneous graph attention network[C]. The World Wide Web Conference, San Francisco, USA, 2019: 2022–2032. doi: 10.1145/3308558.3313562. MIKOLOV T, CHEN Kai, CORRADO G, et al. Efficient estimation of word representations in vector space[C]. The 1st International Conference on Learning Representations, Scottsdale, Arizona, 2013: 1–12. SHANG Chao, TANG Yun, HUANG Jing, et al. End-to-end structure-aware convolutional networks for knowledge base completion[C]. The AAAI Conference on Artificial Intelligence, Hawaii, USA, 2019: 3060–3067. doi: 10.1609/aaai.v33i01.33013060. VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks[C]. International Conference On Learning Representations, Vancouver, Canada, 2018: 1–12. NGUYEN D Q, NGUYEN T D, NGUYEN D Q, et al. A novel embedding model for knowledge base completion based on convolutional neural network[C]. 2018 Conference of the North American Chapter of the Association for Computational Linguistics, New Orleans, USA, 2018: 327–333. doi: 10.18653/v1/N18-2053. PEROZZI B, AL-RFOU R, SKIENA S, et al. DeepWalk: Online learning of social representations[C]. The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA, 2014: 701–710. doi: 10.1145/2623330.2623732. SHANG Jingbo, QU Meng, LIU Jialu, et al. Meta-path guided embedding for similarity search in large-scale heterogeneous information networks[J]. arXiv preprint arXiv: 1610.09769v1, 2016. KINGMA D P and BA J. Adam: A method for stochastic optimization[C]. The 3rd International Conference for Learning Representations, San Diego, USA, 2015: 1–15. -


 下载:
下载:


图(2) / 表(3)
计量
- 文章访问数: 2234
- HTML全文浏览量: 1592
- PDF下载量: 220
- 被引次数: 0
