

Reconstruction of Digital Surface Model of Single-view Remote Sensing Image by Semantic Segmentation Network
-
摘要: 该文提出了一种仅依靠激光探测与测量数据,实现单视图遥感影像数字表面模型(DSM)重建的新方法。该方法基于深度学习技术设计了一种编码-解码结构的语义分割网络,该网络采用多尺度残差融合的编码块与解码(MRFED)块从输入图像中提取语义信息,进而逐像素预测高度值;采用特征图跳跃级联的策略保留输入图像的细节特征和结构信息。该文采用了一个包含DSM数据的遥感影像公开数据集训练与测试模型,实验结果表明:DSM重建结果与真值的平均绝对误差(MAE)为2.1e-02,均方根误差(RMSE)为3.8e-02,结构相似性(SSIM)为92.89%,均优于经典的深度学习语义分割网络。实验证实该方法能够有效实现单视图遥感影像的DSM重建,具有较高的精度,以及较强的地物分布结构重建能力。Abstract: A novel method for Digital Surface Model (DSM) reconstruction of single-view remote sensing image is proposed which only relies on light detection and ranging data. Based on deep learning technology, a semantic segmentation network with an encode-decode structure is designed. The network uses Multi-scale Residual Fusion Encode and Decode (MRFED) blocks to extract semantic information from the input image, and then predicts the height value pixel by pixel, as well as adopts a strategy of skip connections with feature maps to preserves the detailed features and structural information of the input image. The model is trained and tested on a public dataset of remote sensing images containing DSM data. Experiments show that, the Mean Absolute Error (MAE) between DSM reconstruction results and true values is 2.1e-02, the Root Mean Square Error (RMSE) is 3.8e-02, and the Structural SIMilarity (SSIM) is 92.89%, which are all better than the classic deep learning semantic segmentation networks. Experiments confirm that the method can effectively reconstruct the DSM of single-view remote sensing images with high accuracy, as well as the structure of feature distribution.
-
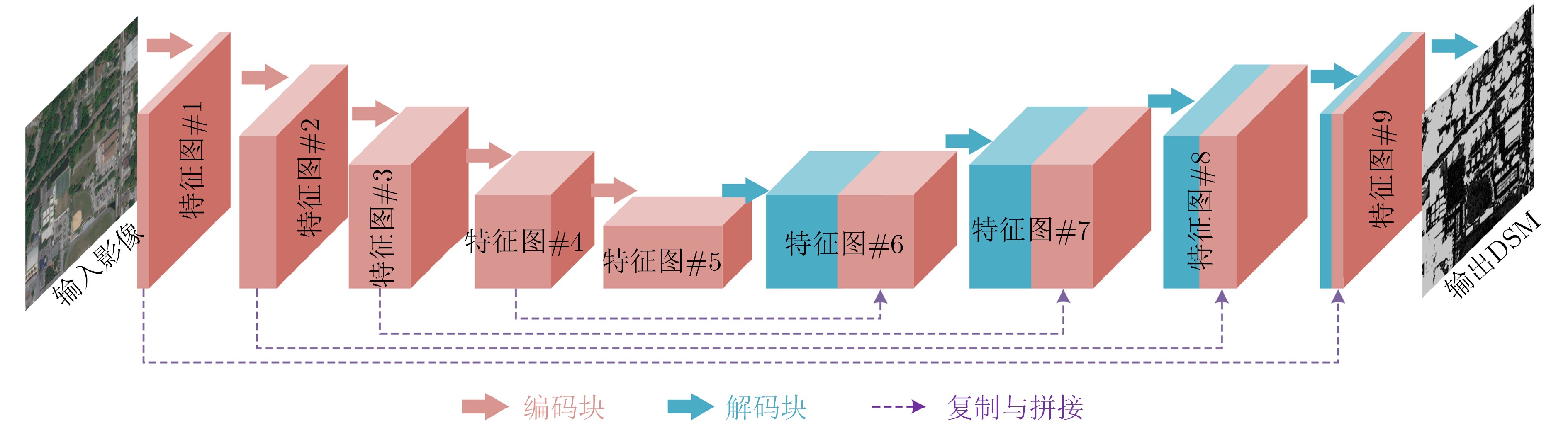
表 1 MRFED各层的特征图尺寸和通道数信息
网络层 尺寸 通道数 输入 512×512 3 特征图#1 256×256 64 特征图#2 128×128 128 特征图#3 64×64 256 特征图#4 32×32 512 特征图#5 16×16 1024 特征图#6 32×32 512×2 特征图#7 64×64 256×2 特征图#8 128×128 128×2 特征图#9 256×256 64×2 输出 512×512 1  下载: 导出CSV
下载: 导出CSV
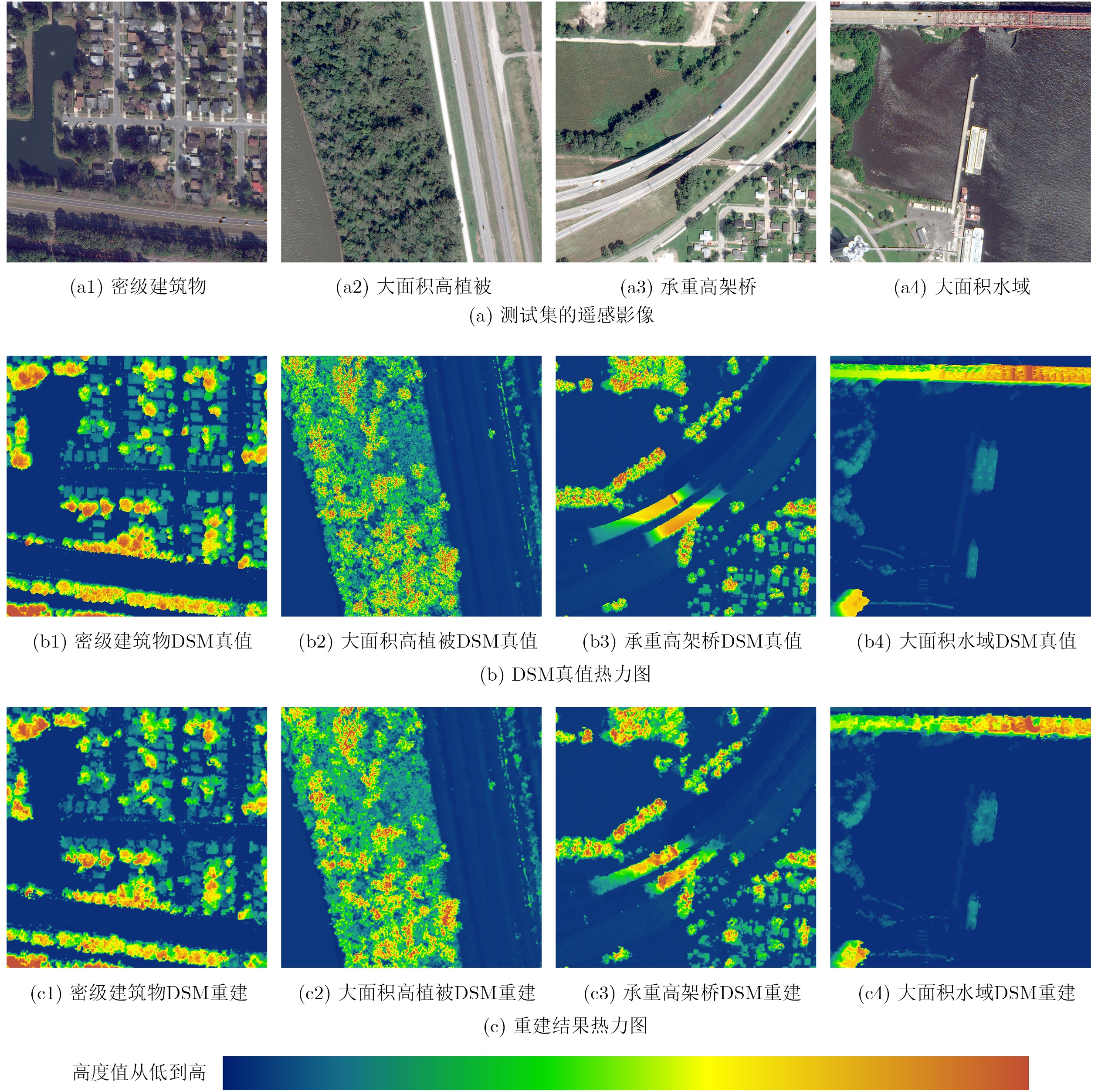
表 2 测试结果的数据指标
算法模型 主干网络 平均绝对误差 均方根误差 结构相似性 FCN VGG16 2.2e-01 4.1e-01 0.6611 U-net ResNet-50 6.9e-02 1.0e-01 0.8534 MRFE ResNet-50 3.3e-02 5.9e-02 0.8490 MRFE+跳跃级联 ResNet-50 2.1e-02 3.8e-02 0.9289
下载: 导出CSV
-
AUDEBERT N, LE SAUX B, and LEFÈVREY S. Fusion of heterogeneous data in convolutional networks for urban semantic labeling[C]. 2017 Joint Urban Remote Sensing Event, Dubai, United Arab Emirates, 2017: 1–4. doi: 10.1109/jurse.2017.7924566. QIN Rongjun, HUANG Xin, GRUEN A, et al. Object-based 3-D building change detection on multitemporal stereo images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(5): 2125–2137. doi: 10.1109/jstars.2015.2424275 QIN Rongjun, TIAN Jiaojiao, and REINARTZ P. 3D change detection–approaches and applications[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 122: 41–56. doi: 10.1016/j.isprsjprs.2016.09.013 BUADES A, COLL B, and MOREL J M. A review of image denoising algorithms, with a new one[J]. Multiscale Modeling & Simulation, 2005, 4(2): 490–530. doi: 10.1137/040616024 LIU Guilin, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 89–105. doi: 10.1007/978-3-030-01252-6_6. DONG Chao, LOY C C, HE Kaiming, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295–307. doi: 10.1109/TPAMI.2015.2439281 SHI Wenzhe, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1874–1883. doi: 10.1109/cvpr.2016.207. EIGEN D, PUHRSCH C, and FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2366–2374. EIGEN D and FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 2650–2658. doi: 10.1109/iccv.2015.304. LIU Fayao, SHEN Chunhua, LIN Guosheng, et al. Learning depth from single monocular images using deep convolutional neural fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2024–2039. doi: 10.1109/tpami.2015.2505283 SRIVASTAVA S, VOLPI M, and TUIA D. Joint height estimation and semantic labeling of monocular aerial images with CNNs[C]. 2017 IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, USA, 2017: 5173–5176. doi: 10.1109/igarss.2017.8128167. ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. The 13th European Conference on computer Vision, Zurich, Switzerland, 2014: 818–833. doi: 10.1007/978-3-319-10590-1_53. MAHENDRAN A and VEDALDI A. Understanding deep image representations by inverting them[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 5188–5196. doi: 10.1109/CVPR.2015.7299155. LONG J, SHELHAMER E, and DARRELL T. Fully convolutional networks for semantic segmentation[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3431–3440. doi: 10.1109/cvpr.2015.7298965. 杨宏宇, 王峰岩. 基于深度卷积神经网络的气象雷达噪声图像语义分割方法[J]. 电子与信息学报, 2019, 41(10): 2373–2381. doi: 10.11999/JEIT190098YANG Hongyun and WANG Fengyan. Meteorological radar noise image semantic segmentation method based on deep convolutional neural network[J]. Journal of Electronics &Information Technology, 2019, 41(10): 2373–2381. doi: 10.11999/JEIT190098 HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/cvpr.2016.90. 罗会兰, 卢飞, 孔繁胜. 基于区域与深度残差网络的图像语义分割[J]. 电子与信息学报, 2019, 41(11): 2777–2786. doi: 10.11999/JEIT190056LUO Huilan, LU Fei, and KONG Fansheng. Image semantic segmentation based on region and deep residual network[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2777–2786. doi: 10.11999/JEIT190056 ZEILER M D, TAYLOR G W, and FERGUS R. Adaptive deconvolutional networks for mid and high level feature learning[C]. 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2018–2025. doi: 10.1109/iccv.2011.6126474. GLOROT X and BENGIO Y. Understanding the difficulty of training deep feedforward neural networks[C]. The 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 2010: 249–256. SUTSKEVER I, MARTENS J, DAHL G, et al. On the importance of initialization and momentum in deep learning[C]. The 30th International Conference on Machine Learning, Atlanta, USA, 2013: 1139–1147. RONNEBERGER O, FISCHER P, and BROX T. U-net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28. -


 下载:
下载:




图(5) / 表(3)
计量
- 文章访问数: 1848
- HTML全文浏览量: 1164
- PDF下载量: 91
- 被引次数: 0
