

Multi-focus Image Fusion Algorithm Based on Super Pixel Level Convolutional Neural Network
-
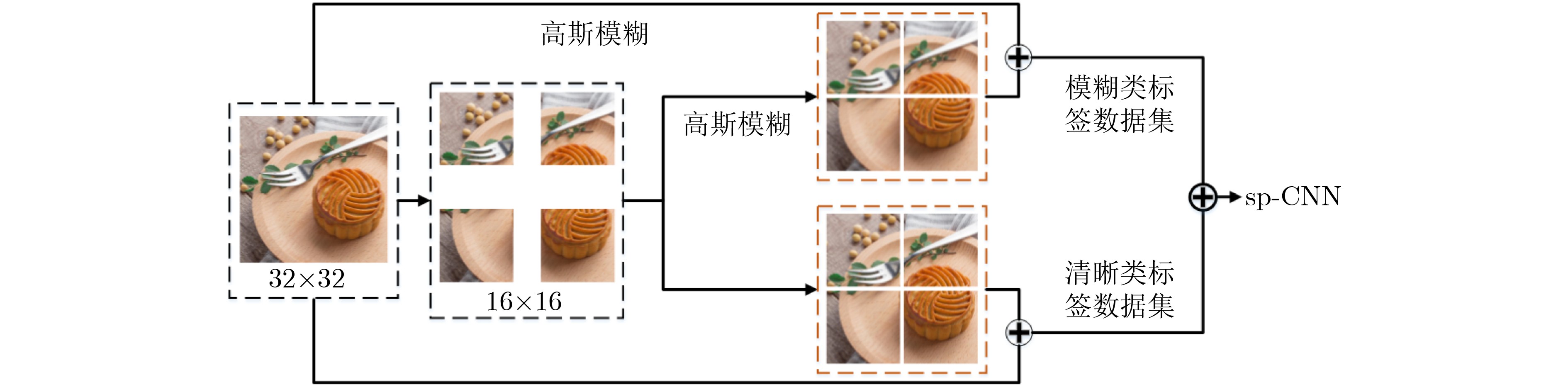
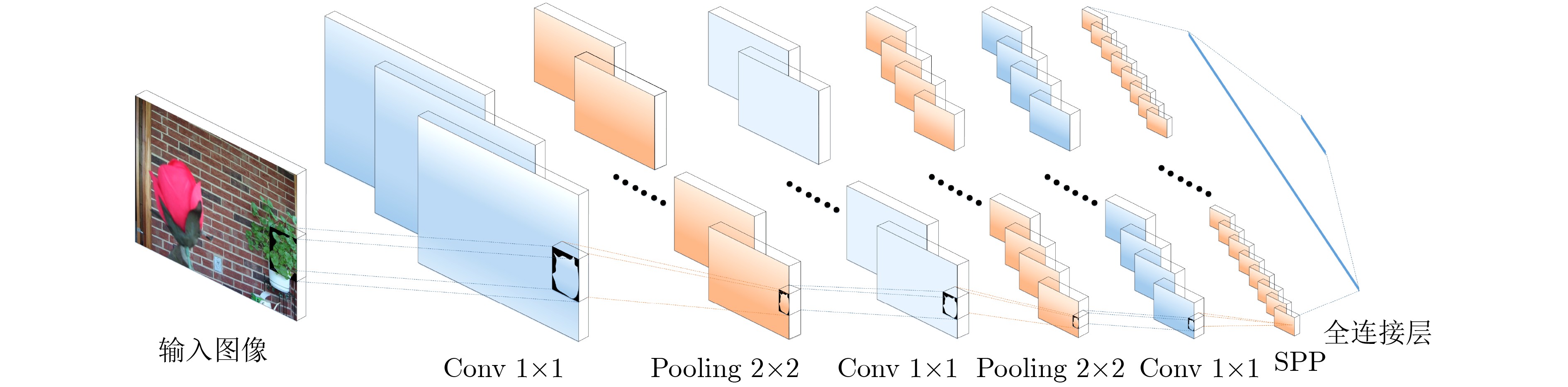
摘要: 该文提出了基于超像素级卷积神经网络(sp-CNN)的多聚焦图像融合算法。该方法首先对源图像进行多尺度超像素分割,将获取的超像素输入sp-CNN,并对输出的初始分类映射图进行连通域操作得到初始决策图;然后根据多幅初始决策图的异同获得不确定区域,并利用空间频率对其再分类,得到阶段决策图;最后利用形态学对阶段决策图进行后处理,并根据所得的最终决策图融合图像。该文算法直接利用超像素分割块进行图像融合,其相较以往利用重叠块的融合算法可达到降低时间复杂度的目的,同时可获得较好的融合效果。Abstract: This paper proposes a multi-focus image fusion algorithm based on super pixel-level Convolutional Neural Network (sp-CNN). In this method, multi-scale super pixel segmentation is firstly applied to the source image to obtain the super pixels. Secondly, the sp-CNN is proposed to acquire the initial decision maps. Thirdly, according to the similarities and differences of the multiple initial decision maps, the uncertain region is reclassified by spatial frequency to obtain the phase decision map. At last, the final decision map is achieved to fuse the source images by post-processing the phase decision graph with morphology. Experimental results show that the proposed method achieves the goal of reducing time complexity and attains better fusion effect compared with the state-of-the-art fusion methods which utilize overlapping blocks.
-
表 1 融合图像的客观评价值
算法 S1 S2 S3 ${Q_{{\rm{MI}}}}$ ${Q_{\rm{P}}}$ ${Q_{\rm{w}}}$ ${Q_{{\rm{af}}}}$ ${Q_{{\rm{MI}}}}$ ${Q_{\rm{P}}}$ ${Q_{\rm{w}}}$ ${Q_{{\rm{af}}}}$ ${Q_{{\rm{MI}}}}$ ${Q_{\rm{P}}}$ ${Q_{\rm{w}}}$ ${Q_{{\rm{af}}}}$ DCT+C+V 8.3869 0.5897 0.8130 0.6342 7.0161 0.6164 0.7704 0.6604 9.3605 0.7533 0.9469 0.7790 DSIFT 10.5221 0.7177 0.8416 0.7408 10.5992 0.7687 0.8226 0.7827 11.1847 0.8153 0.9476 0.8296 GF 10.0879 0.7138 0.8425 0.7377 9.6205 0.7577 0.8184 0.7755 11.1296 0.8153 0.9478 0.8295 IM 10.1618 0.7082 0.8392 0.7332 9.7418 0.7495 0.8112 0.7682 11.0551 0.8115 0.9451 0.8262 PCNN 9.7614 0.6153 0.8078 0.6519 9.8895 0.6927 0.7186 0.7179 11.1311 0.7805 0.9318 0.8033 p-CNN 10.4885 0.7171 0.8410 0.7403 10.6064 0.7655 0.8207 0.7797 11.1851 0.8154 0.9476 0.8296 本文方法 10.4750 0.7184 0.8426 0.7417 10.5767 0.7689 0.8245 0.7832 11.1783 0.8156 0.9477 0.8298  下载: 导出CSV
下载: 导出CSV
表 2 对比方法的平均运行时间(s)
方法 320×240 480×360 640×480 DCT+C+V 0.82 0.93 1.12 DSIFT 1.93 3.89 6.48 GF 0.85 2.81 6.74 IM 10.59 24.25 38.18 PCNN 0.71 1.82 3.16 p-CNN 1.97 3.91 6.62 本文方法 1.15 2.53 4.14
下载: 导出CSV
表 3 融合图像的客观评价值
PSNR SSIM RMSE GS DCT+C+V 26.15017 0.88263 0.01457 0.98793 DSIFT 28.09234 0.90525 0.01552 0.98890 GF 28.10849 0.90569 0.01534 0.98894 IM 27.89434 0.90344 0.01527 0.98885 PCNN 27.66842 0.90257 0.01458 0.98872 p-CNN 28.09490 0.90537 0.01551 0.98890 本文方法 28.10925 0.90571 0.01532 0.98893
下载: 导出CSV
-
RAO Yizhou, HE Lin, and ZHU Jiawei. A residual convolutional neural network for pan-shaprening[C]. 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 2017: 1–4. doi: 10.1109/RSIP.2017.7958807. YIN Ming, LIU Xiaoning, LIU Yu, et al. Medical image fusion with parameter-adaptive pulse coupled neural network in nonsubsampled shearlet transform domain[J]. IEEE Transactions on Instrumentation and Measurement, 2019, 68(1): 49–64. doi: 10.1109/TIM.2018.2838778 朱浩然, 刘云清, 张文颖. 基于灰度变换与两尺度分解的夜视图像融合[J]. 电子与信息学报, 2019, 41(3): 640–648. doi: 10.11999/JEIT180407ZHU Haoran, LIU Yunqing, and ZHANG Wenying. Night-vision image fusion based on intensity transformation and two-scale decomposition[J]. Journal of Electronics &Information Technology, 2019, 41(3): 640–648. doi: 10.11999/JEIT180407 PETROVIC V S and XYDEAS C S. Gradient-based multiresolution image fusion[J]. IEEE Transactions on Image Processing, 2004, 13(2): 228–237. doi: 10.1109/TIP.2004.823821 LEWIS J J, O’CALLAGHAN R J, NIKOLOV S G, et al. Pixel- and region-based image fusion with complex wavelets[J]. Information Fusion, 2007, 8(2): 119–130. doi: 10.1016/j.inffus.2005.09.006 ZHANG Qiang and GUO Baolong. Multifocus image fusion using the nonsubsampled contourlet transform[J]. Signal Processing, 2009, 89(7): 1334–1346. doi: 10.1016/j.sigpro.2009.01.012 LI Shutao, KANG Xudong, FANG Leyuan, et al. Pixel-level image fusion: A survey of the state of the art[J]. Information Fusion, 2017, 33: 100–112. doi: 10.1016/j.inffus.2016.05.004 LI Shutao, KANG Xudong, and HU Jianwen. Image fusion with guided filtering[J]. IEEE Transactions on Image Processing, 2013, 22(7): 2864–2875. doi: 10.1109/TIP.2013.2244222 LI Shutao, KANG Xudong, HU Jianwen, et al. Image matting for fusion of multi-focus images in dynamic scenes[J]. Information Fusion, 2013, 14(2): 147–162. doi: 10.1016/j.inffus.2011.07.001 LIU Yu, LIU Shuping, and WANG Zengfu. Multi-focus image fusion with dense SIFT[J]. Information Fusion, 2015, 23: 139–155. doi: 10.1016/j.inffus.2014.05.004 WANG Zhaobin, MA Yide, and GU J. Multi-focus image fusion using PCNN[J]. Pattern Recognition, 2010, 43(6): 2003–2016. doi: 10.1016/j.patcog.2010.01.011 LIU Yu, CHEN Xun, PENG Hu, et al. Multi-focus image fusion with a deep convolutional neural network[J]. Information Fusion, 2017, 36: 191–207. doi: 10.1016/j.inffus.2016.12.001 TANG Han, XIAO Bin, LI Weisheng, et al. Pixel convolutional neural network for multi-focus image fusion[J]. Information Sciences, 2018, 433/434: 125–141. doi: 10.1016/j.ins.2017.12.043 ACHANTA R, SHAJI A, SMITH K, et al. SLIC superpixels compared to state-of-the-art superpixel methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274–2282. doi: 10.1109/TPAMI.2012.120 REN Xiaofeng and MALIK J. Learning a classification model for segmentation[C]. The 9th IEEE International Conference on Computer Vision, Nice, France, 2003: 10–17. doi: 10.1109/ICCV.2003.1238308. ESKICIOGLU A M and FISHER P S. Image quality measures and their performance[J]. IEEE Transactions on Communications, 1995, 43(12): 2959–2965. doi: 10.1109/26.477498 SHELHAMER E, LONG J, and DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640–651. doi: 10.1109/TPAMI.2016.2572683 HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824 肖斌, 唐翰, 徐韵秋, 等. 基于Hess矩阵的多聚焦图像融合方法[J]. 电子与信息学报, 2018, 40(2): 255–263. doi: 10.11999/JEIT170497XIAO Bin, TANG Han, XU Yunqiu, et al. Multi-focus image fusion based on Hess matrix[J]. Journal of Electronics &Information Technology, 2018, 40(2): 255–263. doi: 10.11999/JEIT170497 CAO Liu, JIN Longxu, TAO Hongjiang, et al. Multi-focus image fusion based on spatial frequency in discrete cosine transform domain[J]. IEEE Signal Processing Letters, 2015, 22(2): 220–224. doi: 10.1109/LSP.2014.2354534 LIU Zheng, BLASCH E, XUE Zhiyun, et al. Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: A comparative study[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(1): 94–109. doi: 10.1109/TPAMI.2011.109 WANG Zhou and LI Qiang. Information content weighting for perceptual image quality assessment[J]. IEEE Transactions on Image Processing, 2011, 20(5): 1185–1198. doi: 10.1109/TIP.2010.2092435 ZHAO Yuxin, JIA Renfeng, and SHI Peng. A novel combination method for conflicting evidence based on inconsistent measurements[J]. Information Sciences, 2016, 367/368: 125–142. doi: 10.1016/j.ins.2016.05.039 LIU Anmin, LIN Weisi, and NARWARIA M. Image quality assessment based on gradient similarity[J]. IEEE Transactions on Image Processing, 2012, 21(4): 1500–1512. doi: 10.1109/TIP.2011.2175935 -


 下载:
下载:









图(10) / 表(3)
计量
- 文章访问数: 2231
- HTML全文浏览量: 1272
- PDF下载量: 174
- 被引次数: 0
