

Single-view 3D Reconstruction Algorithm Based on View-aware
-
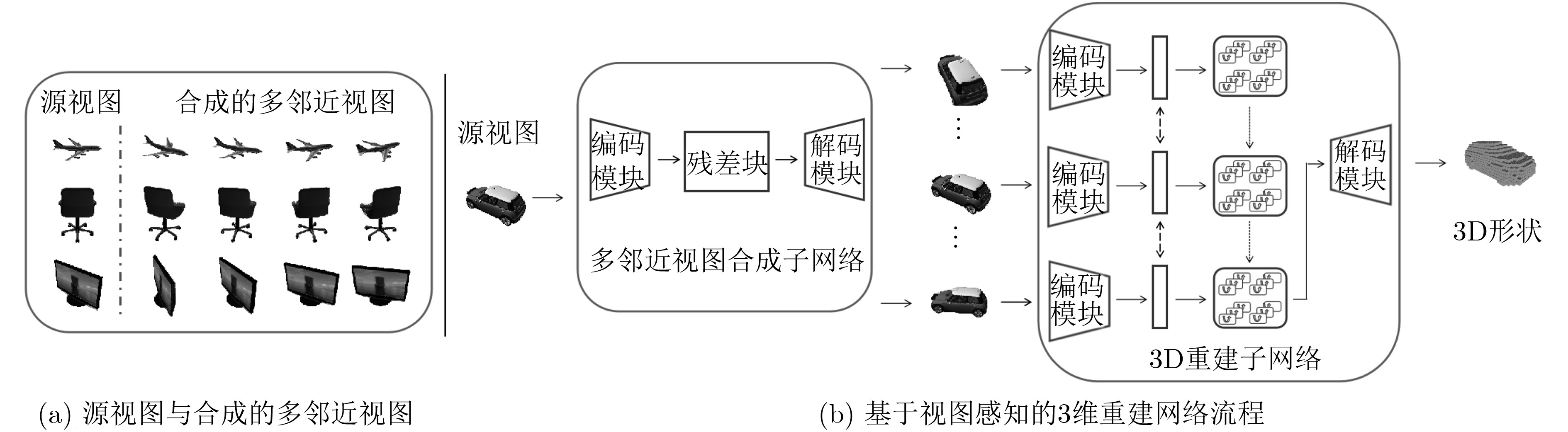
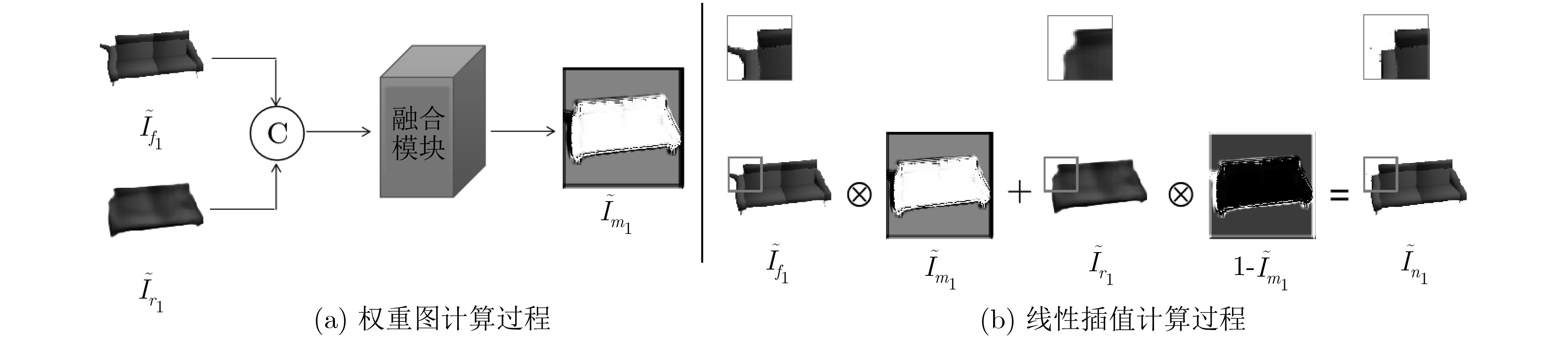
摘要: 尽管由于丢弃维度将3维(3D)形状投影到2维(2D)视图看似是不可逆的,但是从可视化到计算机辅助几何设计,各个垂直行业对3维重建技术的兴趣正迅速增长。传统基于物体深度图或者RGB图的3维重建算法虽然可以在一些方面达到令人满意的效果,但是它们仍然面临若干问题:(1)粗鲁的学习2D视图与3D形状之间的映射;(2)无法解决物体不同视角下外观差异所带来的的影响;(3)要求物体多个观察视角下的图像。该文提出一个端到端的视图感知3维(VA3D)重建网络解决了上述问题。具体而言,VA3D包含多邻近视图合成子网络和3D重建子网络。多邻近视图合成子网络基于物体源视图生成多个邻近视角图像,且引入自适应融合模块解决了视角转换过程中出现的模糊或扭曲等问题。3D重建子网络使用循环神经网络从合成的多视图序列中恢复物体3D形状。通过在ShapeNet数据集上大量定性和定量的实验表明,VA3D有效提升了基于单视图的3维重建结果。Abstract: While projecting 3D shapes to 2D images is irreversible due to the abandoned dimension amid the projection process, there are rapidly growing interests across various vertical industries for 3D reconstruction techniques, from visualization purposes to computer aided geometric design. The traditional 3D reconstruction approaches based on depth map or RGB image can synthesize visually satisfactory 3D objects, while they generally suffer from several problems: (1)The 2D to 3D learning strategy is brutal-force; (2)Unable to solve the effects of differences in appearance from different viewpoints of objects; (3)Multiple images from distinctly different viewpoints are required. In this paper, an end-to-end View-Aware 3D (VA3D) reconstruction network is proposed to address the above problems. In particular, the VA3D includes a multi-neighbor-view synthesis sub-network and a 3D reconstruction sub-network. The multi-neighbor-view synthesis sub-network generates multiple neighboring viewpoint images based on the object source view, while the adaptive fusional module is added to resolve the blurry and distortion issues in viewpoint translation. The 3D reconstruction sub-network introduces a recurrent neural network to recover the object 3D shape from multi-view sequence. Extensive qualitative and quantitative experiments on the ShapeNet dataset show that the VA3D effectively improves the 3D reconstruction results based on single-view.
-
Key words:
- View-aware /
- 3D reconstruction /
- Viewpoint translation /
- End-to-end neural network /
- Adaptive fusional
-
表 1 定量比较结果
类别 IoU F-score 3D-R2N2_1 3D-R2N2_5 VA3D 3D-R2N2_1 3D-R2N2_5 VA3D 柜子 0.7299 0.7839 0.7915 0.8267 0.8651 0.8694 汽车 0.8123 0.8551 0.8530 0.8923 0.9190 0.9178 椅子 0.4958 0.5802 0.5643 0.6404 0.7155 0.6995 飞机 0.5560 0.6228 0.6385 0.7006 0.7561 0.7641 桌子 0.5297 0.6061 0.6128 0.6717 0.7362 0.7386 长凳 0.4621 0.5566 0.5533 0.6115 0.6991 0.6936 平均 0.5976 0.6674 0.6689 0.7238 0.7818 0.7805  下载: 导出CSV
下载: 导出CSV
表 3 MSN中不同输出策略的影响
模型 SSIM PSNR IoU F-score 仅使用${\left\{ {{{{\tilde{ I}}}_r}} \right\}^{\rm{C}}}$ 0.8035 19.8042 0.6525 0.7649 仅使用${\left\{ {{{{\tilde{ I}}}_f}} \right\}^{\rm{C}}}$ 0.8435 20.5273 0.6530 0.7646 自适应融合 0.8488 20.6203 0.6554 0.7672
下载: 导出CSV
表 4 重建结果的方差
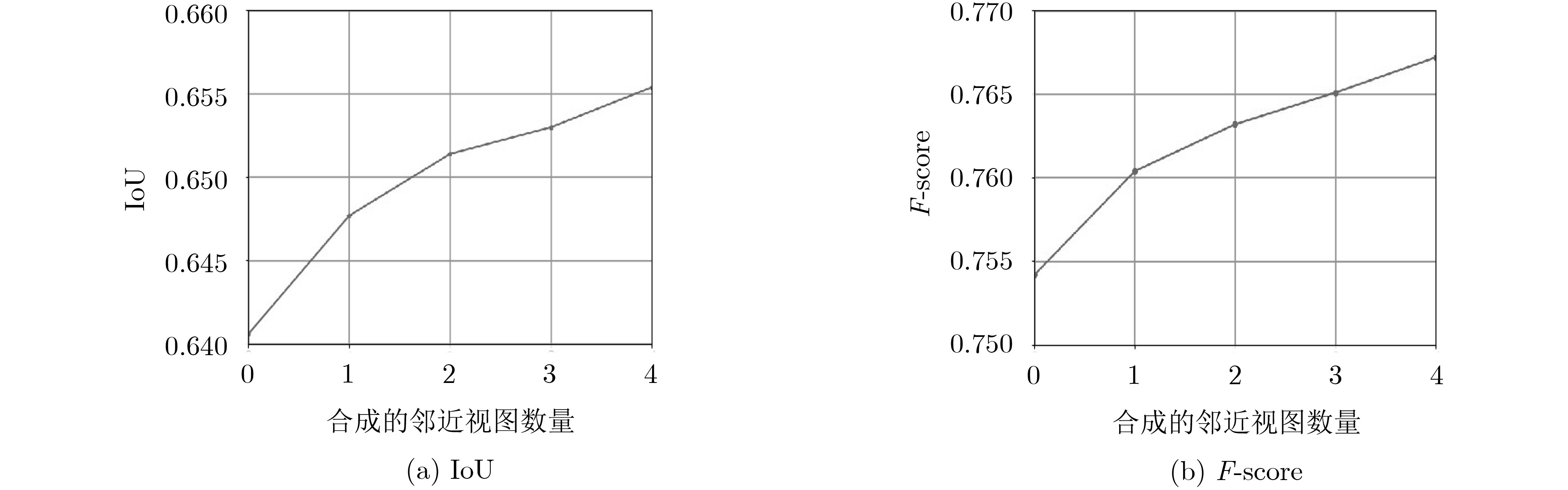
模型 $\sigma _{{\rm{IoU}}}^2$ $\sigma _{{F} {\rm{ - score}}}^{\rm{2}}$ 合成视图数量=0 0.0057 0.0061 合成视图数量=4 0.0051 0.0054
下载: 导出CSV
表 5 不同损失函数的组合
模型 SSIM PSNR IoU F-score 无重建损失${{\cal{L}}_{{\rm{rec}}}}$ 0.8462 20.2693 0.6540 0.7658 无对抗损失${{\cal{L}}_{{\rm{adv}}}}$ 0.8516 21.4385 0.6539 0.7651 无感知损失${{\cal{L}}_{{\rm{per}}}}$ 0.8416 20.3141 0.6525 0.7645 全部损失 0.8488 20.6203 0.6554 0.7672
下载: 导出CSV
-
EIGEN D, PUHRSCH C, and FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2366–2374. WU Jiajun, WANG Yifan, XUE Tianfan, et al. Marrnet: 3D shape reconstruction via 2.5D sketches[C]. The 31st Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 540–550. WANG Nanyang, ZHANG Yinda, LI Zhuwen, et al. Pixel2mesh: Generating 3D mesh models from single RGB images[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 55–71. doi: 10.1007/978-3-030-01252-6_4. TANG Jiapeng, HAN Xiaoguang, PAN Junyi, et al. A skeleton-bridged deep learning approach for generating meshes of complex topologies from single RGB images[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 4536–4545. doi: 10.1109/cvpr.2019.00467. CHOY C B, XU Danfei, GWAK J Y, et al. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction[C]. The 14th European Conference on Computer Vision, Amsterdam, the Netherlands, 2016: 628–644. doi: 10.1007/978-3-319-46484-8_38. HU Xuyang, ZHU Fan, LIU Li, et al. Structure-aware 3D shape synthesis from single-view images[C]. 2018 British Machine Vision Conference, Newcastle, UK, 2018. GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. 张惊雷, 厚雅伟. 基于改进循环生成式对抗网络的图像风格迁移[J]. 电子与信息学报, 2020, 42(5): 1216–1222. doi: 10.11999/JEIT190407ZHANG Jinglei and HOU Yawei. Image-to-image translation based on improved cycle-consistent generative adversarial network[J]. Journal of Electronics &Information Technology, 2020, 42(5): 1216–1222. doi: 10.11999/JEIT190407 陈莹, 陈湟康. 基于多模态生成对抗网络和三元组损失的说话人识别[J]. 电子与信息学报, 2020, 42(2): 379–385. doi: 10.11999/JEIT190154CHEN Ying and CHEN Huangkang. Speaker recognition based on multimodal generative adversarial nets with triplet-loss[J]. Journal of Electronics &Information Technology, 2020, 42(2): 379–385. doi: 10.11999/JEIT190154 WANG Tingchun, LIU Mingyu, ZHU Junyan, et al. High-resolution image synthesis and semantic manipulation with conditional gans[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8798–8807. doi: 10.1109/cvpr.2018.00917. ULYANOV D, VEDALDI A, and LEMPITSKY V. Instance normalization: The missing ingredient for fast stylization[EB/OL]. https://arxiv.org/abs/1607.08022, 2016. XU Bing, WANG Naiyan, CHEN Tianqi, et al. Empirical evaluation of rectified activations in convolutional network[EB/OL]. https://arxiv.org/abs/1505.00853, 2015. GOKASLAN A, RAMANUJAN V, RITCHIE D, et al. Improving shape deformation in unsupervised image-to-image translation[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 662–678. doi: 10.1007/978-3-030-01258-8_40. MAO Xudong, LI Qing, XIE Haoran, et al. Least squares generative adversarial networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2813–2821. doi: 10.1109/iccv.2017.304. GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wasserstein GANs[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5767–5777. LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 105–114. doi: 10.1109/CVPR.2017.19. SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. https://arxiv.org/abs/1409.1556, 2014. KINGMA D P and BA J. Adam: A method for stochastic optimization[EB/OL]. https://arxiv.org/abs/1412.6980, 2014. CHANG A X, FUNKHOUSER T, GUIBAS L, et al. Shapenet: An information-rich 3D model repository[EB/OL]. https://arxiv.org/abs/1512.03012, 2015. GRABNER A, ROTH P M, and LEPETIT V. 3D pose estimation and 3D model retrieval for objects in the wild[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3022–3031. doi: 10.1109/cvpr.2018.00319. HE Xinwei, ZHOU Yang, ZHOU Zhichao, et al. Triplet-center loss for multi-view 3D object retrieval[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1945–1954. doi: 10.1109/cvpr.2018.00208. -

 下载:
下载:





图(6) / 表(5)
计量
- 文章访问数: 3191
- HTML全文浏览量: 1906
- PDF下载量: 148
- 被引次数: 0
