

Image Blind Deblurring Algorithm Based on Deep Multi-level Wavelet Transform
-
摘要:
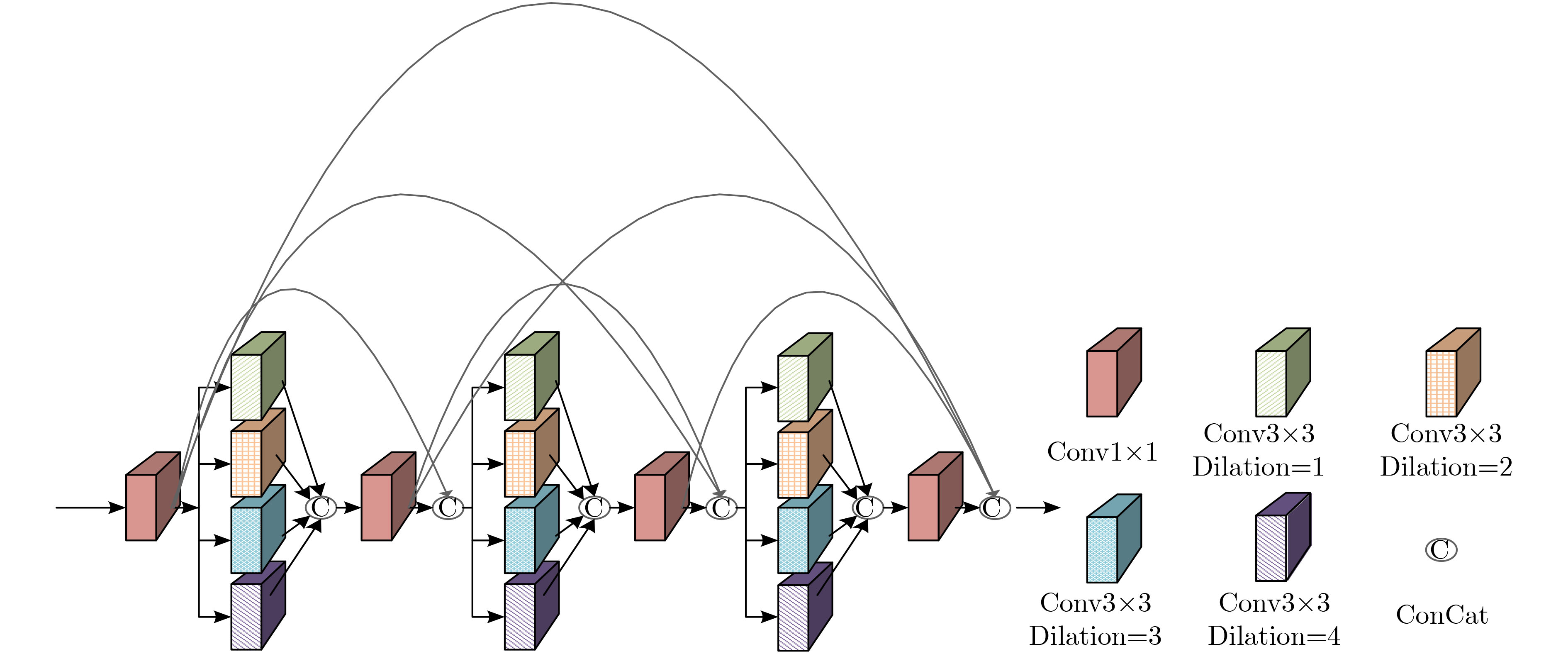
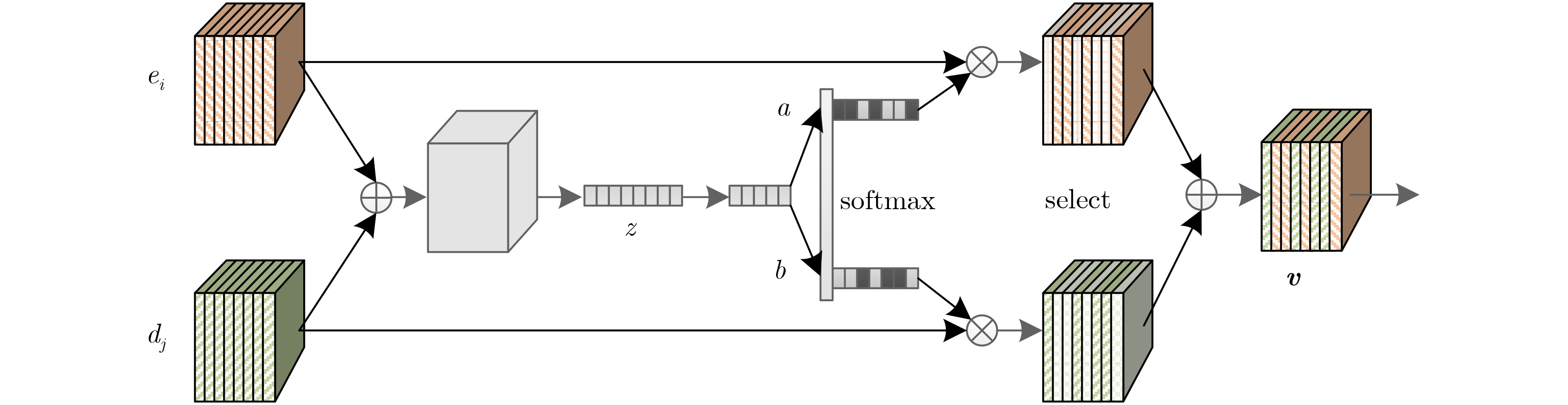
近年来卷积神经网络广泛应用于单幅图像去模糊问题,卷积神经网络的感受野大小、网络深度等会影响图像去模糊算法性能。为了增大感受野以提高图像去模糊算法的性能,该文提出一种基于深度多级小波变换的图像盲去模糊算法。将小波变换嵌入编-解码结构中,在增大感受野的同时加强图像特征的稀疏性。为在小波域重构高质量图像,该文利用多尺度扩张稠密块提取图像的多尺度信息,同时引入特征融合块以自适应地融合编-解码之间的特征。此外,由于小波域和空间域对图像信息的表示存在差异,为融合这些不同的特征表示,该文利用空间域重建模块在空间域进一步提高重构图像的质量。实验结果表明该文方法在结构相似度(SSIM)和峰值信噪比(PSNR)上具有更好的性能,而且在真实模糊图像上具有更好的视觉效果。
Abstract:In recent years, convolutional neural networks are widely used in single image deblurring problems. The receptive field size and network depth of convolutional neural networks can affect the performance of image deblurring algorithms. In order to improve the performance of image deblurring algorithm by increasing the receptive field, an image blind deblurring algorithm based on deep multi-level wavelet transform is proposed. Embedding the wavelet transform into the encoder-decoder architecture enhances the sparsity of the image features while increasing the receptive field. In order to reconstruct high-quality images in the wavelet domain, the paper leverges to multi-scale dilated dense block to extract multi-scale information of images, and introduces feature fusion blocks to fuse adaptively features between encoder and decoder. In addition, due to the difference in representation of image information between the wavelet domain and the spatial domain, in order to fuse these different feature representations, the spatial domain reconstruction module is used to improve further the quality of the reconstructed image in the spatial domain. The experimental results show that the proposed method has better performance on Structural SIMilarity index (SSIM) and Peak Signal-to-Noise Ratio, and has better visual effects on real blurred images.
-
Key words:
- Image deblurring /
- Deep learning /
- Wavelet transform /
- Multi-scale /
- Feature fusion
-
表 4 各基准模型在GoPro测试集上的定量结果
模型 W-B W-C3 W-MS W-FF W-SDR 本文 多尺度 × × √ × × √ 特征融合 × × × √ × √ 空间域图像重构 × × × × √ √ 嵌入卷积 × √ × × × × PSNR 30.98 31.02 31.10 31.09 31.13 31.39 SSIM 0.949 0.949 0.950 0.950 0.950 0.952  下载: 导出CSV
下载: 导出CSV
-
XU Li, ZHENG Shicheng, and JIA Jiaya. Unnatural l0 sparse representation for natural image deblurring[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 1107–1114. doi: 10.1109/CVPR.2013.147. SUN Jian, CAO Wenfei, XU Zongben, et al. Learning a convolutional neural network for non-uniform motion blur removal[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 769–777. doi: 10.1109/CVPR.2015.7298677. GONG Dong, YANG Jie, LIU Lingqiao, et al. From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA, 2017: 3806–3815. doi: 10.1109/CVPR.2017.405. NAH S, KIM T H, and LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 257–265. doi: 10.1109/CVPR.2017.35. KUPYN O, BUDZAN V, MYKHAILYCH M, et al. DeblurGAN: Blind motion deblurring using conditional adversarial networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8183–8192. doi: 10.1109/CVPR.2018.00854. KUPYN O, MARTYNIUK T, WU Junru, et al. DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 8877–8886. doi: 10.1109/ICCV.2019.00897. TAO Xin, GAO Hongyun, SHEN Xiaoyong, et al. Scale-recurrent network for deep image deblurring[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8174–8182. doi: 10.1109/CVPR.2018.00853. 梁晓萍, 郭振军, 朱昌洪. 基于头脑风暴优化算法的BP神经网络模糊图像复原[J]. 电子与信息学报, 2019, 41(12): 2980–2986. doi: 10.11999/JEIT190261LIANG Xiaoping, GUO Zhenjun, and ZHU Changhong. BP neural network fuzzy image restoration based on brain storming optimization algorithm[J]. Journal of Electronics &Information Technology, 2019, 41(12): 2980–2986. doi: 10.11999/JEIT190261 RONNEBERGER O, FISCHER P, and BROX T. U-net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28. CHEN Dongdong, HE Mingming, FAN Qingnan, et al. Gated context aggregation network for image dehazing and deraining[C]. 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa Village, USA, 2019: 1375–1383. doi: 10.1109/WACV.2019.00151. LIU Pengju, ZHANG Hongzhi, ZHANG Kai, et al. Multi-level wavelet-CNN for image restoration[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, USA, 2018: 886–895. doi: 10.1109/CVPRW.2018.00121. JIN Meiguang, HIRSCH M, and FAVARO P. Learning face deblurring fast and wide[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, USA, 2018: 858–866. doi: 10.1109/CVPRW.2018.00118. GUO Tiantong, MOUSAVI H S, VU T H, et al. Deep wavelet prediction for image super-resolution[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 2017: 1100–1109. doi: 10.1109/CVPRW.2017.148. LI Xiang, WANG Wenhai, HU Xiaolin, et al. Selective kernel networks[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 510–519. doi: 10.1109/CVPR.2019.00060. HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2261–2269. doi: 10.1109/CVPR.2017.243. 陈书贞, 张祎俊, 练秋生. 基于多尺度稠密残差网络的JPEG压缩伪迹去除方法[J]. 电子与信息学报, 2019, 41(10): 2479–2486. doi: 10.11999/JEIT180963CHEN Shuzhen, ZHANG Yijun, and LIAN Qiusheng. JPEG compression artifacts reduction algorithm based on multi-scale dense residual network[J]. Journal of Electronics &Information Technology, 2019, 41(10): 2479–2486. doi: 10.11999/JEIT180963 WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1. SU Shuochen, DELBRACIO M, WANG Jue, et al. Deep video deblurring for hand-held cameras[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 237–246. doi: 10.1109/CVPR.2017.33. HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. LAI Weisheng, HUANG Jiabin, HU Zhe, et al. A comparative study for single image blind deblurring[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1701–1709. doi: 10.1109/CVPR.2016.188. -


 下载:
下载:




计量
- 文章访问数: 1867
- HTML全文浏览量: 1603
- PDF下载量: 241
- 被引次数: 0
