

Research on Fuzzy Image Instance Segmentation Based on Improved Mask R-CNN
-
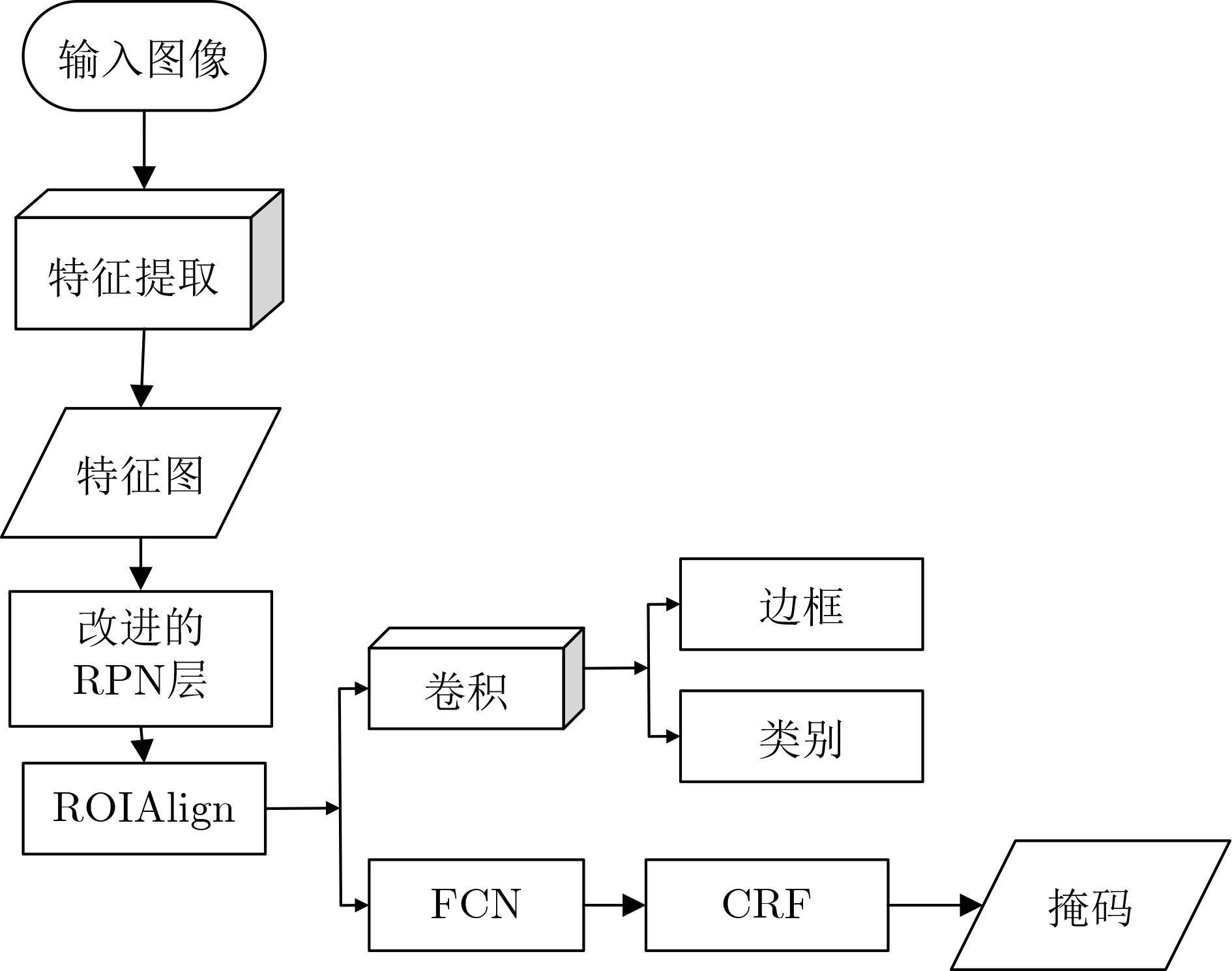
摘要: Mask R-CNN是现阶段实例分割相对成熟的方法,针对Mask R-CNN算法当中还存在的分割边界精度以及对于模糊图片鲁棒性较差等问题,该文提出一种基于改进的Mask R-CNN实例分割方法。该方法首先提出在Mask分支上使用卷积化条件随机场(ConvCRF)来优化Mask分支对于候选区域进一步分割,并使用FCN-ConvCRF分支来代替原有分支;之后提出新锚点大小和IOU标准,使得RPN候选框能够涵盖所有实例区域;最后使用一种添加部分经过转换网络转换的数据进行训练的方法。总的mAP值与原算法相比提升了3%,并且分割边界精确度和鲁棒性都有一定提高。
-
关键词:
- 图像实例分割 /
- Mask R-CNN /
- 条件随机场 /
- RPN层
Abstract: Mask R-CNN is a relatively mature method for image instance segmentation at this stage. For the problems of segmentation boundary accuracy and poor robustness of fuzzy pictures in Mask R-CNN algorithm, an improved Mask R-CNN method for image instance segmentation is proposed. This method first proposes that on the Mask branch, Convolution Condition Random Field(ConvCRF) is used to optimize the Mask branch, and the candidate area is further segmented, and uses FCN-ConvCRF branch to replace the original branch. Then, a new anchor size and IOU standard are proposed to enable the RPN candidate box cover all the instance areas. Finally, a training method is used to add a part of data transformed by the transformation network. Compared with the original algorithm, the total mAP value is improved by 3%, and the accuracy and robustness of segmentation boundary are improved to some extent.-
Key words:
- Image instance segmentation /
- Mask R-CNN /
- Conditional Random Field(CRF) /
- RPN level
-
表 3 总mAP值对比
mAP值(IOU=50) mAP值(IOU=75) mAP值(模糊数据) 原Mask R-CNN 0.60 0.39 0.49 复现的Mask R-CNN(coco) 0.59 0.37 0.48 复现的Mask R-CNN(模糊数据) 0.58 0.37 0.50 改进的Mask R-CNN(模糊数据) 0.66 0.43 0.51 改进的Mask R-CNN(coco) 0.65 0.44 0.49 Mnc 0.44 0.24 – Fcis 0.49 – – Masklab 0.57 0.37 Masklab+ 0.60 0.40 PANet 0.65 0.43 –  下载: 导出CSV
下载: 导出CSV
-
SHELHAMER E, LONG J, and DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640–651. doi: 10.1109/TPAMI.2016.2572683 REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. The Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91. REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. The Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6517–6525. doi: 10.1109/CVPR.2017.690. DAI Jifeng, HE Kaiming, and SUN Jian. Instance-aware semantic segmentation via multi-task network cascades[C]. The Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 3150–3158. doi: 10.1109/CVPR.2016.343. DAI Jifeng, HE Kaiming, LI Yi, et al. Instance-sensitive fully convolutional networks[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 534–549. LI Yi, QI Haozhi, DAI Jifeng, et al. Fully convolutional instance-aware semantic segmentation[C]. The Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4438–4446. doi: 10.1109/CVPR.2017.472. BAI Min and URTASUN R. Deep watershed transform for instance segmentation[C]. The Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2858–2866. doi: 10.1109/CVPR.2017.305. LIU Shu, JIA Jiaya, FIDLER S, et al. SGN: Sequential grouping networks for instance segmentation[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 3516–3524. doi: 10.1109/ICCV.2017.378. HE Kaiming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2980–2988. PINHEIRO P O, COLLOBERT R, and DOLLÁR P. Learning to segment object candidates[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 1990–1998. PINHEIRO P O, LIN T Y, COLLOBERT R, et al. Learning to refine object segments[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 75–91. doi: 10.1007/978-3-319-46448-0_5. ZAGORUYKO S, LERER A, LIN T Y, et al. A multipath network for object detection[C]. The British Machine Vision Conference, Edinburgh, England, 2016. doi: 10.5244/C.30.15. 罗会兰, 卢飞, 孔繁胜. 基于区域与深度残差网络的图像语义分割[J]. 电子与信息学报, 2019, 41(11): 2777–2786. doi: 10.11999/JEIT190056LUO Huilan, LU Fei, and KONG Fansheng. Image semantic segmentation based on region and deep residual network[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2777–2786. doi: 10.11999/JEIT190056 CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184 ZHENG Shuai, JAYASUMANA S, ROMERA-PAREDES B, et al. Conditional random fields as recurrent neural networks[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1529–1537. 韩铮, 肖志涛. 基于纹元森林和显著性先验的弱监督图像语义分割方法[J]. 电子与信息学报, 2018, 40(3): 610–617. doi: 10.11999/JEIT170472HAN Zheng and XIAO Zhitao. Weakly supervised semantic segmentation based on semantic texton forest and saliency prior[J]. Journal of Electronics &Information Technology, 2018, 40(3): 610–617. doi: 10.11999/JEIT170472 KRÄHENBÜHL P and KOLTUN V. Efficient inference in fully connected CRFs with Gaussian edge potentials[C]. The 24th International Conference on Neural Information Processing Systems, Granada, Spain, 2011: 109–117. TEICHMANN M T T and CIPOLLA R. Convolutional CRFs for semantic segmentation[EB/OL]. https://arxiv.org/abs/1805.04777, 2018. LAFFERTY J, MCCALLUM A, and PEREIRA F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]. The 18th International Conference on Machine Learning, San Francisco, CA, USA, 2001: 282–289. LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2. SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. http://arxiv.org/abs/1409.1556v6, 2014. GATYS L A, ECKER A S, and BETHGE M. Image style transfer using convolutional neural networks[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2414–2423. doi: 10.1109/CVPR.2016.265. CHEN L C, HERMANS A, PAPANDREOU G, et al. MaskLab: Instance segmentation by refining object detection with semantic and direction features[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4013–4022. LIU Shu, QI Lu, QIN Haifang, et al. Path aggregation network for instance segmentation[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8759–8768. doi: 10.1109/CVPR.2018.00913. -


 下载:
下载:





图(5) / 表(3)
计量
- 文章访问数: 2107
- HTML全文浏览量: 1337
- PDF下载量: 195
- 被引次数: 0
