

A Discrete Side-lobe Clutter Recognition Method Using Space-time Steering Vectors for Space Based Radar System
-
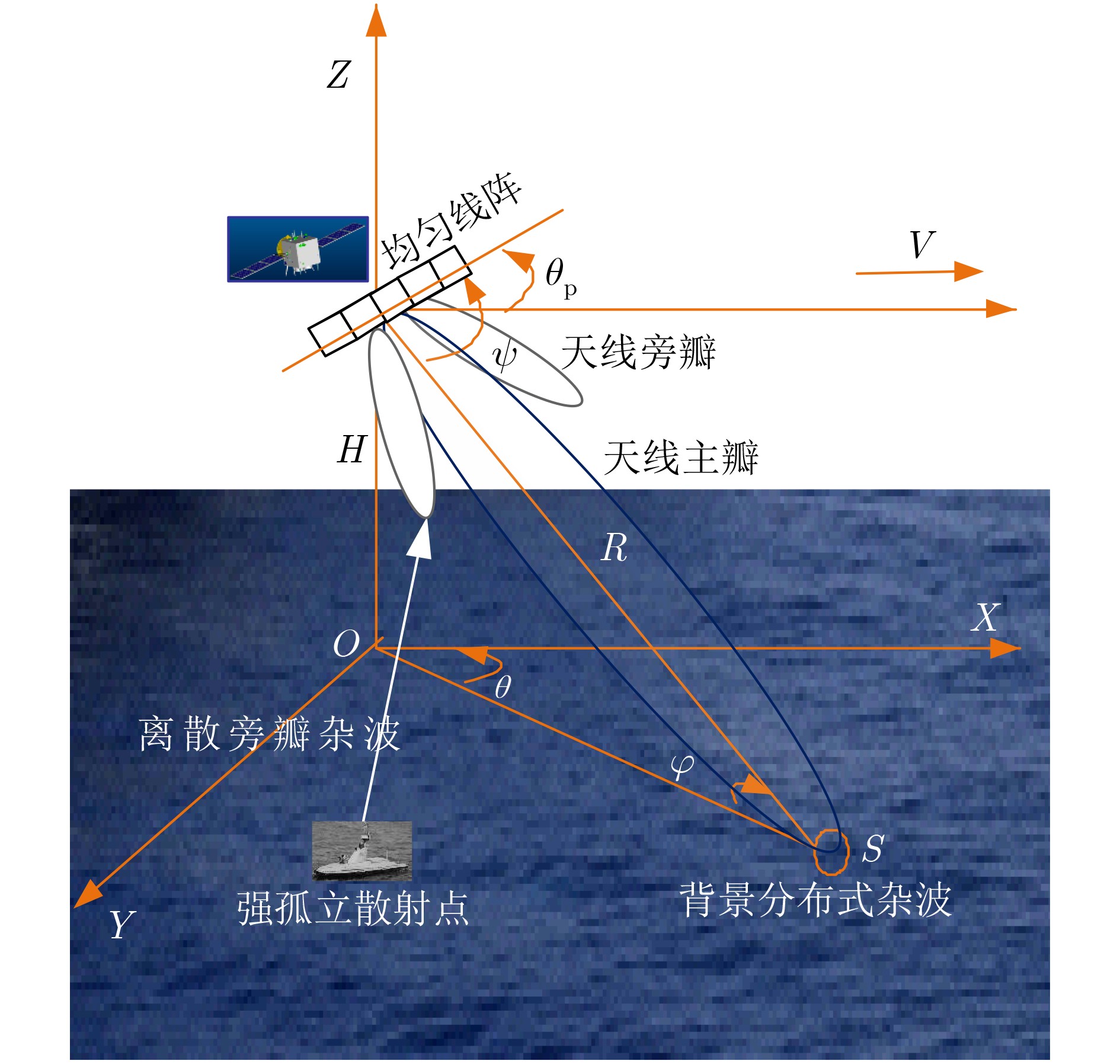
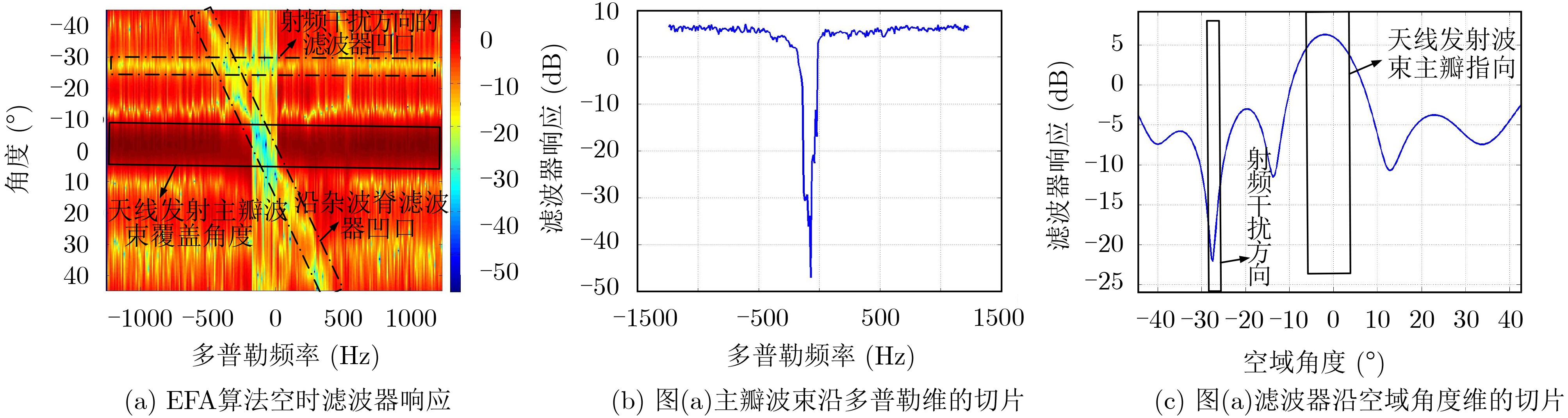
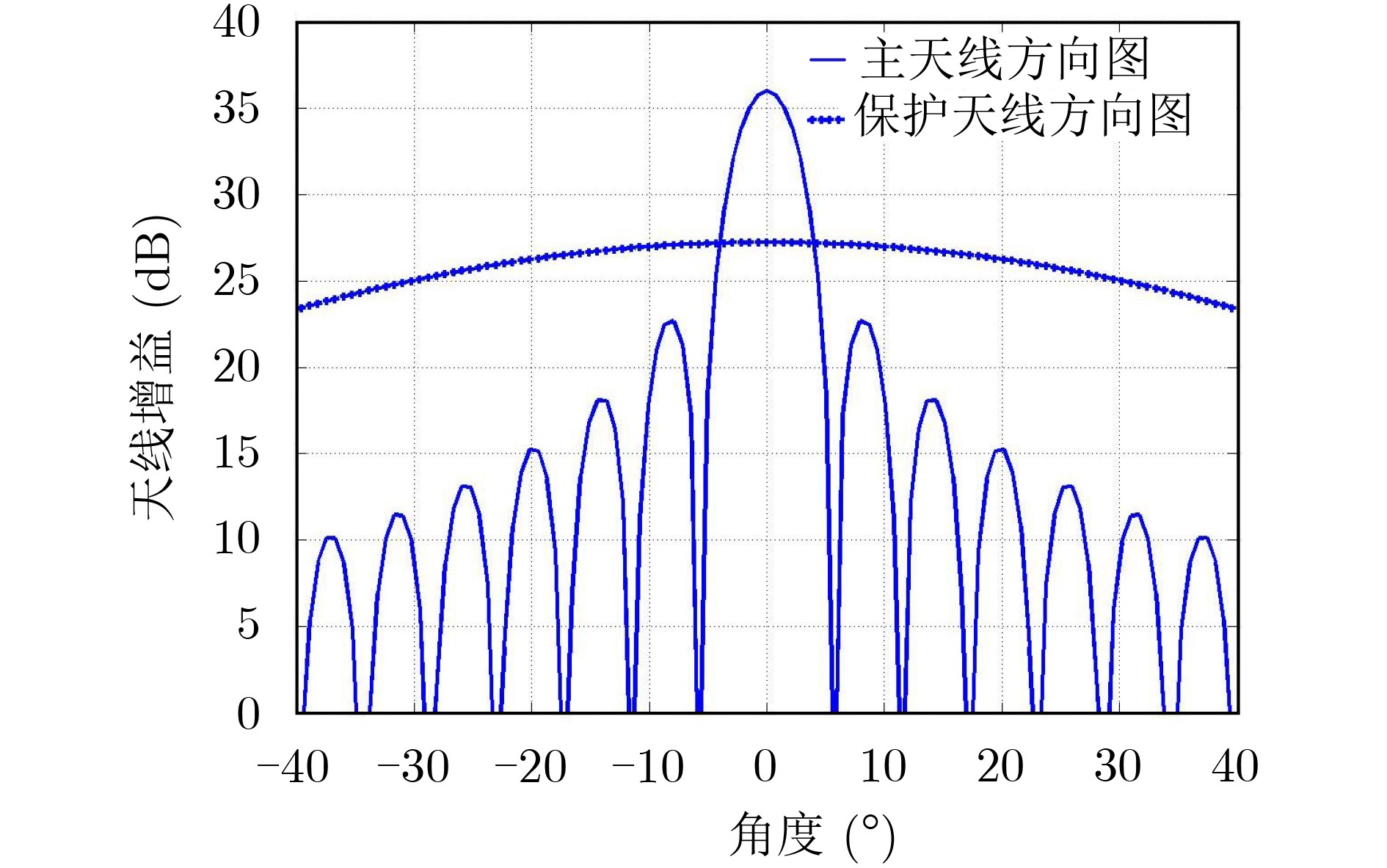
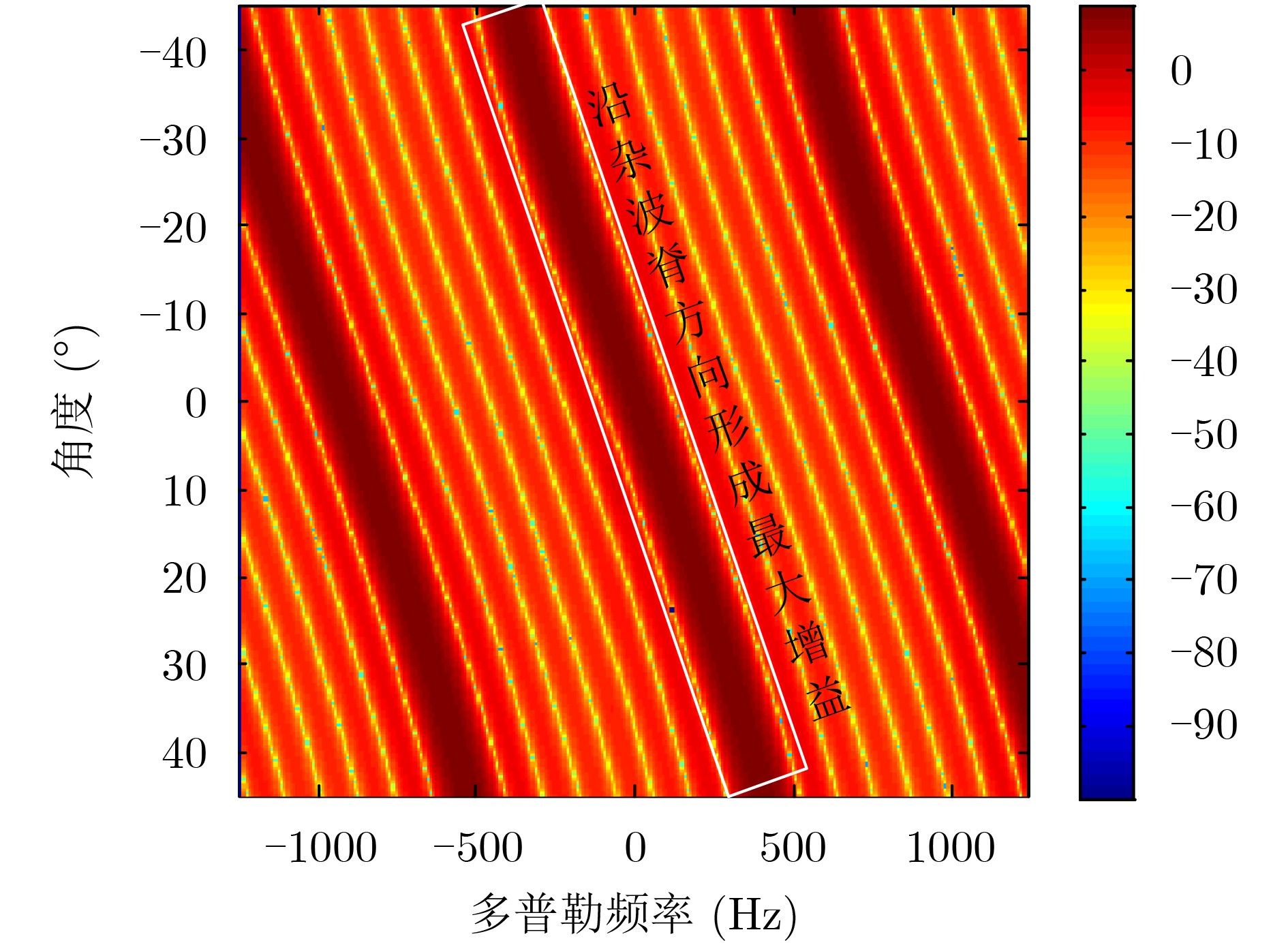
摘要: 由于天基雷达覆盖范围广,大量强离散杂波(小型岛礁、陆地铁塔等)会从天线旁瓣进入雷达系统,其多普勒特征与目标相同,极易造成虚警。针对以上问题,该文提出基于空时导向约束的天基雷达离散旁瓣杂波判别方法,该方法首先选取空时自适应处理(STAP)杂波抑制后检测到的潜在“目标”(包含真实目标与离散旁瓣杂波)距离多普勒单元及其附近单元;然后根据杂波多普勒频率与空间角度的耦合关系获得各杂波单元对应的空时导向矢量;最后利用获得新的导向矢量构成的滤波器再次对“目标”距离多普勒单元及其附近单元进行滤波处理,此时真实目标信杂噪比会大幅度降低,而离散旁瓣杂波信杂噪比变化不大,从而实现离散旁瓣杂波的判别。理论分析及机载实测数据处理证明该方法具有良好的稳健性和可靠性。Abstract: On account of the large coverage of space based radar, a lot of discrete strong side-lobe clutter, which shares familiar Doppler feature with the real moving targets, can be received by the radar system and hence results in false alarms. For this problem, a discrete side-lobe clutter recognition method using space-time steering vectors for space based radar system is proposed. In this method, the “Suspected targets”, including both the real moving targets and discrete side-lobe clutter, are detected after suppressing clutter by employing the Space-Time Adaptive Processing (STAP). The range-Doppler cells where “suspected targets” located in or around are selected. Afterwards, the space time steering vectors of them are obtained based on the coupling relationship between Doppler frequencies and space angles of clutter. Lastly, the above range-Doppler cells are processed again by the adaptive processing filters which are derived from the new space-time steering vectors. Obviously, the signal-clutter-noise ratio of real moving target will be reduced significantly, while it will not change much for the discrete side-lobe clutter. Therefore, the discrete side-lobe clutter can be identified by using the proposed method. Theoretical analyses and multi-channel airborne radar experiments demonstrate the effectiveness and stability of this method.
-
杨晓超, 王伟伟, 张欣, 等. 一种天基雷达等距离环杂波仿真方法[J]. 现代雷达, 2018, 40(4): 13–17, 49. doi: 10.16592/j.cnki.1004-7859.2018.04.003YANG Xiaochao, WANG Weiwei, ZHANG Xin, et al. A simulation method of space-based radar iso-range ring clutter[J]. Modern Radar, 2018, 40(4): 13–17, 49. doi: 10.16592/j.cnki.1004-7859.2018.04.003 SKOLNIK M I, 南京电子技术研究所译. 雷达手册[M]. 3版. 北京: 电子工业出版社, 2010: 148–152.SKOLNIK M I, Nanjing Institute of Electronic Technology. Radar Handbook[M]. 3rd ed. Beijing: Publishing House of Electronics Industry, 2010: 148–152. LI Huiyong, BAO Weiwei, HU Jinfeng, et al. A training samples selection method based on system identification for STAP[J]. Signal Processing, 2018, 142: 119–124. doi: 10.1016/j.sigpro.2017.07.008 WU Yifeng, WANG Tong, WU Jianxin, et al. Robust training samples selection algorithm based on spectral similarity for space-time adaptive processing in heterogeneous interference environments[J]. IET Radar, Sonar & Navigation, 2015, 9(7): 778–782. doi: 10.1049/iet-rsn.2014.0285 SUN Guohao, HE Zishu, TONG Jun, et al. Knowledge-aided covariance matrix estimation via Kronecker product expansions for airborne STAP[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(4): 527–531. doi: 10.1109/LGRS.2018.2799329 李永伟, 谢文冲. 基于空时内插的端射阵机载雷达杂波补偿新方法[J]. 电子与信息学报, 2019, 41(9): 2115–2122. doi: 10.11999/JEIT181131LI Yongwei and XIE Wenchong. A novel clutter spectrum compensation method for end-fire array airborne radar based on space-time interpolation[J]. Journal of Electronics &Information Technology, 2019, 41(9): 2115–2122. doi: 10.11999/JEIT181131 WEN Cai, PENG Jinye, ZHOU Yan, et al. Enhanced three-dimensional joint domain localized STAP for airborne FDA-MIMO radar under dense false-target jamming scenario[J]. IEEE Sensors Journal, 2018, 18(10): 4154–4166. doi: 10.1109/jsen.2018.2820905 刘斌, 何广军, 冯有前, 等. 静态和差波束匹配的空时自适应处理方法[J]. 西安电子科技大学学报: 自然科学版, 2017, 44(3): 138–143, 169. doi: 10.3969/j.issn.1001-2400.2017.03.024LIU Bin, HE Guangjun, FENG Youqian, et al. Static sum-and-difference beam matched STAP method[J]. Journal of Xidian University, 2017, 44(3): 138–143, 169. doi: 10.3969/j.issn.1001-2400.2017.03.024 XU Huajian, YANG Zhiwei, HE Shun, et al. A generalized sample weighting method in heterogeneous environment for space-time adaptive processing[J]. Digital Signal Processing, 2018, 72: 147–159. doi: 10.1016/j.dsp.2018.10.005 侯静, 胡孟凯, 王子微. 一种改进的知识辅助MIMO雷达空时自适应处理方法[J]. 电子与信息学报, 2019, 41(4): 795–800. doi: 10.11999/JEIT180557HOU Jing, HU Mengkai, and WANG Ziwei. An improved knowledge-aided space-time adaptive signal processing algorithm for MIMO radar[J]. Journal of Electronics &Information Technology, 2019, 41(4): 795–800. doi: 10.11999/JEIT180557 SHNIDMAN D A and TOUMODGE S S. Sidelobe blanking with integration and target fluctuation[J]. IEEE Transactions on Aerospace and Electronic Systems, 2002, 38(3): 1023–1037. doi: 10.1109/TAES.2002.1039418 NARASIMHAN R S, VENGADARAJAN A, and RAMAKRISHNAN K R. Mitigation of sidelobe clutter discrete using sidelobe blanking technique in airborne radars[C]. 2018 IEEE Aerospace Conference, Big Sky, USA, 2018: 1–10. BAO Zheng, WU Shunjun, LIAO Guisheng, et al. Review of reduced rank space-time adaptive processing for airborne radar[C]. International Radar Conference, Beijing, China, 1996: 766–769. 何友, 关键, 孟祥伟, 等. 雷达目标检测与恒虚警处理[M]. 2版. 北京: 清华大学出版社, 2011: 40–50.HE You, GUAN Jian, MENG Xiangwei, et al. Radar Target Detection and CFAR Processing[M]. 2nd ed. Beijing: Tsinghua University Press, 2011: 40–50. YANG Xiaopeng, LIU Yongxu, HU Xiaona, et al. Robust generalized inner products algorithm using prolate spheroidal wave functions[C]. 2012 IEEE Radar Conference, Atlanta, USA, 2012: 581–584. -

 下载:
下载:





图(7) / 表(4)
计量
- 文章访问数: 1386
- HTML全文浏览量: 837
- PDF下载量: 96
- 被引次数: 0
