

Deep Reinforcement Learning-based Adaptive Wireless Resource Allocation Algorithm for Heterogeneous Cloud Wireless Access Network
-
摘要:
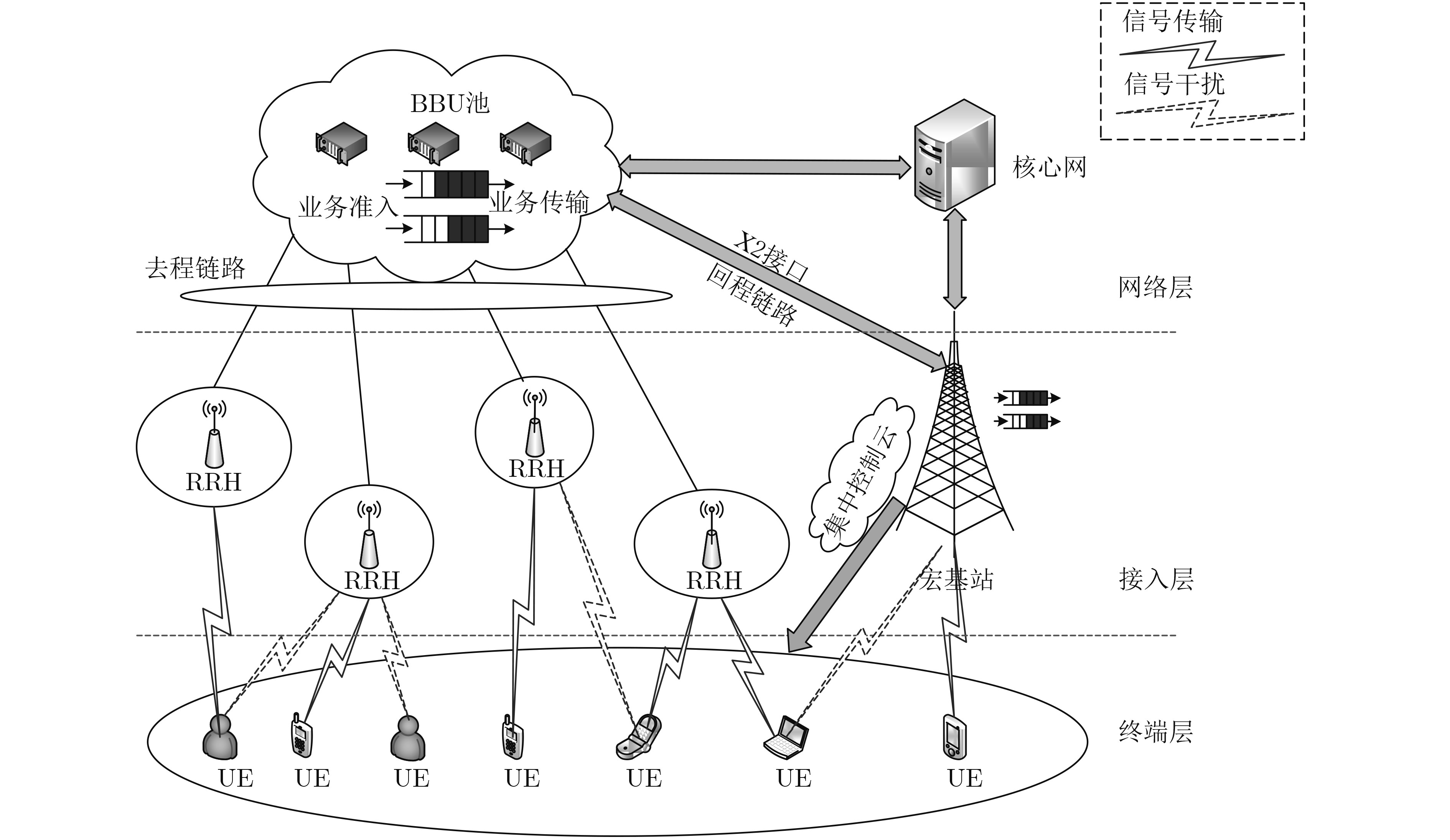
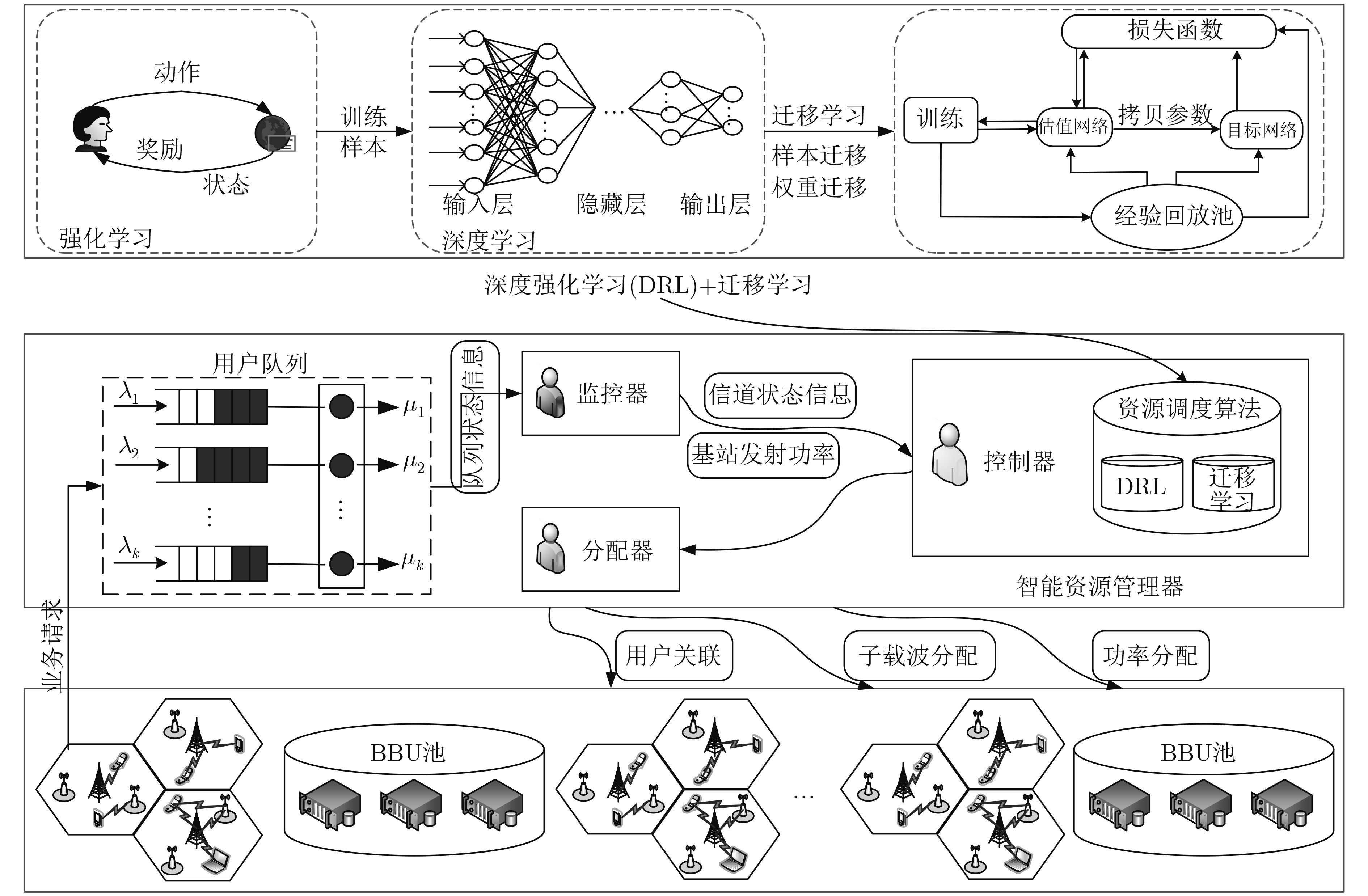
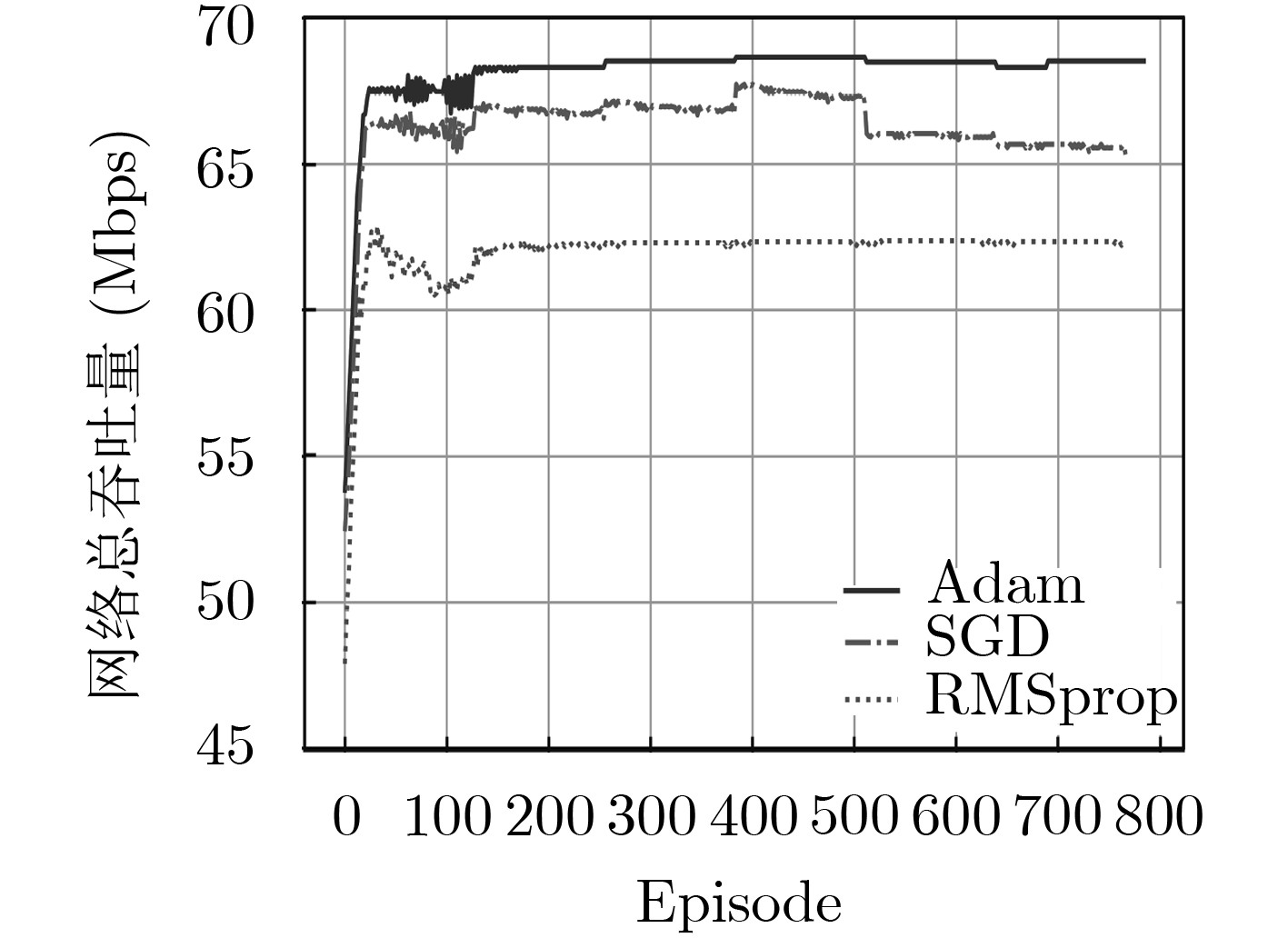
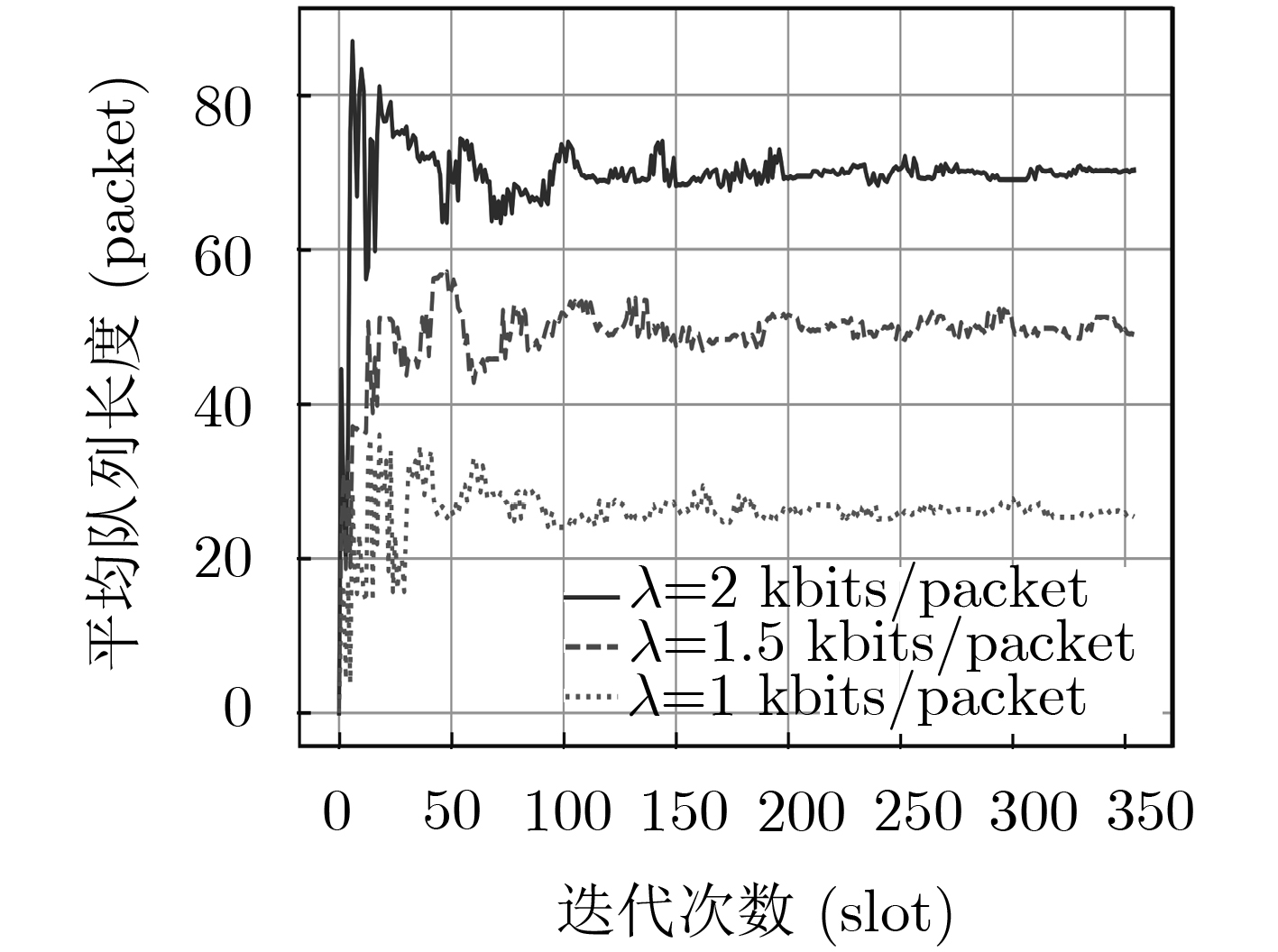
为了满足无线数据流量大幅增长的需求,异构云无线接入网(H-CRAN)的资源优化仍然是亟待解决的重要问题。该文在H-CRAN下行链路场景下,提出一种基于深度强化学习(DRL)的无线资源分配算法。首先,该算法以队列稳定为约束,联合优化拥塞控制、用户关联、子载波分配和功率分配,并建立网络总吞吐量最大化的随机优化模型。其次,考虑到调度问题的复杂性,DRL算法利用神经网络作为非线性近似函数,高效地解决维度灾问题。最后,针对无线网络环境的复杂性和动态多变性,引入迁移学习(TL)算法,利用TL的小样本学习特性,使得DRL算法在少量样本的情况下也能获得最优的资源分配策略。此外,TL通过迁移DRL模型的权重参数,进一步地加快了DRL算法的收敛速度。仿真结果表明,该文所提算法可以有效地增加网络吞吐量,提高网络的稳定性。
Abstract:In order to meet the demand of the substantial increase of wireless data traffic, the resource optimization of the Heterogeneous Cloud Radio Access Network (H-CRAN) is still an important problem that needs to be solved urgently. In this paper, under the H-CRAN downlink scenario, a wireless resource allocation algorithm based on Deep Reinforcement Learning (DRL) is proposed. Firstly, a stochastic optimization model for maximizing the total network throughput is established to jointly optimize the congestion control, the user association, subcarrier allocation and the power allocation under the constraint of queue stability. Secondly, considering the complexity of scheduling problem, the DRL algorithm uses neural network as nonlinear approximate function to solve the dimensional disaster problem efficiently. Finally, considering the complexity and dynamic variability of the wireless network environment, the Transfer Learning(TL) algorithm is introduced to make use of the small sample learning characteristics of TL so that the DRL algorithm can obtain the optimal resource allocation strategy in the case of insufficient samples. In addition, TL further accelerates the convergence rate of DRL algorithm by transferring the weight parameters of DRL model. Simulation results show that the proposed algorithm can effectively increase network throughput and improve network stability.
-
表 1 算法1
算法1:DQN训练估值网络参数算法 (1) 初始化经验回放池 (2) 随机初始化估值网络中的参数$w$,初始化目标网络中的参数
${w^ - }$,权重为${w^ - } = w$(3) For episode $k = 0,1, ···,K - 1$ do (4) 随机初始化一个状态${s_0}$ (5) For $t = 0,1, ···, T - 1$ do (6) 随机选择一个概率$p$ (7) if $p \le \varepsilon $ 资源管理器随机选择一个动作$a(t)$ (8) else 资源管理器根据估值网络选取动作
${a^*}(t) = \arg {\max _a}Q(s,a;w)$(9) 执行动作$a(t)$,根据式(9)得到奖励值$r(t)$,并观察下一
个状态$s(t + 1)$(10) 将元组$(s(t),a(t),r(t),s(t + 1))$存储到经验回放池中 (11) 从经验回放池中随机抽取选取一组样本
$(s(t),a(t),r(t),s(t + 1))$(12) 通过估值网络和目标网络的输出损失函数,利用式(13),
(14)计算1, 2阶矩(13) Adam算法通过式(15),式(16)计算1阶矩和2阶矩的偏差
修正项(14) 通过神经网络的反向传播算法,利用式(17)来更新估值
网络的权重参数$w$(15) 每隔$\delta $将估值网络中的参数$w$复制给参数${w^ - }$ (16) End for (17) End for (18) 获得DQN网络的最优权重参数$w$  下载: 导出CSV
下载: 导出CSV
表 2 算法2
算法2:基于TLDQN的策略知识迁移算法 (1) 初始化: (2) 源基站的DQN参数$w$,策略网络温度参数$T$,目标网络
的DQN参数$w'$(3) For 对于每个状态$s \in {{S}}$,源基站的动作$\overline a $,目标基站可能采
取的动作$a$ do(4) 执行算法1,得到估值网络的参数$w$,以及输出层对应的
$Q$值函数(5) 根据式(18)将源基站上的$Q$值函数转化为策略网络
${ {\pi} _i}(\overline a \left| s \right.)$(6) 根据式(19)将目标基站上的$Q$值函数转化为策略网络
${ {\pi} _{\rm{TG} } }(a\left| s \right.)$(7) 利用式(20)构建策略模仿损失的交叉熵$H(w)$ (8) 根据式(21)进行交叉熵的迭代更新,再进行策略模仿的偏
导数的计算。(9) 直至目标基站选取出的策略达到
${Q_{\rm{TG}}}(s,a) \to {Q^*}_{\rm{TG}}(s,a)$(10) End for (11) 目标基站获得对应的网络参数$w'$ (12) 执行算法1,目标基站得到最优资源分配策略
下载: 导出CSV
-
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. doi: 10.1038/nature14236 SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484–489. doi: 10.1038/nature16961 ZHANG Haijun, LIU Hao, CHENG Julian, et al. Downlink energy efficiency of power allocation and wireless backhaul bandwidth allocation in heterogeneous small cell networks[J]. IEEE Transactions on Communications, 2018, 66(4): 1705–1716. doi: 10.1109/TCOMM.2017.2763623 ZHANG Yuan, WANG Ying, and ZHANG Weidong. Energy efficient resource allocation for heterogeneous cloud radio access networks with user cooperation and QoS guarantees[C]. 2016 IEEE Wireless Communications and Networking Conference, Doha, Qatar, 2016: 1–6. doi: 10.1109/WCNC.2016.7565103. HE Ying, ZHANG Zheng, YU F R, et al. Deep-reinforcement-learning-based optimization for cache-enabled opportunistic interference alignment wireless networks[J]. IEEE Transactions on Vehicular Technology, 2017, 66(11): 10433–10445. doi: 10.1109/TVT.2017.2751641 唐伦, 魏延南, 马润琳, 等. 虚拟化云无线接入网络下基于在线学习的网络切片虚拟资源分配算法[J]. 电子与信息学报, 2019, 41(7): 1533–1539. doi: 10.11999/JEIT180771TANG Lun, WEI Yannan, MA Runlin, et al. Online learning-based virtual resource allocation for network slicing in virtualized cloud radio access network[J]. Journal of Electronics &Information Technology, 2019, 41(7): 1533–1539. doi: 10.11999/JEIT180771 LI Jian, PENG Mugen, YU Yuling, et al. Energy-efficient joint congestion control and resource optimization in heterogeneous cloud radio access networks[J]. IEEE Transactions on Vehicular Technology, 2016, 65(12): 9873–9887. doi: 10.1109/TVT.2016.2531184 NEELY M J. Stochastic network optimization with application to communication and queueing systems[J]. Synthesis Lectures on Communication Networks, 2010, 3(1): 1–211. doi: 10.2200/S00271ED1V01Y201006CNT007 KUMAR N, SWAIN S N, and MURTHY C S R. A novel distributed Q-learning based resource reservation framework for facilitating D2D content access requests in LTE-A networks[J]. IEEE Transactions on Network and Service Management, 2018, 15(2): 718–731. doi: 10.1109/TNSM.2018.2807594 SAAD H, MOHAMED A, and ELBATT T. A cooperative Q-learning approach for distributed resource allocation in multi-user femtocell networks[C]. 2014 IEEE Wireless Communications and Networking Conference, Istanbul, Turkey, 2014: 1490–1495. doi: 10.1109/WCNC.2014.6952410. PAN S J and YANG Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345–1359. doi: 10.1109/TKDE.2009.191 SUN Yaohua, PENG Mugen, and MAO Shiwen. Deep reinforcement learning-based mode selection and resource management for green fog radio access networks[J]. IEEE Internet of Things Journal, 2019, 6(2): 1960–1971. doi: 10.1109/JIOT.2018.2871020 PAN Jie, WANG Xuesong, CHENG Yuhu, et al. Multisource transfer double DQN based on actor learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(6): 2227–2238. doi: 10.1109/TNNLS.2018.2806087 ALQERM I and SHIHADA B. Sophisticated online learning scheme for green resource allocation in 5G heterogeneous cloud radio access networks[J]. IEEE Transactions on Mobile Computing, 2018, 17(10): 2423–2437. doi: 10.1109/TMC.2018.2797166 LI Yan, LIU Lingjia, LI Hongxiang, et al. Resource allocation for delay-sensitive traffic over LTE-Advanced relay networks[J]. IEEE Transactions on Wireless Communications, 2015, 14(8): 4291–4303. doi: 10.1109/TWC.2015.2418991 -

 下载:
下载:





计量
- 文章访问数: 4473
- HTML全文浏览量: 3460
- PDF下载量: 221
- 被引次数: 0
