

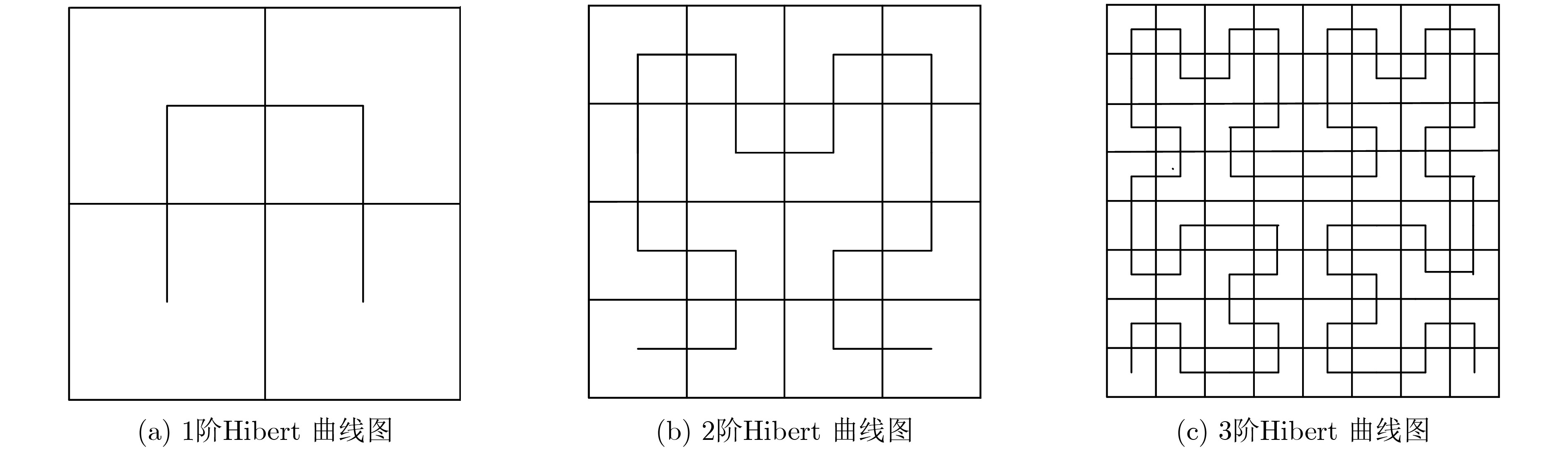
State View Based Efficient Hilbert Encoding and Decoding Algorithms
-
摘要:
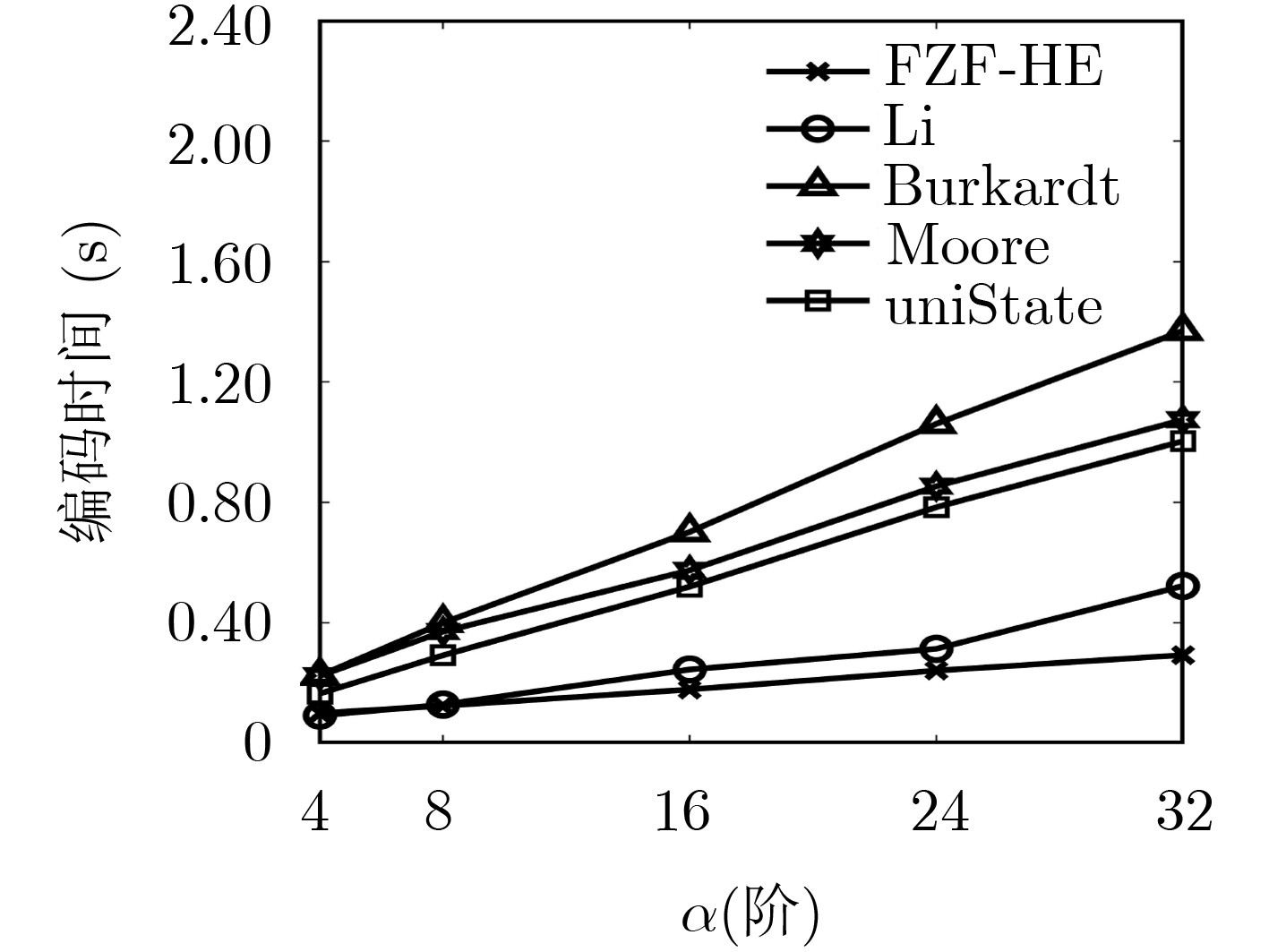
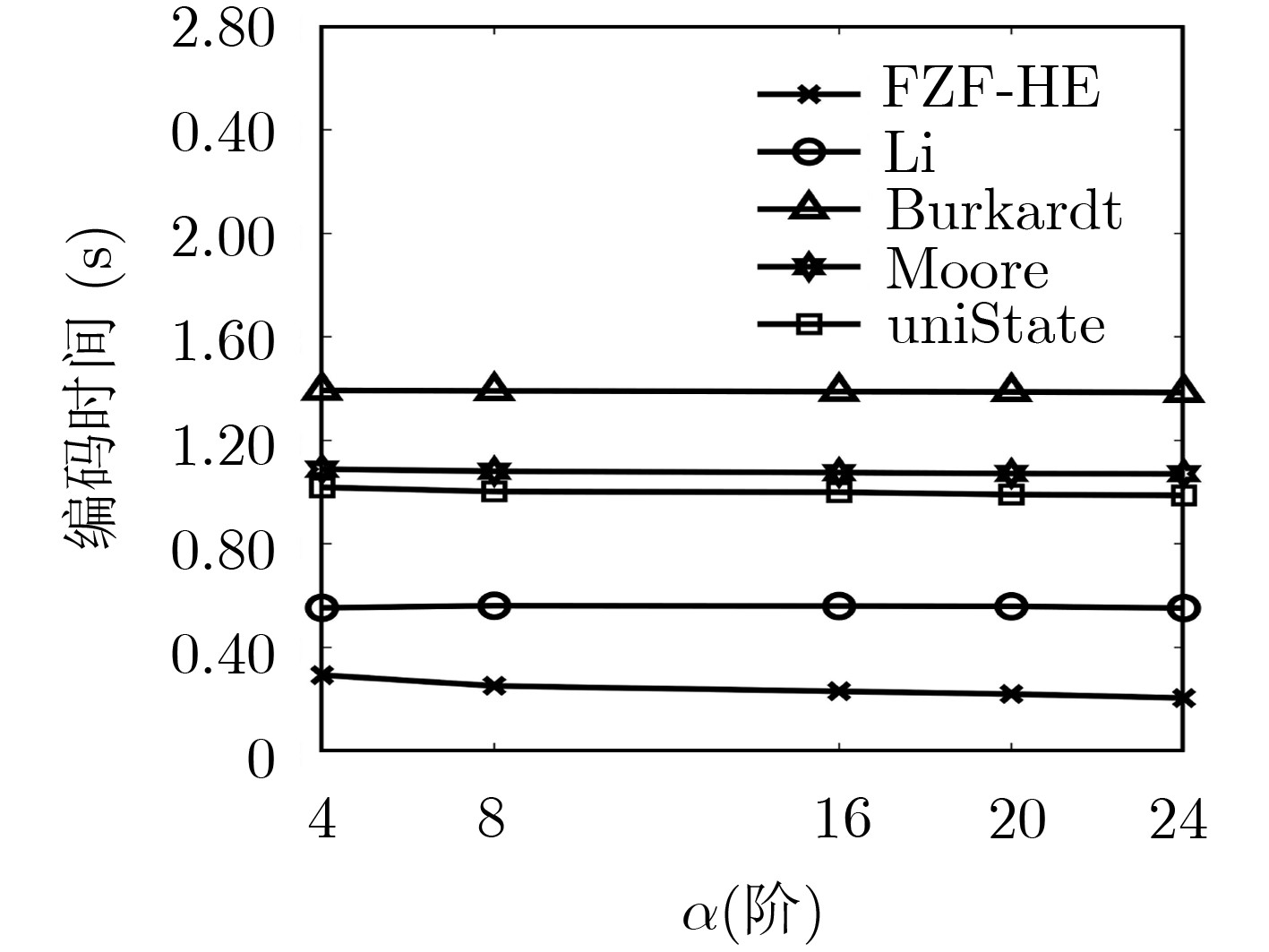
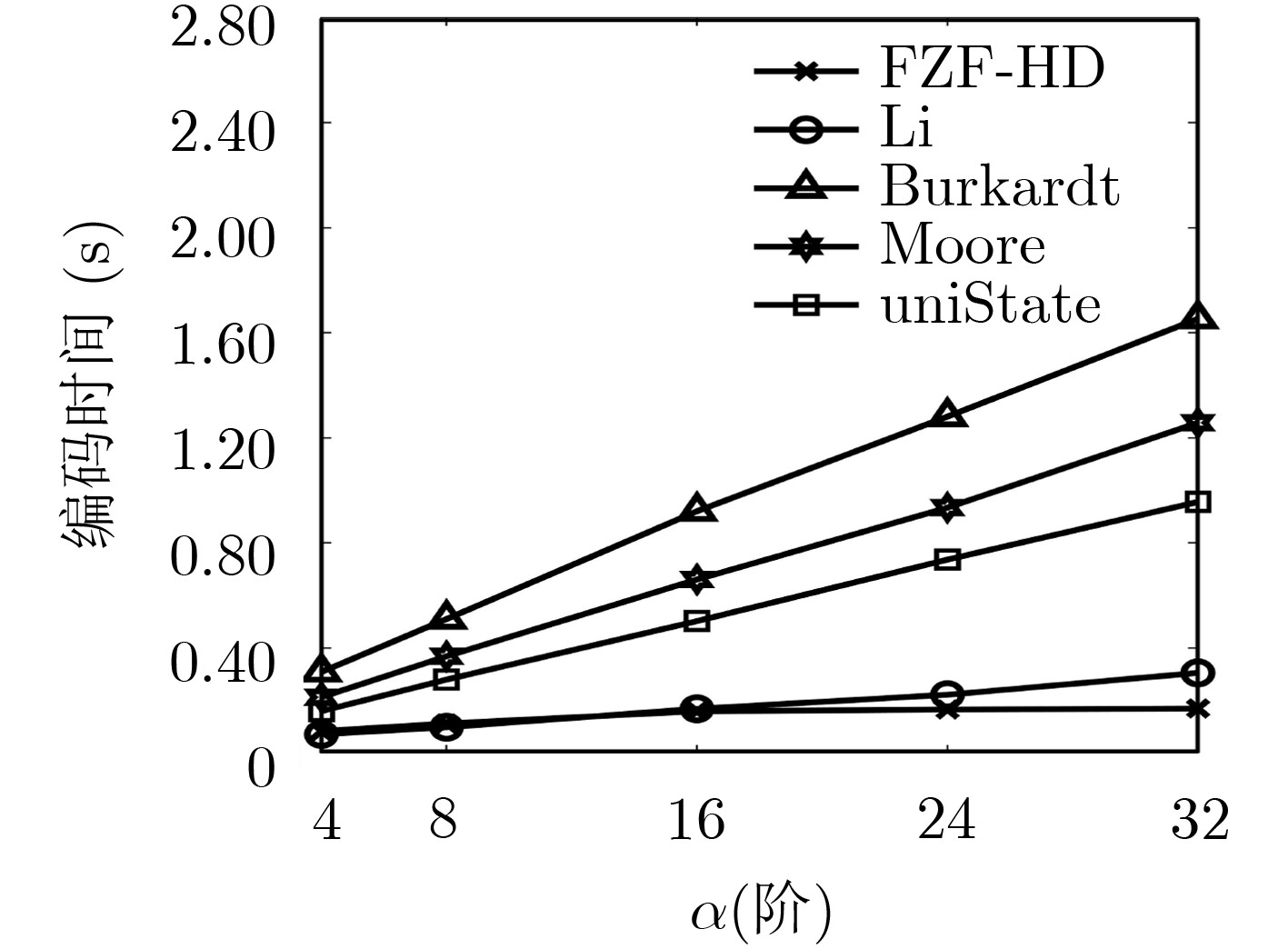
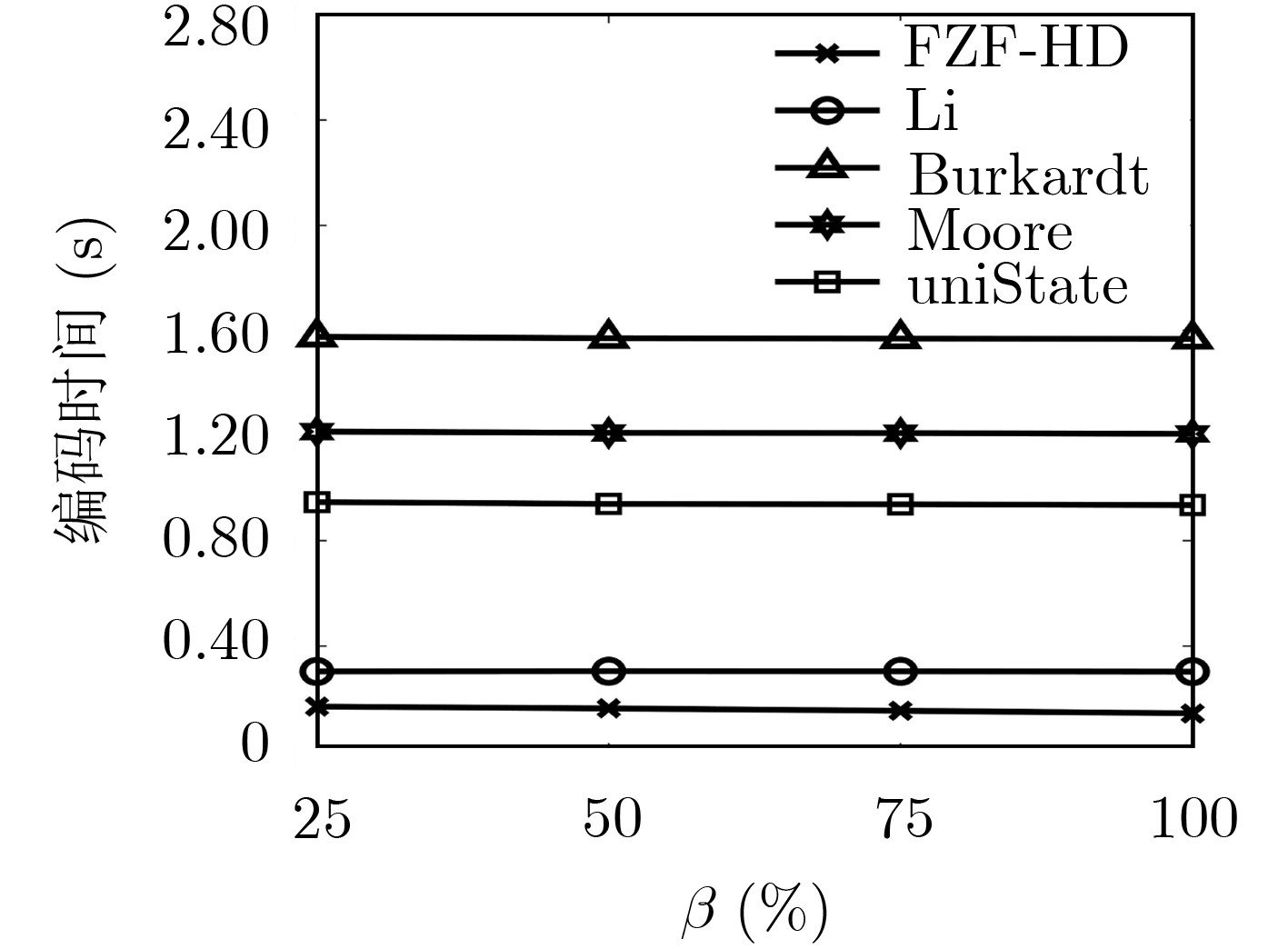
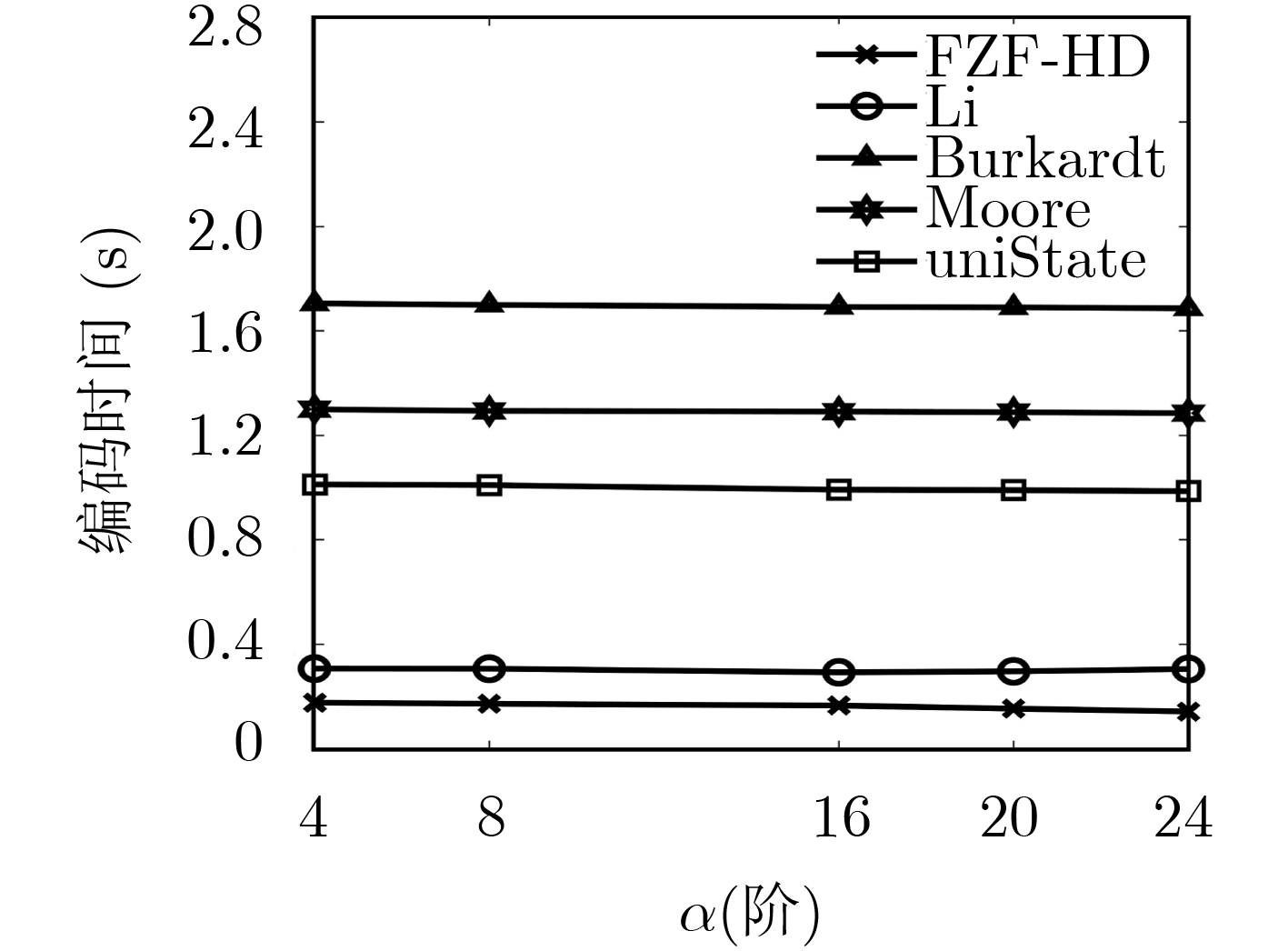
Hilbert曲线是高维降到1维的重要方法,具有较好的空间聚集和空间连续性,在地理信息系统、空间数据库、信息检索等方面有广泛的应用。现有Hilbert编码或解码算法未考虑输入数据对编码或解码效率的影响,因此将不同输入数据同等对待。为此,该文通过设计高效的状态视图并结合快速置位检测算法提出高效的免计前0的Hilbert编码算法(FZF-HE)和免计前0的Hilbert解码算法(FZF-HD),可快速识别输入数据前部为0而无需迭代计算的部分,从而降低迭代查询次数及算法复杂度,提高编解码效率。实验结果表明,FZF-HE算法和FZF-HD算法在数据均匀分布时效率稍高于现有算法,而在数据偏斜分布时效率远高于现有算法。
-
关键词:
- 状态视图 /
- 免计前0的Hilbert编码算法 /
- 免计前0的Hilbert解码算法 /
- Hilbert曲线
Abstract:Hilbert curve is an important method for high-dimensional reduction to one-dimensional. It has good characteristics of spatial aggregation and spatial continuity and is widely used in geographic information system, spatial databases and information retrieval. Existing Hilbert encoding or decoding algorithms do not consider the differences between input data, thus treating them equally. To this end, an efficient Hilbert coding algorithm Front-Zero-Free Hilbert Encoding(FZF-HE) and an efficient decoding algorithm Front-Zero-Free Hilbert Decoding(FZF-HD) are proposed. FZF-HE and FZF-HD can quickly identify the 0 s of the front part of input data before iterative calculation by combining efficient state views and first bit-1 detection algorithm, thus reducing the number of iterations and the complexity of the algorithm, and improving the encoding and decoding efficiency. The experimental results show that efficiencies of these two algorithms are slightly higher than existing algorithms for uniform distributed data, and are much higher than existing algorithms for skew distributed data.
-
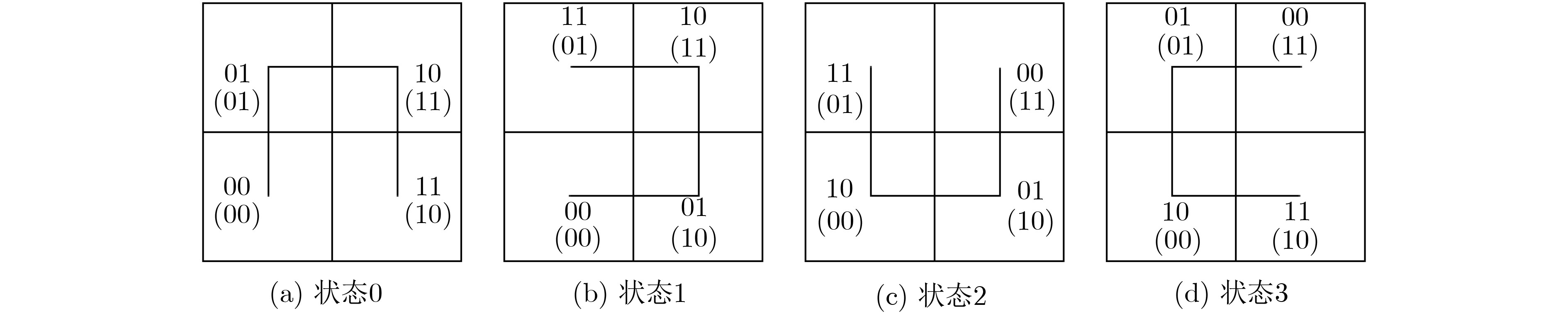
表 1 编码状态视图
状态 0 0 0 0 1 1 1 1 2 2 2 2 3 3 3 3 坐标 00 01 10 11 00 01 10 11 00 01 10 11 00 01 10 11 编码 00 01 11 10 00 11 01 10 10 11 01 00 10 01 11 00 下阶状态 1 0 3 0 0 2 1 1 2 1 2 3 3 3 0 2  下载: 导出CSV
下载: 导出CSV
表 2 解码状态视图
状态 0 0 0 0 1 1 1 1 2 2 2 2 3 3 3 3 编码 00 01 10 11 00 01 10 11 00 01 10 11 00 01 10 11 坐标 00 01 11 10 00 10 11 01 11 10 00 01 11 01 00 10 下阶状态 1 0 0 3 0 1 1 2 3 2 2 1 2 3 3 0
下载: 导出CSV
表 3 FZF-HE算法
输入:X,横坐标 Y,纵坐标 n,阶 输出:Hilbert编码$Z$ (1) Z←0 (2) $p$←${\rm{msb}}(\max(X,Y))$//置位检测 (3) $t$←($n$-$p$-1)%2//计算第$n$-$p$阶状态 (4) for $i$ from $n$-$p$ to $n$ (5) $Z{\rm{ = }}Z{{ < < 2 | {\rm{Key}}[}}t{\rm{][}}{x_i}{\rm{][}}{y_i}{\rm{] }}$//查Key视图 (6) $t{\rm{ = Type[}}t{\rm{][}}{x_i}{\rm{][}}{y_i}{\rm{]}}$//查Type视图
下载: 导出CSV
表 4 FZF-HD算法
输入:$Z$,Hilbert编码 n,阶 输出:X,横坐标 Y,纵坐标 (1) $X$, $Y$←0 (2) $p$←${\rm{msb}}(Z)$//置位检测 (3) $t$←($n$-$p$/2-1)//计算第$n$-$p$/2阶状态 (4) for $i$ from $n$-$p$/2 to $n$ (5) ${\rm{coord}} = {\rm{InvKey}}[t][{z_{2i - 1}}{z_{2i}}]$ //查InvKey视图 (6) $ Y = Y < < 1 | {\rm{coord}} \& 0{\rm{x}}1 $ $ X = X < < 1 | {\rm{coord}} > > 1\& 0{\rm{x}}1 $ (7) $t = {\rm{InvType}}[t][{z_{2i - 1}}{z_{2i}}]$//查InvType视图
下载: 导出CSV
-
GUNTHER S and STOCCO L. Generation of spatial orders and space-filling curves[J]. IEEE Transactions on Image Processing, 2015, 24(6): 1791–1800. doi: 10.1109/TIP.2015.2409571 周映虹, 马争鸣. 基于层次模型的重要性编码算法[J]. 电子与信息学报, 2009, 31(6): 1497–1500.ZHOU Yinghong and MA Zhengming. A significance coding algorithm based on layer model[J]. Journal of Electronics &Information Technology, 2009, 31(6): 1497–1500. CHEN Lu, GAO Yunjun, LI Xinhan, et al. Efficient metric indexing for similarity search and similarity joins[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(3): 556–571. doi: 10.1109/TKDE.2015.2506556 SINGH H and BAWA S. A survey of traditional and mapReduceBased spatial query processing approaches[J]. ACM SIGMOD Record, 2017, 46(2): 18–29. doi: 10.1145/3137586.3137590 ABDULJABBAR M, MARKOMANOLIS G S, IBEID H, et al. Communication reducing algorithms for distributed hierarchical N-Body problems with boundary distributions[C]. The 32nd International Supercomputing Conference, Frankfurt, Germany, 2017: 79–96. LIU Hui, WANG Kun, YANG Bo, et al. Dynamic load balancing using hilbert space-filling curves for parallel reservoir simulations[C]. The SPE Reservoir Simulation Conference, Montgomery, USA, 2017. doi: 10.2118/182613-MS. HAN Guangjie, XUAN Xuan, LIU Li, et al. A disaster management-oriented path planning for mobile anchor node-based localization in wireless sensor networks[J]. IEEE Transactions on Emerging Topics in Computing, 2020, 8(1): 115–125. doi: 10.1109/TETC.2017.2687319 KONG Lingping, PAN J S, SUNG T W, et al. An energy balancing strategy based on hilbert curve and genetic algorithm for wireless sensor networks[J]. Wireless Communications and Mobile Computing, 2017, 2017: 5720659. BOHM C, PERDACHER M, and PLANT C. A novel hilbert curve for cache-locality preserving loops[J]. IEEE Transactions on Big Data, To be published. doi: 10.1109/TBDATA.2018.2830378 MORTON G M. A computer oriented geodetic data base and a new technique in file sequencing[EB/OL]. https://domino.research.ibm.com/library/cyberdig.nsf/0/0dabf9473b9c86d48525779800566a39?OpenDocument, 1966. BUTZ A R. Alternative algorithm for Hilbert's space-filling curve[J]. IEEE Transactions on Computers, 1971, C-20(4): 424–426. doi: 10.1109/T-C.1971.223258 MOON B, JAGADISH H V, FALOUTSOS C, et al. Analysis of the clustering properties of the hilbert space-filling curve[J]. IEEE Transactions on Knowledge and Data Engineering, 2001, 13(1): 124–141. doi: 10.1109/69.908985 NAGARKAR P, CANDAN K S, and BHAT A. Compressed spatial hierarchical bitmap (cSHB) indexes for efficiently processing spatial range query workloads[J]. Proceedings of The VLDB Endowment, 2015, 8(12): 1382–1393. doi: 10.14778/2824032.2824038 CHRISTOFORAKI M, HE Jinru, DIMOPOULOS C, et al. Text vs. space: Efficient geo-search query processing[C]. The 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 2011: 423–432. FISHER A J. A new algorithm for generating Hilbert curves[J]. Practice and Experience, 1986, 16(1): 5–12. doi: 10.1002/spe.4380160103 李绍俊, 钟耳顺, 王少华, 等. 基于状态转移矩阵的Hilbert码快速生成算法[J]. 地球信息科学学报, 2014, 16(6): 846–851.LI Shaojun, ZHONG Ershun, WANG Shaohua, et al. An algorithm for Hilbert ordering code based on state-transition matrix[J]. Journal of Geo-Information Science, 2014, 16(6): 846–851. XCTORRES. Hilbert_spatial_index[EB/OL]. https://github.com/xcTorres/hilbert_spatial_index, 2017. BURKARDT J. HILBERT_CURVE convert between 1D and 2D coordinates of Hilbert curve[EB/OL]. http://people.math.sc.edu/Burkardt/c_src/hilbert_curve/hilbert_curve.html, 2015. MOORE D. Fast Hilbert curve generation, sorting, and range queries[EB/OL]. https://github.com/Cheedoong/hilbert, 2016. 曹雪峰, 万刚, 张宗佩. 紧致的Hilbert曲线Gray码索引算法[J]. 测绘学报, 2016, 45(S1): 90–98. doi: 10.11947/j.AGCS.2016.F010CAO Xuefeng, WAN Gang, and ZHANG Zongpei. Compact Hilbert curve index algorithm based on Gray code[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(S1): 90–98. doi: 10.11947/j.AGCS.2016.F010 LI R. Hilbert range query decomosition[EB/OL]. https://github.com/cloudray8580/Hilbert RangeQueryDecomosition, 2019. ZHANG Jian and KAMATA S I. A generalized 3-D Hilbert scan using look-up tables[J]. Journal of Visual Communication and Image Representation, 2012, 23(3): 418–425. doi: 10.1016/j.jvcir.2011.12.005 LIU Hui, CUI Tao, LENG Wei, et al. Encoding and decoding algorithms for arbitrary dimensional Hilbert order[J]. 2016, arXiv: 1601.01274. 刘辉, 冷伟, 崔涛. 高维Hilbert曲线的编码与解码算法设计[J]. 数值计算与计算机应用, 2015, 36(1): 42–58.LIU Hui, LENG Wei, and CUI Tao. Development of encoding and decoding algorithms for high dimensional Hilbert curves[J]. Journal on Numerical Methods and Computer Applications, 2015, 36(1): 42–58. ROSETTA. Find first and last set bit of a long integer[EB/OL]. http://rosettacode.org/wiki/Find_first_and_last_set_bit_of_a_long_integer, 2019. -

 下载:
下载:







计量
- 文章访问数: 2985
- HTML全文浏览量: 1300
- PDF下载量: 84
- 被引次数: 0
