

Dynamic Resource Allocation and Energy Management Algorithm for Hybrid Energy Supply in Heterogeneous Cloud Radio Access Networks
-
摘要:
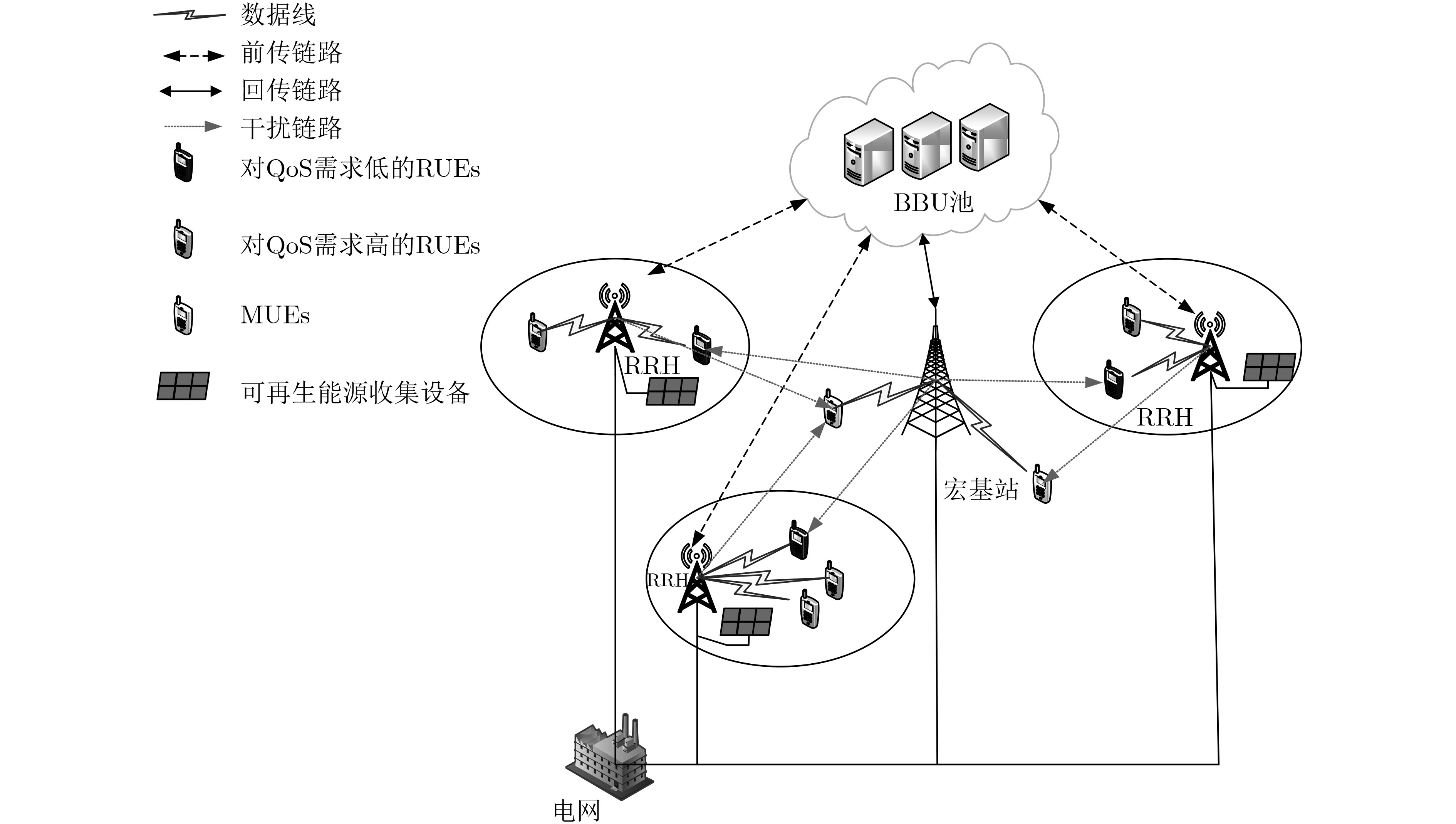
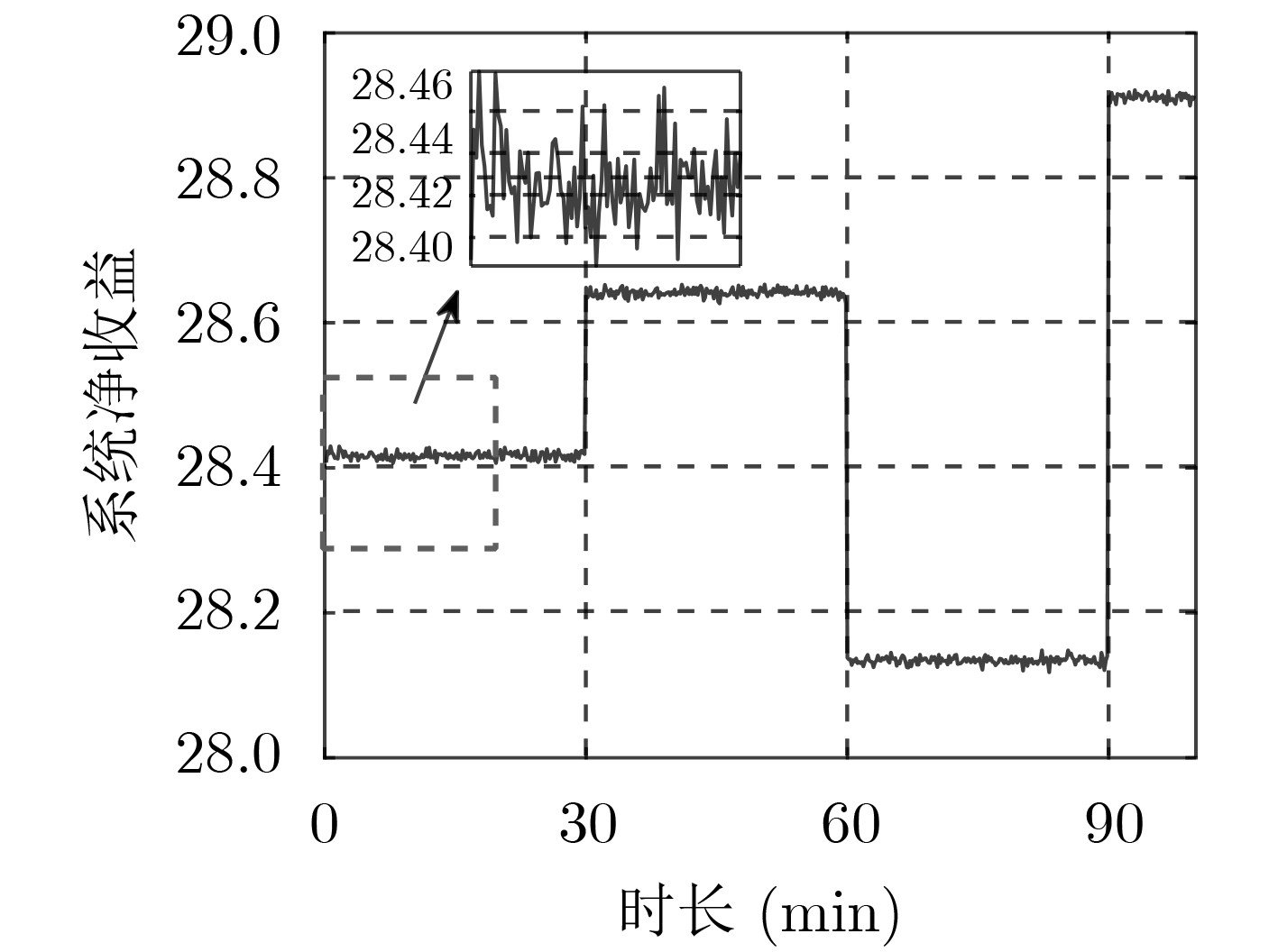
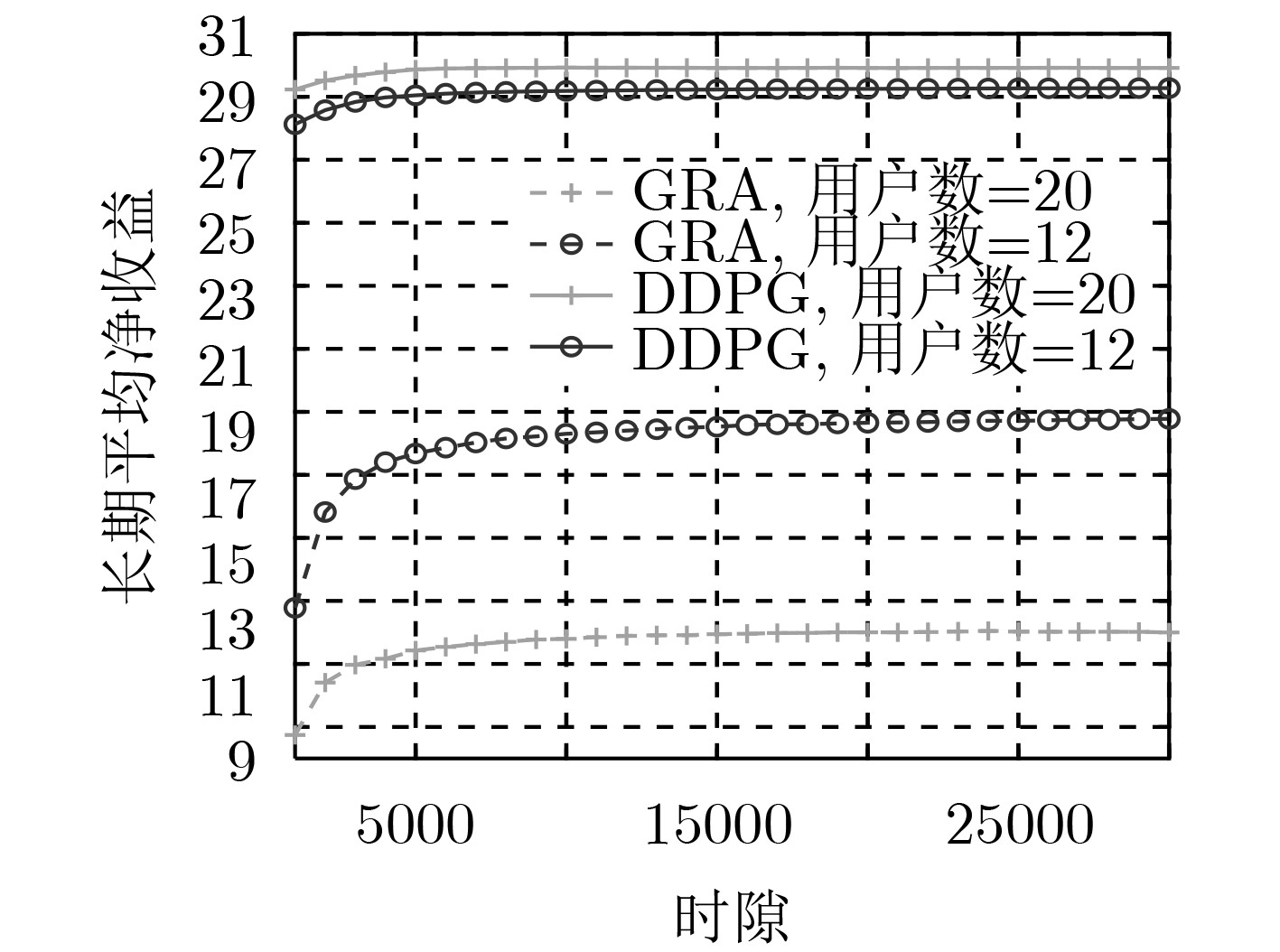
针对面向混合能源供应的 5G 异构云无线接入网(H-CRANs)网络架构下的动态资源分配和能源管理问题,该文提出一种基于深度强化学习的动态网络资源分配及能源管理算法。首先,由于可再生能源到达的波动性及用户数据业务到达的随机性,同时考虑到系统的稳定性、能源的可持续性以及用户的服务质量(QoS)需求,将H-CRANs网络下的资源分配以及能源管理问题建立为一个以最大化服务提供商平均净收益为目标的受限无穷时间马尔科夫决策过程(CMDP)。然后,使用拉格朗日乘子法将所提CMDP问题转换为一个非受限的马尔科夫决策过程(MDP)问题。最后,因为行为空间与状态空间都是连续值集合,因此该文利用深度强化学习解决上述MDP问题。仿真结果表明,该文所提算法可有效保证用户QoS及能量可持续性的同时,提升了服务提供商的平均净收益,降低了能耗。
Abstract:Considering the dynamic resource allocation and energy management problem in the 5G Heterogeneous Cloud Radio Access Networks(H-CRANs) architecture for hybrid energy supply, a dynamic network resource allocation and energy management algorithm based on deep reinforcement learning is proposed. Firstly, due to the volatility of renewable energy and the randomness of user data service arrival, taking into account the stability of the system, the sustainability of energy and the Quality of Service(QoS) requirements of users, the resource allocation and energy management issues in the H-CRANs network as a Constrained infinite time Markov Decision Process (CMDP) are modeled with the goal of maximizing the average net profit of service providers. Then, the Lagrange multiplier method is used to transform the proposed CMDP problem into an unconstrained Markov Decision Process (MDP) problem. Finally, because the action space and the state space are both continuous value sets, the deep reinforcement learning is used to solve the above MDP problem. The simulation results show that the proposed algorithm can effectively guarantee the QoS and energy sustainability of the system, while improving the average net income of the service provider and reducing energy consumption.
-
表 1 算法流程表
算法1:基于DDPG算法的资源分配与能源管理算法 (1)初始化 随机初始化参数${\theta ^Q}$和${\theta ^\mu }$;初始化目标网络参数:${\theta ^{Q'}} \leftarrow {\theta ^Q}$,${\theta ^{\mu '}} \leftarrow {\theta ^\mu }$;初始化拉格朗日乘子${\xi _u} \ge 0,\forall u \in { {{U} }_{\rm{RRH} } },{\upsilon _u} \ge 0,$
$\forall u \in { {{U} }_{\rm{MBS} } } $;初始化经验回放池D(2)学习阶段 For episode=1 to M do 初始化一个随机过程作为行为噪声${{N}}$,并观察初始状态${x_0}$ For t=1 to T do 根据${a_t} = \mu ({x_t}|\theta _t^\mu ) + {{N}}$选择一个行为 if 约束C3-C13满足: 执行行动${a_t}$,并得到回报值${r_{{t}}}$与下一状态${x_{t + 1}}$ 将状态转换组$ < {x_t},{a_t},{r_t},{x_{t + 1}} > $存入经验回放池D 从经验回放池D中随机采样${N_{\rm{D}}}$个样本,每个样本用i表示 (a) 更新评判家网络 从行动者目标网络得到$\mu '({x_{i + 1}}|{\theta ^{\mu '}})$ 从评判家目标网络中得到$Q({s_{i + 1}},\mu '({x_{i + 1}}|{\theta ^{\mu '}})|{\theta ^{Q'}})$ 根据式(20)得到${y_i}$,从评判家网络得到$Q({x_i},{a_i}|{\theta ^Q})$ 根据式(21)计算损失函数,并根据式(19)更新评判家网络参数${\theta ^Q}$ (b) 更新行动者网络 从评判家网络得到$Q({x_i},{a_i}|{\theta ^Q})$,并根据式(22)计算策略梯度 根据策略梯度更新行动者网络参数${\theta ^\mu }$ (c) 更新行动者目标网络和评判家目标网络 根据式(23)更新行动者目标网络和评判家网络参数 (d)基于标准次梯度法[15]更新拉格朗日乘子 ${\xi _{u,t + 1} } \leftarrow {\left[ { {\xi _{u,t} } - {\alpha _\xi }({Q_{ {\max} } } - { {\bar Q}_u})} \right]^ + },\forall u \in { {{U} }_{ {\rm{RRH} } } }\;\;\;\;\;\;\;\;\;\;(24)$ ${\nu _{u,t + 1} } \leftarrow {\left[ { {\nu _{u,t} } - {\alpha _\nu }({Q_{ {\max} } } - { {\bar Q}_u})} \right]^ + },\forall u \in { {{U} }_{ {\rm{MBS} } } }\;\;\;\;\;\;\;\;\;\;(25)$ End for End for  下载: 导出CSV
下载: 导出CSV
表 2 仿真参数
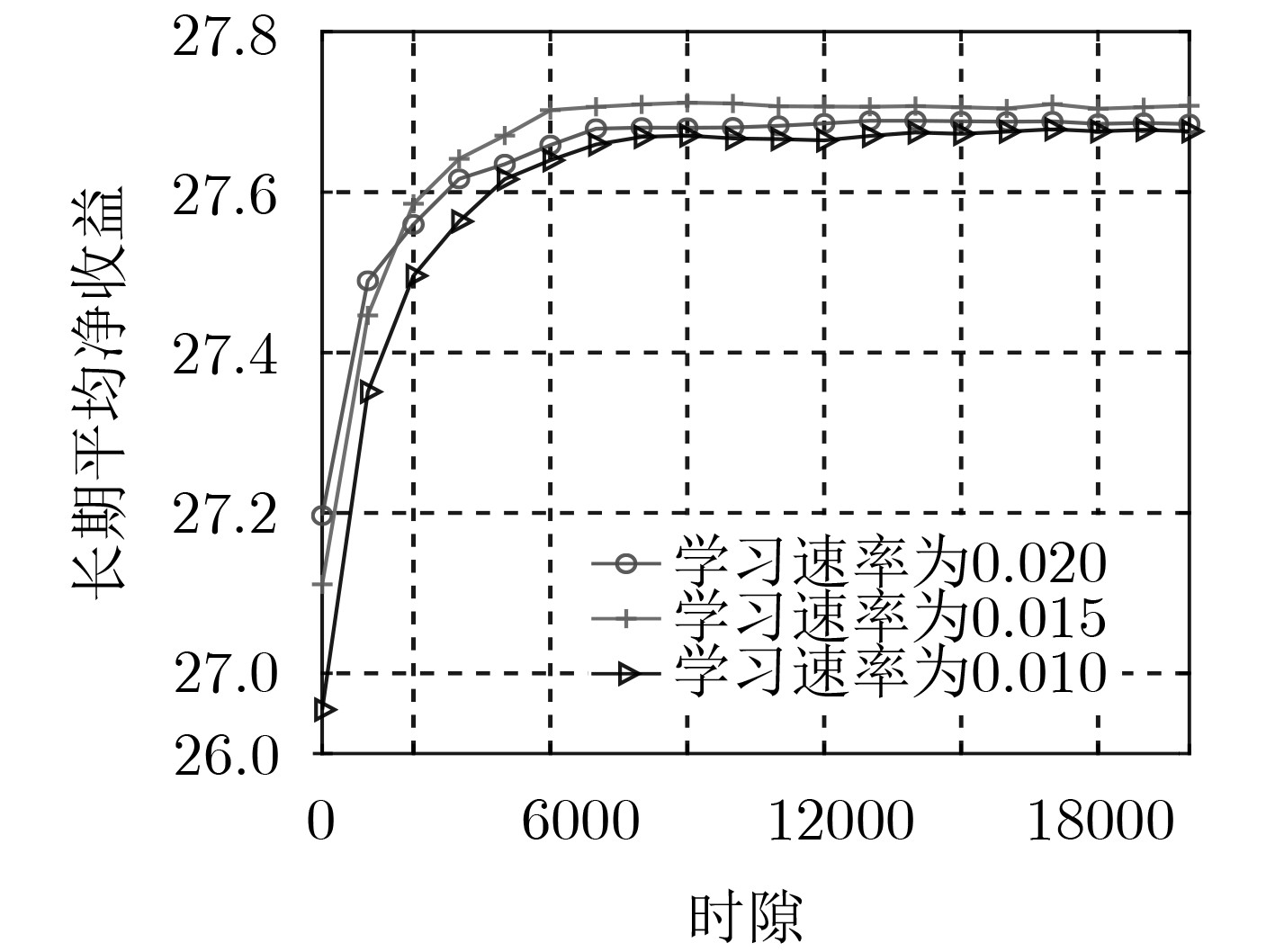
仿真参数 值 仿真参数 值 RRH最大发射功率 3 W 数据包大小$L$ 4 kbit/packet MBS最大发射功率 10 W MUEs路径损耗模型 31.5+35lg(d) (d[km]) 热噪声功率谱密度 –102 dBm/Hz RUEs路径损耗模型 31.5+40lg(d) (d[km]) 子载波个数$N$ 12 折扣因子$\gamma $ 0.99 单个资源块带宽 180 kHz ${r_{{{{\varGamma}} _1}}}$ 4 Mbps 软更新因子$\varsigma $ 0.01 ${r_{{{{\varGamma}} _2}}}$ 4.5 Mbps 时隙长度$\tau $ 10 ms ${r_{{\rm{MBS}}}}$ 512 kbps
下载: 导出CSV
-
彭木根, 艾元. 异构云无线接入网络: 原理、架构、技术和挑战[J]. 电信科学, 2015, 31(5): 41–45.PENG Mugen and AI Yuan. Heterogeneous cloud radio access networks: Principle, architecture, techniques and challenges[J]. Telecommunications Science, 2015, 31(5): 41–45. ALNOMAN A, CARVALHO G H S, ANPALAGAN A, et al. Energy efficiency on fully cloudified mobile networks: Survey, challenges, and open issues[J]. IEEE Communications Surveys & Tutorials, 2018, 20(2): 1271–1291. doi: 10.1109/COMST.2017.2780238 AKTAR M R, JAHID A, AL-HASAN M, et al. User association for efficient utilization of green energy in cloud radio access network[C]. 2019 International Conference on Electrical, Computer and Communication Engineering, Cox’sBazar, Bangladesh, 2019: 1–5. doi: 10.1109/ECACE.2019.8679128. ALQERM I and SHIHADA B. Sophisticated online learning scheme for green resource allocation in 5G heterogeneous cloud radio access networks[J]. IEEE Transactions on Mobile Computing, 2018, 17(10): 2423–2437. doi: 10.1109/TMC.2018.2797166 LIU Qiang, HAN Tao, ANSARI N, et al. On designing energy-efficient heterogeneous cloud radio access networks[J]. IEEE Transactions on Green Communications and Networking, 2018, 2(3): 721–734. doi: 10.1109/TGCN.2018.2835451 吴晓民. 能量捕获驱动的异构网络资源调度与优化研究[D]. [博士论文], 中国科学技术大学, 2016.WU Xiaomin. Resources optimization and control in the energy harvesting heterogeneous network[D]. [Ph.D. dissertation], University of Science and Technology of China, 2016. ZHANG Deyu, CHEN Zhigang, CAI L X, et al. Resource allocation for green cloud radio access networks with hybrid energy supplies[J]. IEEE Transactions on Vehicular Technology, 2018, 67(2): 1684–1697. doi: 10.1109/TVT.2017.2754273 孔巧. 混合能源供能的异构蜂窝网络中能源成本最小化问题的研究[D]. [硕士论文], 华中科技大学, 2016.KONG Qiao. Research on energy cost minimization problem in heterogeneous cellular networks with hybrid energy supplies[D]. [Master dissertation], Huazhong University of Science and Technology, 2016. YANG Jian, YANG Qinghai, SHEN Zhong, et al. Suboptimal online resource allocation in hybrid energy supplied OFDMA cellular networks[J]. IEEE Communications Letters, 2016, 20(8): 1639–1642. doi: 10.1109/LCOMM.2016.2575834 WEI Yifei, YU F R, SONG Mei, et al. User scheduling and resource allocation in HetNets with hybrid energy supply: An actor-critic reinforcement learning approach[J]. IEEE Transactions on Wireless Communications, 2018, 17(1): 680–692. doi: 10.1109/TWC.2017.2769644 PENG Mugen, ZHANG Kecheng, JIANG Jiamo, et al. Energy-efficient resource assignment and power allocation in heterogeneous cloud radio access networks[J]. IEEE Transactions on Vehicular Technology, 2015, 64(11): 5275–5287. doi: 10.1109/TVT.2014.2379922 陈前斌, 杨友超, 周钰, 等. 基于随机学习的接入网服务功能链部署算法[J]. 电子与信息学报, 2019, 41(2): 417–423. doi: 10.11999/JEIT180310CHEN Qianbin, YANG Youchao, ZHOU Yu, et al. Deployment algorithm of service function chain of access network based on stochastic learning[J]. Journal of Electronics &Information Technology, 2019, 41(2): 417–423. doi: 10.11999/JEIT180310 深度强化学习-DDPG算法原理和实现[EB/OL]. https://www.jianshu.com/p/6fe18d0d8822, 2018. 齐岳, 黄硕华. 基于深度强化学习DDPG算法的投资组合管理[J]. 计算机与现代化, 2018(5): 93–99. doi: 10.3969/j.issn.1006-2475.2018.05.019QI Yue and HUANG Shuohua. Portfolio management based on DDPG algorithm of deep reinforcement learning[J]. Computer and Modernization, 2018(5): 93–99. doi: 10.3969/j.issn.1006-2475.2018.05.019 California ISO[EB/OL]. http://www.caiso.com, 2019. WANG Xin, ZHANG Yu, CHEN Tianyi, et al. Dynamic energy management for smart-grid-powered coordinated multipoint systems[J]. IEEE Journal on Selected Areas in Communications, 2016, 34(5): 1348–1359. doi: 10.1109/JSAC.2016.2520220 LI Jian, PENG Mugen, YU Yuling, et al. Energy-efficient joint congestion control and resource optimization in heterogeneous cloud radio access networks[J]. IEEE Transactions on Vehicular Technology, 2016, 65(12): 9873–9887. doi: 10.1109/TVT.2016.2531184 -

 下载:
下载:





计量
- 文章访问数: 2626
- HTML全文浏览量: 1032
- PDF下载量: 84
- 被引次数: 0
