

Motion Defocus Infrared Image Restoration Based on Multi Scale Generative Adversarial Network
-
摘要:
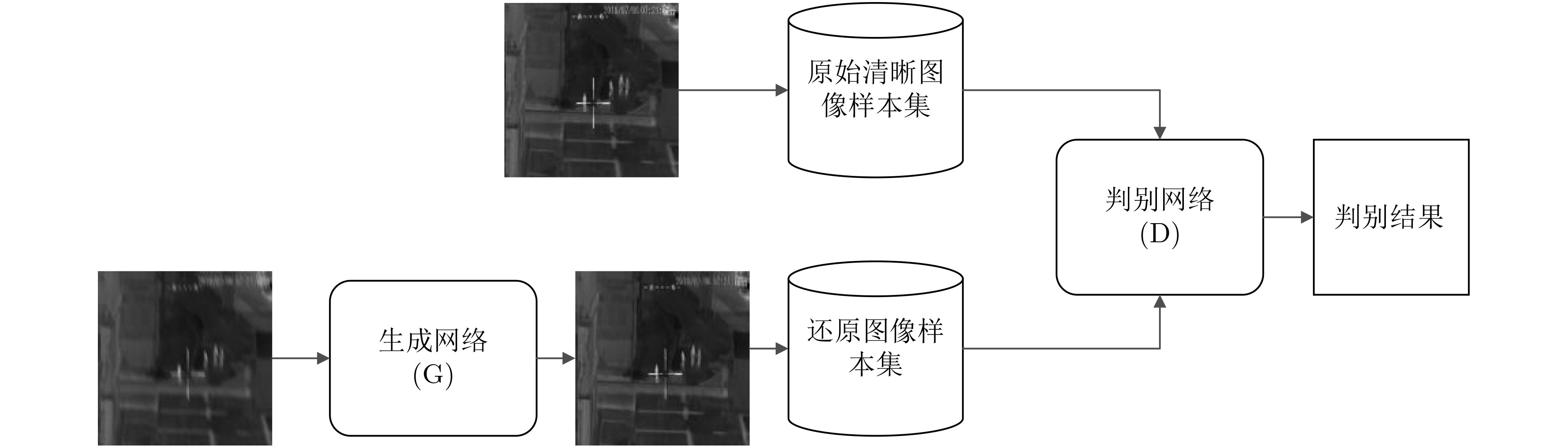
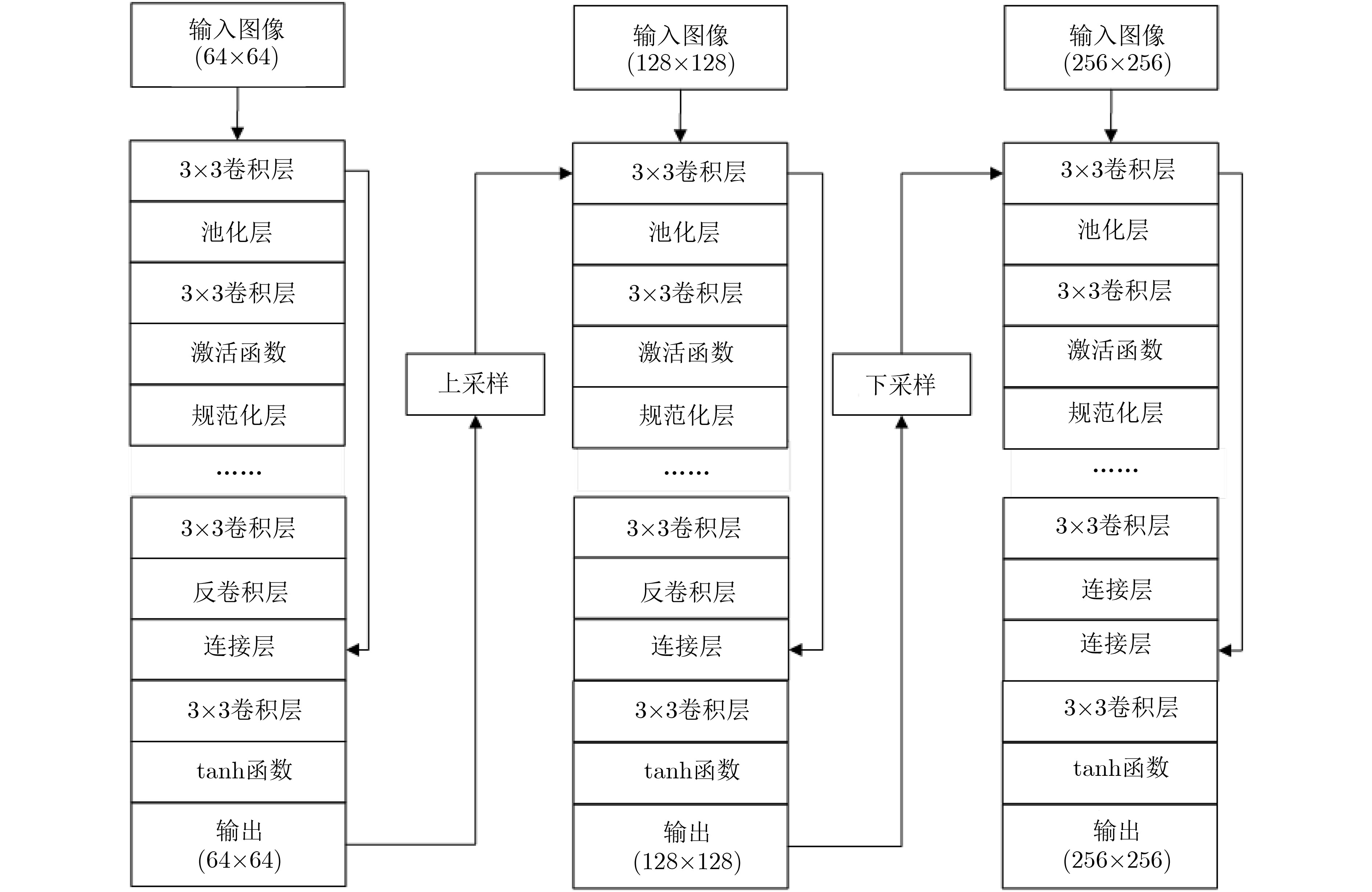
红外热成像系统在夜间实施目标识别与检测优势明显,而移动平台上动态环境所导致的运动散焦模糊影响上述成像系统的应用。该文针对上述问题,基于生成对抗网络开展运动散焦后红外图像复原方法研究,采用生成对抗网络抑制红外图像的运动散焦模糊,提出一种针对红外图像的多尺度生成对抗网络(IMdeblurGAN)在高效抑制红外图像运动散焦模糊的同时保持红外图像细节对比度,提升移动平台上夜间目标的检测与识别能力。实验结果表明:该方法相对已有最优模糊图像复原方法,图像峰值信噪比(PSNR)提升5%,图像结构相似性(SSIMx)提升4%,目标识别YOLO置信度评分提升6%。
Abstract:Infrared thermal imaging system has obvious advantages in target recognition and detection at night, and the motion defocus blur caused by dynamic environment on mobile platform affects the application of the above imaging system. In order to solve the above problems, based on the research of infrared image restoration method after motion defocusing using generating confrontation network, a Infrared thermal image Multi scale deblurGenerative Adversarial Network (IMdeblurGAN) is proposed to suppress motion defocusing blurring effectively while preserving the image by using generating confrontation network to suppress the motion defocusing blurring of infrared image to hold the contrast of infrared image details, to improve the detection and recognition ability of night targets on motion platform. The experimental results show that compared with the existing optimal restoration methods for blurred images, Peak Signal to Noise Ratio (PSNR) of the image is increased by 5%, the Structure SIMilarity (SSIM) is increased by 4%, and the confidence score of YOLO for target recognition is increased by 6%.
-
表 1 复原性能对比分析
复原方法 平均峰值信噪比 (dB) 平均结构相似性 Wiener 21.3 0.62 LR 22.5 0.65 DeblurGAN 27.0 0.75 SRN-DeblurNet 30.5 0.88 本文IMdeblurGAN 32.0 0.92  下载: 导出CSV
下载: 导出CSV
表 2 YOLO V3置信度对比分析
原始图像 运动散焦图像 Wiener逆滤波 LR迭代去卷积 DeblurGAN SRN-DeblurNet 本文IMdeblurGAN YOLOV3 评分 0.97 不能识别 不能识别 不能识别 0.77 0.89 0.95
下载: 导出CSV
-
崔美玉. 论红外热像仪的应用领域及技术特点[J]. 中国安防, 2014(12): 90–93. doi: 10.3969/j.issn.1673-7873.2014.12.026CUI Meiyu. On the application field and technical characteristics of infrared thermal imager[J]. China Security &Protection, 2014(12): 90–93. doi: 10.3969/j.issn.1673-7873.2014.12.026 KUPYN O, BUDZAN V, MYKHAILYCH M, et al. DeblurGAN: Blind motion deblurring using conditional adversarial networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8183–8192. TAO Xin, GAO Hongyun, SHEN Xiaoyong, et al. Scale-recurrent network for deep image deblurring[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8174–8182. HE Zewei, CAO Yanpeng, DONG Yafei, et al. Single-image-based nonuniformity correction of uncooled long-wave infrared detectors: A deep-learning approach[J]. Applied Optics, 2018, 57(18): D155–D164. doi: 10.1364/AO.57.00D155 邵保泰, 汤心溢, 金璐, 等. 基于生成对抗网络的单帧红外图像超分辨算法[J]. 红外与毫米波学报, 2018, 37(4): 427–432. doi: 10.11972/j.issn.1001-9014.2018.04.009SHAO Baotai, TANG Xinyi, JIN Lu, et al. Single frame infrared image super-resolution algorithm based on generative adversarial nets[J]. Journal of Infrared and Millimeter Wave, 2018, 37(4): 427–432. doi: 10.11972/j.issn.1001-9014.2018.04.009 刘鹏飞, 赵怀慈, 曹飞道. 多尺度卷积神经网络的噪声模糊图像盲复原[J]. 红外与激光工程, 2019, 48(4): 0426001. doi: 10.3788/IRLA201948.0426001LIU Pengfei, ZHAO Huaici, and CAO Feidao. Blind deblurring of noisy and blurry images of multi-scale convolutional neural network[J]. Infrared and Laser Engineering, 2019, 48(4): 0426001. doi: 10.3788/IRLA201948.0426001 BOUSMALIS K, SILBERMAN N, DOHAN D, et al. Unsupervised pixel-level domain adaptation with generative adversarial networks[C]. The 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 95–104. 李凌霄, 冯华君, 赵巨峰, 等. 红外焦平面阵列的盲元自适应快速校正[J]. 光学精密工程, 2017, 25(4): 1009–1018. doi: 10.3788/OPE.20172504.1009LI Lingxiao, FENG Huajun, ZHAO Jufeng, et al. Adaptive and fast blind pixel correction of IRFPA[J]. Optics and Precision Engineering, 2017, 25(4): 1009–1018. doi: 10.3788/OPE.20172504.1009 DONG Chao, LOY C, HE Kaiming, et al. Learning a deep convolutional network for image super-resolution[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 184–199. EFRAT N, GLASNER D, APARTSIN A, et al. Accurate blur models vs. image priors in single image super-resolution[C]. The 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 2013: 2832–2839. HE Anfeng, LUO Chong, TIAN Xinmei, et al. A twofold Siamese network for real-time object tracking[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4834–4843. LIN Zhouchen and SHUM H Y. Fundamental limits of reconstruction-based superresolution algorithms under local translation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1): 83–97. doi: 10.1109/TPAMI.2004.1261081 杨阳, 杨静宇. 基于显著性分割的红外行人检测[J]. 南京理工大学学报, 2013, 37(2): 251–256.YANG Yang and YANG Jingyu. Infrared pedestrian detection based on saliency segmentation[J]. Journal of Nanjing University of Science and Technology, 2013, 37(2): 251–256. PINNEGAR C R and MANSINHA L. Time-local spectral analysis for non-stationary time series: The S-transform for noisy signals[J]. Fluctuation and Noise Letters, 2003, 3(3): L357–L364. doi: 10.1142/S0219477503001439 CAO Yanpeng and TISSE C L. Single-image-based solution for optics temperature-dependent nonuniformity correction in an uncooled long-wave infrared camera[J]. Optics Letters, 2014, 39(3): 646–648. doi: 10.1364/OL.39.000646 REAL E, SHLENS J, MAZZOCCHI S, et al. YouTube-boundingboxes: A large high-precision human-annotated data set for object detection in video[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7464–7473. WU Yi, LIM J, and YANG M H. Online object tracking: A benchmark[C]. The 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 2411–2418. doi: 10.1109/CVPR.2013.312. WANG Zhou, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600–612. doi: 10.1109/TIP.2003.819861 KIM J, LEE J K, and LEE K M. Accurate image super-resolution using very deep convolutional networks[C]. The 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1646–1654. doi: 10.1109/CVPR.2016.182. KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386 -


 下载:
下载:






计量
- 文章访问数: 3389
- HTML全文浏览量: 1765
- PDF下载量: 128
- 被引次数: 0
