

Image-to-image Translation Based on Improved Cycle-consistent Generative Adversarial Network
-
摘要:
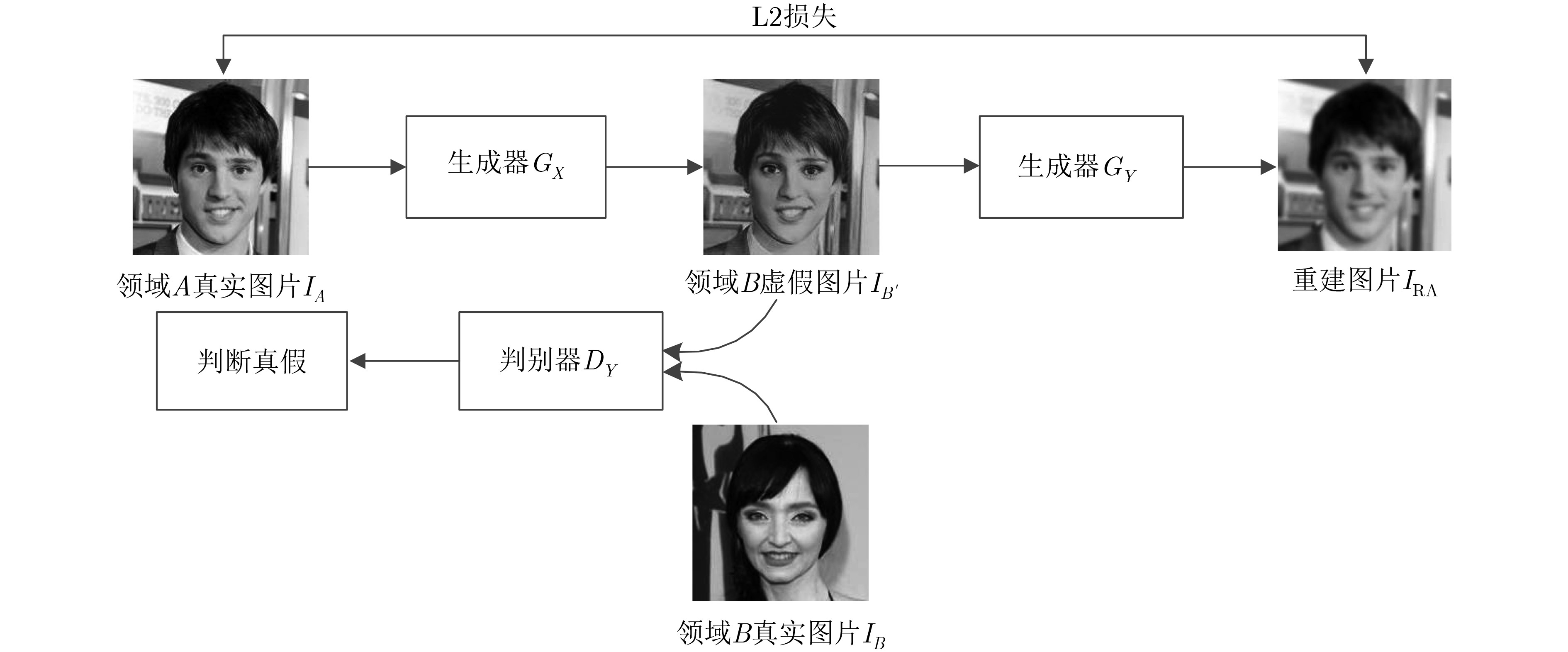
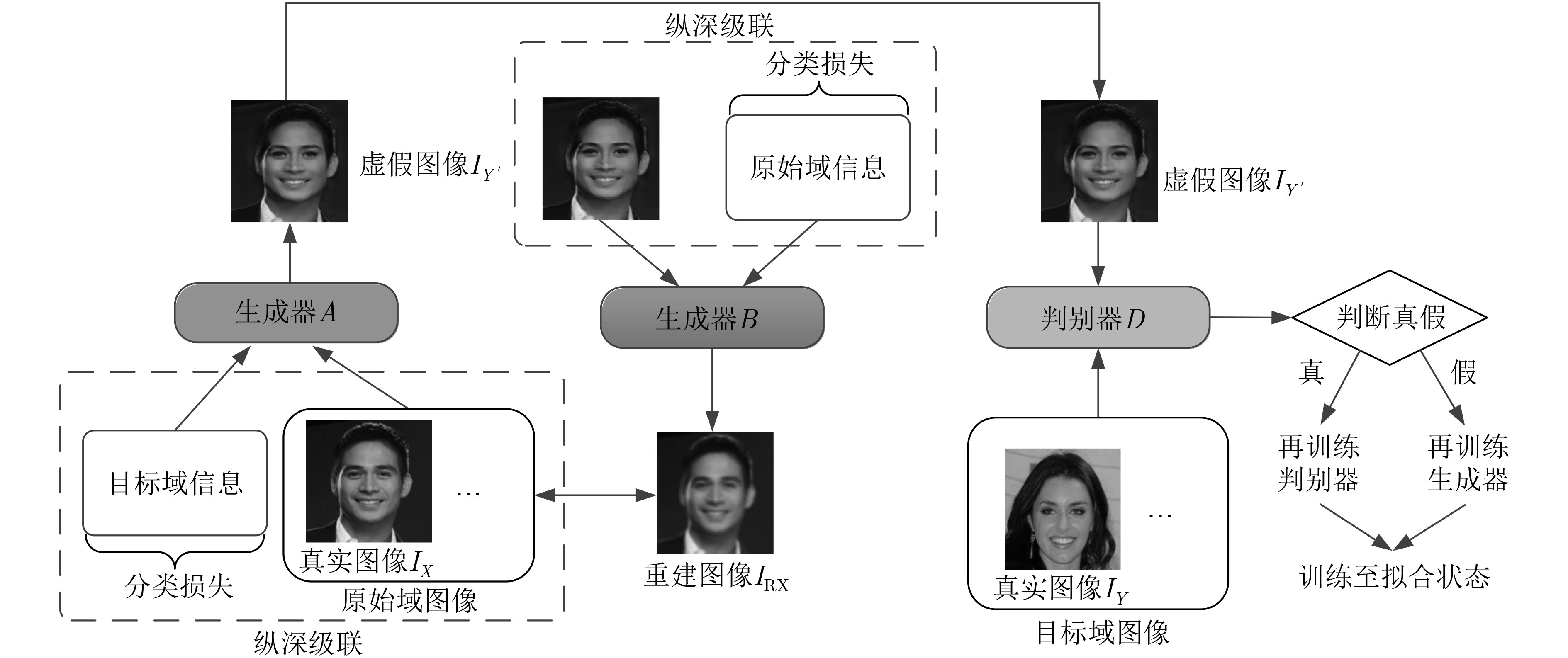
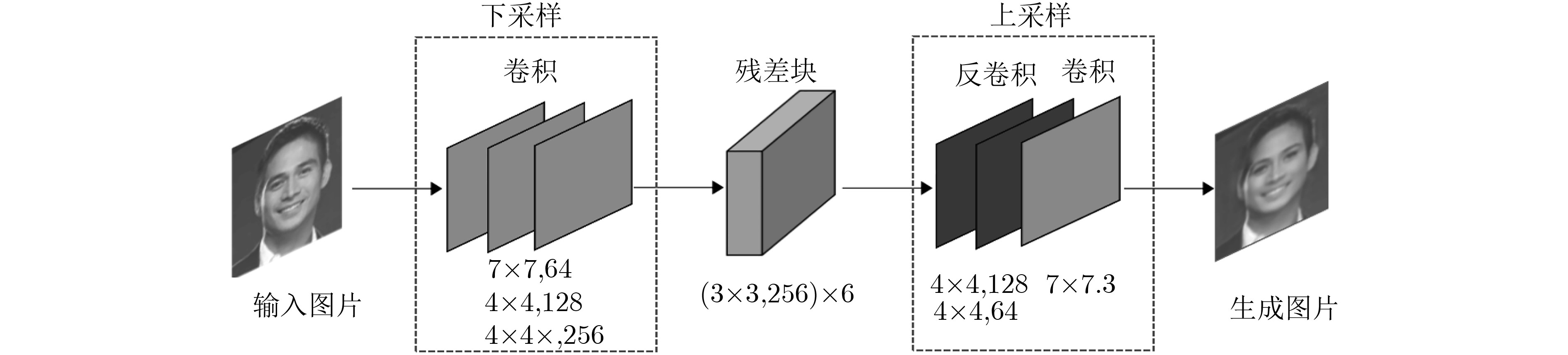
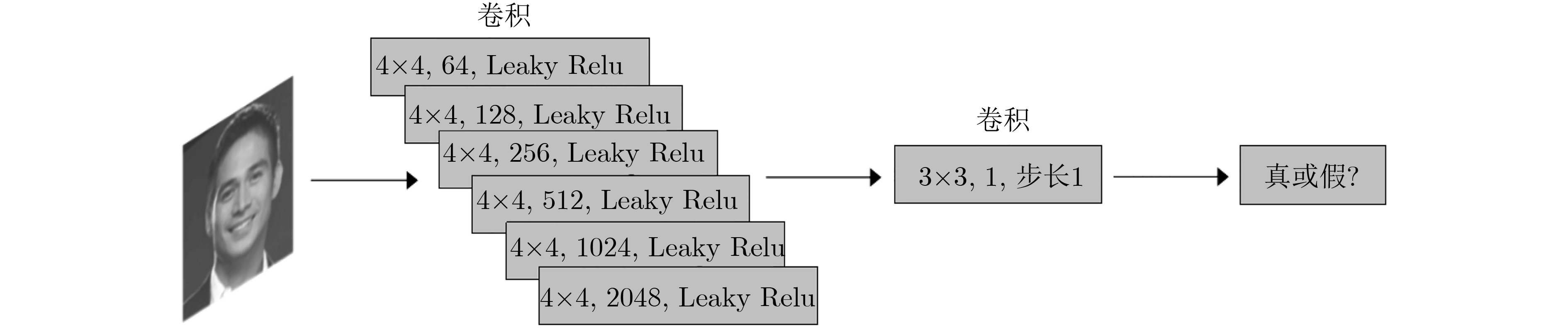
图像间的风格迁移是一类将图片在不同领域进行转换的方法。随着生成式对抗网络在深度学习中的快速发展,其在图像风格迁移领域中的应用被日益关注。但经典算法存在配对训练数据较难获取,生成图片效果差的缺点。该文提出一种改进循环生成式对抗网络(CycleGAN++),取消了环形网络,并在图像生成阶段将目标域与源域的先验信息与相应图片进行纵深级联;优化了损失函数,采用分类损失代替循环一致损失,实现了不依赖训练数据映射的图像风格迁移。采用CelebA和Cityscapes数据集进行实验评测,结果表明在亚马逊劳务平台感知研究(AMT perceptual studies)与全卷积网络得分(FCN score)两个经典测试指标中,该文算法比CycleGAN, IcGAN, CoGAN, DIAT等经典算法取得了更高的精度。
Abstract:Image-to-image translation is a method to convert images in different domains. With the rapid development of the Generative Adversarial Network(GAN) in deep learning, GAN applications are increasingly concerned in the field of image-to-image translation. However, classical algorithms have disadvantages that the paired training data is difficult to obtain and the convert effect of generation image is poor. An improved Cycle-consistent Generative Adversarial Network(CycleGAN++) is proposed. New algorithm removes the loop network, and cascades the prior information of the target domain and the source domain in the image generation stage, The loss function is optimized as well, using classification loss instead of cycle consistency loss, realizing image-to-image translation without training data mapping. The evaluation of experiments on the CelebA and Cityscapes dataset show that new method can reach higher precision under the two classical criteria—Amazon Mechanical Turk perceptual studies(AMT perceptual studies) and Full-Convolutional Network score(FCN score), than the classical algorithms such as CycleGAN, IcGAN, CoGAN, and DIAT.
-
表 1 CycleGAN+与原算法的AMT测试结果对比(%)
方法 男性→女性 女性→男性 照片→标签 标签→照片 CycleGAN 24.6±2.3 21.1±1.8 26.8±2.8 23.2±3.4 CycleGAN+ 29.5±3.2 29.2±4.1 27.8±2.2 28.2±2.4  下载: 导出CSV
下载: 导出CSV
表 3 CycleGAN++与CycleGAN+的AMT感知研究结果对比(%)
方法 男性→女性 女性→男性 照片→标签 标签→照片 CycleGAN+ 29.5±3.2 29.2±4.1 27.8±2.2 28.2±2.4 本文CycleGAN++ 31.4±3.8 32.6±4.7 30.1±2.6 30.9±2.7
下载: 导出CSV
表 4 CycleGAN++与CycleGAN+的FCN得分结果对比
方法 每像素精度 每类精度 IoU分类 CycleGAN+ 0.60 0.21 0.16 本文CycleGAN++ 0.69 0.27 0.23
下载: 导出CSV
-
HERTZMANN A, JACOBS C E, OLIVER N, et al. Image analogies[C]. The 28th Annual Conference on Computer Graphics and Interactive Techniques, New York, USA, 2001: 327–340. doi: 10.1145/383259.383295. GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. RADFORD A, METZ L, and CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. https://arxiv.org/abs/1511.06434, 2015. ARJOVSKY M, CHINTALA S, and BOTTOU L. Wasserstein GAN[EB/OL]. https://arxiv.org/abs/1701.07875, 2017. GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wasserstein GANs[C]. The 31st International Conference on Neural Information Processing Systems, Red Hook, USA, 2017: 5769–5779. ISOLA P, ZHU Junyan, ZHOU Tinghui, et al. Image-to-image translation with conditional adversarial networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 5967–5976. doi: 10.1109/CVPR.2017.632. MIRZA M and OSINDERO S. Conditional generative adversarial nets[EB/OL]. https://arxiv.org/abs/1411.1784, 2014. ROSALES R, ACHAN K, and FREY B. Unsupervised image translation[C]. The 9th IEEE International Conference on Computer Vision, Nice, France, 2003: 472–478. doi: 10.1109/ICCV.2003.1238384. LIU Mingyu, BREUEL T, KAUTZ J, et al. Unsupervised image-to-image translation networks[C]. The 31st Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 700–708. LIU Mingyu and TUZEL O. Coupled generative adversarial networks[C]. The 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 469–477. KINGMA D P and WELLING M. Auto-encoding variational bayes[EB/OL]. https://arxiv.org/abs/1312.6114, 2013. ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2242–2251. doi: 10.1109/ICCV.2017.244. KIM T, CHA M, KIM H, et al. Learning to discover cross-domain relations with generative adversarial networks[C]. The 34th International Conference on Machine Learning, Sydney, Australia, 2017: 1857–1865. YI Zili, ZHANG Hao, TAN Ping, et al. DualGAN: Unsupervised dual learning for image-to-image translation[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2868–2876. doi: 10.1109/ICCV.2017.310. BOUSMALIS K, SILBERMAN N, DOHAN D, et al. Unsupervised pixel-level domain adaptation with generative adversarial networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 95–104. doi: 10.1109/CVPR.2017.18. SHRIVASTAVA A, PFISTER T, TUZEL O, et al. Learning from simulated and unsupervised images through adversarial training[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2242–2251. doi: 10.1109/CVPR.2017.241. TAIGMAN Y, POLYAK A, and Wolf L. Unsupervised cross-domain image generation[EB/OL]. https://arxiv.org/abs/1611.02200, 2016. LI Chuan and WAND M. Precomputed real-time texture synthesis with markovian generative adversarial networks[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 702–716. doi: 10.1007/978-3-319-46487-9_43. LIU Ziwei, LUO Ping, WANG Xiaogang, et al. Deep learning face attributes in the wild[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 3730–3738. doi: 10.1109/ICCV.2015.425. KINGMA D P and BA J. Adam: A method for stochastic optimization[EB/OL]. https://arxiv.org/abs/1412.6980, 2014. LI Mu, ZUO Wangmeng, and ZHANG D. Deep identity-aware transfer of facial attributes[EB/OL]. https://arxiv.org/abs/1610.05586, 2016. PERARNAU G, VAN DE WEIJER J, RADUCANU B, et al. Invertible conditional GANs for image editing[EB/OL]. https://arxiv.org/abs/1611.06355, 2016. -

 下载:
下载:





计量
- 文章访问数: 5520
- HTML全文浏览量: 3073
- PDF下载量: 323
- 被引次数: 0
