

Integrated Navigation Algorithm for Large Concave Obstacles
-
摘要:
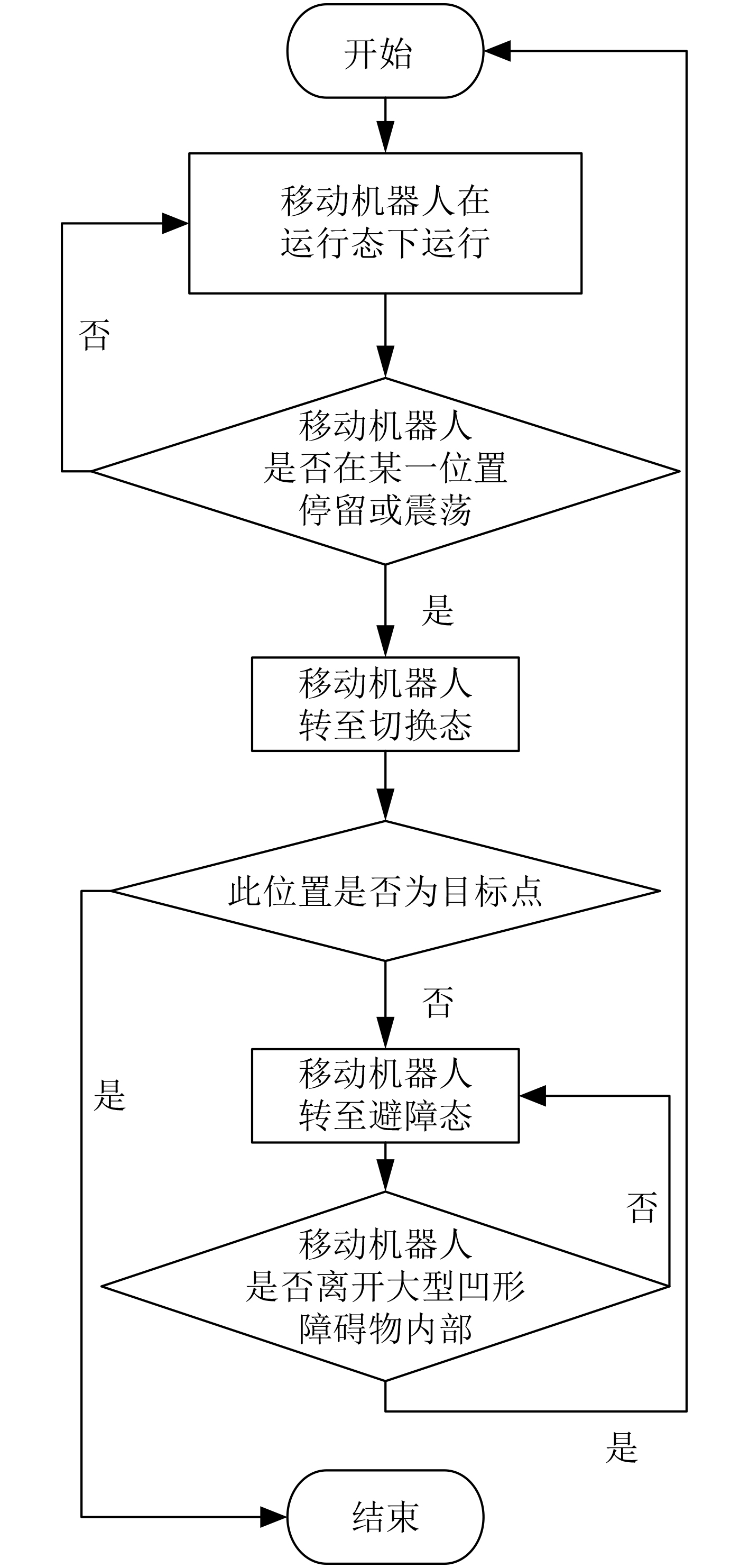
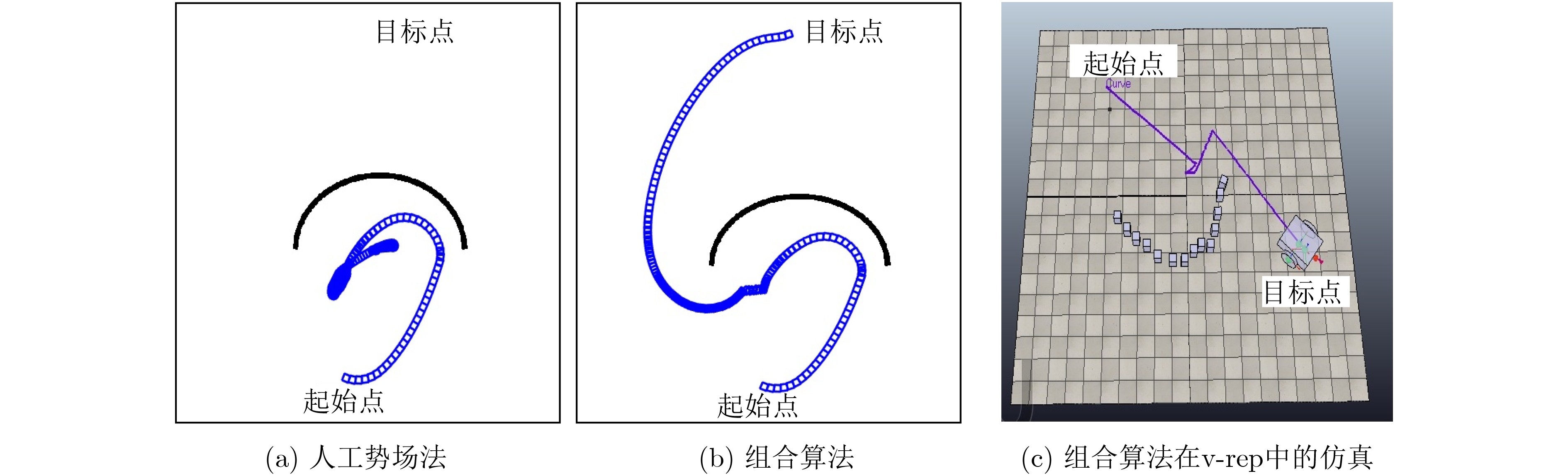
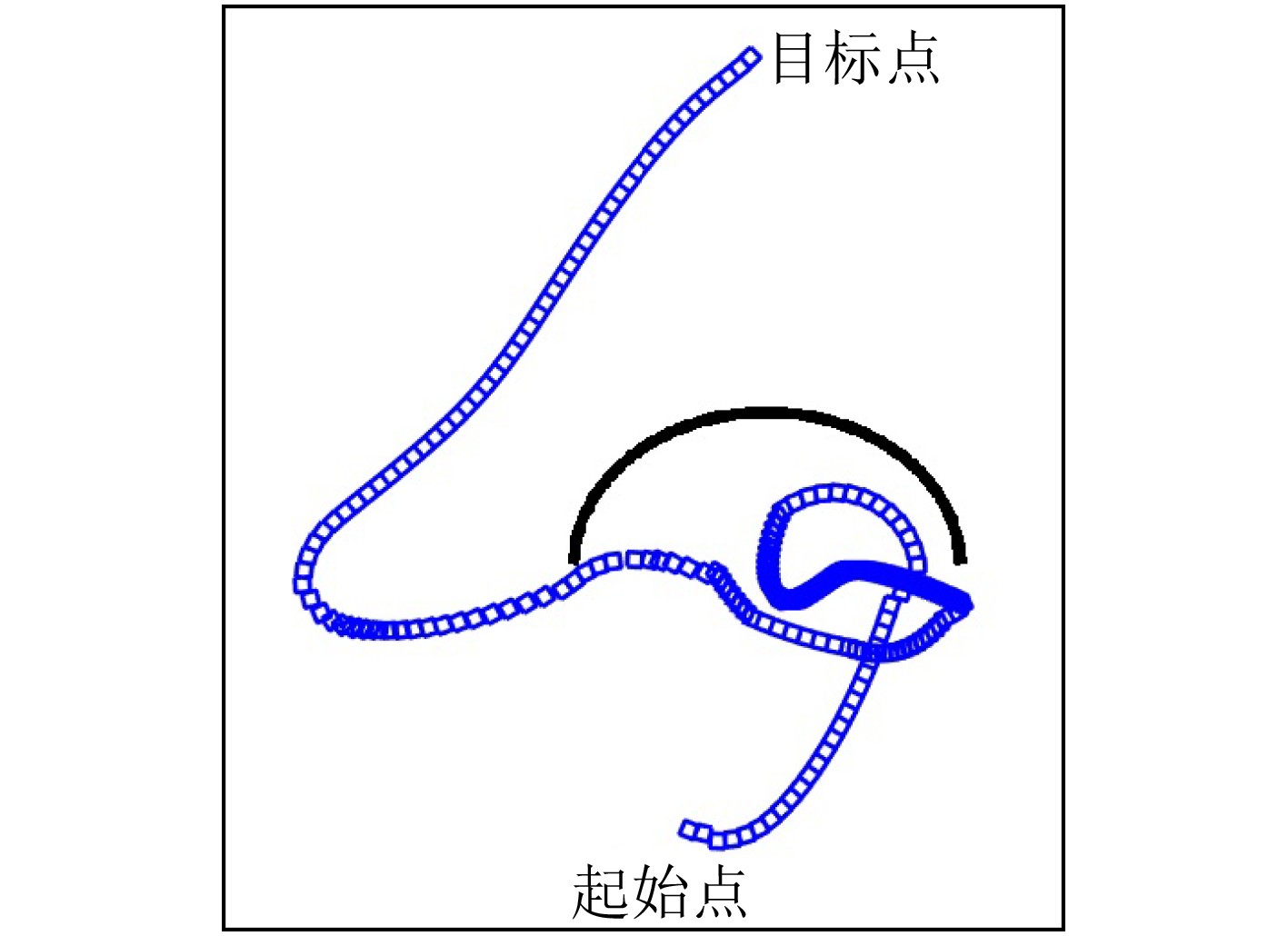
针对移动机器人导航过程中无法规避大型凹型障碍物问题,该文提出一种多状态的组合导航算法。算法按照不同的运动环境,将移动机器人的运行状态分类为运行态、切换态、避障态,同时定义了基于移动机器人运行速度和运行时间的状态双切换条件。当移动机器人处于运行态时,采用人工势场法(APFM)进行导航,并实时观测毗邻障碍物的几何构型。在遭遇障碍物时,切换态用于判断是否满足状态切换条件,以进入避障态执行避障算法。避障完成后,状态自动切换回运行态继续执行导航任务。多状态的提出,可有效解决传统人工势场法在大型凹形障碍物的避障过程中存在局部震荡的问题。基于运行速度和运行时间的双切换条件判定算法,可实现多状态间的平滑切换。实验结果表明,该算法在解决局部震荡问题的同时,还可降低避障时间,提升导航算法效率。
Abstract:For the problem that mobile robot can not avoid large concave obstacles during navigation, this paper proposes a multi-state integrated navigation algorithm. The algorithm classifies the running state of mobile robot into running state, switching state and obstacle avoidance state according to different moving environment, and defines the state double switching conditions based on the running speed and running time of the mobile robot. The Artificial Potential Field Method (APFM) is used to navigate and observe the geometric configuration of adjacent obstacles in real time. When encountering an obstacle, the switching state is used to determine whether the state switching condition is satisfied, and the obstacle avoidance algorithm is executed to enter the obstacle avoidance state and enter the obstacle avoidance state to implement the obstacle avoidance algorithm. After the obstacle avoidance is completed, the state automatically switches back to the running state to continue the navigation task. The proposal of multi-state can solve the problem of local oscillation of traditional artificial potential field method in the process of avoiding large concave obstacles. Furthermore, the double-switching condition determination algorithm based on running speed and running time can realize smooth switching between states and optimize the path. The experimental results show that the algorithm can not only solve the local oscillation problem, but also reduce the obstacle avoidance time and improve the efficiency of the navigation algorithm.
-
表 1 人工势场法符号含义
符号 符号含义 符号 符号含义 ${\rm{obs}}$ 障碍物 ${\bf{X}}{\rm{d}}$ 目标位置 ${U_{{\rm{Xd}}}}(x)$ 引力势能 ${U_{{\rm{obs}}}}(x)$ 斥力势能 ${U_{{\rm{art}}}}(x)$ 总势能 ${{F}}$ 合力 ${{{F}}_{{\rm{Xd}}}}$ 吸引力 ${{F}}_{\rm{obs}}$ 排斥力 $j$ 移动机器人感知到的
周边障碍物的个数 下载: 导出CSV
下载: 导出CSV
表 2 A*算法符号含义
符号 符号含义 符号 符号含义 $g(\cdot )$ 从初始节点到当前移动机器人
所在节点node的启发式评估代价$h(\cdot )$ 从当前移动机器人所在节点node到
目标节点的启发式评估代价$(x_{\rm{start}},y_{\rm{start}})$ 初始节点坐标 $(x_{\rm{goal}},y_{\rm{goal}})$ 目标节点坐标 $(x,y)$ 移动机器人实时位置坐标
下载: 导出CSV
表 3 模型描述符号含义
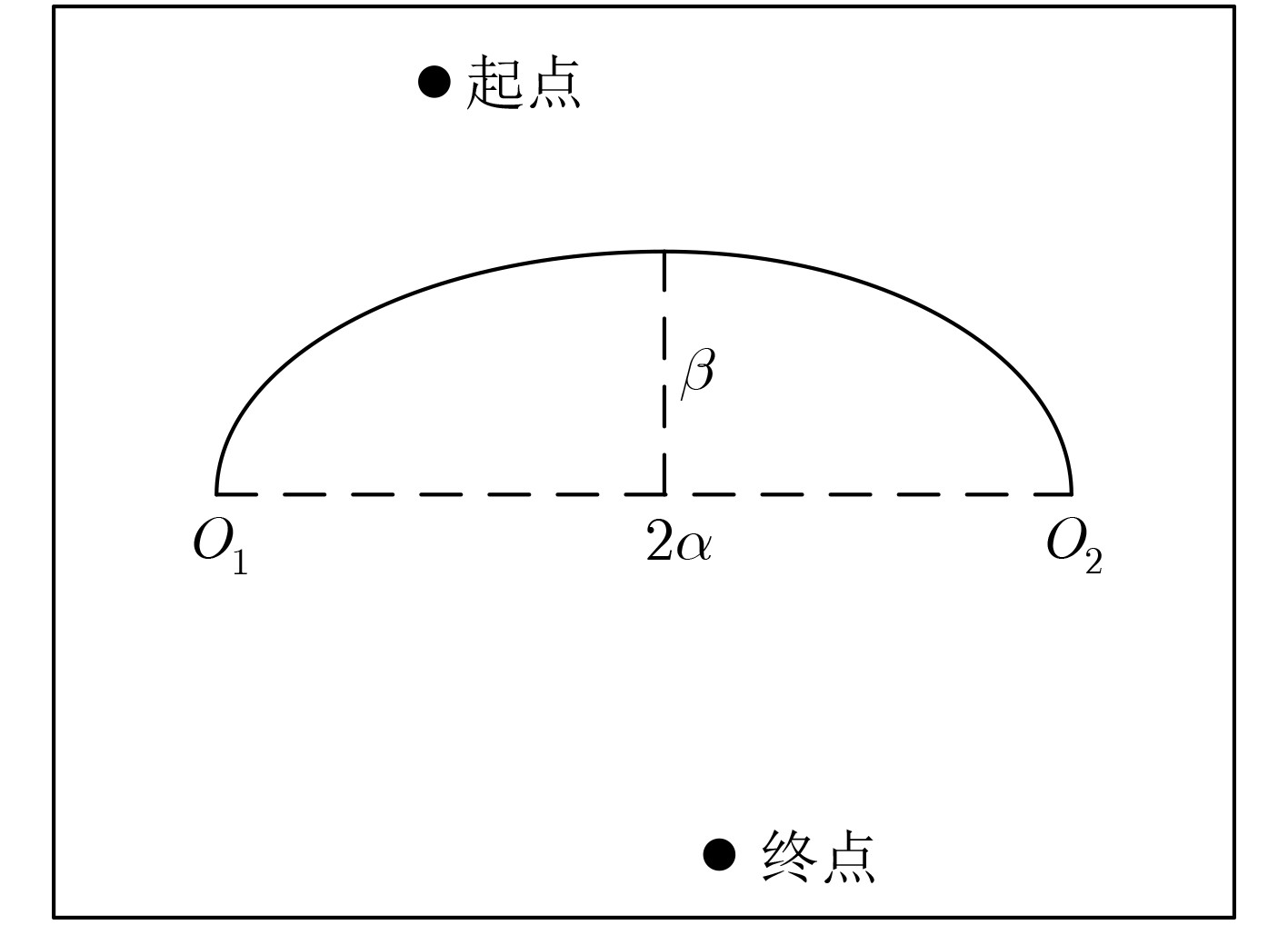
符号 符号含义 符号 符号含义 $O_1$ 障碍物的左端点 $O_2$ 障碍物的右端点 $2\alpha $ 障碍物的长 $\beta $ 障碍物的宽 $v_t$ 移动机器人的实时线速度 $a$ 移动机器人在运行态时的最大速度 $\Delta d$ 移动机器人在某段时间内的移动距离 $S_{\rm{obs}}$ 所有障碍物总面积 $S_{\rm{map}}$ 地图面积 $\rho $ 障碍物密度
下载: 导出CSV
-
王勇臻, 陈燕, 于莹莹. 求解多旅行商问题的改进分组遗传算法[J]. 电子与信息学报, 2017, 39(1): 198–205. doi: 10.11999/JEIT160211WANG Yongzhen, CHEN Yan, and YU Yingying. Improved grouping genetic algorithm for solving multiple traveling salesman problem[J]. Journal of Electronics &Information Technology, 2017, 39(1): 198–205. doi: 10.11999/JEIT160211 黄长强, 赵克新. 基于改进蚁狮算法的无人机三维航迹规划[J]. 电子与信息学报, 2018, 40(7): 1532–1538. doi: 10.11999/JEIT170961HUANG Changqiang and ZHAO Kexin. Three dimensional path planning of UAV with improved ant lion optimizer[J]. Journal of Electronics &Information Technology, 2018, 40(7): 1532–1538. doi: 10.11999/JEIT170961 KHATIB O. Real-time obstacle avoidance for manipulators and mobile robots[J]. The International Journal of Robotics Research, 1986, 5(1): 90–98. doi: 10.1177/027836498600500106 PARK M G, JEON J H, and LEE M C. Obstacle avoidance for mobile robots using artificial potential field approach with simulated annealing[C]. 2001 IEEE International Symposium on Industrial Electronics, Pusan, South Korea, 2001: 1530–1535. doi: 10.1109/ISIE.2001.931933. 况菲, 王耀南. 基于混合人工势场-遗传算法的移动机器人路径规划仿真研究[J]. 系统仿真学报, 2006, 18(3): 774–777. doi: 10.16182/j.cnki.joss.2006.03.061KUANG Fei and WANG Yaonan. Robot path planning based on hybrid artificial potential field/genetic algorithm[J]. Journal of System Simulation, 2006, 18(3): 774–777. doi: 10.16182/j.cnki.joss.2006.03.061 LEE D, JEONG J, KIM Y H, et al. An improved artificial potential field method with a new point of attractive force for a mobile robot[C]. The 2nd International Conference on Robotics and Automation Engineering, Shanghai, China, 2017: 63–67. doi: 10.1109/ICRAE.2017.8291354. ROSTAMI S M H, SANGAIAH A K, WANG Jin, et al. Obstacle avoidance of mobile robots using modified artificial potential field algorithm[J]. EURASIP Journal on Wireless Communications and Networking, 2019(1): No. 70, 1–19. doi: 10.1186/s13638-019-1396-2 HART P E, NILSSON N J, and RAPHAEL B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100–107. doi: 10.1109/TSSC.1968.300136 DECHTER R and PEARL J. Generalized best-first search strategies and the optimality of A*[J]. Journal of the ACM, 1985, 32(3): 505–536. doi: 10.1145/3828.3830 田景文, 孔垂超, 高美娟. 一种车辆路径规划的改进混合算法[J]. 计算机工程与应用, 2014, 50(14): 58–63. doi: 10.3778/j.issn.1002-8331.1208-0319TIAN Jingwen, KONG Chuichao, and GAO Meijuan. Improved hybrid algorithm of vehicle path planning[J]. Computer Engineering and Applications, 2014, 50(14): 58–63. doi: 10.3778/j.issn.1002-8331.1208-0319 胡中华, 潘洲, 王凯凯. 基于混合算法的动态路径规划[J]. 煤矿机械, 2015, 36(12): 243–245. doi: 10.13436/j.mkjx.201512103HU Zhonghua, PAN Zhou, and WANG Kaikai. Dynamic path planning based on hybrid algorithm[J]. Coal Mine Machinery, 2015, 36(12): 243–245. doi: 10.13436/j.mkjx.201512103 唐志荣, 冀杰, 吴明阳, 等. 基于改进人工势场法的车辆路径规划与跟踪[J]. 西南大学学报: 自然科学版, 2018, 40(6): 174–182. doi: 10.13718/j.cnki.xdzk.2018.06.025TANG Zhirong, JI Jie, WU Mingyang, et al. Vehicles path planning and tracking based on an improved artificial potential field method[J]. Journal of Southwest University:Natural Science Edition, 2018, 40(6): 174–182. doi: 10.13718/j.cnki.xdzk.2018.06.025 赵奇, 赵阿群. 一种基于A*算法的多径寻由算法[J]. 电子与信息学报, 2013, 35(4): 952–957. doi: 10.3724/SP.J.1146.2012.00983ZHAO Qi and ZHAO Aqun. A multi-path routing algorithm base on A* algorithm[J]. Journal of Electronics &Information Technology, 2013, 35(4): 952–957. doi: 10.3724/SP.J.1146.2012.00983 DIJKSTRA E W. A note on two problems in connexion with graphs[J]. Numerische Mathematik, 1959, 1(1): 269–271. doi: 10.1007/BF01386390 沈文君. 基于改进人工势场法的机器人路径规划算法研究[D]. [硕士论文], 暨南大学, 2009.SHEN Wenjun. Algorithm research of path planning for robot based on improved artifical potential field[D]. [Master dissertation], Jinan University, 2009. -

 下载:
下载:


计量
- 文章访问数: 2985
- HTML全文浏览量: 1647
- PDF下载量: 89
- 被引次数: 0
