

Design of Convolutional Neural Networks Hardware Acceleration Based on FPGA
-
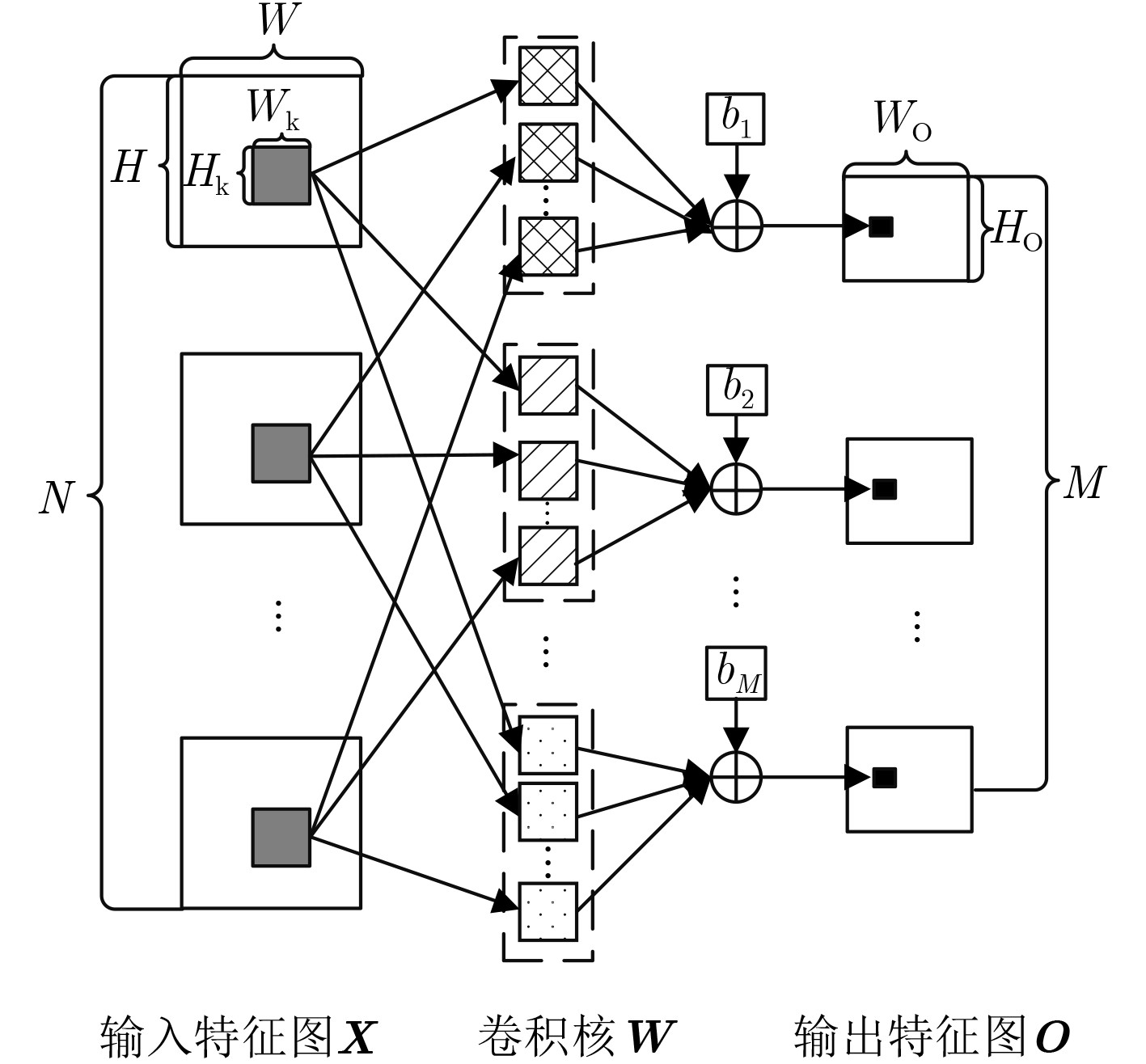
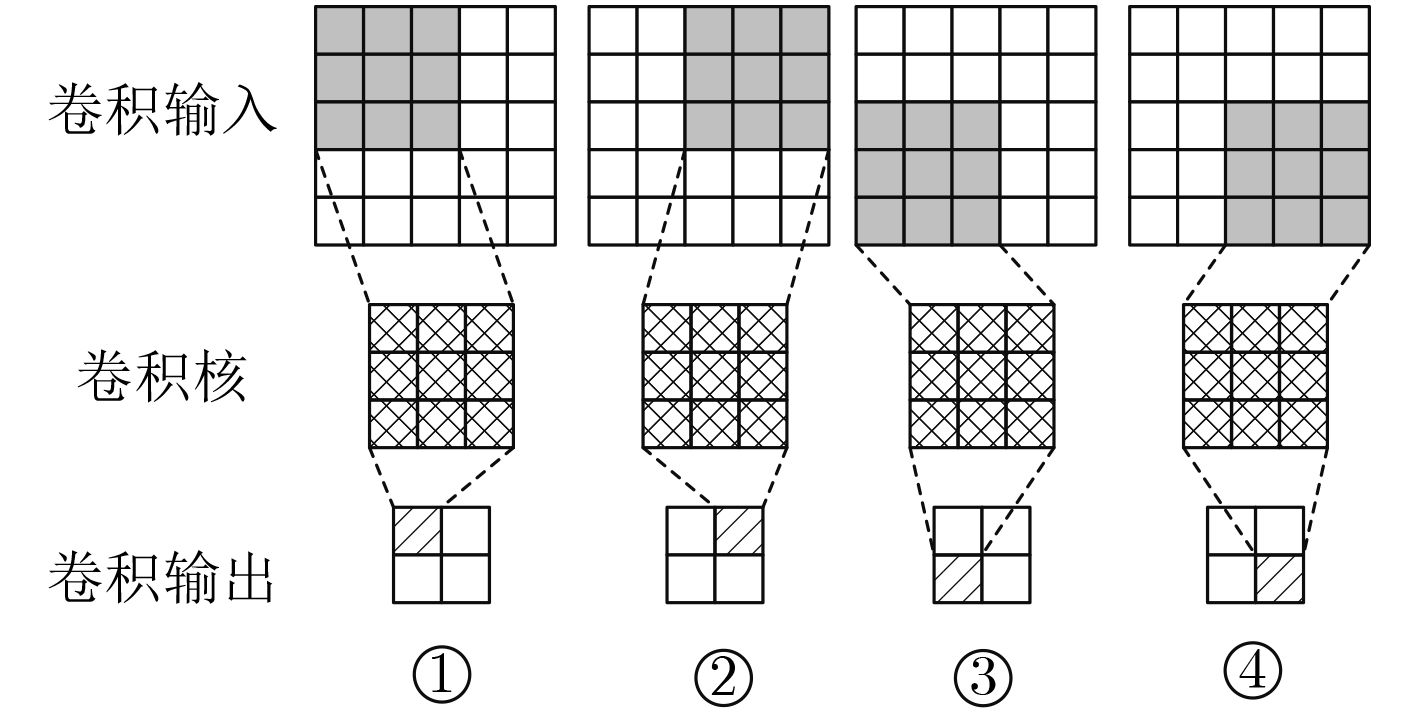
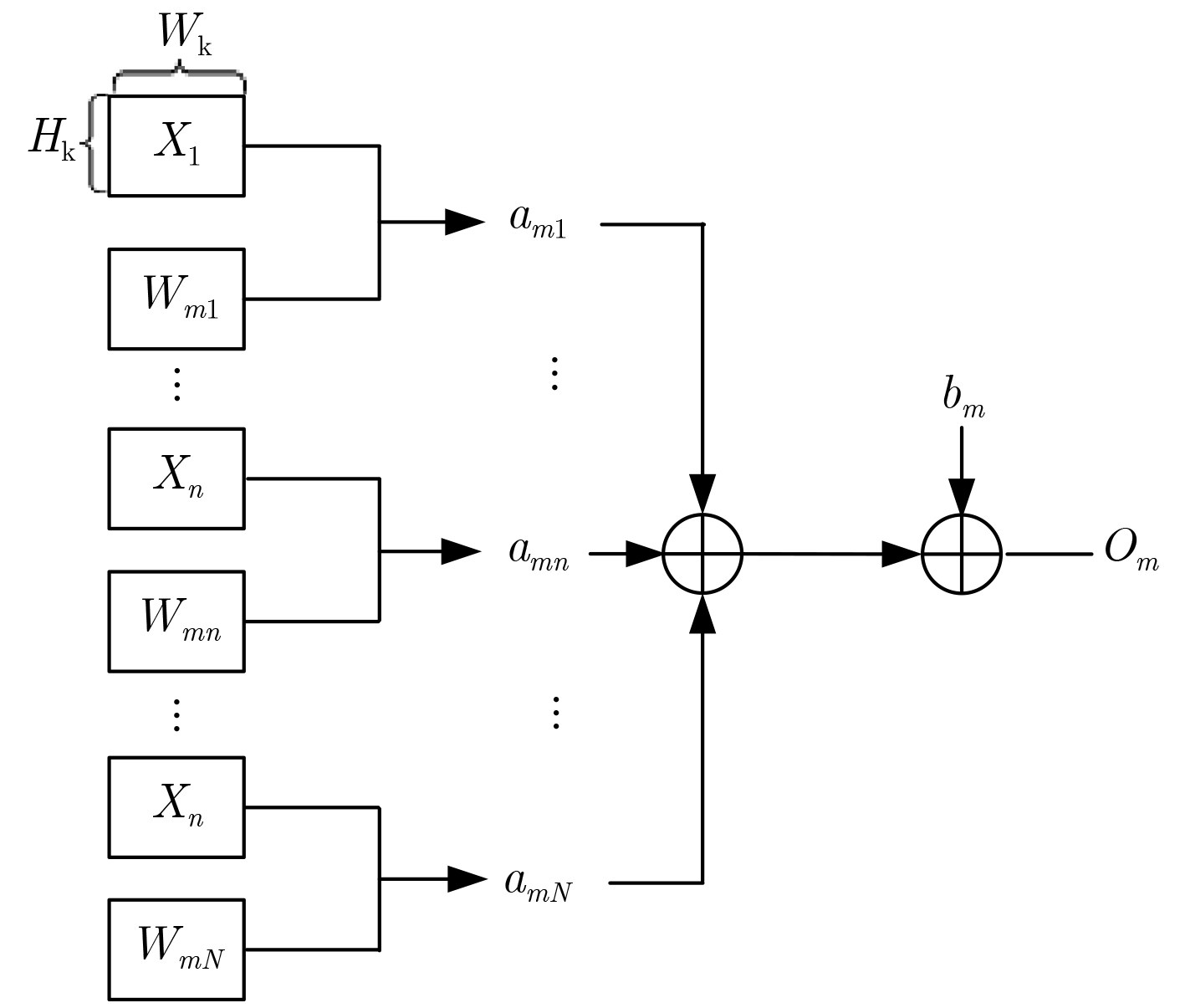
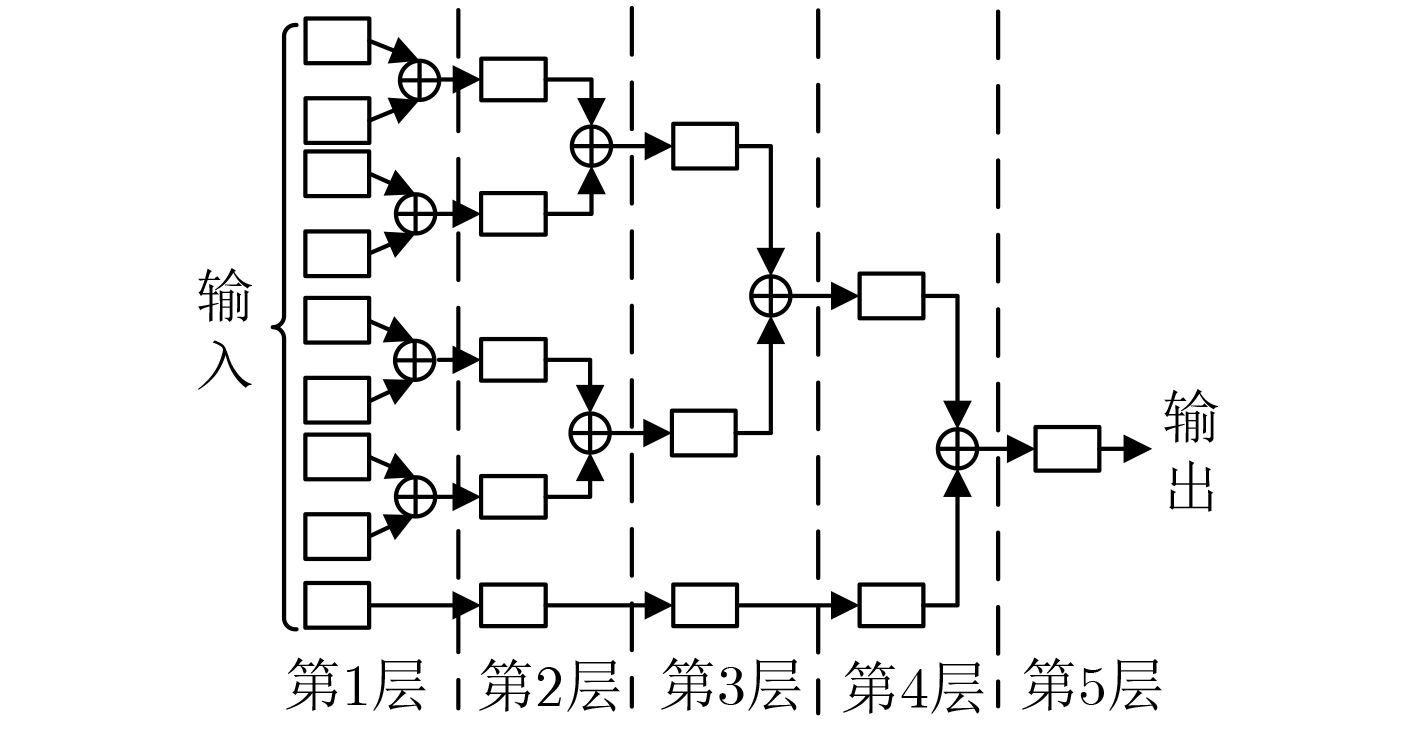
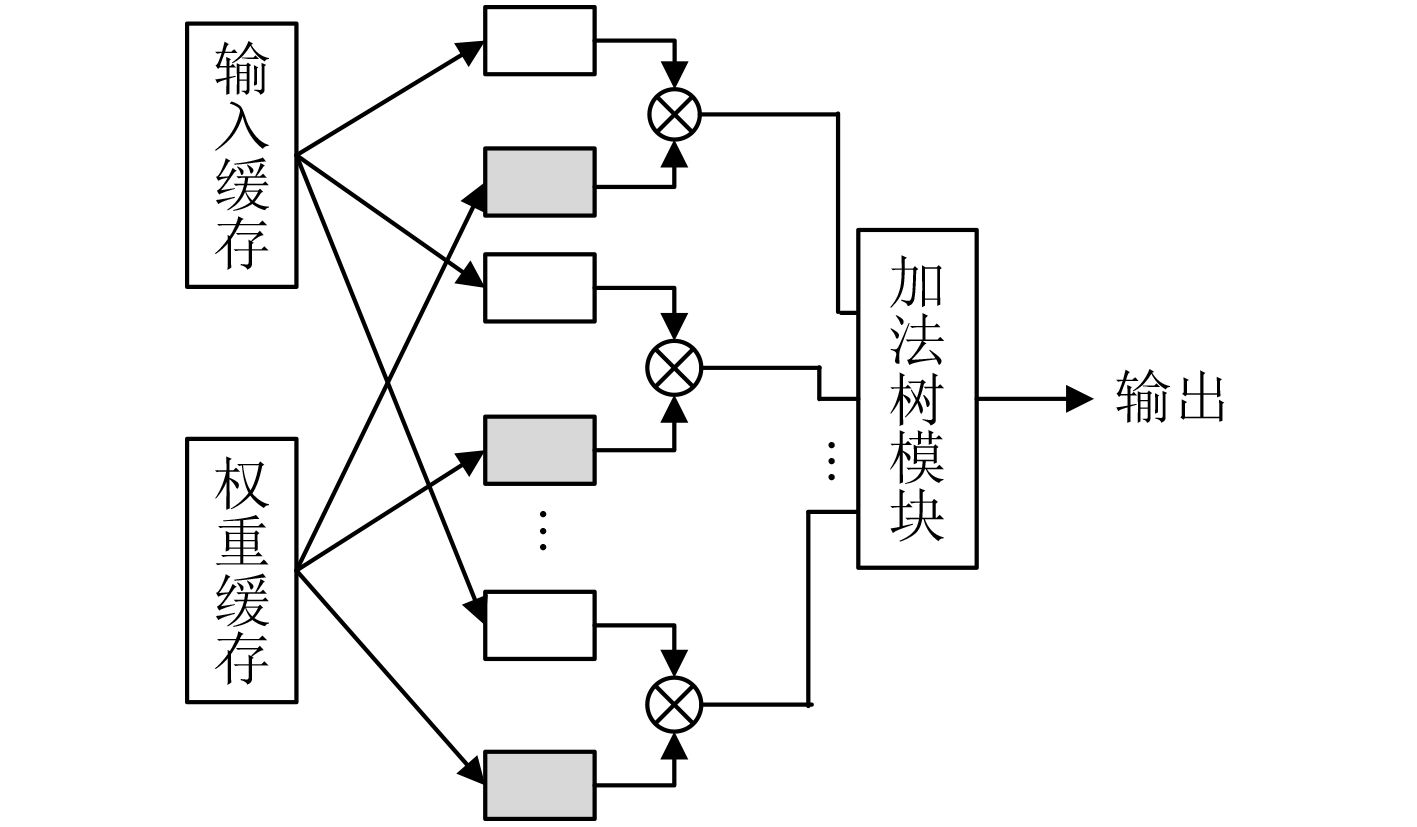
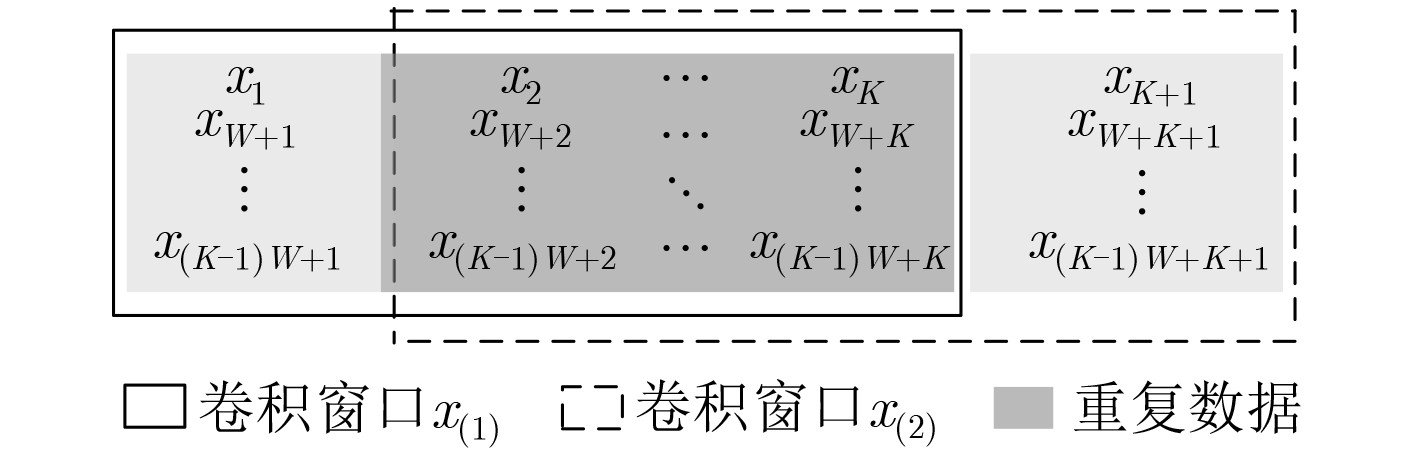
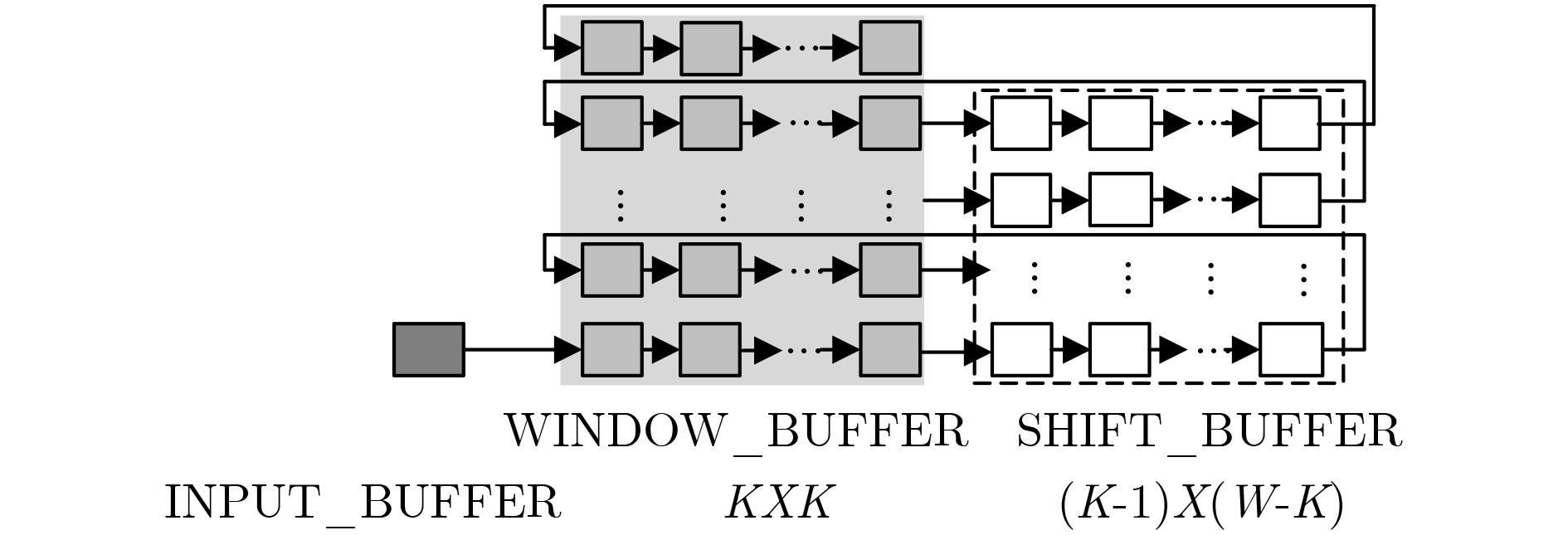
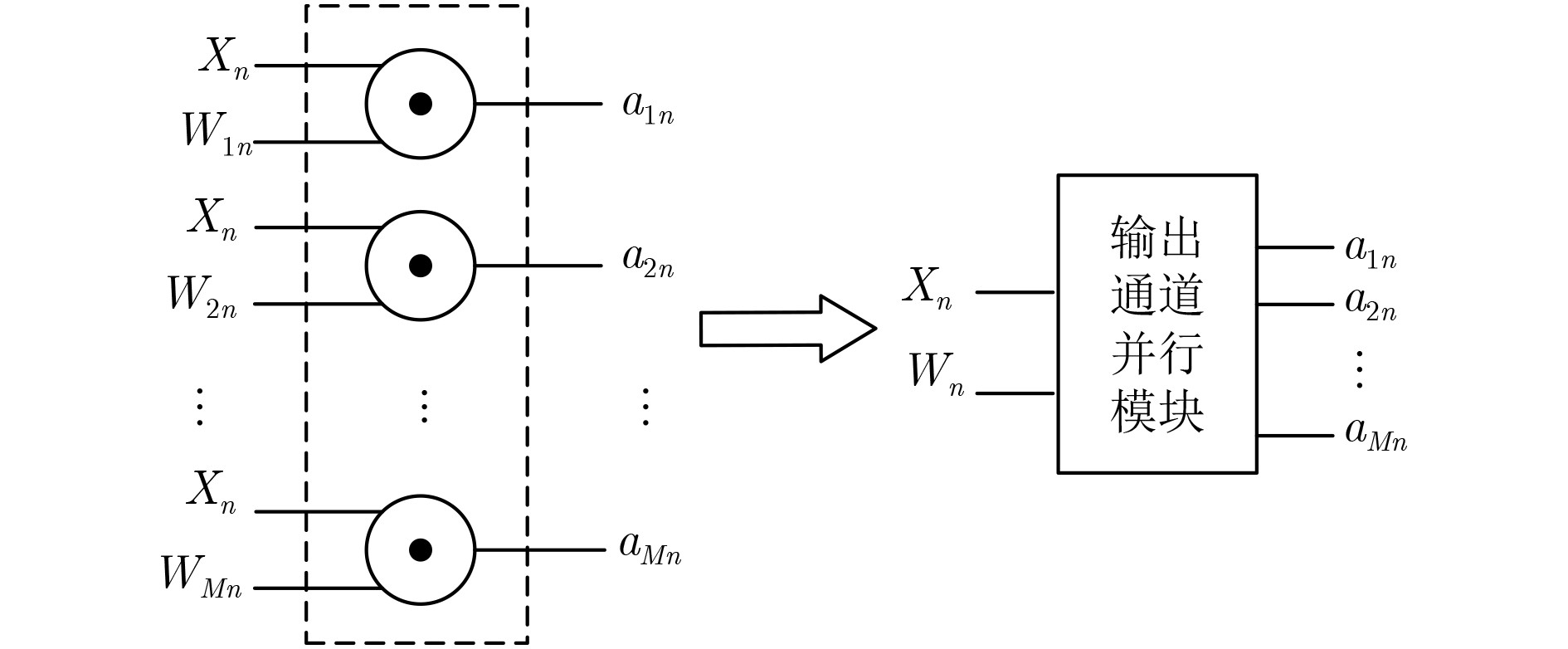
摘要: 针对卷积神经网络(CNN)计算量大、计算时间长的问题,该文提出一种基于现场可编程逻辑门阵列(FPGA)的卷积神经网络硬件加速器。首先通过深入分析卷积层的前向运算原理和探索卷积层运算的并行性,设计了一种输入通道并行、输出通道并行以及卷积窗口深度流水的硬件架构。然后在上述架构中设计了全并行乘法-加法树模块来加速卷积运算和高效的窗口缓存模块来实现卷积窗口的流水线操作。最后实验结果表明,该文提出的加速器能效比达到32.73 GOPS/W,比现有的解决方案高了34%,同时性能达到了317.86 GOPS。
-
关键词:
- 卷积神经网络 /
- 硬件加速 /
- 现场可编程逻辑门阵列 /
- 计算并行 /
- 深度流水
Abstract: Considering the large computational complexity and the long-time calculation of Convolutional Neural Networks (CNN), an Field-Programmable Gate Array(FPGA)-based CNN hardware accelerator is proposed. Firstly, by deeply analyzing the forward computing principle and exploring the parallelism of convolutional layer, a hardware architecture in which parallel for the input channel and output channel, deep pipeline for the convolution window is presented. Then, a full parallel multi-addition tree is designed to accelerate convolution and efficient window buffer to implement deep pipelining operation of convolution window. The experimental results show that the energy efficiency ratio of proposed accelerator reaches 32.73 GOPS/W, which is 34% higher than the existing solutions, as the performance reaches 317.86 GOPS. -
表 1 卷积神经网络结构参数
层名称 层结构 参数量(个) 卷积层1 卷积核大小3×3,卷积核个数15,步长1 150 激活层1 无 0 池化层1 池化大小2×2,步长2 0 卷积层2 卷积核大小6×6,卷积核个数20,步长1 10820 激活层2 无 0 池化层2 池化大小2×2,步长2 0 全连接层 输出神经元个数10 3210  下载: 导出CSV
下载: 导出CSV
-
LIU Weibo, WANG Zidong, LIU Xiaohui, et al. A survey of deep neural network architectures and their applications[J]. Neurocomputing, 2017, 234: 11–26. doi: 10.1016/j.neucom.2016.12.038 HAN Song, MAO Huizi, and DALLY W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv: 1510.00149, 2015. COATES A, HUVAL B, WANG Tao, et al. Deep learning with COTS HPC systems[C]. Proceedings of the 30th International Conference on International Conference on Machine Learning, Atlanta, USA, 2013: III-1337–III-1345. JOUPPI N P, YOUNG C, PATIL N, et al. In-datacenter performance analysis of a tensor processing unit[C]. Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, Canada, 2017: 1–12. doi: 10.1145/3079856.3080246. MOTAMEDI M, GYSEL P, AKELLA V, et al. Design space exploration of FPGA-based deep convolutional neural networks[C]. Proceedings of the 21st Asia and South Pacific Design Automation Conference, Macau, China, 2016: 575–580. doi: 10.1109/ASPDAC.2016.7428073. ZHANG Jialiang and LI Jing. Improving the performance of OpenCL-based FPGA accelerator for convolutional neural network[C]. Proceedings of 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2017: 25–34. doi: 10.1145/3020078.3021698. QIU Jiantao, WANG Jie, YAO Song, et al. Going deeper with embedded FPGA platform for convolutional neural network[C]. Proceedings of 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2016: 26–35. doi: 10.1145/2847263.2847265. 余奇. 基于FPGA的深度学习加速器设计与实现[D]. [硕士论文], 中国科学技术大学, 2016: 30–38.YU Qi. Deep learning accelerator design and implementation based on FPGA[D]. [Master dissertation], University of Science and Technology of China, 2016: 30–38. LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791 ABADI M, BARHAM P, CHEN Jianmin, et al. Tensorflow: A system for large-scale machine learning[C]. Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, USA, 2016: 265–283. XIAO Qingcheng, LIANG Yun, LU Liqiang, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs[C]. Proceedings of the 54th Annual Design Automation Conference, Austin, USA, 2017: 62. doi: 10.1145/3061639.3062244. SHEN Junzhong, HUANG You, WANG Zelong, et al. Towards a uniform template-based architecture for accelerating 2D and 3D CNNs on FPGA[C]. Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2018: 97–106. doi: 10.1145/3174243.3174257. -

 下载:
下载:






图(14) / 表(3)
计量
- 文章访问数: 5539
- HTML全文浏览量: 2554
- PDF下载量: 373
- 被引次数: 0
