

Design of Convolutional Neural Networks Accelerator Based on Fast Filter Algorithm
-
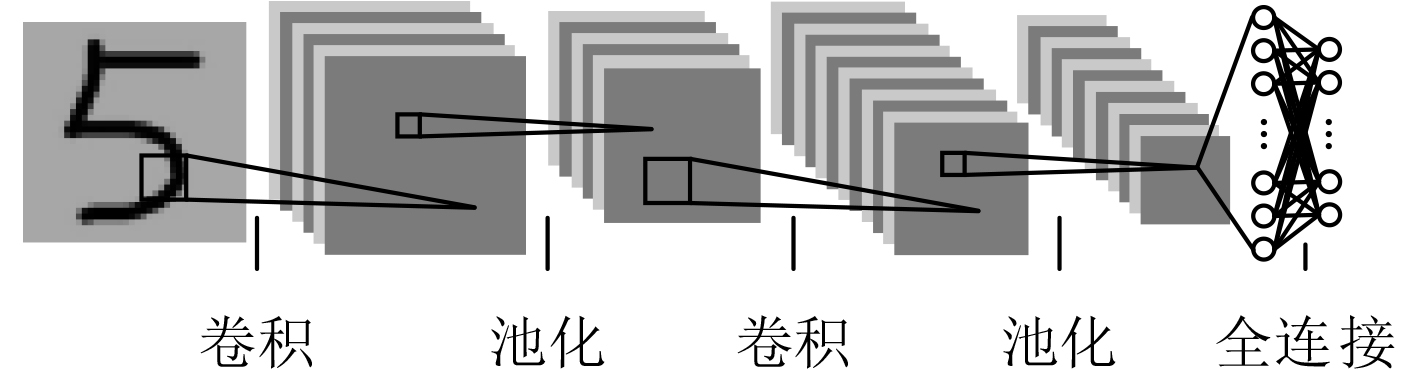
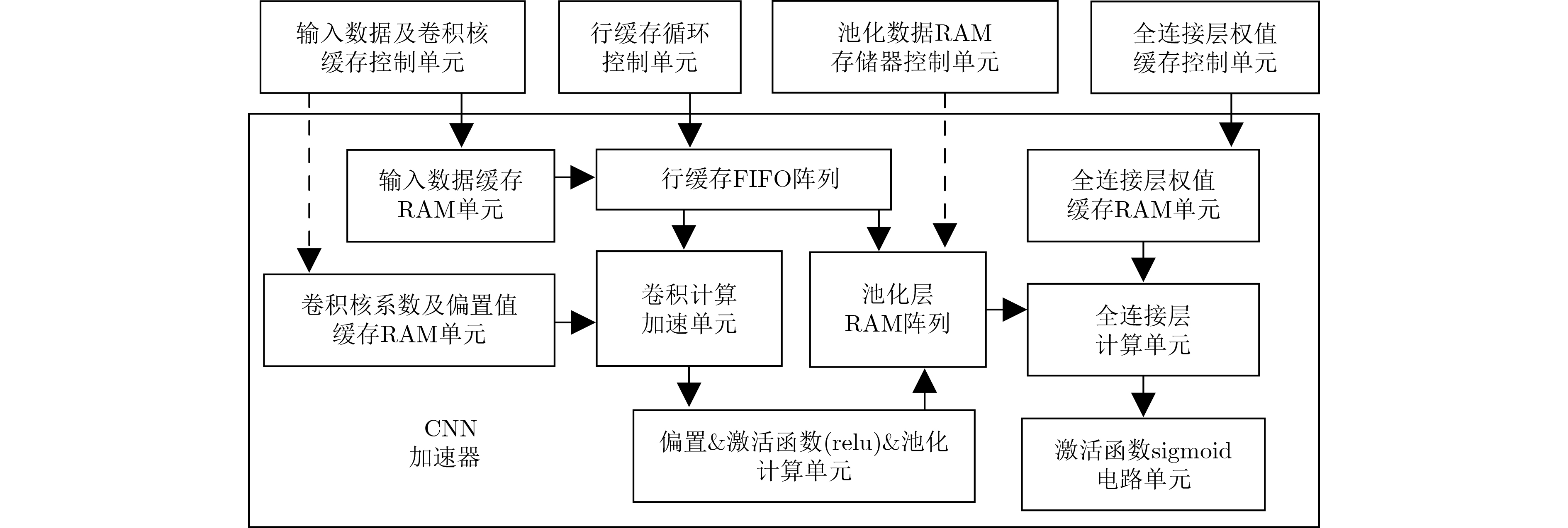
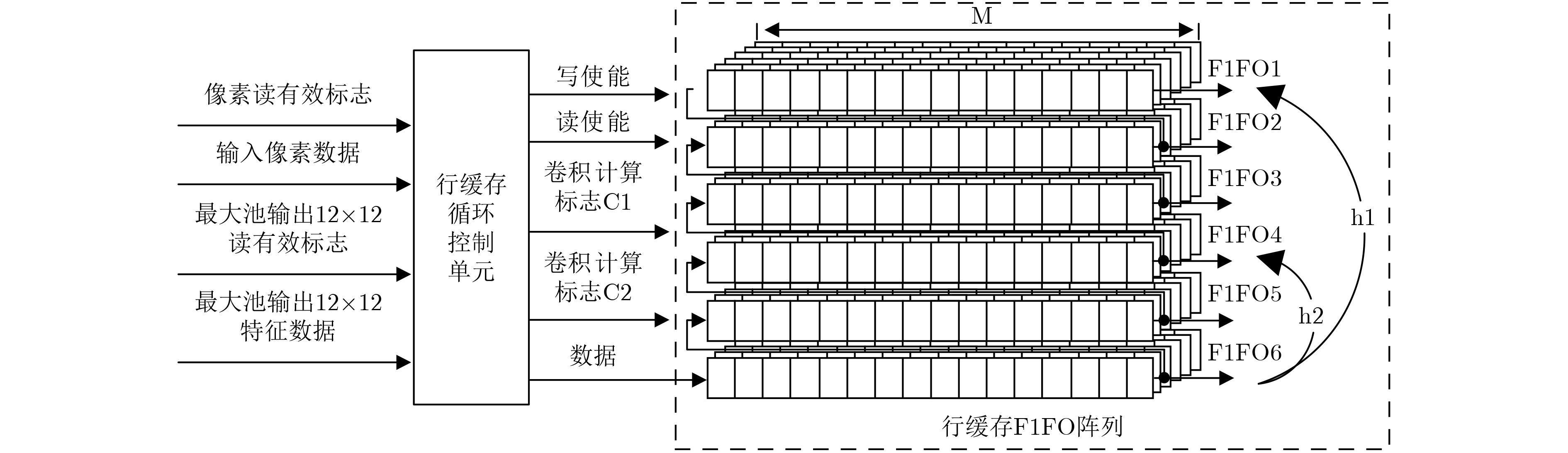
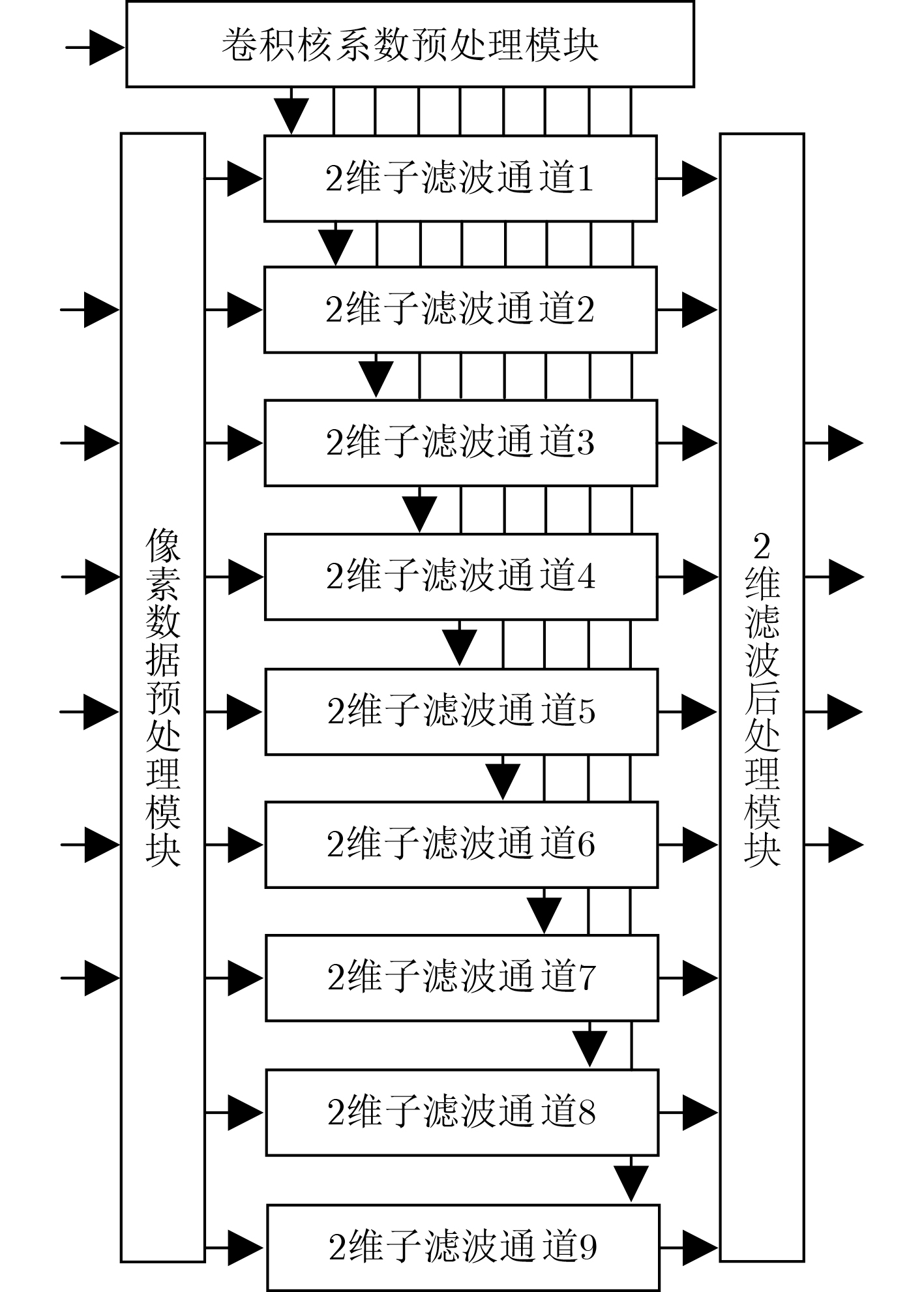
摘要: 为减少卷积神经网络(CNN)的计算量,该文将2维快速滤波算法引入到卷积神经网络,并提出一种在FPGA上实现CNN逐层加速的硬件架构。首先,采用循环变换方法设计行缓存循环控制单元,用于有效地管理不同卷积窗口以及不同层之间的输入特征图数据,并通过标志信号启动卷积计算加速单元来实现逐层加速;其次,设计了基于4并行快速滤波算法的卷积计算加速单元,该单元采用若干小滤波器组成的复杂度较低的并行滤波结构来实现。利用手写数字集MNIST对所设计的CNN加速器电路进行测试,结果表明:在xilinx kintex7平台上,输入时钟为100 MHz时,电路的计算性能达到了20.49 GOPS,识别率为98.68%。可见通过减少CNN的计算量,能够提高电路的计算性能。Abstract: In order to reduce the computational complexity of Convolutional Neural Network(CNN), the two-dimensional fast filtering algorithm is introduced into the CNN, and a hardware architecture for implementing CNN layer-by-layer acceleration on FPGA is proposed. Firstly, the line buffer loop control unit is designed by using the cyclic transformation method to manage effectively different convolution windows and the input feature map data between different layers, and starts the convolution calculation acceleration unit by the flag signal to realize layer-by-layer acceleration. Secondly, a convolution calculation accelerating unit based on 4 parallel fast filtering algorithm is designed. The unit is realized by a less complex parallel filtering structure composed of several small filters. Using the handwritten digit set MNIST to test the designed CNN accelerator circuit, the results show that on the xilinx kintex7 platform, when the input clock is 100 MHz, the computational performance of the circuit reaches 20.49 GOPS, and the recognition rate is 98.68%. It can be seen that the computational performance of the circuit can be improved by reducing the amount of calculation of the CNN.
-
Key words:
- Convolution Neural Network(CNN) /
- Fast filter algorithms /
- FPGA /
- Parallel structure
-
表 1 MATLAB实现与FPGA实现的比较
类型 时间(ms/frams) 精度(bad/10000 frames) 数据类型 .m文件 0.7854 1.19% 双精度 .v 文件 0.01986 1.32% 16 bit定点数  下载: 导出CSV
下载: 导出CSV
-
ZHANG Chen, LI Peng, SUN Guangyu, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks[C]. 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2015: 161–170. KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[C]. The 25th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 1097–1105. DONG Han, LI Tao, LENG Jiabing, et al. GCN: GPU-based cube CNN framework for hyperspectral image classification[C]. The 201746th International Conference on Parallel Processing, Bristol, UK, 2017: 41–49. GHAFFARI S and SHARIFIAN S. FPGA-based convolutional neural network accelerator design using high level synthesize[C]. The 20162nd International Conference of Signal Processing and Intelligent Systems, Tehran, Iran, 2016: 1–6. CHEN Y H, KRISHNA T, EMER J S, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1): 127–138. doi: 10.1109/JSSC.2016.2616357 FENG Gan, HU Zuyi, CHEN Song, et al. Energy-efficient and high-throughput FPGA-based accelerator for Convolutional Neural Networks[C]. The 201613th IEEE International Conference on Solid-State and Integrated Circuit Technology, Hangzhou, China, 2016: 624–626. ZHOU Yongmei and JIANG Jingfei. An FPGA-based accelerator implementation for deep convolutional neural networks[C]. The 20154th International Conference on Computer Science and Network Technology, Harbin, China, 2015: 829–832. HOSEINI F, SHAHBAHRAMI A, and BAYAT P. An efficient implementation of deep convolutional neural networks for MRI segmentation[J]. Journal of Digital Imaging, 2018, 31(5): 738–747. doi: 10.1007/s10278-018-0062-2 HUANG Jiahao, WANG Tiejun, ZHU Xuhui, et al. A parallel optimization of the fast algorithm of convolution neural network on CPU[C]. The 201810th International Conference on Measuring Technology and Mechatronics Automation, Changsha, China, 2018: 5–9. LAVIN A and GRAY S. Fast algorithms for convolutional neural networks[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, 4013–4021. VINCHURKAR P P, RATHKANTHIWAR S V, and KAKDE S M. HDL implementation of DFT architectures using winograd fast Fourier transform algorithm[C]. The 2015 5th International Conference on Communication Systems and Network Technologies, Gwalior, India, 2015: 397–401. WANG Xuan, WANG Chao, and ZHOU Xuehai. Work-in-progress: WinoNN: Optimising FPGA-based neural network accelerators using fast winograd algorithm[C]. 2018 International Conference on Hardware/Software Codesign and System Synthesis, Turin, Italy, 2018: 1–2. NAITO Y, MIYAZAKI T, and KURODA I. A fast full-search motion estimation method for programmable processors with a multiply-accumulator[C]. 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, USA, 1996: 3221–3224. JIANG Jingfei, HU Rongdong, and LUJÁN M. A flexible memory controller supporting deep belief networks with fixed-point arithmetic[C]. The 2013 IEEE 27th International Symposium on Parallel and Distributed Processing Workshops and PhD Forum, Cambridge, USA, 2013: 144–152. LI Sicheng, WEN Wei, WANG Yu, et al. An FPGA design framework for CNN sparsification and acceleration[C]. The 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines, Napa, USA, 2017: 28. -


 下载:
下载:



图(6) / 表(2)
计量
- 文章访问数: 3695
- HTML全文浏览量: 1788
- PDF下载量: 144
- 被引次数: 0
