

An Incremental Feature Extraction Method without Estimating Image Covariance Matrix
-
摘要: 针对2维主成分分析(2DPCA)算法无法实现在线特征提取及无法体现完整数据结构信息等问题,该文提出一种基于图像协方差无关的增量式2DPCA(I2DPCA)算法。该算法无需对图像协方差矩阵进行特征值分解奇异值分解,复杂度将大为降低,提高了特征提取速度。针对I2DPCA仅提取了横向特征的问题,又提出一种增量式行列顺序2DPCA(IRC2DPCA)算法,该算法对I2DPCA的特征矩阵再次进行纵向特征提取,保留了图像的横向与纵向结构信息,实现了行列两个方向上的特征提取与数据降维。最后,以自建的物块数据集、通用的ORL和Yale人脸数据集分别进行对比实验,结果表明,该文算法在收敛率、分类率及复杂度等性能方面均得到了显著提高,其收敛率达到99%以上,分类率可达97.6%,平均处理速度为29 帧/s,能够满足增量特征提取的实时处理需求。Abstract: To solve the problems that Two-Dimensional Principal Component Analysis (2DPCA) can not implement the on-line feature extraction and can not represent the complete structure information, an Incremental 2DPCA (I2DPCA) without estimating covariance matrices is presented by an iterative estimation method, not to deal with the image covariance matrices by the eigenvalue decomposition or the singular value decomposition. The complexity will be greatly reduced and the on-line feature extraction speed can be improved. The proposed I2DPCA can only extract the horizontal features, and thus another Incremental Row-Column 2DPCA (IRC2DPCA) is proposed to incrementally extract the longitudinal ones from the feature matrices of the I2DPCA. The IRC2DPCA can preserve the horizontal and longitudinal features and implement the dimensionality reduction in both row and column directions. Finally, a series of experiments are carried out with the self-built block dataset, ORL and Yale face datasets, respectively. The results show that the proposed algorithms have significantly improved the performances of the convergence rate, the classification rate and the complexity. The convergence rate is over 99%, the classification rate can reach 97.6% and the average processing speed is about 29 frames per second, and it can meet the on-line feature extraction requirements for incremental learning.
-
表 1 不同数据集下特征向量收敛率的均值及标准差
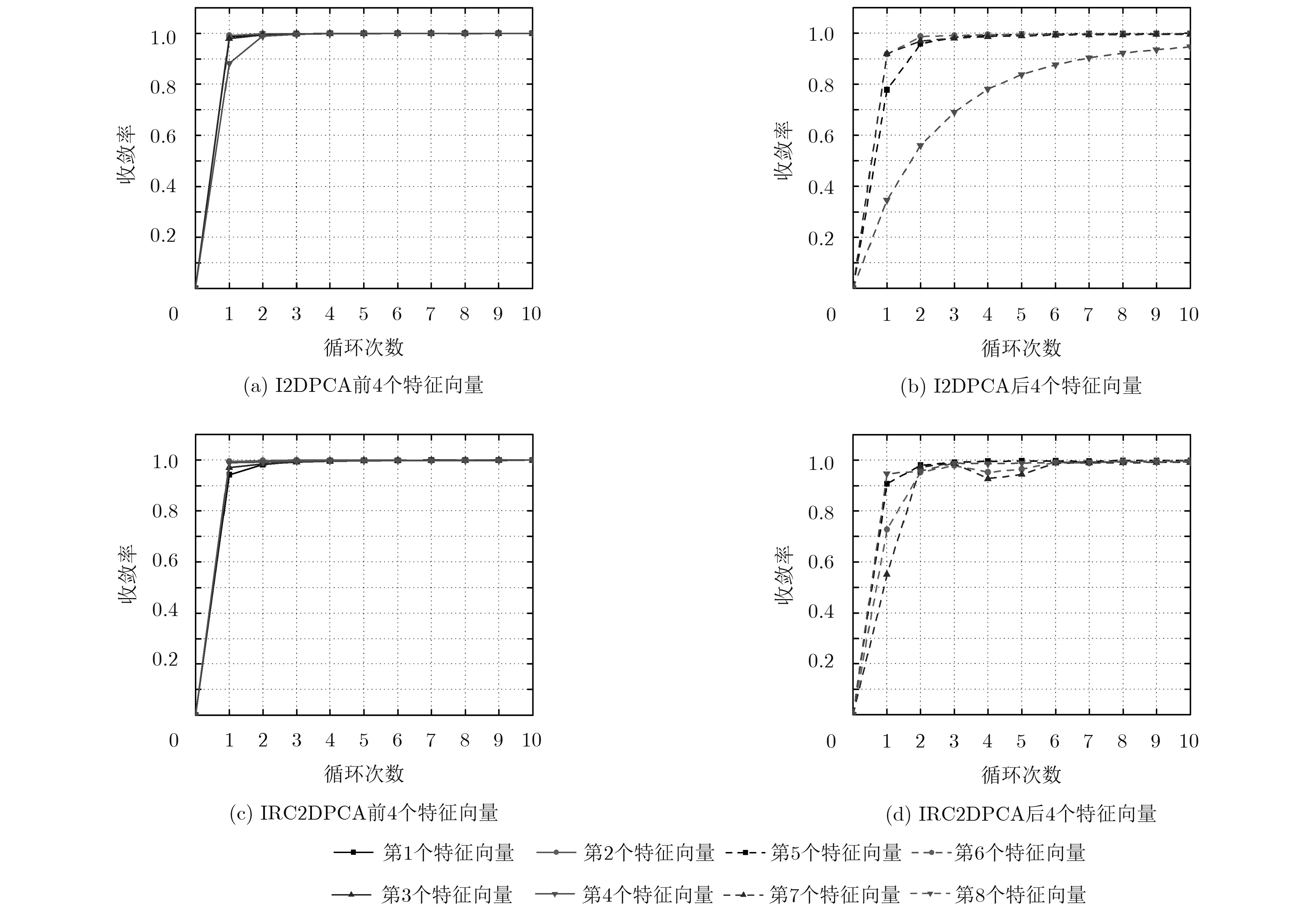
数据集 输入次数 I2DPCA(均值/标准差) IRC2DPCA(均值/标准差) 前4个特征向量 后4个特征向量 前4个特征向量 后4个特征向量 物块 $m = 2$ 0.99442/0.00361 0.86836/0.17826 0.98964/0.00573 0.96564/0.01135 $m = 5$ 0.99924/0.00041 0.95478/0.15818 0.99824/0.00101 0.97302/0.01020 $m = 10$ 0.99981/0.00010 0.98453/0.02225 0.99950/0.00030 0.99495/0.00322 ORL $m = 2$ 0.99991/0.00004 0.89400/0.06763 0.99753/0.00203 0.98175/0.01027 $m = 5$ 0.99997/0.00002 0.91620/0.05154 0.99951/0.00037 0.99441/0.00231 $m = 10$ 0.99998/0.00001 0.92833/0.05163 0.99986/0.00010 0.99755/0.00074 Yale $m = 2$ 0.93732/0.07244 0.96069/0.03026 0.99602/0.00441 0.98308/0.00659 $m = 5$ 0.96001/0.04678 0.98261/0.01609 0.99924/0.00074 0.99528/0.00140 $m = 10$ 0.97283/0.03180 0.99041/0.00970 0.99975/0.00024 0.99793/0.00088  下载: 导出CSV
下载: 导出CSV
表 2 物块数据集的最佳分类率
每类训练
样本数2DPCA
(120×4)[8]RC2DPCA
(8×8)[11]Angle-2DPCA
(120×4)[12]BA2DPCA
(8×8)[13]BDPCA
(8×8)[10]IBDPCA
(8×8)[17]I2DPCA
(120×4)IRC2DPCA
(8×8)L=10 0.933 0.927 0.922 0.931 0.930 0.930 0.926 0.922 L=25 0.957 0.960 0.958 0.961 0.959 0.959 0.962 0.968 L=50 0.959 0.961 0.961 0.961 0.961 0.967 0.962 0.972 L=75 0.954 0.957 0.954 0.957 0.958 0.956 0.955 0.958 L=100 0.966 0.963 0.966 0.964 0.963 0.973 0.971 0.976
下载: 导出CSV
表 3 ORL数据集的最佳分类率
每类训练
样本数2DPCA
(112×4)[8]RC2DPCA
(8×8)[11]Angle-2DPCA
(112×4)[12]BA2DPCA
(8×8)[13]BDPCA
(8×8)[10]IBDPCA
(8×8)[17]I2DPCA
(112×4)IRC2DPCA
(8×8)L=1 0.744 0.728 0.742 0.725 0.728 0.708 0.736 0.717 L=2 0.850 0.844 0.850 0.847 0.847 0.844 0.847 0.841 L=3 0.868 0.857 0.868 0.861 0.861 0.846 0.864 0.857 L=4 0.888 0.896 0.888 0.892 0.904 0.904 0.883 0.900 L=5 0.905 0.905 0.905 0.905 0.915 0.915 0.905 0.925
下载: 导出CSV
表 4 Yale数据集的最佳分类率
每类训练
样本数2DPCA
(100×4)[8]RC2DPCA
(8×8)[11]Angle-2DPCA
(100×4)[12]BA2DPCA
(8×8)[13]BDPCA
(8×8)[10]IBDPCA
(8×8)[17]I2DPCA
(100×4)IRC2DPCA
(8×8)L=1 0.560 0.560 0.560 0.560 0.560 0.553 0.573 0.560 L=2 0.719 0.733 0.719 0.733 0.741 0.741 0.726 0.726 L=3 0.800 0.808 0.792 0.800 0.817 0.825 0.792 0.825 L=4 0.857 0.876 0.857 0.876 0.876 0.876 0.857 0.867 L=5 0.856 0.889 0.856 0.889 0.889 0.889 0.856 0.889
下载: 导出CSV
表 5 物块数据集处理的所需时间对比(s)
算法 L=10 L=25 L=50 L=75 L=100 特征提取 分类识别 特征提取 分类识别 特征提取 分类识别 特征提取 分类识别 特征提取 分类识别 2DPCA(120×4)[8] 2.152 5.279 9.568 6.561 32.745 7.990 69.065 9.015 123.779 10.319 RC2DPCA(8×8)[11] 2.029 0.941 9.208 1.140 32.630 1.362 66.446 1.335 115.344 1.554 Angle-2DPCA(120×4)[12] 4.991 1.097 15.604 1.174 93.28 1.296 67.788 1.471 57.624 1.545 BA2DPCA(8×8)[13] 13.117 1.179 14.261 1.190 46.107 1.203 65.105 1.250 48.089 1.233 BDPCA(8×8)[10] 2.356 0.933 9.456 0.966 32.988 1.248 67.501 1.414 127.39 1.556 IBDPCA(8×8)[17] 11.826 0.868 29.074 1.055 56.778 1.221 86.120 1.408 114.845 1.604 I2DPCA(120×4) 3.103 5.361 7.381 6.225 14.693 7.778 21.938 8.963 29.039 11.181 IRC2DPCA(8×8) 7.159 0.846 17.047 1.043 34.413 1.266 51.577 1.443 65.510 1.669
下载: 导出CSV
表 6 物块数据集处理的所需内存对比(kB)
算法 L=10 L=25 L=50 L=75 L=100 特征提取 分类识别 特征提取 分类识别 特征提取 分类识别 特征提取 分类识别 特征提取 分类识别 2DPCA(120×4)[8] 16.658 70.889 37.588 69.935 72.753 68.149 107.941 66.383 143.179 64.622 RC2DPCA(8×8)[11] 16.736 11.354 38.199 11.423 73.977 11.227 109.867 10.805 145.764 10.612 Angle-2DPCA(120×4)[12] 16.096 48.774 16.096 48.118 16.080 46.768 16.080 45.596 16.080 44.440 BA2DPCA(8×8)[13] 16.080 21.642 16.088 21.142 16.104 20.57 16.12 20.504 16.096 20.036 BDPCA(8×8)[10] 16.379 11.345 37.040 11.427 71.663 11.243 106.438 10.768 141.160 10.620 IBDPCA(8×8)[17] 8.830 11.382 8.499 11.403 8.482 11.218 8.478 10.780 8.486 10.612 I2DPCA(120×4) 8.847 70.897 8.503 69.935 8.486 68.141 8.486 66.301 8.503 64.602 IRC2DPCA(8×8) 8.511 11.350 8.507 11.419 8.486 11.243 8.536 10.797 8.511 10.604
下载: 导出CSV
-
WANG Hongjuan, HU Jiani, and DENG Weihong. Face feature extraction: a complete review[J]. IEEE Access, 2018, 6: 6001–6039. doi: 10.1109/ACCESS.2017.2784842 CHAUDHARY G, SRIVASTAVA S, and BHARDWAJ S. Feature extraction methods for speaker recognition: A review[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2017, 31(12): 1–39. doi: 10.1142/S0218001417500410 SOORA N R and DESHPANDE P S. Review of feature extraction techniques for character recognition[J]. IETE Journal of Research, 2018, 64(2): 280–295. doi: 10.1080/03772063.2017.1351323 NEIVA D H and ZANCHETTIN C. Gesture recognition: A review focusing on sign language in a mobile context[J]. Expert Systems with Applications, 2018, 103: 159–183. doi: 10.1016/j.eswa.2018.01.051 陈小龙, 关键, 于晓涵, 等. 基于短时稀疏时频分布的雷达目标微动特征提取及检测方法[J]. 电子与信息学报, 2017, 39(5): 1017–1023. doi: 10.11999/JEIT161040CHEN Xiaolong, GUAN Jian, YU Xiaohan, et al. Radar micro-Doppler signature extraction and detection via short-time sparse time-frequency distribution[J]. Journal of Electronics &Information Technology, 2017, 39(5): 1017–1023. doi: 10.11999/JEIT161040 ISLAM S, ANAND S, HAMID J, et al. Comparing the performance of linear and nonlinear principal components in the context of high-dimensional genomic data integration[J]. Statistical Applications in Genetics and Molecular Biology, 2017, 16(3): 199–216. doi: 10.1515/sagmb-2016-0066 BRO R and SMILDE A K. Principal component analysis[J]. Analytical Methods, 2014, 6(9): 2812–2831. doi: 10.1039/c3ay41907j YANG Jian, ZHANG David, FRANGI A F, et al. Two-dimensional PCA: a new approach to appearance-based face representation and recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1): 131–137. doi: 10.1109/TPAMI.2004.1261097 ZHANG Daoqiang and ZHOU Zhihua. (2D)2PCA: Two-directional two-dimensional PCA for efficient face representation and recognition[J]. Neurocomputing, 2005, 69(1-3): 224–231. doi: 10.1016/j.neucom.2005.06.004 ZUO Wangmeng, ZHANG David, and WANG Kuanquan. Bidirectional PCA with assembled matrix distance metric for image recognition[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) , 2006, 36(4): 863–872. doi: 10.1109/TSMCB.2006.872274 YANG Wankou, SUN Changyin, and RICANEK K. Sequential Row–Column 2DPCA for face recognition[J]. Neural Computing and Applications, 2012, 21(7): 1729–1735. doi: 10.1007/s00521-011-0676-5 GAO Quanxue, MA Lan, LIU Yang, et al. Angle 2DPCA: A new formulation for 2DPCA[J]. IEEE Transactions on Cybernetics, 2018, 48(5): 1672–1678. doi: 10.1109/TCYB.2017.2712740. ZHOU Shuisheng and ZHANG Danqing. Bilateral angle 2DPCA for face recognition[J]. IEEE Signal Processing Letters, 2019, 26(2): 317–321. doi: 10.1109/LSP.2018.2889925 DIAZ-CHITO K, FERRI F J, and HERNÁNDEZ-SABATÉ A. An overview of incremental feature extraction methods based on linear subspaces[J]. Knowledge-Based Systems, 2018, 145: 219–235. doi: 10.1016/j.knosys.2018.01.020 WENG Juyang, ZHANG Yilu, and HWANG Weyshiuan. Candid covariance-free incremental principal component analysis[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2003, 25(8): 1034–1040. doi: 10.1109/TPAMI.2003.1217609 王肖锋, 张明路, 刘军. 基于增量式双向主成分分析的机器人感知学习方法研究[J]. 电子与信息学报, 2018, 40(3): 618–625. doi: 10.11999/JEIT170561WANG Xiaofeng, ZHANG Minglu, and LIU Jun. Robot perceptual learning method based on incremental bidirectional principal component analysis[J]. Journal of Electronics &Information Technology, 2018, 40(3): 618–625. doi: 10.11999/JEIT170561 谢自强, 葛为民, 王肖锋, 等. 发展型机器人实时特征提取方法研究[J]. 机器人, 2017, 39(2): 189–196. doi: 10.13973/j.cnki.robot.2017.0189XIE Ziqiang, GE Weimin, WANG Xiaofeng, et al. Real time feature extraction method of developmental robot[J]. Robot, 2017, 39(2): 189–196. doi: 10.13973/j.cnki.robot.2017.0189 REN Chuanxian and DAI Daoqing. Incremental learning of bidirectional principal components for face recognition[J]. Pattern Recognition, 2010, 43(1): 318–330. doi: 10.1016/j.patcog.2009.05.020 曹向海, 刘宏伟, 吴顺君. 一种有效的增量BDPCA算法[J]. 系统仿真学报, 2008, 20(20): 5530–5533. doi: 10.16182/j.cnki.joss.2008.20.041CAO Xianghai, LIU Hongwei, and WU Shunjun. A kind of efficient incremental BDPCA algorithm[J]. Journal of System Simulation, 2008, 20(20): 5530–5533. doi: 10.16182/j.cnki.joss.2008.20.041 文颖, 施鹏飞. 一种基于共同向量结合2DPCA的人脸识别方法[J]. 自动化学报, 2009, 35(2): 202–205. doi: 10.3724/SP.J.1004.2009.00202WEN Ying and SHI Pengfei. An approach to face recognition based on common vector and 2DPCA[J]. Acta Automatica Sinica, 2009, 35(2): 202–205. doi: 10.3724/SP.J.1004.2009.00202 -


 下载:
下载:




图(4) / 表(6)
计量
- 文章访问数: 3548
- HTML全文浏览量: 1082
- PDF下载量: 70
- 被引次数: 0
