

Research on Faster RCNN Object Detection Based on Hard Example Mining
-
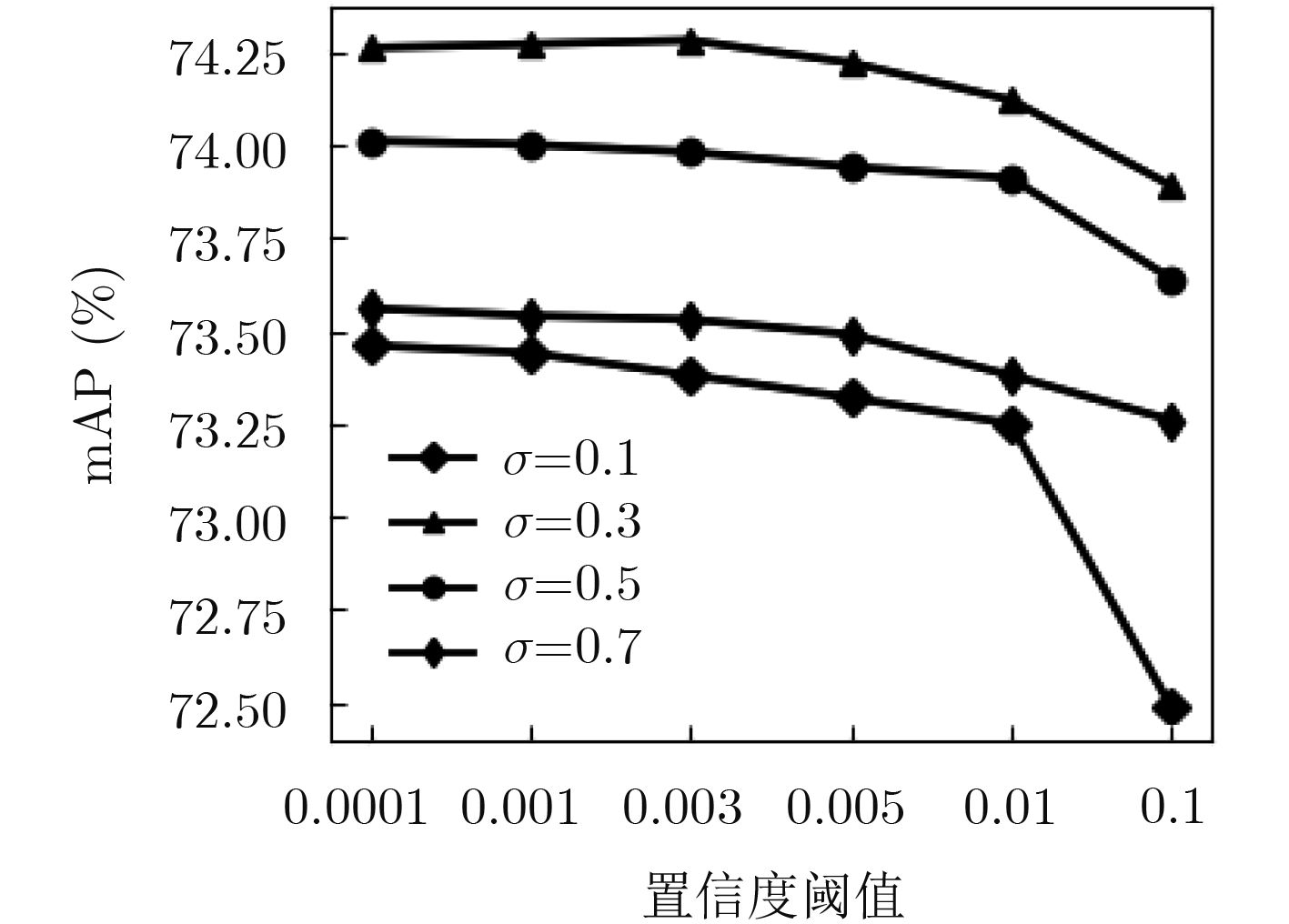
摘要: 针对经典的快速区域卷积神经网络(Faster RCNN)训练过程存在太多难训练样本、召回率低等问题,该文采用一种基于在线难分样本挖掘技术(OHEM)与负难分样本挖掘(HNEM)技术相结合的方法,通过训练中实时筛选的最大损失值难分样本进行误差传递,解决了模型对难分样本检测率低问题,提高模型训练效率;为更好地提高模型的召回率和模型的泛化性,该文改进了非极大值抑制(NMS)算法,设置了置信度阈值罚函数,又引入多尺度、数据增强等训练方法。最后通过比较改进前后的结果,经敏感性实验分析表明,该算法在VOC2007数据集上取得了较好效果,平均精度均值从69.9%提升到了74.40%,在VOC2012上从70.4%提升到79.3%,验证了该算法的优越性。Abstract: Because of the classic Faster RCNN training proccess with too many difficult training samples and low recall rate problem, a method which combines the techniques of Online Hard Example Mining (OHEM) and Hard Negative Example Mining (HNEM) is adopted, which carries out the error transfer for the difficult samples using its corresponding maximum loss value from real-time filtering. It solves the problem of low detection of hard example and improves the efficiency of the model training. To improve the recall rate and generalization of the model, an improved Non-Maximum Suppression (NMS) algorithm is proposed by setting confidence thresholds penalty function; In addition, multi-scale training and data augmentation are also introduced. Finally, the results before and after improvement are compared: Sensibility experiments show that the algorithm achieves good results in VOC2007 data set and VOC2012 data set, with the mean Average Percision (mAP) increasing from 69.9% to 74.40%, and 70.4% to 79.3% respectively, which demonstrates strongly the superiority of the algorithm.
-
表 1 负难分样本挖掘参数设置
参数名称 代表含义 参数取值 FG_THRESH 正样本IoU阈值 [0.7, 1.0] BG_THRESH_LO 负样本IoU阈值 [0, 0.5) HNEM_NMS_THRESH 非极大值抑制阈值 0.7 HNEM_BATCHSIZE 图片目标批次大小 64 RPN_FG_FRACTION 正样本比例 0.25 RPN_BG_FRACTION 负样本比例 0.75  下载: 导出CSV
下载: 导出CSV
表 2 在线样本挖掘参数设置
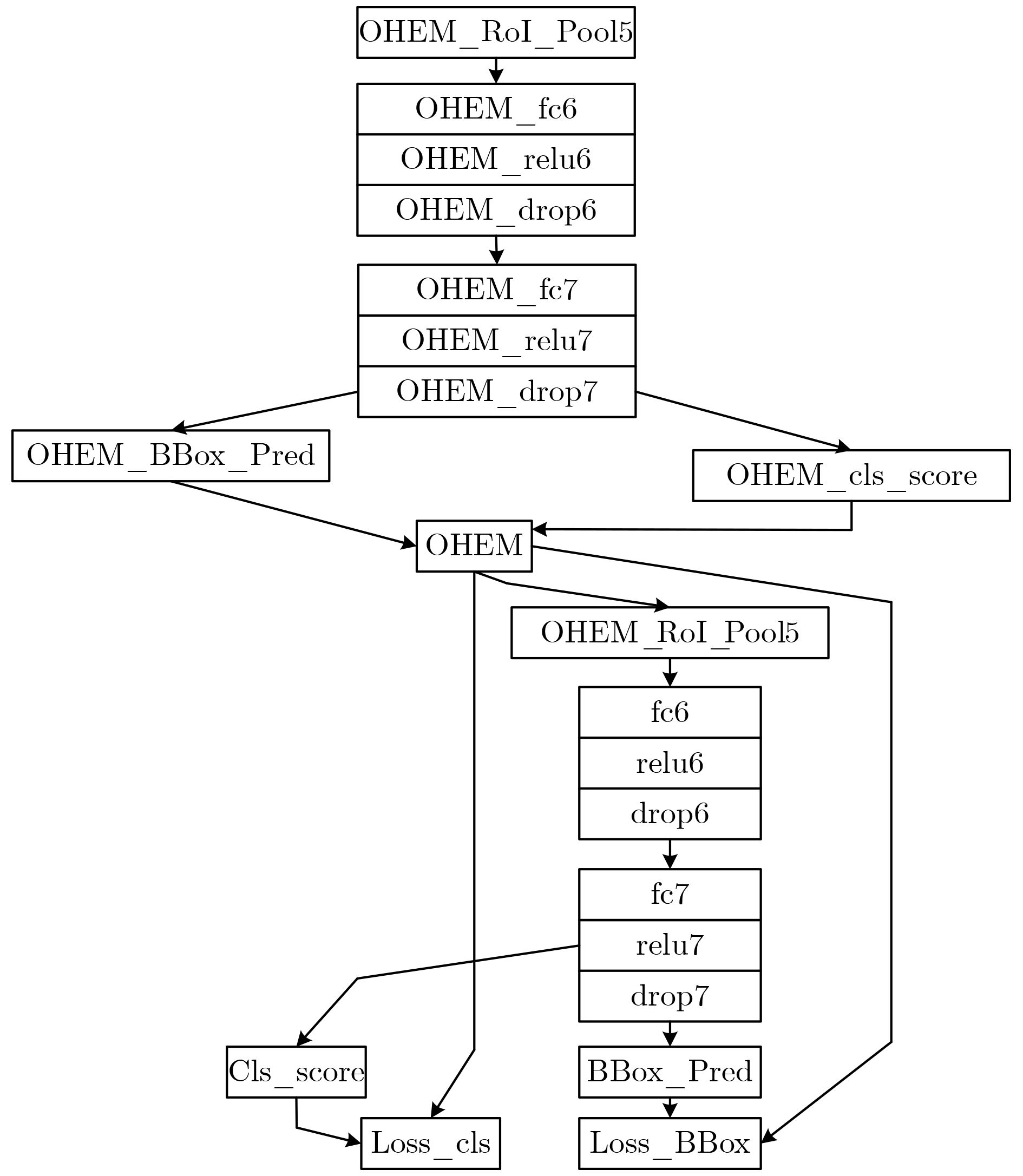
参数名称 代表含义 参数取值 ITERS 每次迭代个数 1 OHEM_ROI_POOL5 在线样本兴趣池化 7×7 OHEM_FC6 在线样本全连接层 4096 OHEM_RELU6 在线样本激活操作 – OHEM_FC7 在线样本全连接层 4096 OHEM_RELU7 在线样本激活操作 – OHEM_CLS_SCORE 在线样本分类数 21 OHEM_CLS_PRED 在线样本边框矩阵 84 OHEM 在线样本处理模块 OHEMData
下载: 导出CSV
表 3 改进的非极大值抑制算法
输入:候选边框集合$B = \left\{ {{{{b}}_1}, {{{b}}_2}, ·\!·\!·, {{{b}}_{{N}}}} \right\}$,置信度集合
$S = \left\{ {{{{s}}_1}, {{{s}}_2}, ·\!·\!·, {{{s}}_{{N}}}} \right\}$, IoU阈值${N_{\rm t}}$循环操作: 最优框$D \leftarrow \left\{ {} \right\}$ While $B \ne {\rm Null}$ do $m \leftarrow \arg {\rm Max}\ \left( S \right)$ $M \leftarrow {b_m}$ $D \leftarrow D \cup M;B \leftarrow B - M$ for ${{{b}}_{{i}}}$ in $B$ do If ${\rm{IoU}}\left( {M, {{{b}}_{{i}}}} \right) \ge {N_{\rm t}}$ then ${\rm weight} = {\rm Method}\left( {1 - 3} \right)$ ${{{s}}_{{i}}} \leftarrow {{{s}}_{{i}}} * {\rm weight}$ If ${{{s}}_{{i}}} \le {\rm threshold}$ $B \leftarrow B - {{{b}}_{{i}}}$ End End End End 输出最终结果:$D$, $S$
下载: 导出CSV
表 4 在线样本挖掘等实验mAP指标结果
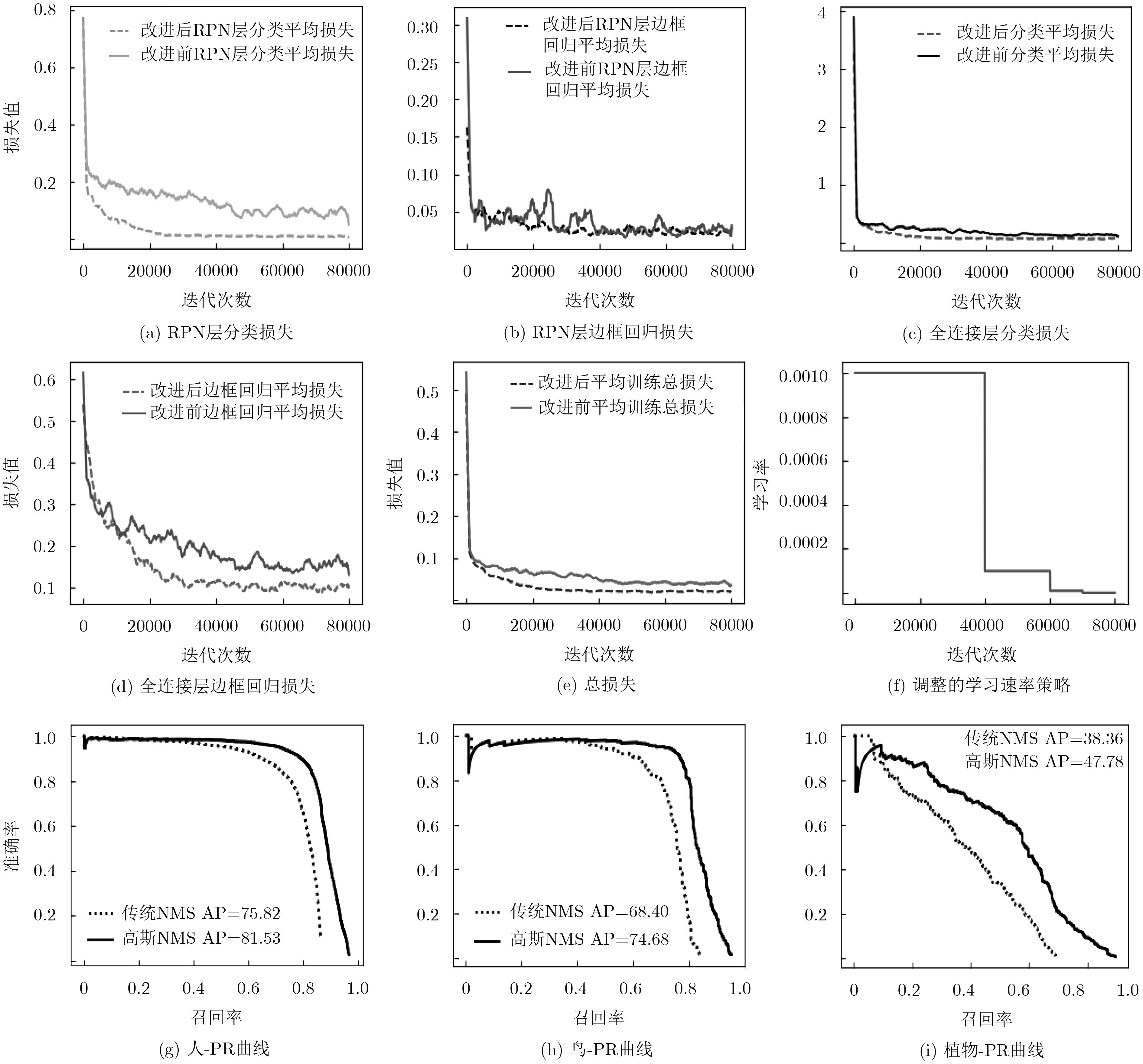
类别 bird boat bottle bus car chair cow table dog horse person plant sheep sofa train mAP FRCNN 68.5 54.7 50.6 78.1 80.2 50.7 74.6 65.5 81.3 83.7 75.7 38.3 70.6 67.1 80.7 69.9 ohem_fc 69.2 57.9 46.5 81.8 79.1 47.9 76.2 68.9 83.2 80.8 72.7 39.9 67.5 66.2 75.6 69.9 ohem1: 1 71.1 54.6 52.3 79.7 81.3 50.3 74.3 66.8 80.7 83.7 76.7 40.9 70.0 68.2 77.6 70.4 ohem1: 10 71.8 58.5 53.2 79.3 82.9 52.2 81.2 70.0 81.4 83.2 77.9 43.7 71.9 67.1 75.0 71.7 ohem1: 3 72.2 57.8 56.6 80.8 84.0 53.8 77.5 68.0 82.2 84.0 77.6 43.2 70.9 68.4 79.4 72.1 数据增强 69.8 62.0 55.2 80.2 83.6 54.5 80.3 67.2 80.7 85.0 78.0 44.6 70.8 69.4 79.0 72.5 NMS-线 74.5 64.4 57.8 80.0 84.3 57.4 80.8 70.1 83.2 83.7 81.3 48.3 71.9 68.4 79.4 74.1 NMS-高 74.7 64.0 58.5 80.5 84.5 56.9 81.5 70.1 83.8 84.2 81.5 47.8 71.5 69.1 79.6 74.3 NMS-指 73.7 63.7 56.9 79.6 83.9 56.5 80.7 69.4 82.8 82.7 80.8 48.0 70.5 66.8 79.2 73.3 Lr-调整 75.8 63.3 57.6 81.1 84.7 56.5 83.1 70.6 84.8 85.2 81.2 47.8 71.6 68.6 79.1 74.4 12+ohem 76.8 64.8 61.4 85.0 84.1 59.9 82.6 61.9 88.5 85.2 86.9 56.7 79.5 67.5 85.4 77.5 12+ohem* 78.1 65.0 55.4 84.9 84.0 62.1 83.6 67.3 91.3 88.9 85.6 54.7 83.8 77.3 88.3 79.3
下载: 导出CSV
-
吕博云. 数字图像处理技术及应用研究[J]. 科技与创新, 2018(2): 146–147. doi: 10.15913/j.cnki.kjycx.2018.02.146LÜ Boyun. Research on the technology and application of digital image processing[J]. Science and Technology &Innovation, 2018(2): 146–147. doi: 10.15913/j.cnki.kjycx.2018.02.146 王湘新, 时洋, 文梅. CNN卷积计算在移动GPU上的加速研究[J]. 计算机工程与科学, 2018, 40(1): 34–39. doi: 10.3969/j.issn.1007-130X.2018.01.005WANG Xiangxin, SHI Yang, and WEN Mei. Accelerating CNN on mobile GPU[J]. Computer Engineering &Science, 2018, 40(1): 34–39. doi: 10.3969/j.issn.1007-130X.2018.01.005 胡炎, 单子力, 高峰. 基于Faster-RCNN和多分辨率SAR的海上舰船目标检测[J]. 无线电工程, 2018, 48(2): 96–100. doi: 10.3969/j.issn.1003-3106.2018.02.04HU Yan, SHAN Zili, and GAO Feng. Ship detection based on faster-RCNN and multiresolution SAR[J]. Radio Engineering, 2018, 48(2): 96–100. doi: 10.3969/j.issn.1003-3106.2018.02.04 GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81. REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 FELZENSZWALB P, MCALLESTER D, and RAMANAN D. A discriminatively trained, multiscale, deformable part model[C]. Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, USA, 2008: 1–8. doi: 10.1109/CVPR.2008.4587597. YAN Junjie, LEI Zhen, WEN Longyin, et al. The fastest deformable part model for object detection[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2497–2504. FORSYTH D. Object detection with discriminatively trained part-based models[J]. Computer, 2014, 47(2): 6–7. doi: 10.1109/MC.2014.42 DALAL N and TRIGGS B. Histograms of oriented gradients for human detection[C]. Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, USA, 2005: 886–893. doi: 10.1109/CVPR.2005.177. WANG Xiaoyu, HAN T X, and YAN Shuicheng. An HOG-LBP human detector with partial occlusion handling[C]. Proceedings of 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 2009: 32–39. doi: 10.1109/ICCV.2009.5459207. ERHAN D, SZEGEDY C, TOSHEV A, et al. Scalable object detection using deep neural networks[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2155–2162. doi: 10.1109/CVPR.2014.276. NEUBECK A and VAN GOOL L. Efficient non-maximum suppression[C]. Proceedings of the 18th International Conference on Pattern Recognition, Hongkong, China, 2006: 850–855. doi: 10.1109/ICPR.2006.479. 李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012: 18–23.LI Hang. Statistical Learning Method[M]. Beijing: Tsinghua University Press, 2012: 18–23. 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 23–35.ZHOU Zhihua. Machine Learning[M]. Beijing: Tsinghua University Press, 2016: 23–35. SUN Changming and VALLOTTON P. Fast linear feature detection using multiple directional non-maximum suppression[J]. Journal of Microscopy, 2009, 234(2): 147–157. doi: 10.1111/jmi.2009.234.issue-2 -




图(4) / 表(4)
计量
- 文章访问数: 3319
- HTML全文浏览量: 2032
- PDF下载量: 90
- 被引次数: 0
 下载:
下载:
