

A Maximal Frequent Itemsets Mining Algorithm Based on Adjacency Table
-
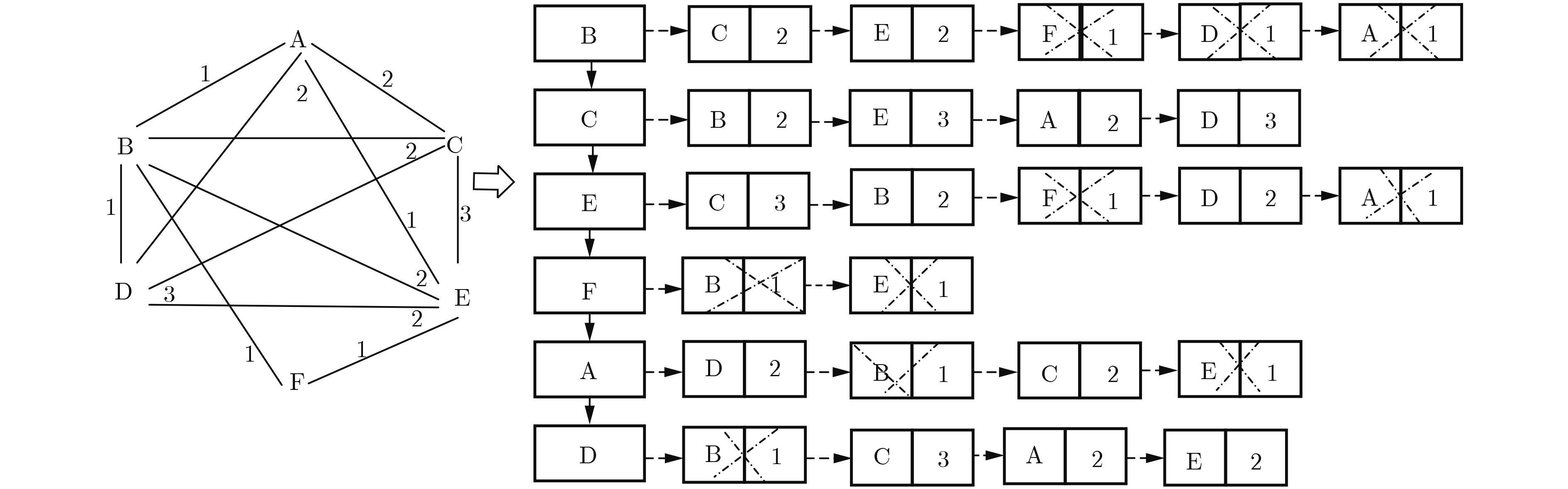
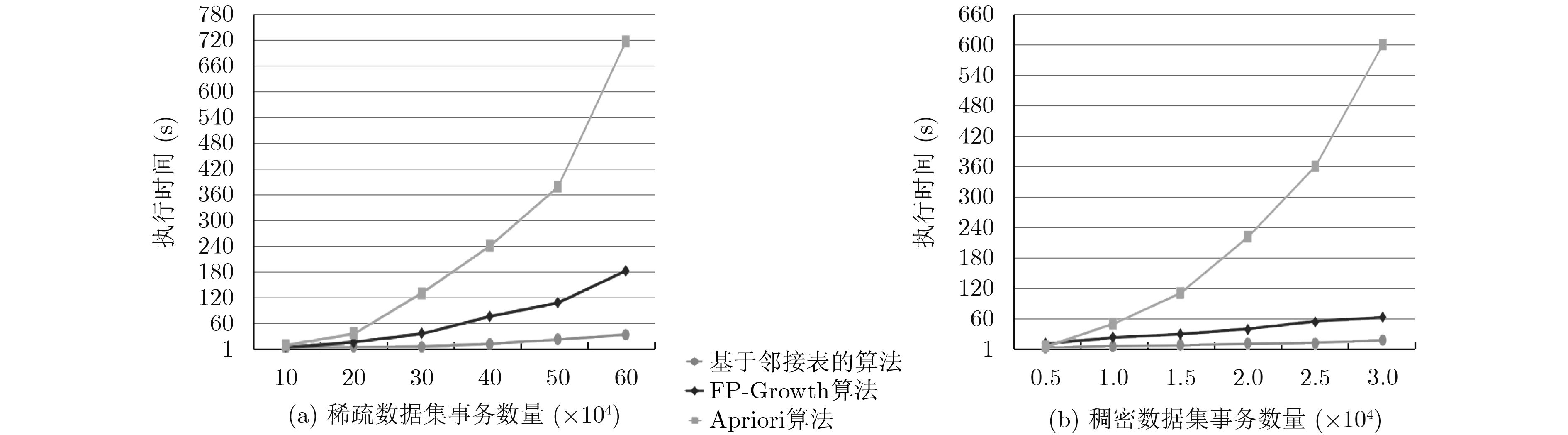
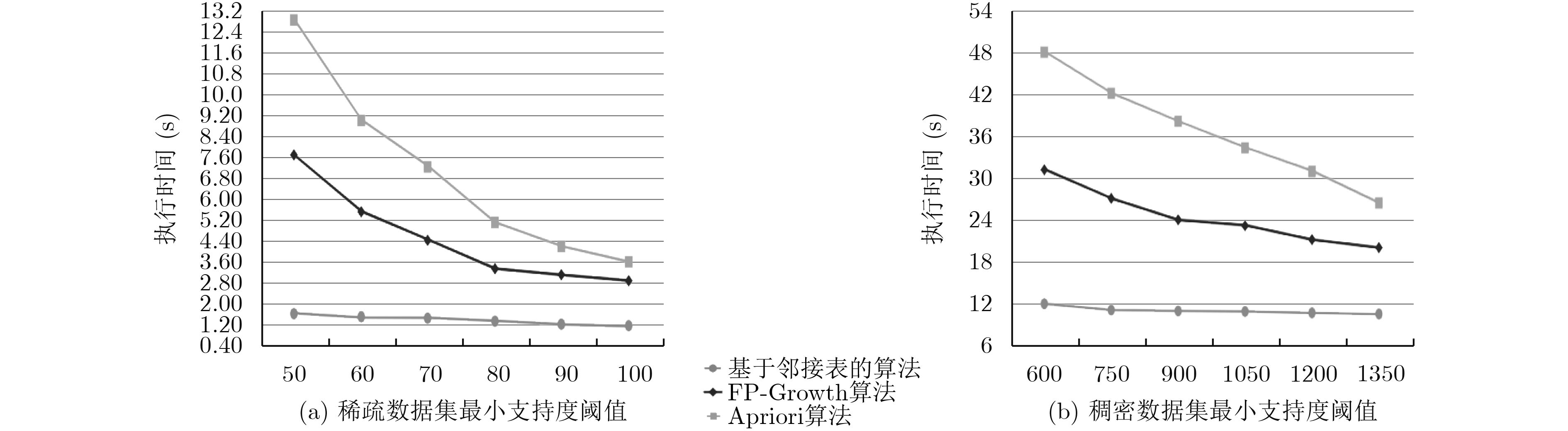
摘要: 针对Apriori算法与FP-Growth算法在最大频繁项集挖掘过程中存在的运行低效、内存消耗大、难以适应稠密数据集的处理、影响大数据价值挖掘时效等问题,该文提出一种基于邻接表的最大频繁项集挖掘算法。该算法只需遍历数据库一次,同时用哈希表对邻接表进行辅助存储,减小了遍历的空间规模。理论分析与实验结果表明,该算法时间与空间复杂度较低,提高了最大频繁项集挖掘速率,尤其在处理稠密数据集时具有较好的优越性。Abstract: To solve the problems of Apriori algorithm and FP-Growth algorithm in the process of mining the maximal frequent itemsets, which refer to inefficient operation, high memory consumption, difficulty in adapting to the process of dense datasets, and affecting the time-effectiveness of large data value mining, this paper proposes a maximal frequent itemsets mining algorithm based on adjacency table. The algorithm only needs to traverse the database once and adopts the hash table to store the adjacency table, which reduces the memory consumption. Theoretical analysis and experimental results show that the algorithm has lower time and space complexity and improves the mining rate of maximal frequent itemsets, especially when dealing with dense datasets.
-
Key words:
- Data mining /
- Frequent itemsets /
- Apriori /
- FP-Growth /
- FP-Tree
-
表 2 3种算法的最大频繁项集挖掘结果
Apriori FP-Growth 基于邻接表的算法 支持度 (A,C:2) (A,C:2) (C,A:2) 0.3 (D,A:2) (A,D:2) (A,D:2) 0.3 (B,C:2) (B,C:2) (B,C:2) 0.3 (E,B:2) (B,E:2) (B,E:2) 0.3 (D,C:3) (D,C:3) (C,D:3) 0.5 (C,E:3) (E,C:3) (C,E:3) 0.5 (D,E:2) (D,E:2) (E,D:2) 0.3 (D,A,C:2) (A,C,D:2) (C,A,D:2) 0.3 (E,C,B:2) (B,C,E:2) (B,C,E:2) 0.3 (D,C,E:2) (D,C,E:2) (C,D,E:2) 0.3  下载: 导出CSV
下载: 导出CSV
-
WU Xindong, KUMAR V, QUINLAN J R, et al. Top 10 algorithms in data mining[J]. Knowledge and Information Systems, 2008, 14(1): 1–37. doi: 10.1007/s10115-007-0114-2 FASIH H and SHAHRAKI M H N. Incremental mining maximal frequent patterns from univariate uncertain data[J]. Knowledge-Based Systems, 2018, 152: 40–50. doi: 10.1016/j.knosys.2018.04.001 易彤, 徐宝文, 吴方君. 一种基于FP树的挖掘关联规则的增量更新算法[J]. 计算机学报, 2004, 27(5): 703–710. doi: 10.3321/j.issn:0254-4164.2004.05.017YI Tong, XU Baowen, and WU Fangjun. A FP-tree based incremental updating algorithm for mining association rules[J]. Chinese Journal of Computers, 2004, 27(5): 703–710. doi: 10.3321/j.issn:0254-4164.2004.05.017 陈安龙, 唐常杰, 陶宏才, 等. 基于极大团和FP-Tree的挖掘关联规则的改进算法[J]. 软件学报, 2004, 15(8): 1198–1207. doi: 10.13328/j.cnki.jos.2004.08.012CHEN Anlong, TANG Changjie, TAO Hongcai, et al. An improved algorithm based on maximum clique and FP-Tree for mining association rules[J]. Journal of Software, 2004, 15(8): 1198–1207. doi: 10.13328/j.cnki.jos.2004.08.012 BUI H, VO B, NGUYEN H, et al. A weighted N-list-based method for mining frequent weighted itemsets[J]. Expert Systems with Applications, 2018, 96: 388–405. doi: 10.1016/j.eswa.2017.10.039 AGRAWAL R and SRIKANT R. Fast algorithms for mining association rules in large databases[C]. The 20th International Conference on Very Large Data Bases, San Francisco, 1994: 487–499. APILETTI D, BARALIS E, CERQUITELLI T, et al. Frequent itemsets mining for big data: A comparative analysis[J]. Big Data Research, 2017, 9: 67–83. doi: 10.1016/j.bdr.2017.06.006 肖波, 徐前方, 蔺志青, 等. 可信关联规则及其基于极大团的挖掘算法[J]. 软件学报, 2008, 19(10): 2597–2610.XIAO Bo, XU Qianfang, LIN Zhiqing, et al. Credible association rule and its mining algorithm based on maximum clique[J]. Journal of Software, 2008, 19(10): 2597–2610. HAN Jiawei, PEI Jian, and YIN Yiwen. Mining frequent patterns without candidate generation[C]. The 2000 ACM SIGMOD International Conference on Management of Data, Dallas, 2000: 1–12. doi: 10.1145/342009.335372. KARIM R, COCHEZ M, BEYAN O D, et al. Mining maximal frequent patterns in transactional databases and dynamic data streams: A spark-based approach[J]. Information Sciences, 2018, 432: 278–300. doi: 10.1016/j.ins.2017.11.064 吉根林, 杨明, 宋余庆, 等. 最大频繁项目集的快速更新[J]. 计算机学报, 2005, 28(1): 128–135. doi: 10.3321/j.issn:0254-4164.2005.01.016JI Genlin, YANG Ming, SONG Yuqing, et al. Fast updating maximum frequent itemsets[J]. Chinese Journal of Computers, 2005, 28(1): 128–135. doi: 10.3321/j.issn:0254-4164.2005.01.016 宋余庆, 朱玉全, 孙志挥, 等. 基于FP-Tree的最大频繁项目集挖掘及更新算法[J]. 软件学报, 2003, 14(9): 1586–1592. doi: 10.13328/j.cnki.jos.2003.09.012SONG Yuqing, ZHU Yuquan, SUN Zhihui, et al. An algorithm and its updating algorithm based on FP-Tree for mining maximum frequent itemsets[J]. Journal of Software, 2003, 14(9): 1586–1592. doi: 10.13328/j.cnki.jos.2003.09.012 VIJAYARANI S and SHARMILA S. Comparative analysis of association rule mining algorithms[C]. 2016 International Conference on Inventive Computation Technologies, Coimbatore, 2016: 1–6. doi: 10.1109/INVENTIVE.2016.7830203. LIU Li, YU Shuo, WEI Xiang, et al. An improved Apriori-based algorithm for friends recommendation in microblog[J]. International Journal of Communication Systems, 2018, 31(2): e3453. doi: 10.1002/dac.3453 连志春, 伊凤新. 一种改进的频繁模式树生长算法[J]. 应用科技, 2008, 35(6): 47–51. doi: 10.3969/j.issn.1009-671X.2008.06.012LIAM Zhichun and YI Fengxin. An improved frequent pattern tree growth algorithm[J]. Applied Science and Technology, 2008, 35(6): 47–51. doi: 10.3969/j.issn.1009-671X.2008.06.012 -


 下载:
下载:



图(5) / 表(2)
计量
- 文章访问数: 2368
- HTML全文浏览量: 1574
- PDF下载量: 82
- 被引次数: 0
