

A Probabilistic Flow Sampling Method for Traffic Anomaly Detection
-
摘要: 针对基于概率抽样的网络流量异常检测数据集构造过程中无法同时兼顾大、小流抽样需求及未区分flash crowd与流量攻击等问题,该文提出一种面向流量异常检测的概率流抽样方法。在对数据流按目的、源IP地址进行分类的基础上,将每类数据流抽样率定义为其目的、源IP地址抽样率的最大值,并在抽样过程中对数据流抽样数目向上取整,保证每类数据流至少被抽样一次,使抽样得到的数据集可有效反映原始流量在大、小流和源、目的IP地址方面的分布性。采用源IP地址熵刻画异常流源IP地址分散度,并基于源IP地址熵阈值设计攻击流抽样算法,降低由flash crowd引起的非攻击异常流抽样概率。仿真结果表明,该方法能同时满足大、小流抽样需求,具有较强的异常流抽样能力,可抽样到所有与异常流相关的可疑源、目的IP地址,并能在抽样过程中过滤非攻击异常流。Abstract: For problems of not meeting the demand of sampling both large flows and small flows at the same time, and not distinguishing flash crowd from traffic attacks in building network traffic anomaly detection datasets based on probabilistic sampling methods, a probabilistic flow sampling method for traffic anomaly detection is proposed. On the basis of the classification of network data flows according to their destination and source IP addresses, the sampling probability for each class of data flows is set as the maximum of its destination and source IP address’s sampling probability, and the number of sampled data flows is ceiled to ensure that each class of data flows is sampled at least once, so that the sampled dataset can reflect the distributions of large, small flows and source, destination IP addresses in original traffics. Then, the source IP address entropy is used to characterize the source IP dispersion of anomaly flows, and the attack flow sampling algorithm is designed based on the threshold of the source IP address entropy, which reduces the sampling probability of non-attack anomaly flows caused by flash crowd. The simulation results show that the proposed method can satisfy the sampling requirements of both large flows and small flows, it has a high anomaly flows sampling ability, can sample all the suspicious sources and destination IP addresses related to anomaly flows, and can effectively filter the non-attack anomaly flows.
-
Key words:
- Network traffic /
- Anomaly detection /
- Flow sampling /
- Probabilistic sampling
-
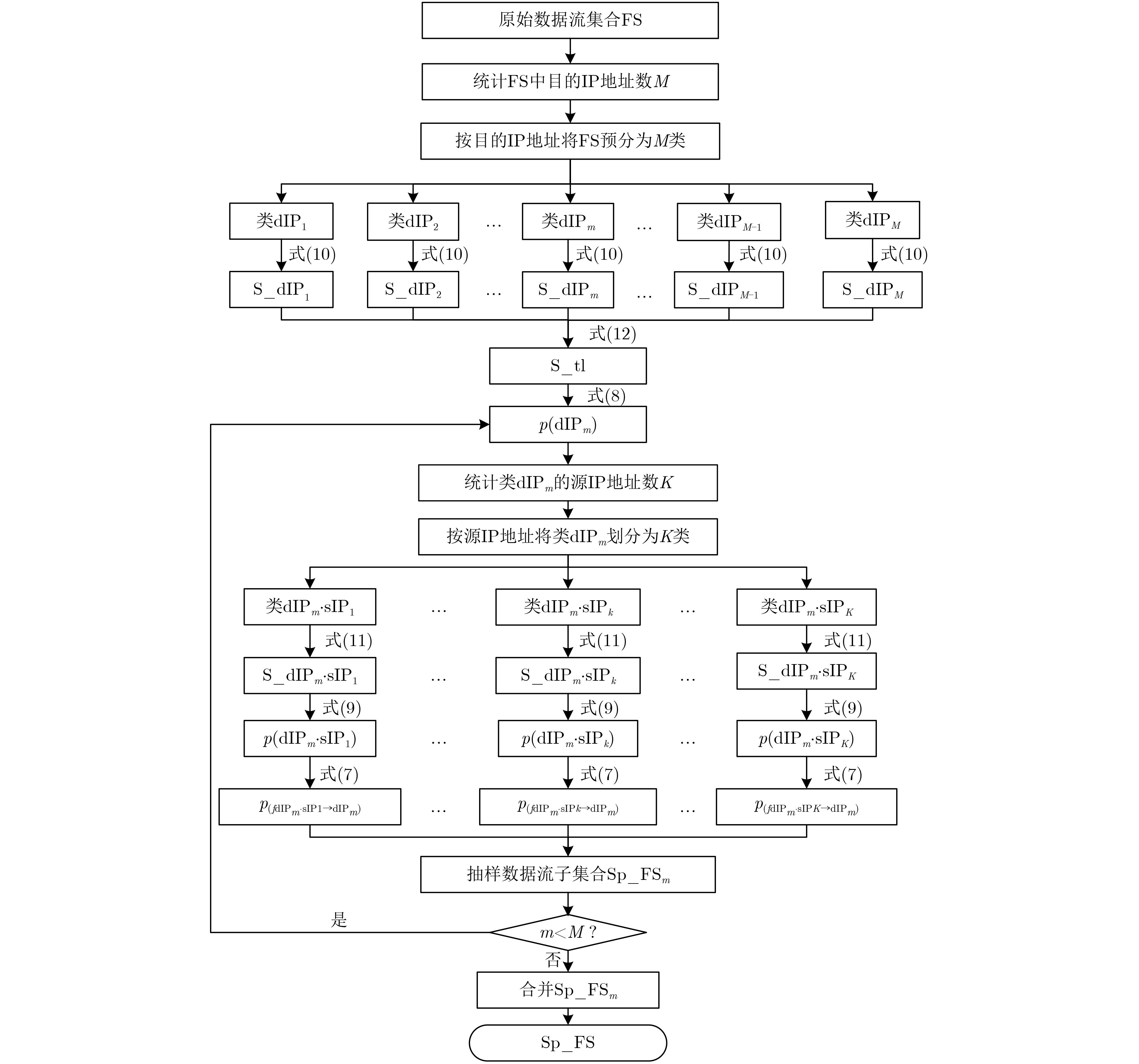
表 1 抽样流程具体描述
输入:原始数据流集合$\rm{FS} $ 输出:抽样后的数据流集合${\rm{Sp}}\_{\rm{FS}}$ 步骤1 统计$\rm{FS} $中目的IP地址数$M$,根据目的IP地址将$\rm{FS} $分成$M$类,即:类${\rm{dIP} _1}$,类${\rm{dIP} _2}$,···,类${{\rm{dIP} }_m}$,···,类${{\rm{dIP} }_M}$; 步骤2 分别统计$M$类的数据流空间大小$L$,依次采用式(10)计算其接收字节总数${\rm{S}}\_{\rm{dI}}{{\rm{P}}_1}$, ${\rm{S}}\_{\rm{dI}}{{\rm{P}}_2}$, ···, ${\rm{S}}\_{\rm{dI}}{{\rm{P}}_m}$, ···, ${\rm{S}}\_{\rm{dI}}{{\rm{P}}_M}$,并采用式
(12)计算样本空间字节总数${\rm{S}}\_{\rm{tl}}$;步骤3 对于类${{\rm{dIP} }_m}$而言,采用式(8)计算目的IP地址${{\rm{dIP} }_m}$的抽样率$p\left( {{{\rm{dIP} }_m}} \right)$; 步骤4 统计类${{\rm{dIP} }_m}$的唯一源IP地址数$K$,并将类${{\rm{dIP} }_m}$进一步划分为$K$类,即:类${{\rm{dIP} }_m} \cdot {\rm{sIP} _1}$, ···, 类${{\rm{dIP} }_m} \cdot {{\rm{sIP} }_k}$, ···,类${{\rm{dIP} }_m} \cdot {{\rm{sIP} }_K}$; 步骤5 分别统计$K$类的数据流空间大小$P$,采用式(11)计算各类发送字节总数${\rm{S}}\_{\rm{dI}}{{\rm{P}}_m} \cdot {\rm{sIP} _1}$, ···, ${\rm{S}}\_{\rm{dI}}{{\rm{P}}_m} \cdot {{\rm{sIP} }_k}$, ···, ${\rm{S}}\_{\rm{dI}}{{\rm{P}}_m} \cdot {{\rm{sIP} }_K}$,并采
用式(9)计算${{\rm{dIP} }_m}$对应的$K$个源IP地址抽样率$p\left( {{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_1}} \right)$, ···, $p\left( {{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_k}} \right)$, ···, $p\left( {{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_K}} \right)$;步骤6 依次采用式(7)计算类${{\rm{dIP} }_m}$中由不同源IP地址流向${{\rm{dIP} }_m}$的数据流抽样率$p\left( {{f_{{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_1} \to {{\rm{dIP} }_m}}}} \right)$, ···, $p\left( {{f_{{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_k} \to {{\rm{dIP} }_m}}}} \right)$, ···,
$p\left( {{f_{{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_K} \to {{\rm{dIP} }_m}}}} \right)$,并输出抽样数据流子集合${\rm{Sp}}\_{\rm{F}}{{\rm{S}}_m} = \bigcup\nolimits_{k = 1}^K {\left\lceil {{f_{{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_k} \to {{\rm{dIP} }_m}}}p\left( {{f_{{{\rm{dIP} }_m} \cdot {{\rm{sIP} }_k} \to {{\rm{dIP} }_m}}}} \right)} \right\rceil } $;
步骤7 如果$m < M$,则返回步骤3;如果$m = M$,则迭代终止,输出最终抽样后的数据流集合${\rm{Sp}}\_{\rm{FS}} = \bigcup\nolimits_{m = 1}^M {{\rm{Sp}}\_{\rm{F}}{{\rm{S}}_m}} $。 下载: 导出CSV
下载: 导出CSV
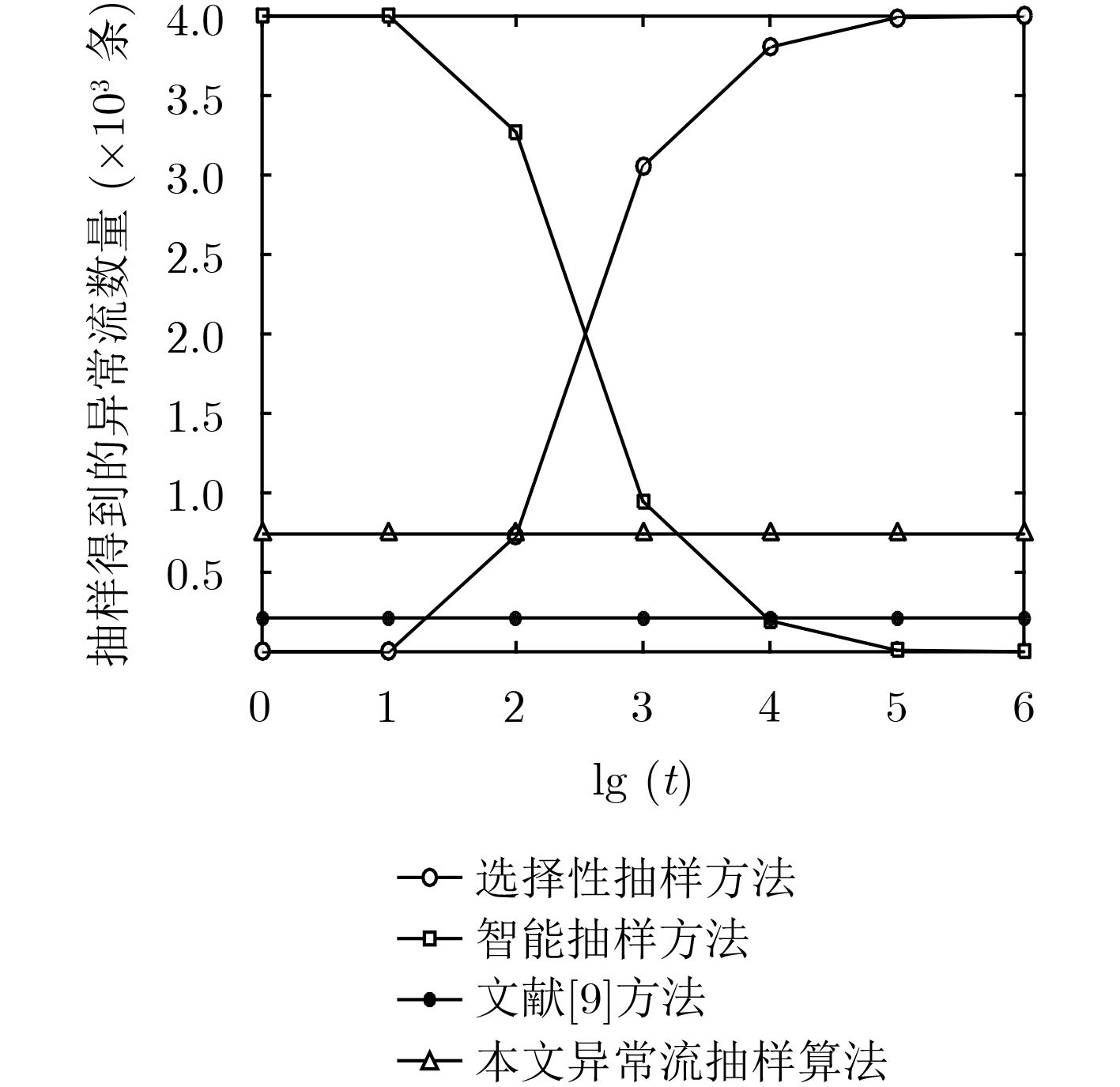
表 2 不同抽样方法数据流保留情况(条)
抽样方法 Dataset1 Dataset2 异常流 大流 异常流 大流 选择性抽样方法 3805 0 3826 0 智能抽样方法 195 1933 174 1294 文献[9]方法 213 747 226 565 本文异常流抽样算法 741 1063 745 1091
下载: 导出CSV
-
YANG Chen. Anomaly network traffic detection algorithm based on information entropy measurement under the cloud computing environment[J/OL]. https://doi.org/10.1007/s10586-018-1755-5, 2018. KWON D, KIM H, KIM J, et al. A survey of deep learning-based network anomaly detection[J/OL]. https://doi.org/10.1007/s10586-017-1117-8, 2017. 周爱平, 程光, 郭晓军. 高速网络流量测量方法[J]. 软件学报, 2014, 25(1): 135–153. doi: 10.13328/j.cnki.jos.004445ZHOU Aiping, CHENG Guang, and GUO Xiaojun. High-speed network traffic measurement method[J]. Journal of Software, 2014, 25(1): 135–153. doi: 10.13328/j.cnki.jos.004445 ANDROULIDAKIS G, CHATZIGIANNAKIS V, and PAPAVASSILIOU S. Network anomaly detection and classification via opportunistic sampling[J]. IEEE Network, 2009, 23(1): 6–12. doi: 10.1109/MNET.2009.4804318 ESTAN C and VARGHESE G. New directions in traffic measurement and accounting: Focusing on the elephants, ignoring the mice[J]. ACM Transactions on Computer Systems, 2003, 21(3): 270–313. doi: 10.1145/859716.859719 ANDROULIDAKIS G and PAPAVASSILIOU S. Improving network anomaly detection via selective flow-based sampling[J]. IET Communications, 2008, 2(3): 399–409. doi: 10.1049/iet-com:20070231 JADIDI Z, MUTHUKKUMARASAMY V, SITHIRASENAN E, et al. Intelligent sampling using an optimized neural network[J]. Journal of Networks, 2016, 11(1): 16–27. 伊鹏, 钱坤, 黄万伟, 等. 基于抽样流长与完全抽样阈值的异常流自适应抽样算法[J]. 电子与信息学报, 2015, 37(7): 1606–1611. doi: 10.11999/JEIT141379YI Peng, QIAN Kun, HUANG Wanwei, et al. Adaptive flow sampling algorithm based on sampled packets and force sampling threshold S towards anomaly detection[J]. Journal of Electronics &Information Technology, 2015, 37(7): 1606–1611. doi: 10.11999/JEIT141379 JADIDI Z, MUTHUKKUMARASAMY V, SITHIRASENAN E, et al. A probabilistic sampling method for efficient flow-based analysis[J]. Journal of Communications and Networks, 2016, 18(5): 818–825. doi: 10.1109/JCN.2016.000110 BEHAL S, KUMAR K, and SACHDEVA M. Discriminating flash events from DDoS attacks: A comprehensive review[J]. International Journal of Network Security, 2017, 19(5): 734–741. doi: 10.6633/IJNS.201709.19(5).11 BEHAL S and KUMAR K. Detection of DDoS attacks and flash events using novel information theory metrics[J]. Computer Networks, 2017, 116: 96–110. doi: 10.1016/j.comnet.2017.02.015 张斌, 刘自豪, 董书琴, 等. 基于偏二叉树SVM多分类算法的应用层DDoS检测方法[J]. 网络与信息安全学报, 2018, 4(3): 24–34. doi: 10.11959/j.issn.2096-109x.2018020ZHANG Bin, LIU Zihao, DONG Shuqin, et al. App-DDoS detection method using partial binary tree based SVM algorithm[J]. Chinese Journal of Network and Information Security, 2018, 4(3): 24–34. doi: 10.11959/j.issn.2096-109x.2018020 CAIDA. The CAIDA UCSD anonymized internet traces 2013[EB/OL]. http://www.caida.org/data/passive/passive_2013_dataset.xml, 2018. CAIDA. The CAIDA UCSD anonymized internet traces 2018[EB/OL]. http://www.caida.org/data/passive/passive_2018_dataset.xml, 2018. MIT Lincoln Lab. 1999 DARPA intrusion detection evaluation dataset[EB/OL]. https://www.ll.mit.edu/r-d/datasets, 2017. -

 下载:
下载:



图(5) / 表(4)
计量
- 文章访问数: 2723
- HTML全文浏览量: 1160
- PDF下载量: 94
- 被引次数: 0
